6. 監視結果の確認
6. 監視結果の確認
正しく設定されていれば、しばらくすると自動的に監視が開始されます。
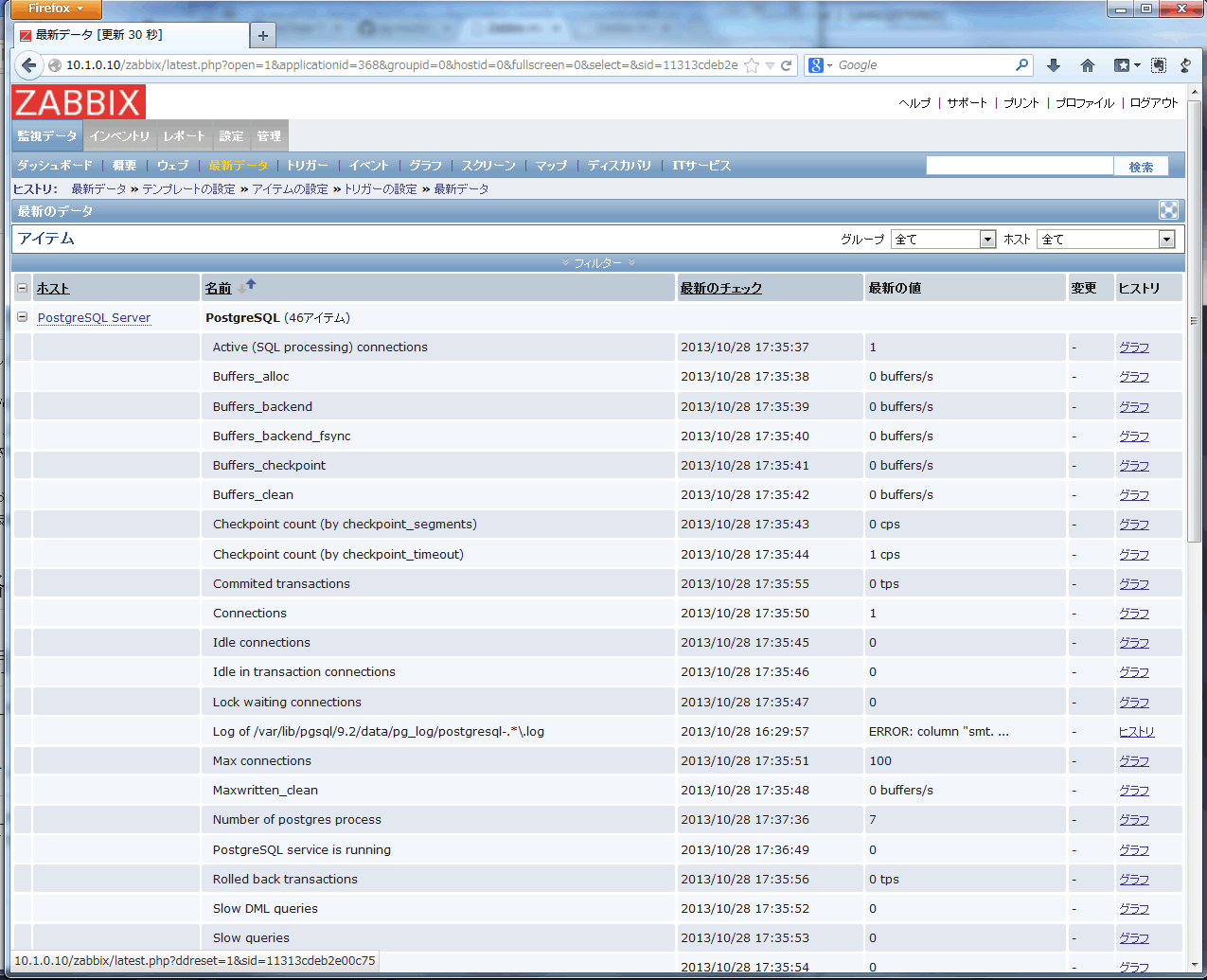
監視結果を確認するにはタブの「監視データ (Monitoring)」-「最新データ (Latest data)」を選択します。
監視データが取得できている場合、上記で登録したホストが一覧に表示され、ホスト名の左の「+」をクリックすると、取得した各項目の最新の値が表示されます。
pg_monz の動作の仕組み
pg_monzは以下の仕組みで動作します。
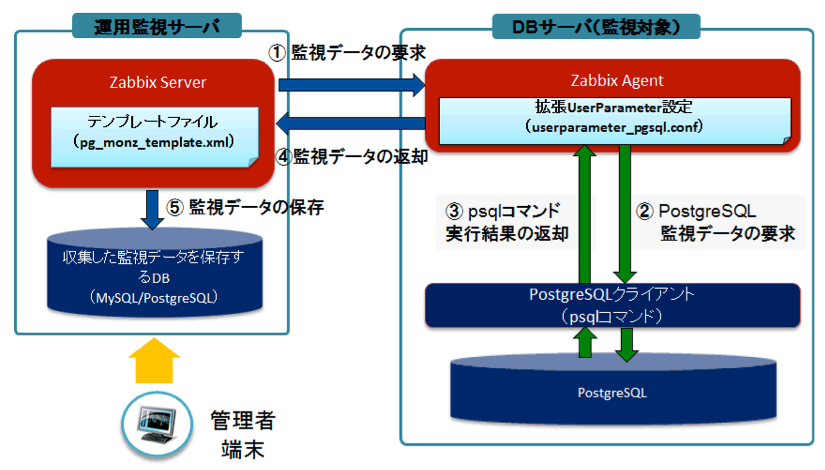
- 運用監視サーバーのZabbix Serverは、インポートしたテンプレートファイルに定義された監視項目のデータを定期的に監視対象サーバーのZabbix Agentに要求します。
- 監視対象サーバーのZabbix Agentは拡張UserParameter設定から監視データを取得するコマンドを実行します。
- 2. のコマンド(psqlで実行するSQL)で取得したデータはZabbix Agentに返却されます。
- 返却されたデータは運用監視サーバーのZabbix Serverに返却されます。
- 監視データはZabbix Serverの収集DBに保存されます。
Zabbixローレベルディスカバリ(LLD)機能による監視設定の自動生成
pg_monzはデータベースの最新状態から監視項目を自動生成する機能を用意しています。この機能はZabbix のローレベルディスカバリ機能を応用しており、以下の様な仕組みで動作します。
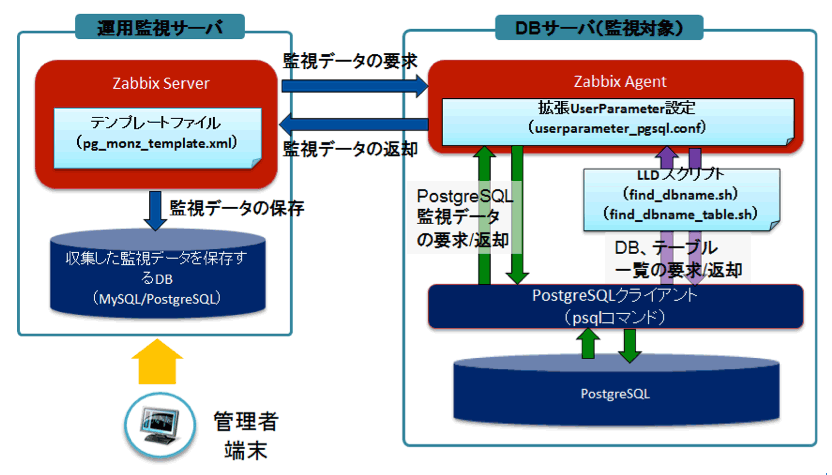
ZabbixのローレベルディスカバリはZabbix2.0から実装された機能で、ホストが保有するネットワークインタフェースやファイルシステム、SNMP OIDといった情報を検出し、監視アイテムやトリガ、グラフを自動的に登録するものです。また、通常の監視アイテムと同様に拡張UserParameter設定を定義することで、ネットワークインタフェース、ファイルシステム、SNMP OID以外の情報を検出することも可能です。
pg_monzでは最新のデータベース、テーブル情報を取得するスクリプト(find_dbname.sh, fjnd_dbname_table.sh)を呼び出す独自のディスカバリルールを拡張UserParamater設定に定義しており、最新のデータベース状態に合わせた監視設定が自動生成されるようになっています。
find_dbname.sh, find_dbname_table.shではPostgreSQLのシステムカタログからデータベース、テーブル情報を取得します。例えばfind_dbname.shでは以下のSQLでpg_databaseカタログからデータベース名の一覧を取得しています。
select datname from pg_database where datistemplate = 'f'また、find_dbname.shは取得したデータベース名を以下の様なJSON形式で返却するように作られています。
{"data": [ {“{#DBNAME}”:“postgres”}, {"{#DBNAME}":"DB1"}] }Zabbixのローレベルディスカバリでは、予めマクロを埋め込んだプロトタイプを作成しておくと、上記のJSON形式のデータが展開されたアイテム、トリガ、グラフが自動生成されます。例えばDB容量を監視するアイテムのプロトタイプは以下の様に定義されており、find_dbname.shから返却された{#DBNAME}の値(postgres, DB1)が埋め込まれた2つのキーが作成されるようになっています。
psql.db_size[{$PGHOST},{$PGPORT},{$PGROLE},{$PGDATABASE},{#DBNAME}]pg_monz を使ったPostgreSQL監視運用の実態
pg_monzによってPostgreSQLサーバーを監視する環境で実際に障害を検知した場合の運用手順をいくつか紹介します。
死活監視
死活監視のトリガで障害が検知された場合、psコマンド等でPostgreSQLのサーバープロセスの稼働状況を確認し、停止しているようであればpg_ctl startコマンドでPostgreSQLサーバープロセスの再起動を試みます。
チェックポイント実行回数の監視
トリガによって一定数以上のチェックポイント実行が検知された場合、合わせて「Checkpoint count」のグラフを確認します。このグラフで「Checkpoint count (by checkpoint_segments)」の値が常時大きいようであれば、PostgreSQLサーバーに設定されたWALセグメント数が小さいことでチェックポイントが頻発している可能性が高いため、postgresql.conf内のcheckpoint_segmentsの値を大きくするパラメータチューニングを検討するとよいでしょう(checkpoint_segmentsの値はデフォルトの3では小さすぎることが多く、一般的には16~64の範囲で設定することが推奨されています)。
データベースキャッシュヒット率
トリガによってキャッシュヒット率の低下が検知された場合、「Cache Hit Ratio」のグラフでキャッシュヒット率の低下が常時発生しているのか、ある時間帯のみ発生しているのかを確認します。
キャッシュヒット率低下が常時発生している場合は、postgresql.conf内のshared_buffersを大きくするパラメータチューニングを検討することになりますが、ある時間帯のみ発生する場合はPostgreSQLサーバーの共有メモリを専有するSQLを発行するバッチプログラムが動いているかもしれません。この場合は対象バッチプログラムの稼働時間を調整したり、発行するSQLを見なおすというチューニング手法も考えられます。
一時ファイル発生状況
トリガによって一定以上の一時ファイル出力が検知される場合、postgresql.conf内のwork_memを大きくするパラメータチューニングを検討することになりますが、ある時間帯のみ発生する場合は特定のプログラムが原因の可能性があります。この場合はSET文で対象のセッションに限定してwork_memを大きくするのがよいでしょう。
今後のpg_monz 開発予定
現状ではシングル構成のPostgreSQLサーバーを監視する機能を提供していますが、今後はストリーミングレプリケーションやHAクラスタソフトウェア(pgpool-II, Pacemaker等)を組み合わせた クラスタ環境を監視できる機能強化を予定しています。また、pg_statsinfo、pg_stat_statment といった既存ツールとの連携を強化したり、Zabbix 2.2, PostgreSQL 9.3 といった新バージョンへの対応や機能強化も行っていきたいと考えています。
pg_monz はこれからもオープンな形で開発を進めていきますので、興味がある方は是非開発にも参画していただければ幸いです。
【関連リンク】
(リンク先最終アクセス:2014.02)
- この記事のキーワード
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
