そもそもディープラーニングとは何か?
今、人工知能は世界中の注目を集めている。そして、間違いなくその中心にいる主役は、「人工知能の革命」とも言われているディープラーニング(Deep Learning、深層学習)だ。ディープラーニングとはニューラルネットワークに対する機械学習の手法の一種で、他の機械学習技術では達成できないレベルの精度を実
2015年8月31日 16:00
今、人工知能は世界中の注目を集めている。そして、間違いなくその中心にいる主役は、「人工知能の革命」とも言われているディープラーニング(Deep Learning、深層学習)だ。ディープラーニングとはニューラルネットワークに対する機械学習の手法の一種で、他の機械学習技術では達成できないレベルの精度を実現できる、夢のような技術として期待されている。とはいえ、実際にはまだまだできないことも多く、万能な技術と言うには時期尚早なのが現状だ。
本連載は3回に渡り、今話題のディープラーニングについて解説する。第一回目は、なぜディープラーニングがここまで注目されるのか、何がすごいのか、そして同技術が注目されはじめた経緯とその理由を、エンジニアの視点からなるべくわかりやすく説明する。第二回目はニューラルネットワークのモデルと、ディープラーニング学習の仕方を紹介する。最終回は、同技術の応用例を事例集という形で紹介し、今後の発展について簡単にまとめる予定だ。
ディープラーニングの最新事例に興味のある方は、9月18日(金)に虎ノ門ヒルズで開かれる「GPUテクノロジー会議GTC Japan 2015」への参加を強く薦める。2000人規模の大きい会議なのだが、参加費が無料なので、是非参加してほしい。
注目された経緯
ディープラーニングがこれほどまでに有名になったそもそものきっかけは、2012年に開催された画像認識コンテスト、ImageNet Large Scale Visual Recognition Challenge(http://image-net.org/challenges/LSVRC/2012/index)にある。カナダ・トロント大学のGeoffrey Hinton教授(現在はGoogleでも研究活動をしているディープラーニング大家の一人)のチームが約1200万画像・1000カテゴリの画像認識に対して初めてディープラーニングを適用し、2位以下を大きく離す圧倒的な精度を実証したのだ。同コンテストは毎年行われ、世界中の一流大学や研究機関がエントリーして独自のアルゴリズムを競っている。2012年にHinton教授のチームが達成した成績は、今後数十年到達することができないようなことが起こったくらいの衝撃として話題となり、日本人の研究者らの間でもディープラーニングの登場が黒船来航に例えられたりして騒がれた。
急速な実用化の波
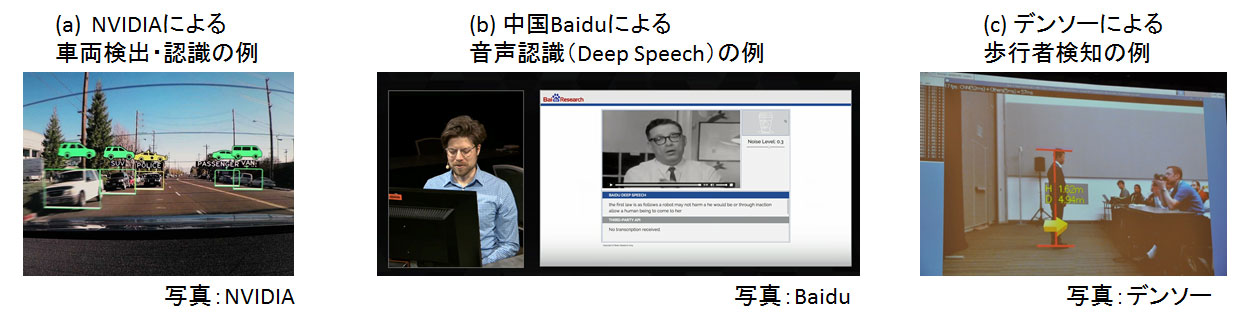
それから3年、ディープラーニングは画像分野などで急速に実用化され、さまざまな革新を起こし始めている。米Googleは、2012年のImageNet画像コンテスト優勝チームが中心となって起業したDNNresearch inc.を即買収し、いち早くディープラーニングの実用化に着手した。その後も積極的なM&Aとビックデータを使い、猛烈なスピードで実用化に成功している。2015年3月に開催されたNVIDIAのイベントで、米GoogleのSenior FellowであるJeffery Dean氏は、同社の画像検索サービスや道路画像表示サービスからAndroidの音声認識など「すでに47種類の自社サービスで、ディープラーニングを利用している」と発表した。当然、米Facebook、米Microsoft、中国Baiduといった他の大手IT企業も、画像検索や音声認識、自然言語処理などさまざまなサービスにディープラーニングを実用化してきた。
Game changerになり得るディープラーニング
そのうちの一社である中国Baiduは、ディープラーニングのために研究所を作り、元米Googleのディープラーニング研究チームリーダであるスタンフォード大学のAndrew Ng准教授を招聘した。米Googleと争う形で同技術の実用化を進めている。
Ng氏は、音声認識がスマートフォンのインターフェイスとして広まらなかった理由の一つとして、特に雑音の多い環境での認識精度の低さを挙げている。これまでの音声認識が仮に95%のボイスコマンドを認識したとしても、それは高い精度で認識できるだけであって十分ではないそうだ。そして、もし95%ではなく99%以上の精度であれば、初めて人々が自然に使おうと思えるほどの正確性を備える「Game changer」になり得ると言っている。そしてNg氏は、その実現可能に一番近い技術がディープラーニングと見ているようで、このことからも大きな可能性を秘めている技術であることがわかるだろう。
日本でも新興企業を中心に実用化が進む
日本国内でも、ディープラーニングをめぐる動きは活発だ。例えば2012年に設立されたベンチャー企業であるABEJAは、小売業や外食店舗内にいる消費者の購買行動のデータ分析にディープラーニングを応用している。他にも、設立11年目を迎える新興企業であるモルフォが、2014年12月からスマートフォンでも動くディープラーニング画像認識器の提供を開始している。
今年の5月26日に行われたNVIDIAディープラーニングフォーラムでは、東京大学の松尾准教授による基調講演に始まり、Preferred Networks、モルフォ、クロスコンパスなどの新興企業や、システム計画研究所が同技術に関しての講演を行った。定員500名のところに1000名以上の応募があり、非常に注目度が高い。
機械学習
ディープラーニングは機械学習の手法の一つだ。ウィキペディアによると、機械学習とは「人工知能の研究課題の一つで、人間が自然に行っている学習能力と同様の機能をコンピュータで実現しようとする技術・手法」とある。つまり、機械に何らかの情報を学習させる技術のことだ。機械学習は通常、入力データと出力データ、そして学習するためのモデルで表せる(図2)。通常の関数やロジックと異なる点は、知識やルールを人間が全部記述しないとこだ。ただし、入力データに依存しているため、同じ学習モデルでも学習データが変われば出力結果も多少変わってくる。

機械学習の手法には大きく分けて三つある。教師あり・なし学習と強化学習だ。ディープラーニングは、いずれにも適用できる。
教師あり学習
問題(入力)と答え(出力)をセットで入力データとして与える場合で、例えば、画像認識(image classification)では、入力画像それぞれに画像のラベル(例:食事、花、人、風景など)を与える。他にも出力データ(変数の関係性)を推定する回帰(regression)などがある。教師データが十分あれば、実用に一番適している。前述のNg氏によると、ディープラーニング関連製品の9割以上は教師あり学習によるものだそうだ。
教師なし学習
答えが与えられないため、入力データの傾向から近いデータ同士をクラスタリングしたり、入力データの次元を削減して、よりコンパクトに抽象化する表現を学習させたりできる。実用的には難しいが、教師データがないときには便利だ。
強化学習
ある環境で選択された行動のフィードバックをもとに、選択された行動の価値を高めるよう強化学習する。チェスや将棋などのゲームを学習させることに適している。米GoogleのDeepMindチームがスペースインベーダーなどのAtariゲームをQ-learningという強化学習アルゴリズムで深層学習させ、驚くべきパフォーマンスを出した。
From Pixels to Actions:Human-level control through Deep Reinforcement Learning
http://googleresearch.blogspot.jp/2015/02/from-pixels-to-actions-human-level.html
ニューラルネットワークが再び注目された理由
実はニューラルネットワークの歴史は古く、1960年代からすでに存在している機械学習アルゴリズムだが、これまでは主流にはなりきれていなかった。その大きな理由の一つとして、多数のパラメータを必要とする非線形の問題に対して非常に学習が困難で、かつ膨大な時間がかかる点があった。一般的に、非線形の問題は線形のものより複雑な認識ができる。例えば、ある静止画像から青いボールを検出するのに、青いピクセルの数だけで判断するのは線形で、ボールの形状や、同じ青でも濃淡や色彩まで考慮して検出する場合は非線形となる。非線形の場合はより情報量が多く、高度な認識が出来る反面、学習が難しい傾向にある。
実際、2012年まではSupport Vector Machine(https://ja.wikipedia.org/wiki/%E3%82%B5%E3%83%9D%E3%83%BC%E3%83%88%E3%83%99%E3%82%AF%E3%82%BF%E3%83%BC%E3%83%9E%E3%82%B7%E3%83%B3)など、比較的簡単に線形分類ができ、精度も良いアルゴリズムが学習モデルを構成する上では実用的で好まれた。しかし現在では、「ディープラーニングとその他機械学習技術」という棲み分けがなされるほど、同技術は圧倒的な精度を誇り、応用範囲も広いことが実証されてきている。
Hinton教授によると、ディープラーニングが可能になった理由は大きく三つある。一つは、ウェブにより大量のデジタルデータが容易に入手できるようになったこと。二つ目は、GPUのように高速演算処理を可能とする汎用的なハードウェアが登場したこと。そして最後の三つ目が、ニューラルネットワークが不遇な時代でもHinton教授をはじめとする少数の研究者たちが地道に研究成果を積み重ね続けてきたことだ。決して偶然に作られたのではなく、技術(ウェブとハードウェア)の進歩が絶え間ない研究努力と結びついた結果だろう。
何が「ディープ」なのか?
ディープラーニングの登場によってニューラルネットワークは再び注目されることとなったが、では何が「ディープ」なのか? その答えは、ニューラルネットワークの構成にある(図3)。ニューラルネットワークは大きく三つの層(入力層、中間層、出力層)に分けられる。入力データは入力層を通り、中間層、出力層を通過して処理され、出力結果が作られる。こうした一連の入力から出力への流れにより、認識が可能となる。ディープラーニングは、特に中間層が2層以上のネットワークを対象にした学習手法のことである。たった数層なのかと思うかもしれないが、これら数層で学習するべきパラメータ数は大幅に増え、学習の難易度も上がる。例えば、2014年のImageNet画像コンテストで優勝した米Googleのネットワークは、20層以上の中間層を持つ大きいネットワークだという。
ニューラルネットワークの種類
ニューラルネットワークは教師あり・なし学習や強化学習どれにでも適用でき、それぞれの学習用途に応じて種類の異なるモデルが存在する。一般的に画像・自然言語処理などではCNN(Convolutional Neural Network)が主流で、音声認識にはRNN(Recurrent Neural Network)や全結合型が使われる。教師なし学習ではオートエンコーダは次元削減に、確率的なモデルであるスパースコーディングやボルツマンマシンはクラスタリングに使われる。次回は、これらモデルとディープラーニングの学習の仕方について、もう少し詳しく説明をしていく予定だ。
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
