大規模言語モデルの自然言語処理「Transformer」モデルの仕組み
第3回は、Transformerモデルのアーキテクチャーやデコーダーの処理内容、RLHFを使ったお作法の訓練を中心に解説します。
2023年7月12日 6:30
はじめに
前回は、大規模言語モデル(LLC)の概要のついて説明しました。今回は、GPTシリーズなどの大規模言語モデルが採用している「Transformer」という自然言語処理について解説します。
RNNやLSTMなどの回帰型ニューラルネットワークが中心だったところに彗星のように現れたTransformerは、どのような仕組みでGPTのような言語モデルを生み出したのでしょうか。
回帰型ニューラルネットワーク
私が2017年にThink ITの連載「ビジネスに活用するためのAIを学ぶ」を書いていた頃は、自然言語処理(NLP)と言えば次の2つが主流でした。拙書『エンジニアなら知っておきたいAIのキホン』にも、この2つの技術解説をしています。
- RNN(Recurrent Neural Network)
- LSTM(Long Short-Term Memory)
しかし、2017年6月にGoogleの研究者たちがTransformerという技術を発表し、この技術を使った大規模言語モデルが次々と登場しています。Transformerアーキテクチャーを解説するためには、その前にRNNやLSTMなどの回帰型ニューラルネットワークのアーキテクチャーを理解する必要があるので、簡単に解説します。
画像認識などで用いられるCNN(畳み込みニューラルネットワーク)は、ある一瞬の画像(スナップショット)を解析して顔や物体を認識するのに使われます。一方、自然言語処理では、前の文脈によって次につながる言葉が変わるので、前の言葉を記憶しながら時系列に処理する必要があります。
図1は、次の単語を予測して出力するトレーニングを行うRNNのイメージです。実際に入力されるテキスト(トークン)はもっと細かいですが、説明のためにまとめています。
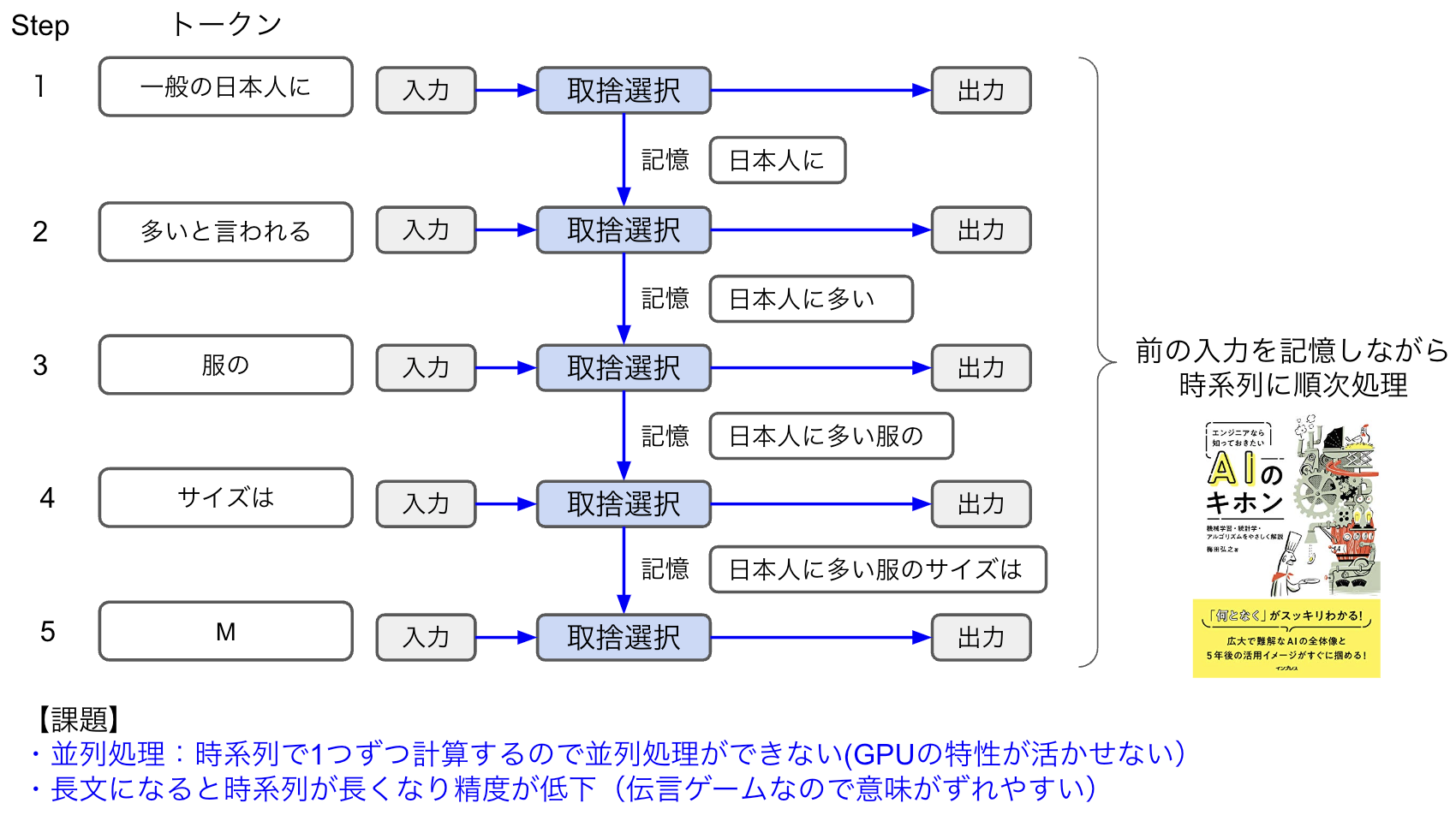
図1:回帰型ニューラルネットワーク
Step1では「一般の日本人に」という入力のうち重要と思われる単語のみ取捨選択し、それを記憶としてStep2に伝えます。人間の言葉は冗長な部分が多いので、入力された単語を重み付けし、重要なワードのみを記憶して次に伝えるのです。この例では「一般の」というワードは重要でないと切り捨てて、「日本人に」という部分だけを次に伝えています。
Step2はStep1から送られた「日本人に」という情報と入力テキスト「多いと思われる」を組み合わせて取捨選択を行った結果「日本人に多い」をStep3に伝えます。このように、前の部分の単語を順番に伝言ゲームのように伝えながら(つまり、文脈を理解しながら)、今回の出力(次に続く単語を予測)をするのが回帰型ニューラルネットワークの特徴です。
回帰型ニューラルネットワークは、このように前のワードを再利用するため回帰型と呼ばれています(再帰型とも言います)。繰り返し時系列処理の学習を行い、前の文脈を理解することで次に続く単語を出力できるようになるのです。
RNNは図1のように記憶ラインが1本ですが、LSTMは短期記憶と長期記憶の2本に分けて次に伝える改良版です。こちらは大きな文脈と直前の文の構成の2つが伝わる方式だとイメージしてください。
RNNやLSTMの課題は次の2点です。世界中でこの課題解決に取り組んで改良を続けているところに、Transformeが彗星のように現れたのです。
- 並列処理:時系列で1つずつ計算するため並列処理ができない(GPUの特性が活かせない)
- 長文の処理:長文になると時系列が長くなり精度が下がってしまう(伝言ゲームなので、途中で意味がずれていきやすい)
Transformerアーキテクチャ
Transformerは、2017年12月6日にGoogleが発表した「Attention Is All You Need」という論文で登場しました。タイトルの意味は「Attentionだけあればいい」というもので、ちょっとおしゃれですね。これは、図1のような時系列の回帰層やCNNのような時系列処理を行わなくても、どの言葉に注目するかというAttentionだけでNLPの性能向上ができるという画期的な発表だったのです。
図2は論文の中で示されているTransformerモデルです。RNNと対比するために少しシンプルにして横に倒したものが図3です。この図を使ってどのような処理を行うのか説明しましょう。
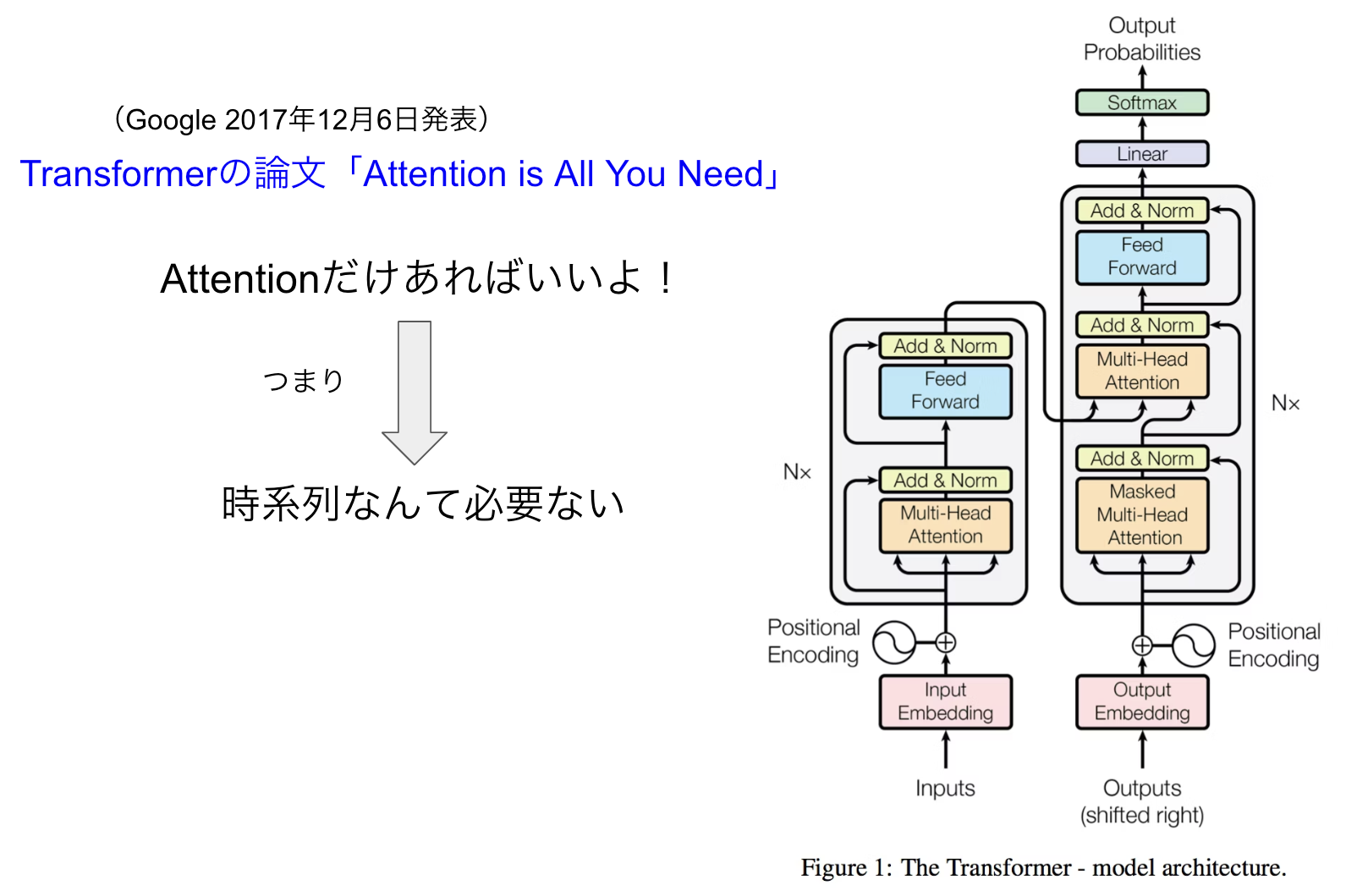
図2:Google論文で示されたTransformerモデル
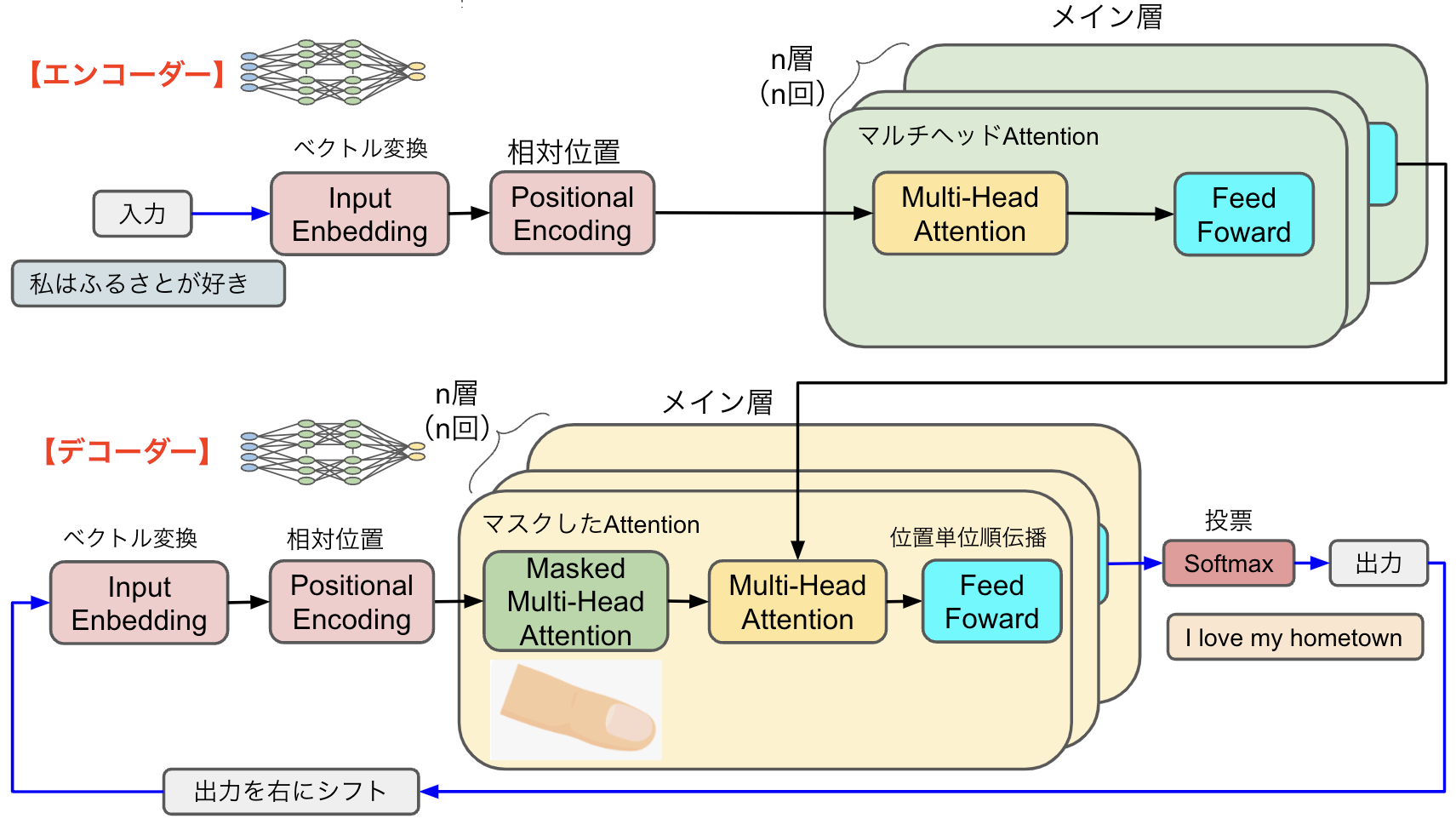
図3:Transformerアーキテクチャー
エンコーダー/デコーダー
Transformerモデルは、エンコーダーとデコーダーから構成されます。エンコーダーとは、データをベクトルなどの特定の形式に符号化することで、デコーダーがそれをデータに復元する処理を言います。図3では、青い矢印がテキストデータで、それをエンコーダーがベクトル化したものが黒い矢印になっています。
エンコーダー・デコーダーモデルは翻訳などでもよく使われており、エンコーダーで入力した文章(例えば日本語)がデコーダーから別の文章(英語など)として出力されます。
(1)エンコーダー
・前処理
前処理としてInput Embeddingでベクトル変換を行い、Positional Encodeingで相対位置を付加します。RNNの場合は時系列にワードが並びますが、Transformerモデルは時系列の概念がなく「私」「は」「ふるさと」「が」「好き」という単語をいっぺんに処理します。そのためPositional Encodingでこれらのワードの相対位置関係を持たせます。
・メイン層
メイン層はマルチヘッドAttentionとPosition-wise Feed-Forward Networkです。エンコーダの処理は1回だけではなく、同一構造の層でn層分(例えばnが6なら6回分)処理を行い、良い具合にAttention処理された後の出力をデコーダに渡します。
・Self-Attention
Self-AttentionはTransformerの中心的な概念で、単語と単語の関連度をスコア付けする処理です。図4はSelf-Attentionの仕組みを表したもので、入力された文章と同じ文章を並べて単語間の関連付け(Attention)を行います。この例では「サイズ」という単語は「M」と関連が強く、「服」や「日本人」などとも関連があるとしてスコアを付けています。Selfと付いているのは自分という意味です。「私に興味を持ってくれるのは誰かしら」と、セルフィッシュな人が品定めしていると思ってください。
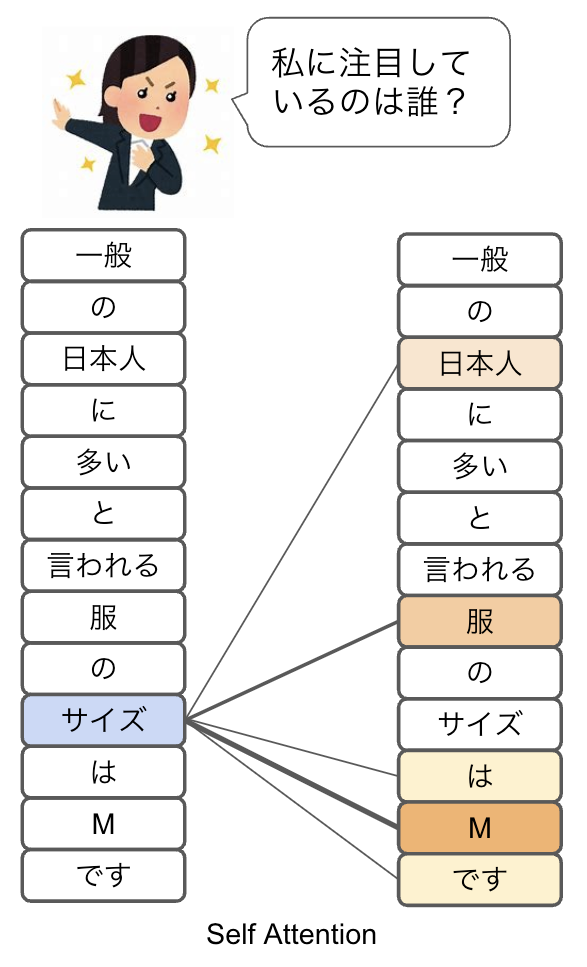
図4:Self-Attention
図1のRNNの取捨選択では、今回入力された単語と伝言ゲームで伝えられた情報とミックスした上で取捨選択しています。一方、Attention方式は図4のように、入力された単語すべてが総当たりで関係性をスコア付けしているのが特徴です。
Self-Attentionの総当りアプローチは伝言ゲームのロスをなくす効果が大きく、長いシーケンス(文章)を処理するのに有効です。200人の男女が集まる婚活イベントがあったとしましょう。20人ずつグループトークを10回行って相性の良い相手を探すやり方だと、最初のグループの人がもう誰だったか忘れてしまいます。それよりも、200人集まった場で自分と合いそうな相手をいっぺんに値踏みする方が効果的というわけです。
・マルチヘッドAttention
マルチヘッドAttentionは、このSelf-Attention(総当り)を並列処理するものです。例えばヘッド(頭)が8つなら、8つの単語のSelf-Attentionを並列に処理します。図4の例で言えば「一般」や「日本人」「言われる」「服」「サイズ」などの単語を8つ並列してSelf-Attentionできる感じです。
これは、処理速度を速くするだけでなく、アンサンブル学習のような効果によって取りこぼしを少なくするメリットもあります。アンサンブル学習とは、1つのモデルだけで予測するよりも複数のモデルの予想を合わせて予測精度を高める、AIでよく使われる方法です。
200人いる会場のステージに8人ずつ登り、それぞれが自分中心に品定めビームを発している光景を思い浮かべてください。これがマルチヘッドAttentionです。そして自分だけだと見落としていたかも知れないところを、みんながピンとくる人を見て「あ、この人も良い」とAttentionするのがアンサンブル学習効果です。
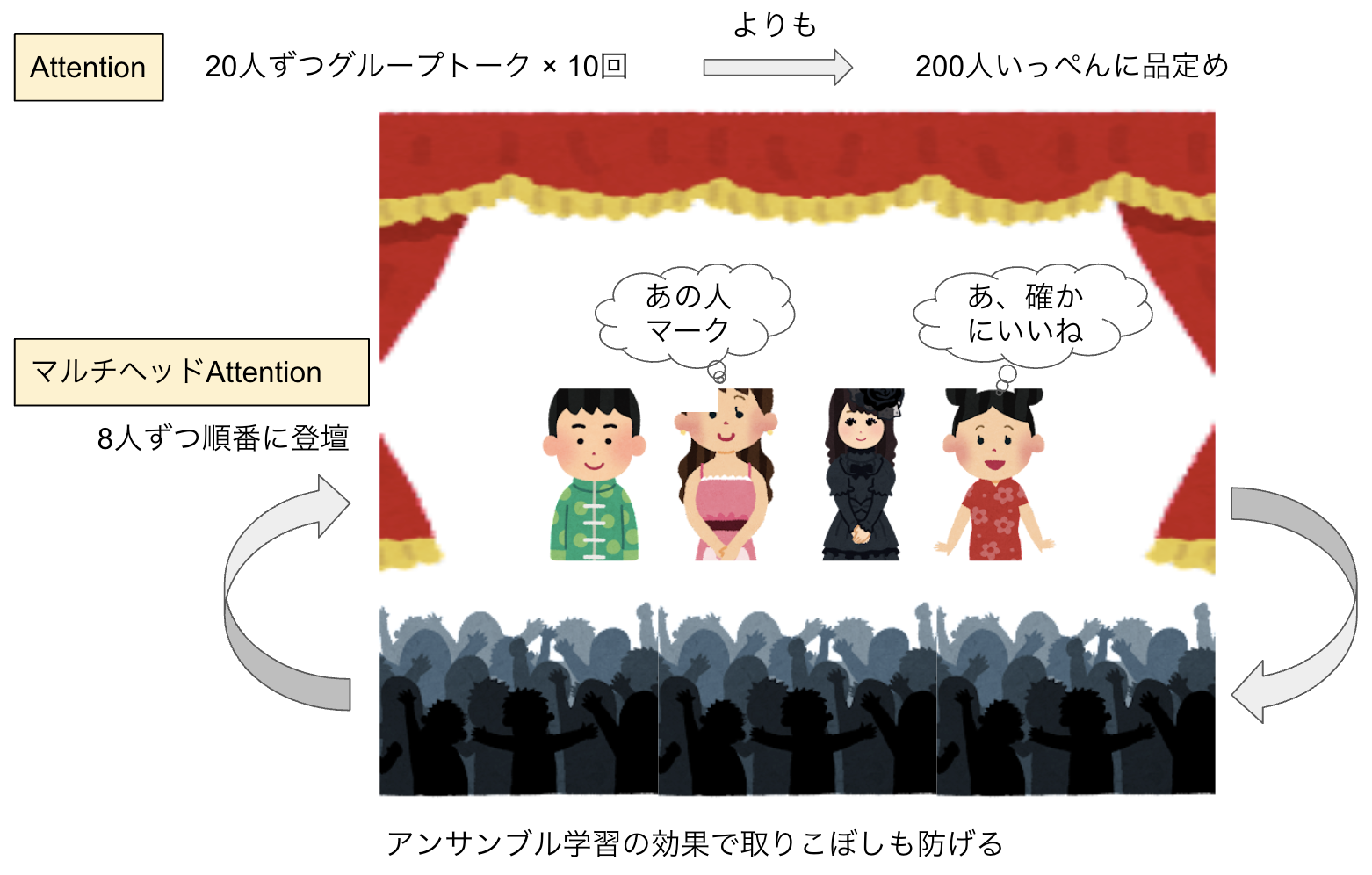
図5:マルチヘッドAttention
・PFFN
PFFN(Position-wise Feed-Forward Network)は、日本語では位置単位順伝播ネットワークと訳されています。順伝播とは、ニューラルネットワークの層を順方向(入力から出力に向かう)に信号が伝わることです。Position-wise(位置単位)とは、独立した単語ごとに並列して順伝播処理を実行することを意味します。つまり「一般」や「日本人」「言われる」「服」「サイズ」などの単語ごとに独立してニューラルネットワークの順伝播処理が行えるので処理が速いというわけです。
(2)デコーダー
入力された文章に含まれる単語と単語の重み付け(Attention)を行うのがエンコーダーです。デコーダーは、この結果をインプットとして受け取り、ひたすら続きを予想する学習を行います。図4の例であれば「一般の」で続きの文章を予想し、「一般の日本人に」で続きを予想するというように、出力される文章の単語と単語の重み付け(Attention)をして文章の続きを予想するトレーニングを行うわけです。
機械翻訳の場合であれば「私はふるさとが好き」という文章をエンコーダーで入力し、「I love my hometown」という文章がデコーダーから出力される感じです。入力される文章「私」「は」「ふるさと」「が」「好き」「です」を総当りでAttentionするのがエンコーダー、そのベクトル情報を使って「I 」「love」「my」「hometown」という英文を導き出すのがデコーダーの役目です。
・行列積(matmul)
エンコーダと同じくメイン層はn回繰り返し処理されます。エンコーダーでn回処理された最終アウトプットが、良い塩梅にAttention付けされた入力文章ということになります。これをデコーダーの1回前の出力とMulti-Head Attentionで行列積(matmul)計算しています。
行列積とは、2つの行列をかけ合わせて1つの行列を出力することです。ここではエンコーダの出力と1つ前のデコーダの出力の要素を合わせていると理解してください。そして、この処理をn回繰り返すことでデコーダは良い塩梅で正解に近い文章を作り出せるようになるのです。
・Masked Multi-Head Attention
デコーダーはエンコーダーの構成とほぼ同じですが、Masked Multi-Head Attention層がプラスされています。これは、デコーダが続きの文章(正解)を知ってしまわないように(これから予想する未来の)単語をマスクしてトレーニングするためのものです。人間の学習に例えれば、指や下敷きで正解を隠して解答を考えるというやつと同じです。
・Softmax
Softmaxは、複数の出力値の合計が1.0(100%)となるような値を返す関数です。例えば、myが0.8、ourが0.1、theとaが0.05というように出力値の確率を返します。その値によって回答「my」を決めるのです。
エンコーダーとデコーダーの言語処理内容
Transformerのアーキテクチャを理解したところで、このモデルがどのように言語処理するのか掘り下げてみましょう。図2と図3は学習時と推論時に分かれていないので、図6を使ってデコーダーの翻訳処理を説明します。
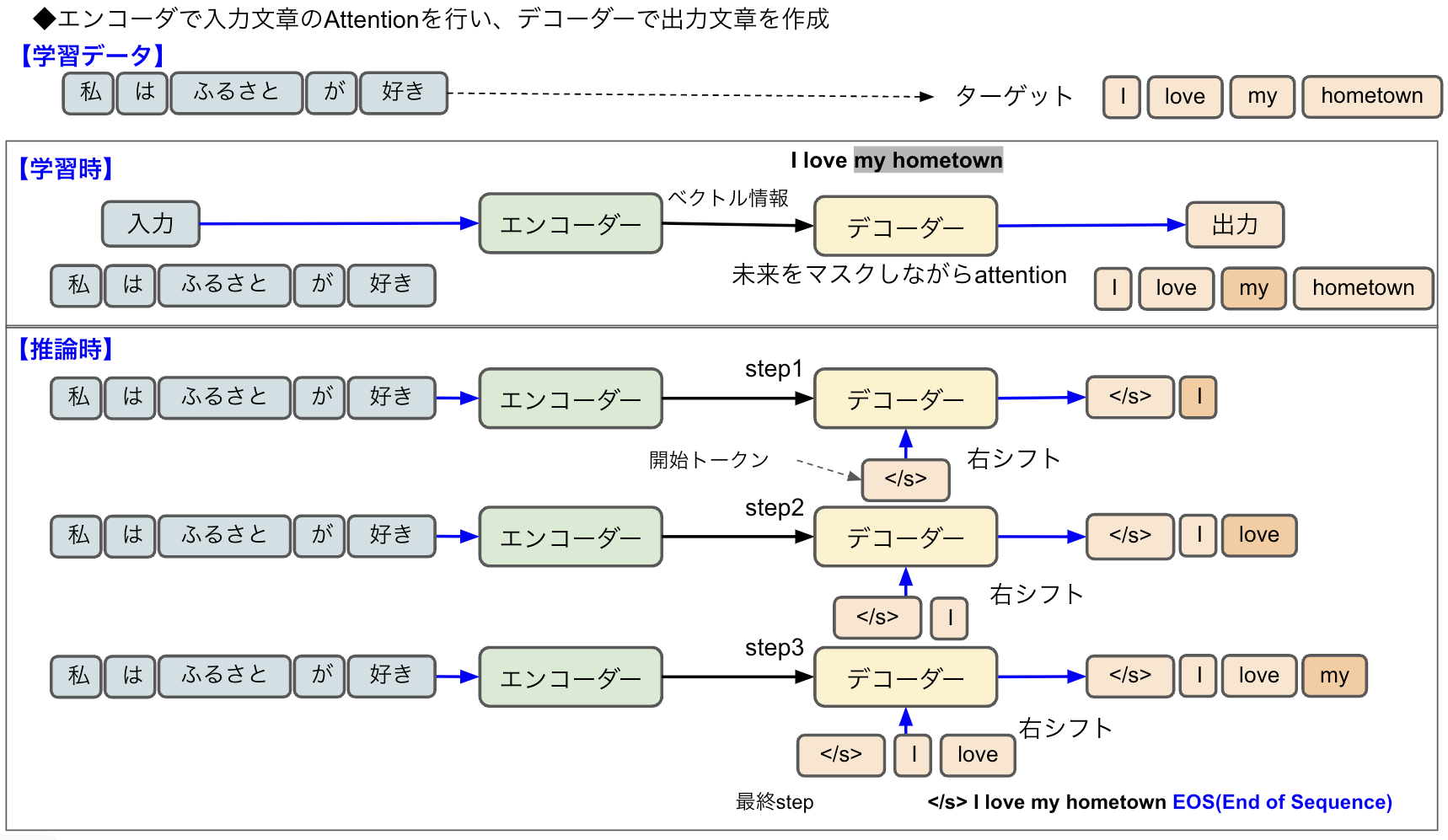
図6:エンコーダー/デコーダーモデル
学習データ
学習データは、「私はふるさとが好き」という日本語とその英訳の「I love my hometown」です。
学習時
エンコーダーで良い具合にAttentionされた入力情報「私はふるさとが好き」がデコーダーに渡されます。デコーダーは「I love my hometown」という出力ができるようにトレーニングされるのですが、デコーダーのAttentionは未来の単語を隠したMasked Multi-Head Attentionです。
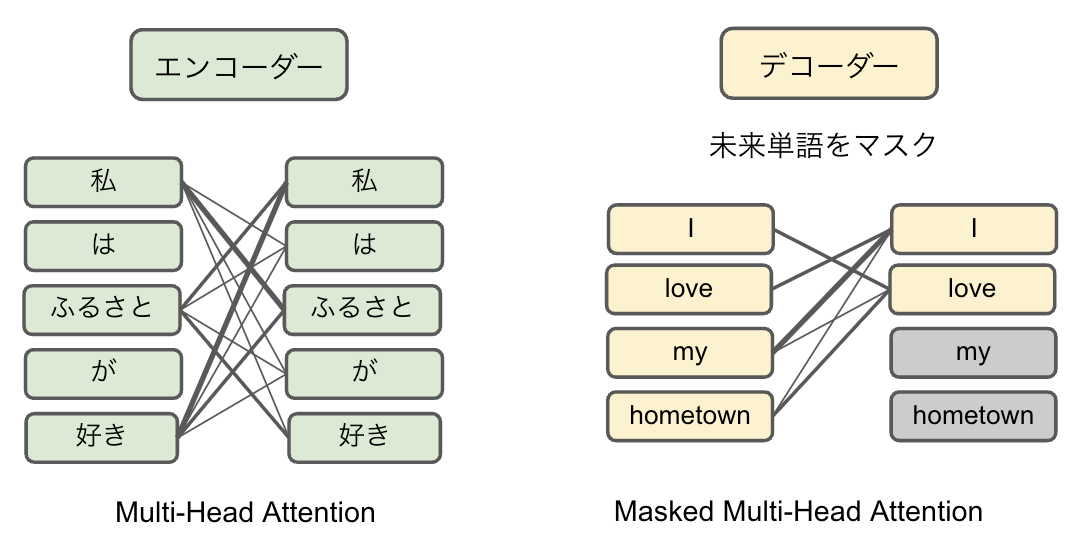
図7:エンコーダとデコーダのAttention
例えば「I love」の次の言葉を予測する際に「my hometown」という未来の言葉がわかると学習にならないので、それをマスクするわけです。
推論時
学習はいっぺんにAttentionしますが、推論は時系列に行います。step1でデコーダーが予測する最初の言葉は「I」ですが、これに対して右シフトを行うことにより開始トークン(ここでは<s/<という文字)が挿入されます。右シフトとは、入力された単語の位置を右にずらす操作です。例えば「1,2,3」という文字列があるときに、1つ右にシフトすることで先頭に0が入り「0,1,2」となります。
step2では「love」が予測され、step3では「my」が予測されるというように次々と処理され、最終的にEOS(End of Seuence)が入って終了です。
ニューラルネットワークの重み
ここでニューラルネットワークのキホンを押さえておきましょう。人間の脳は、ニューロンという神経細胞と、ニューロン間をつなぐシナプスのネットワーク構造になっています。ニューロンから別のニューロンにシグナルが伝達してモノを判断しているわけです。
ニューラルネットワークは、この仕組みを模倣した図8のようなネットワーク構造となっており、丸がニューロン、丸をつなぐ線がシナプスに相当します。入力層と出力層の間に隠れ層(中間層)があり、この層を数十から数百という具合に深くすると頭が良くなるという発見がディープラーニングにつながっています。ちなみにGPT-3はTransformerとFeedfowardで96層を持つと言われています。
線の太さが重み(weight)で、これが信号の伝わりやすさです。この例はインプットされた文章をもとにMかLかを当てる単純なモデルですが、入力側のノードからMを支持する信号とLを支持する信号が伝わっていき、最後にsoftmaxで多数決を取ってMかLという回答を出力するわけです(図3にもsoftmaxがあります)。
学習の際、正解がMなのにLだと誤答した場合、それを誤差として逆伝播して間違いの原因と思われる線の重み(太さ)を調整します。その学習を延々と繰り返し、良い塩梅の重みとなったときに正解を答えられるようになるのです。
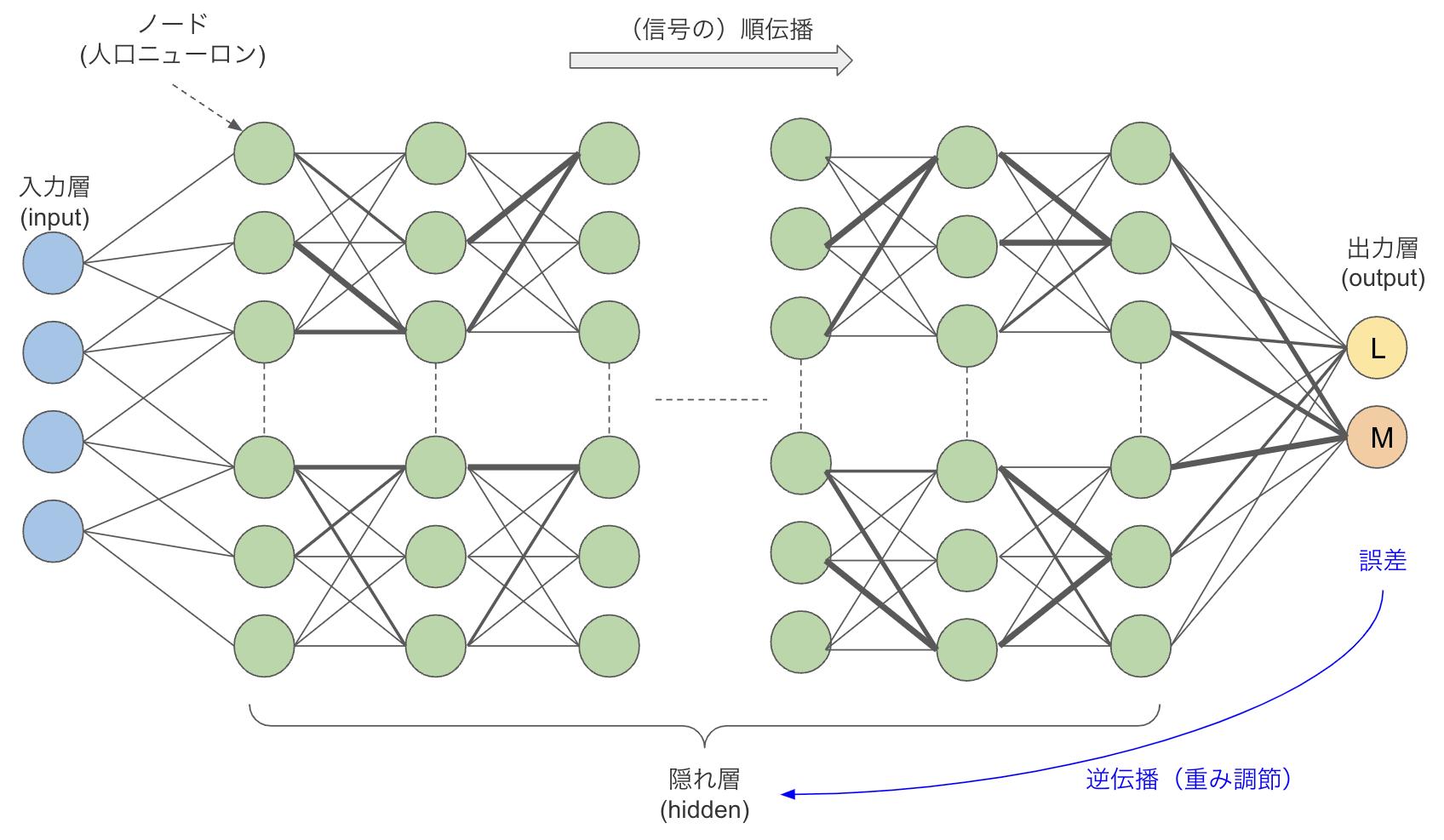
図8:ニューラルネットワークの構造
RLHF
GPT-3.5は、豊富な学習データでトレーニングしているだけに、いろいろな質問に対して素晴らしい回答を出力します。しかし、普通に言語を覚える学習をするだけでは、人間に好かれるような話し方をしてくれません。また、学習に使ったネット上の言葉には差別用語や攻撃的な言葉が溢れていますので、平気で眉をひそめるような発言をしてしまいます。
チャットで会話するためには、もっと人間の好む言い回しを覚えたり、差別的な表現や暴力的な発言をしたりしないようにしつける必要があります。このしつけは、RLHF(Reinforcement Learning from Human Feedback)という強化学習モデルで行っています。
InstructGPTとChatGPT
実はGPT-3.5とChatGPTの間にInstructGPTというものがあります。これは言語モデルのGPT-3.5シリーズに対し、人間の指示(Instruction)に従って人間好みの無害な出力を得るように調整したものです。そして、InstructGPTの対話機能をさらに強化してチャットサービスにしたものがChatGPTとして出現したのです。
つまりChatGPTはGPT-3.5という言語モデルをベースとし、RLHFを使って人間の好むような言い回しにしたり、差別的・暴力的な表現を避けるようにした上でリリースしたものです。GPT-4でもRLHFは使用されていますが、もはや標準装備でありChatというネームは付けていません。
RLHF(Reinforcement Learning from Human Feedback)を直訳すると、人間のフィードバックを用いた強化学習です。強化学習(Reinforcement Learning)とはAIエージェントが期待報酬を最大化するように行動を学習する方法で、囲碁のプロ棋士を破ったDeepMind社のAlphaGOに使われて一気に知られるようになりました。後ろのHFはAIが生成した文章を人間が評価する学習を表しています。
RLHFの仕組み
図9はRLHFの仕組みを簡単に表したものです。RLHFの学習は3つのステップで行われます。
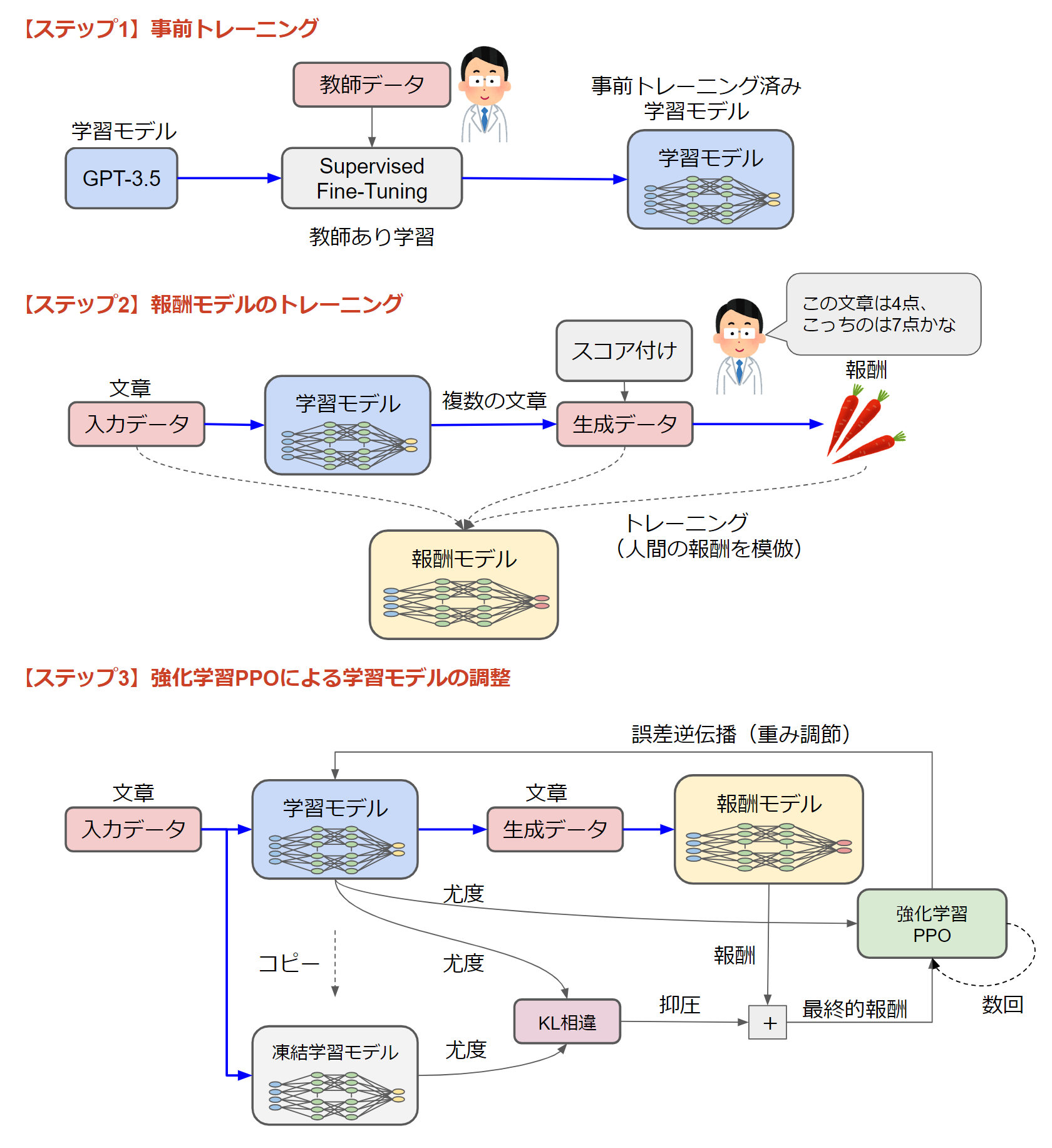
図9:RLHF(Reinforcement Learning from Human Feedback)
【ステップ1】事前トレーニング
最初に学習モデル(GPT-3.5)に対して、教師データを元にトレーニングします。教師データは、好ましい言い回しや差別用語を使わない言い方を定義したデータセットから一連のプロンプト(せりふ)をサンプリング生成したものです。人間に例えれば、まずは基本的な言葉の作法をテキストで学び、それから実践で学習するという感じでしょうか。
【ステップ2】報酬モデルのトレーニング
RLHFでは「学習モデル」と「報酬モデル」を使います。ステップ1は「学習モデル」の基礎学習ですが、ステップ2は「報酬モデル」のトレーニングです。ここでも人間が関与しており、ステップ1でトレーニングした学習モデルに文章をインプットし、いくつかの文章をアウトプットします。
これらの文章に対して人間がスコア(報酬)を付けます。「この文章は4点」「こっちの文章は7点」というように報酬を付けるわけです。そして、そのスコア付け加減を模倣するのが「報酬モデル」です。「入力データ」と「生成データ」と「報酬」を元に人間に近いスコアリング能力を身につけていきます。
【ステップ3】強化学習PPOによる学習モデルの調整
2つのステップで事前準備したら、いよいよ人間なしでぐるぐる学習ができます。基本は「学習モデル」を「報酬モデル」でトレーニング(重み調節)するループですが、その他に「PPO」や「KL損失」「凍結学習モデル」「誤差逆伝播」などちょっと難しい用語が出てきますので、これらも簡単に解説します。
(1)凍結学習モデルとKL相違と尤度
最初に学習モデルのコピーを「凍結学習モデル」として用意します。これは、トレーニングにより学習モデルが意味不明なデータを生成してしまうのを防ぐためです。人間の文章に例えれば、推敲で文を変更しまくった結果、わけがわからなくなってしまわないように、オリジナルの文章を取っておき見比べて作業するような感じです。
KL相違(Kullback-Leibler divergence)とは、2つの確率分布の差異を図る尺度です。ここでは同じ入力データに対する学習モデルと凍結学習モデルの出力の尤度(確率分布)の差を使って、学習モデルが異変を起こさないように抑圧すると理解してください。
尤度(likelihood)とは、あるデータを元にしたパラメータ分布の確率(尤もらしさ)を表す統計用語です。学習モデルの出力文章を確率分布データで表したものだと思っておいてください。人間を模倣してできた「報酬モデル」は文章をインプットとして報酬を算出していますが、KL損失やPPOは尤度というコンピュータが処理しやすい確率分布で学習モデルの出力を評価・計算するわけです。
「報酬モデル」でスコアされた「報酬」をこのKL相違で調整して最終的な報酬が決定します。この一連の計算の役目は、報酬モデルが付ける報酬に対して、少し抑圧するような処理となります。
(2)PPOと誤差逆伝播
PPO(Proximal Policy Optimization)とはOpenAIが2017年に公開した強化学習アルゴリズムで、近接方策最適化と訳されています。前の方策と新しい方策の比率を近接勾配法により一定の範囲に制限(clipping)することで、パラメータの急激な変更を抑えられる強化学習アルゴリズムです。図9においては、今回の学習モデルの出力(尤度)と、それに与えられる最終的報酬を前回と比較して、その比率に制限を加えた上で学習モデルの重みを調節します。
学習モデルは、誤差逆伝播により頭が良くなっていきます。図8で説明したように、誤差逆伝播は誤差を元にニューラルネットワークの重みを調節するフィードバック処理です。「今回の文章は、前回の文章よりこんなとこが良かったよ」という報酬の差を元に学習モデルの重みを調節する作業を数回繰り返し、そしてまた次の入力データに切り替えて延々と学習を行うのです。
以上が、言語モデルがRLHFによって人間が好む会話ができるようになる仕組みです。最初に人間が覚えてほしいお作法を教え、次に人間の評価を模倣する報酬モデルを作り、最後にその報酬モデルを使って言語モデルを強化学習するという流れが理解できたでしょうか。
AlphaGoと言語モデルの対比
AlphaGoは人間が対局した棋譜を学習データに使いましたが、進化版のAphaZeroは人間の学習データは使わずに自己同士の対局(Selfplay)だけで学習できるモデルです。ルールを教えるだけで勝手に強くなれるので、囲碁だけでなくチェスや将棋などあらゆるゲームで強みを発揮します。
AlphaZeroは3つのAIを使っています。局面を評価するモデル(Value network)と着手を評価するモデル(Policy network)の2つのニューラルネットワークを強化学習でトレーニングし、モンテカルロ木の探索を組み合わせて着手を選択しています。人間に置き換えれば、形勢判断して最善手を探し、そこに読みを入れて次の一手を決める感じです。
ゲームの特徴は「勝つ」という最高の報酬がはっきりしていることです。そのため、自分と自分を気が遠くなるほど戦わせた棋譜を学習データとして使い、局面や着手を評価するAIをトレーニングできます。これに対し、自然言語モデルの最高の報酬は「最高にわかりやすい文章」です。勝ち負けと違ってあいまいなので人間の手助けが必要になっています。
AIの能力は「人間の手助け」がボトルネックです。現在のモデル(GPT-4)は人間が学習データを用意しているので、その準備作業が大変です(未だに2021年9月の学習データです)。しかし、すでにチャットで公開して膨大な反応(ユーザーとのトーク内容)を獲得していますし、今後ネットの最新情報を自動的に学習データにする技術も進むと思われるので、学習データは大幅にパワーアップするでしょう。
そして、最終的にはAlphaZeroのようにAI同士が勝手にデータを作成したり、それを評価する仕組みができて、飛躍的に進化すると予想しています。
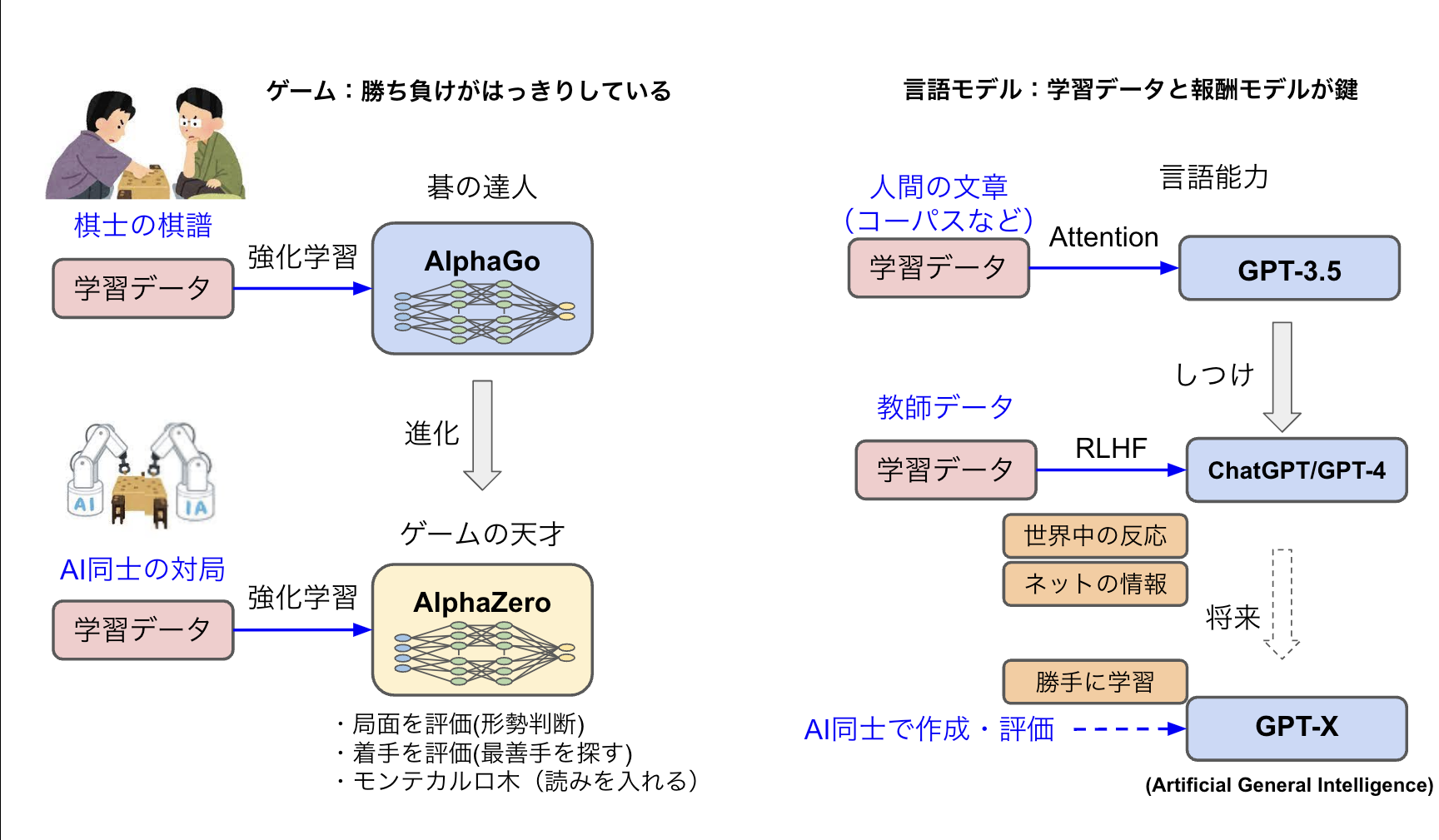
図10:AlphaGoと言語モデルの対比
まとめ
今回は、以下の内容について学習しました。
- 自然言語処理は、RNNやLSTMなどの回帰型ニューラルネットワークに代わりTransformerモデルが主流になっている
- Transformerモデルは、エンコーダーで入力された文章を元にデコーダーで文章を出力する
- Attentionは単語と単語の関連性をスコアする技術で、時系列に学習処理しなくても済む
- デコーダーは未来の単語をマスクしながら学習し、推論はステップごとに行う
- ニューラルネットワークは誤差逆伝播によりネットワークの重みを調整して賢くなる
- RLHFはステップ1で基礎を学び、2で報酬モデルを模倣し、3でぐるぐる訓練する
- ChatGPTやGPT-4はTransformerモデルで言語学習したものをRLHFでしつけ、チャットで使えるようにしている
今回はTransformerモデルのアーキテクチャーやデコーダーの処理内容、RLHFを使ったお作法のしつけを中心に説明しました。次回は、GPT-4を搭載したBingやCoPilotの仕組みを解説し、これらを使うとどのようなことができるのかについて解説します。
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
