ニューラルネットワークのモデルのバリエーション
前回は、ディープラーニングの概要を紹介した。今回は、もう一歩踏み込んだニューラルネットワークのモデルの説明と、ディープラーニングの学習をするためのオープンソースのフレームワークを紹介しよう。ディープラーニングは、他の機械学習技術とどこが違う?まず学習方法の説明に入る前に、ディープラーニングと他の機械
2015年9月9日 16:00
前回は、ディープラーニングの概要を紹介した。今回は、もう一歩踏み込んだニューラルネットワークのモデルの説明と、ディープラーニングの学習をするためのオープンソースのフレームワークを紹介しよう。
ディープラーニングは、他の機械学習技術とどこが違う?
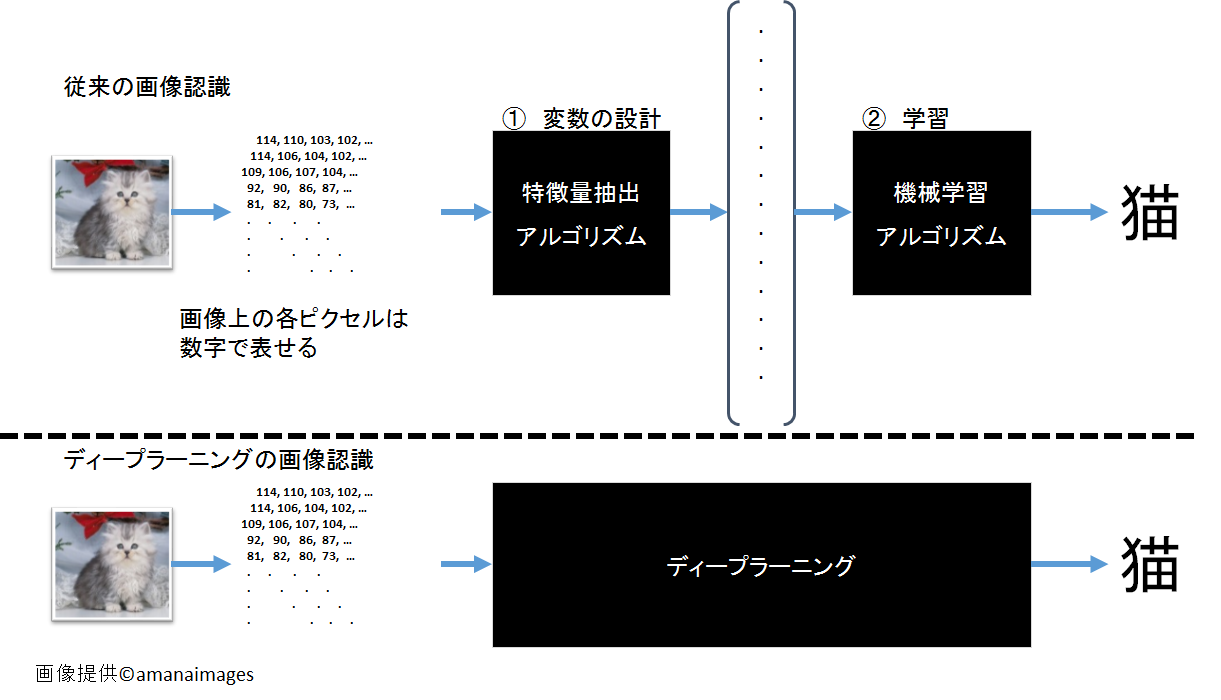
まず学習方法の説明に入る前に、ディープラーニングと他の機械学習技術には決定的に違う点があることを理解する必要がある。それは、機械学習において非常に難しいとされる変数の設計だ。従来の技術では、例えば画像認識を行う場合、入力データはピクセル値そのものではなく、「特徴量」と呼ばれる何らかの変数の集合となる(図1)。画像の特徴量は色、形状、テクスチャなどいろいろな情報を、ヒストグラムなどでコンパクトに表現した変数のセットであることが一般的だ。ただし、特徴量の設計というのは非常に難しく、研究者の経験と直感によるところが大きかった。一方ディープラーニングは、そういった変数もデータから自動的に学習してくれる。つまり、今まではハンドエンジニアリングされてきた特徴量を、データに基づいて最適なものを自動的に生成してくれるため、学習データの表現力に富む。そのためディープラーニングの場合は、入力データはピクセル値そのものでよく、特徴量である必要はない。これが他の機械学習技術と大きく違う点であり、より高い精度が出る理由のひとつだ。
学習の流れ
ディープラーニングの学習には、大量のデータと学習を効率的にするための高速演算能力が必要だ。学習と学習済みモデルの実行環境を図2に示した。画像、音声、テキストなど問題に応じた大量のデータを入力として、GPUの計算能力をフルに使い学習を行う。学習済みモデルには、学習で使用した入出力データに基づき学習された変数と、ネットワークの構造情報が格納される。この『学習済みモデルデータ』への参照と実行には、学習時ほどの計算リソースは必要なく(詳細は次のセクション)、PCやモバイル端末などさまざまな環境から実行可能となる。

ディープラーニングがさらに広まるためには、GPUに依存せず、FPGAやDSPなどのチップで低消費電力に抑えられることも重要になってくる。クラウド依存しないアプリケーションでも応用できれば、オンライン・オフラインに関わらずさまざまなデバイスで同技術が導入され、さらなる技術革新へとつながる可能性が高い。実際、米MicrosoftはFPGA上でディープラーニングの実装をし、GPUを使用したシステムに匹敵するレベルの性能を低消費電力で実現した。電力効率で、最大約3倍の性能だと発表している。巨大なデータセンターを持つ大手企業にとっては、電力消費削減によるコストメリットのため、FPGA上で学習を行うことも選択肢のひとつとなっていくだろう。
Microsoftの深層学習はFPGAで動く
http://techon.nikkeibp.co.jp/article/MAG/20150311/408682/
ニューラルネットワークの学習
ここではニューラルネットワークの学習について簡単に説明する。まず、前回の記事でも紹介したニューラルネットワークの構成について、ここではもう一歩踏み込んでみる。一般的にネットワークは入力データと出力データを持ち、内部の演算処理は複数の「人工ニューロン」により行われる。ニューロンひとつひとつは入力と出力を持つ関数の役割を持ち、それらが複合的に組み合わさるわけだ。図3は、ネットワーク構成と人工ニューロンの内部処理を模式的に示したものだ。
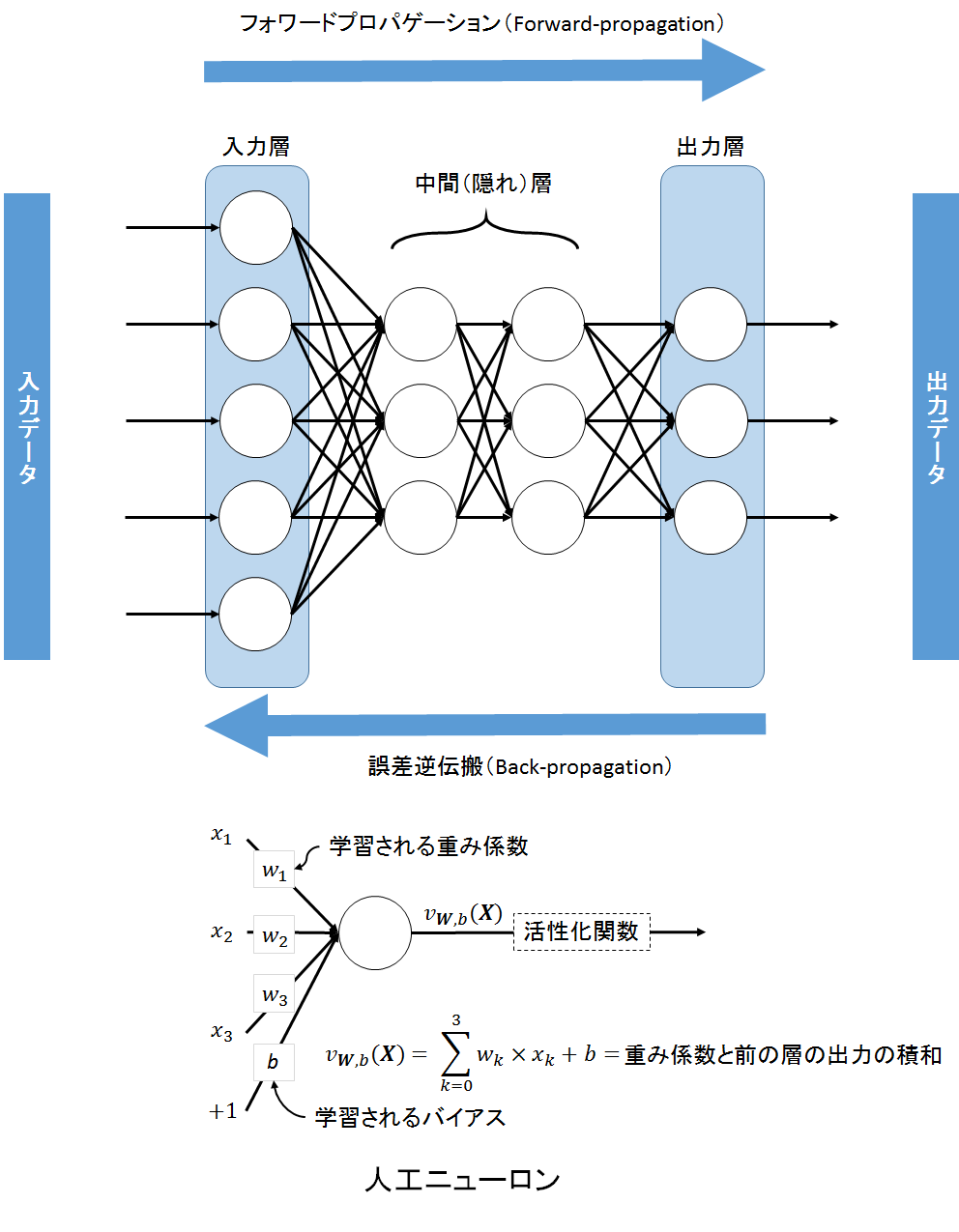
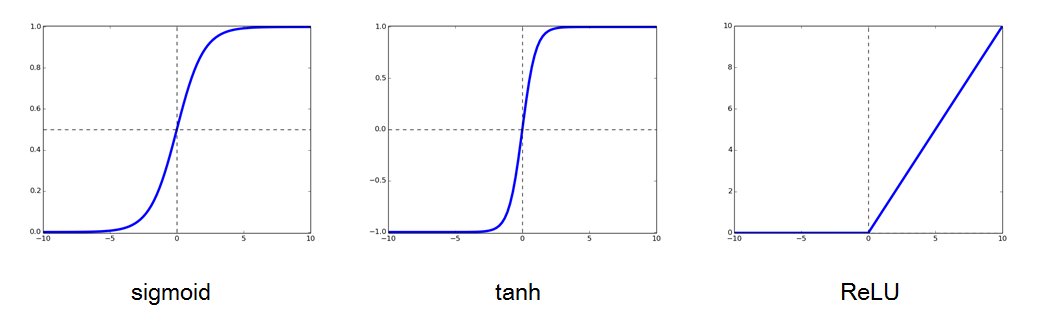
人工ニューロンは、前の層の出力に対して重みを掛けたものの総和を出力としている。ニューロンの出力値は活性化関数により制御され、非線形性が付加される。代表的な活性化関数を図4にまとめた。例えば、sigmoid関数やtanh関数を使って出力値を0から1もしくは-1から1に正規化することができる。sigmoidとtanh関数は、S字カーブのような形状で、入力が小さいうちは、あまり出力も大きくならないが、あるところから急激に入力に対する出力の増加が高くなり(勾配が急)、一定以上では飽和する。他にも、分類ではsoftmax関数がよく使われ、出力値を確率として解釈できるように0から1で正規化することができる。最近はRectified Linear Unit(ReLU)関数が学習の収束が早く、シンプルで人気がある。ReLU関数というのは、0以上の値だけをとり、それ以外の値はすべてゼロにするという区分線形関数だ。これらはいずれも単調増加型の関数であり、前の層のニューロンの出力と重みを乗算したものの合計値が大きくなるとニューロンが活性化する。この現象のことを、「ニューロンが発火する」と表現することもある。
ニューラルネットワークでは、入力データから出力データまで人工ニューロンを通して演算処理することを、順方向のデータ伝搬、フォワードプロパゲーション(Forward-propagation)と呼ぶ。逆に学習は、出力データから入力データまでの逆方向の情報伝搬のことを指し、誤差逆伝搬法(Back-propagation)と呼ぶ。学習の目的は、フォワードプロパゲーションしたときの出力データと目的とする理想的な出力データとの誤差を近づけることだ。
教師あり学習の場合は、学習に使用する入力データと正解データの誤差を誤差逆伝搬法により、逐次的に変数(重みやバイアス)を更新していく。つまり「学習」とは、データの出力誤差を重み(活性化関数も含む)で偏微分して、少しずつ最適な値へと調整する過程のことである。この学習に時間がかかるのは、入力から出力まで各学習データに対して順方向と逆方向に往復伝搬することを何万回と繰り返してたくさんの重み係数(一般的に数百万は下らない)を調整していくからだ。
ニューラルネットワークの種類
ニューラルネットワークには、問題に応じて特性の異なるモデルがいくつか存在する。ここではいくつかの主流なモデルについて簡単に説明する。

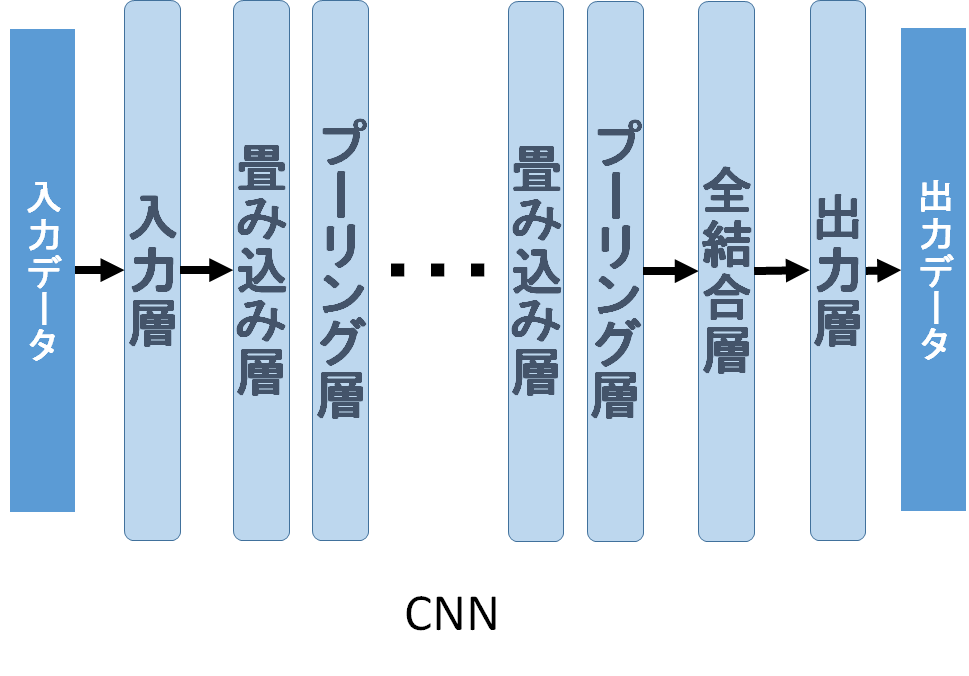
Convolutional Neural Network(CNN)は、主に画像や自然言語処理に使われており、特に画像認識分野での実用化は急速に進んでいる。中間層は主に畳み込み(convolution)層とプーリング(サブサンプリング)層を交互に繰り返すことでデータの特徴を抽出し、最後に全結合層で認識を行う(図6)。回帰の場合も同様だ。ここでのプーリングとは、局所的に最大値(max pooling)や平均値(average pooling)をとる処理のことで、局所的なデータの不変性を獲得することを目的としている。他にもプーリングの手法はあるが、この二つが最もよく使われている。通常2×2以上の領域を処理するため、次元数を減らす効果もあり、サブサンプリングとも呼ばれる。
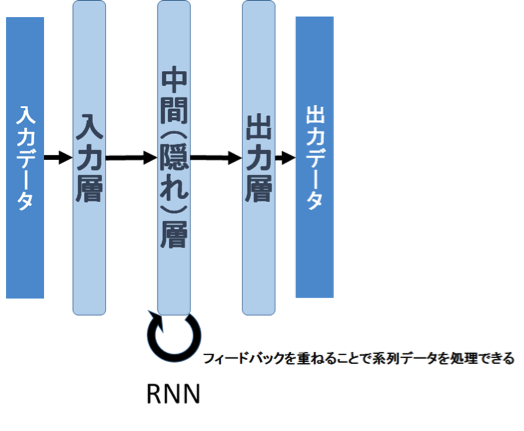
Recurrent Neural Network(RNN)は、時系列キーフレームを複数セットで解析する動画分類や、自然言語処理・音声認識での言語モデル、さらには強化学習によるロボットの行動制御などに使われる。現在、世界中のあらゆる研究機関がRNNに注目していて、ディープラーニングによる世界最先端の研究課題となっている。このモデルの特徴は、唯一中間層への自己フィードバックができる点にある。例えば、前時刻の層の出力を考慮して現中間層の出力を計算したり、次時刻の層の出力を考慮して現中間層へと両方向に情報をフィードバックしたりさせられる。三層が一般的だが、系列的に中間層のフィードバックを記憶できるため、系列データへの対応が可能だ。通常は三層分くらいの系列フィードバックを記憶して使う。他のネットワークとは違い、系列データへの対応と応用範囲が広いのが特徴だ。最近はLong Short-Term Memory(LSTM)と呼ばれるRNNモデルが、シンプルで学習も比較的簡単にできるために人気がある。
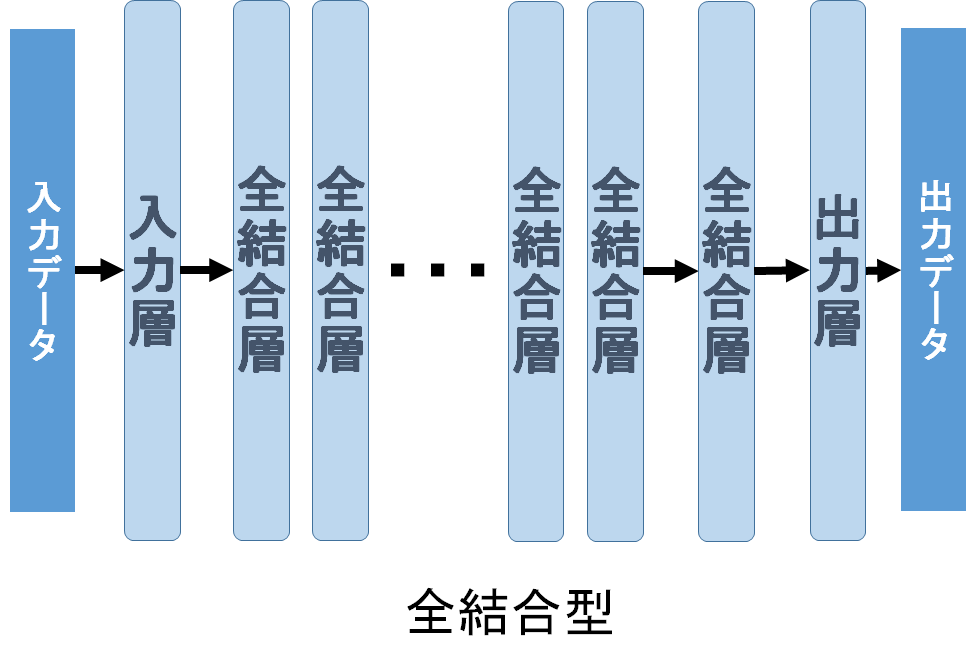
全結合型(フィードフォワード)は、主に音声認識で応用が進んでいる。これは、一見CNNと似ているが、中間層がすべて全結合層となっている点が異なる。すべて全結合層の場合は、パラメータ数も非常に多く、層数も十層に満たないのが一般的だ。
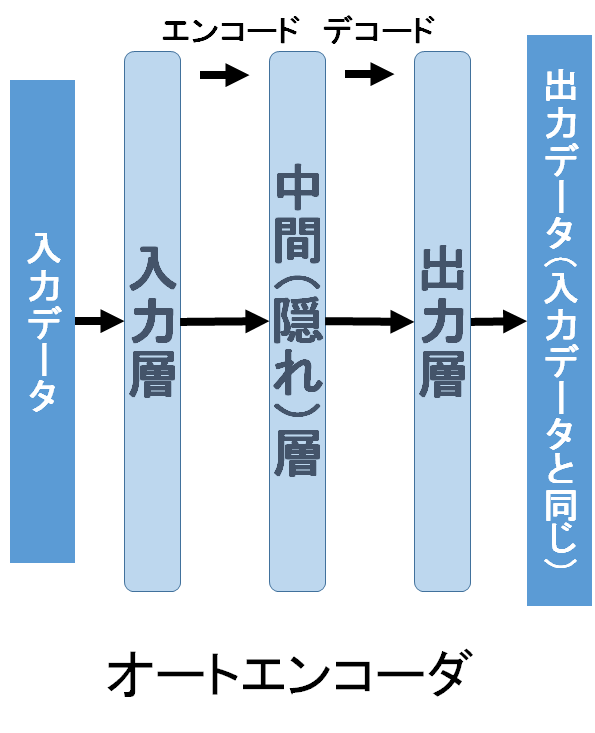
オートエンコーダはノイズ除去、次元削減などに有効なネットワークだ。その名の通り、入力データを再現(デコード)することが可能な低次元の特徴を抽出(エンコード)できる。中間層は全結合である必要はなく、数十層重ねることが多い。積層型オートエンコーダ(Stacked Autoencoder)は、中間層のエンコード部分を一層ずつ逐次的に加えて学習し、積み重ねていく。教師なし学習のため、入力データ自身を教師データとするところが、ここまで紹介した他のネットワークとは異なる点だ。
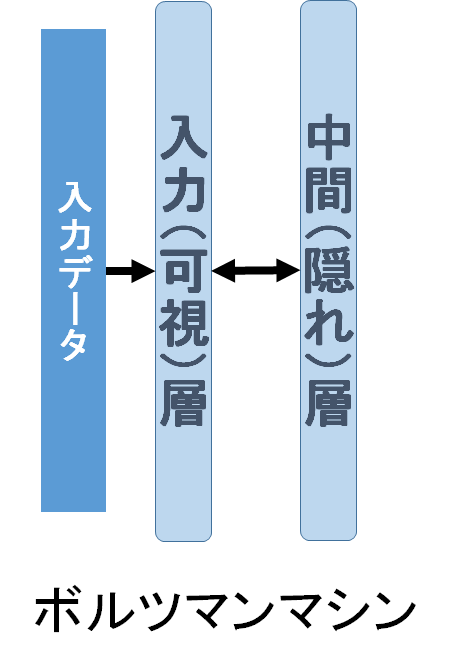
最後にボルツマンマシンだが、これはHinton教授が使用しディープラーニングが有名になるきっかけとなったネットワークだ。主に画像や音声認識などに適用できる。ネットワーク構成は、入力(可視)層と中間(隠れ)層が双方向で結合している。中間層の中の層同士の関係が確率モデルで記述され、入力データをうまく再現できるようになる生成型モデルだ。オートエンコーダとボルツマンマシンは、教師なし学習で特徴量を抽出させ、教師あり学習前の事前学習(pre-training)として使うこともある。事前学習の結果を使えば、特徴抽出部分の大半のパラメータをあらかじめ最適に近い値に初期設定することができ、ゼロからすべてのパラメータを学習する必要はない。このような事前学習は、ファインチューニング(fine-tuning)とも呼ばれ、効率的に学習を行う手段の一つとして有効だ。
ディープラーニング学習ツールの紹介
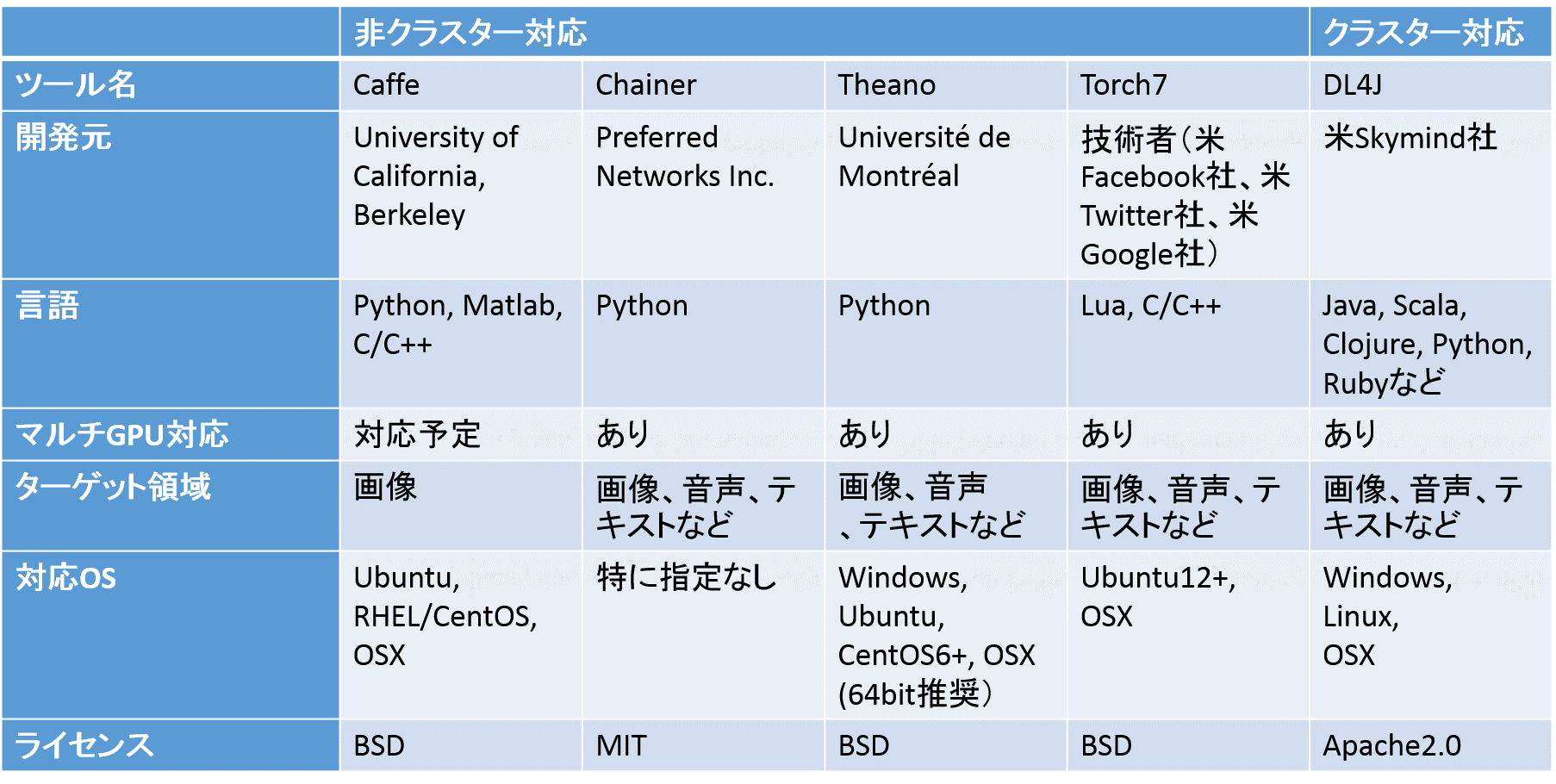
ここでは、特にこれからディープラーニングを始めたい人、実装して試してみたい人にとって便利なオープンソースベースの学習ツールを紹介する。Chainer以外はすべて米国から発信されている。世界で最も使われているのはCaffe、Theano、Torch7であり、それぞれコミュニティーも巨大だ。特にCaffeとTorch7は有名で、世界中の研究者、開発者が毎日のようにソース改良や機能追加に貢献している。
ChainerはPreferred Networks Inc.が開発し、今年の6月にオープンソースとして発表されたばかりだ。現在のところ、日本発信で唯一のオープンソース型学習環境だ。日本人を中心にコミュニティーも大きくなりつつあるが、ドキュメントもすべて英語で、はじめからグローバルの開発者をターゲットにしている。今後の発展に期待したいところだ。初心者には、ドキュメントが充実しているCaffeかTorch7、もしくはChainerが比較的使いやすいだろう。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
