はじめに
前回まで、2回に渡ってAIの利用形態が研究室からAI PaaS、そしてエッジAI、組込みAI、AIチップへと、より身近なところに広がり、AIがいたるところに存在する社会になりつつある状況をお伝えしました。今回は、引き続きハイプ・サイクルに登場するAI技術とその関連技術を取り上げて、AIの概要と変遷を理解していきましょう。
汎用人工知能
(AGI:Artificial General intelligence)
汎用人工知能は、2017年と2018年にハイプ・サイクルの黎明期に登場したキーワードです。この頃はAIが将来、人間を超えて脅威の存在になるという論調も多く聞かれており、「強いAI」と「弱いAI」という言葉もよく使われていました。囲碁や自動運転車など特定の分野にのみ力を発揮する特化型AIを「弱いA」と称し、人間のできるあらゆる知的作業をこなせる万能型AIが「強いAI」と呼ばれるものです。
この「強いAI」が汎用人工知能(AGI)です。私は「さすがにそんなの無理!」と思っていましたが、実際、AIの実用化模索が進む中で「過度の期待」が現実レベルに落ちたため、最近ではあまり聞かれないキーワードになってきました。ただ、個々の「弱いAI」が次々と実用レベルになるにつれ、それらを統集合して結果的に「強いAI」に見えるAIが登場する日は来るかも知れないと感じています。
深層強化学習
(Deep Reinforcement Learning)
2017年の黎明期に取り上げられた強化学習は、エージェントが報酬を最大化するために試行錯誤を繰り返して学習する手法で、ディープラーニング技術を使ったものが深層強化学習です。2016年に囲碁で韓国のトップ棋士に勝って一躍有名になったAIエージェント(ALPHA GO)は、深層強化学習によって鍛えられたものです。
深層強化学習は、試行錯誤により正しい行動を見つけ出すアプローチで、何百万回と繰り返し学習できるケースに向いたアルゴリズムです。例えば囲碁などではAI同士を果てしなく戦わせて、どの局面でどういう手を打ったら勝利(報酬)を得られるかを学びます。自動運転車のドライビング技術習得にも使われており、ソフトシミュレータで死ぬほど(AIは不死身ですが)運転を繰り返し、無事故(報酬)で運転する技術を身につけます。
転移学習(Transfer Learning)と
ファイン・チューニング(Fine Tuning)
2019年の黎明期に登場した転移学習は、少ないデータで学習する方法の1つです。これを説明する前に、そもそもディープラーニングがどういうもので、なぜ学習することによって賢くなってゆくかという原点から順を追って説明しましょう。
(1)ニューロンとシナプス
人間の脳は、図1のようにニューロンと呼ばれる神経細胞が無数にあり、ニューロンからシナプス(樹状突起)を介して次のニューロンにインパルス(電気信号)が伝わります。ニューロンからニューロンへ情報が伝達することをスパイク(発火)と呼びますが、伝達のしやすさ(結合強度)は1つずつ異なっています。
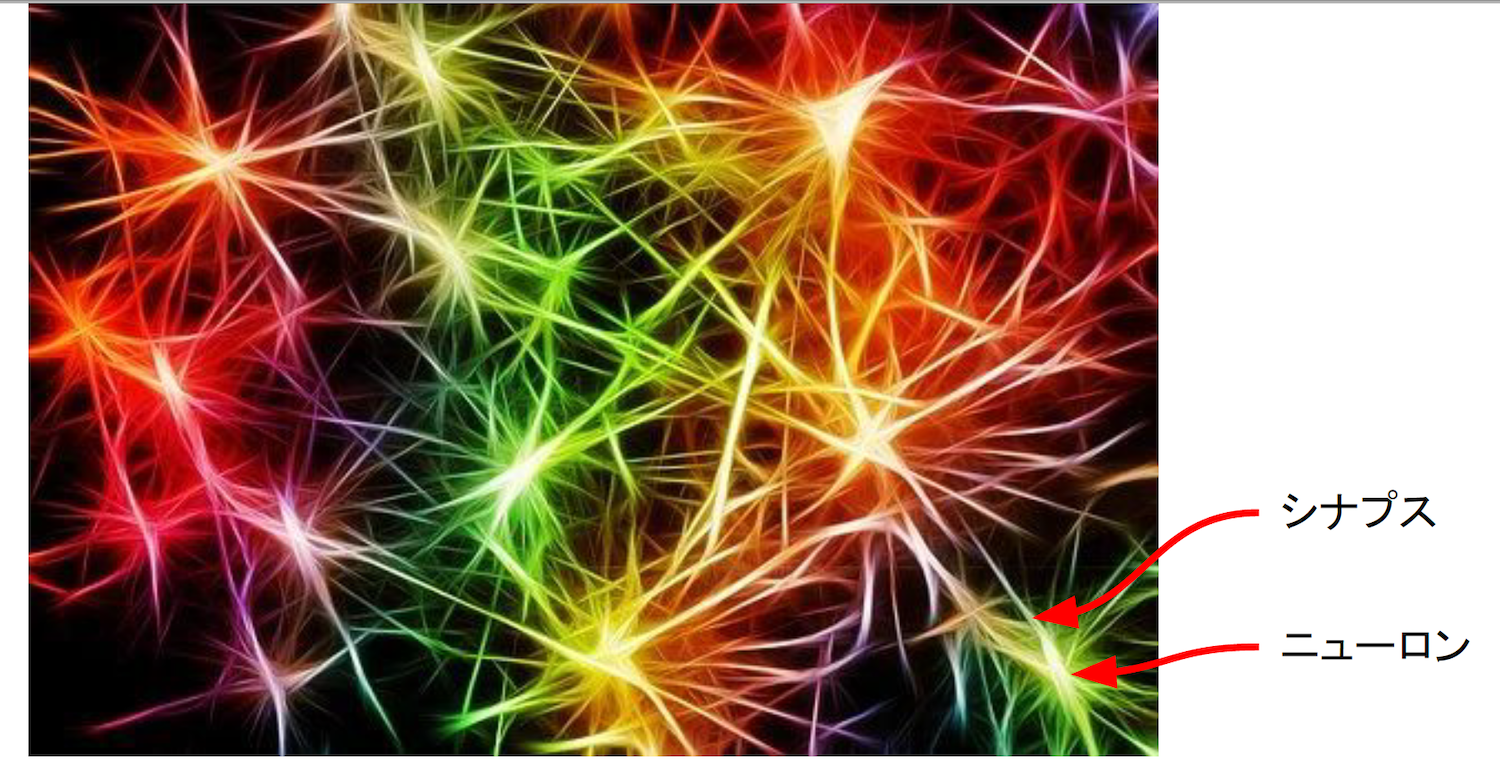
図1:ニューロンとシナプス
(2)ニューラルネットワーク
この脳の構造をモデル化したものがニューラルネットワークです。図2のようにニューロンを模した人工ニューロンを行列演算しやすいように層に並べて配置した構造で、層を数十から数百と増やしたものを深層学習と呼びます。一般に層が増えれば増えるほど推論精度は高まりますが、その分、学習に時間がかかります。シナプスと同じように人工ニューロンから人工ニューロンへ信号が伝わりやすさは1つずつ異なっていて、これをWeight(重み)と呼んでいます(図では線の太さで表しています)。

図2:ニューラルネットワークと誤差逆伝播
(3)誤差逆伝播
ところで、人工知能はどうやって頭が良くなっていくのでしょう。その基本原理が誤差逆伝播(ごさぎゃくでんぱ)です。例えば、図2は出力が2つの分類モデルで、バラかバラじゃないかを判定するだけのAIです。学習データとしていろいろな花の写真を5000枚用意し、その中にバラの写真が1000枚入っているとしましょう。ランダムに100枚ずつ抽出してAIを繰り返しトレーニングするのですが、最初のうちAIはバラをバラじゃないと判定したり、バラじゃない花をバラと判定したりします。
このトレーニングにおいて、間違った場合には重みを調整します。間違っては重みを調整、間違っては重みを調整、という処理をずっと繰り返すことにより、AIはバラを判定するのに最適な重み配置となります。これがAIが頭が良くなる仕組みです。間違い(誤差)を逆方法に伝播するので、誤差逆伝播(Backpropagation)と呼びます。
バラの代わりに製品の正常画像と異常画像を用意して学習し、異常か異常じゃないかを判定できるモデルを作るのが異常検知AIです。出力は2値とは限りません。例えば出力を500に増やしてバラや牡丹、菊など500種類の花を学習させれば、もっと多くの花を判別できるAIになります。異常検知においても異常を「キズ」「サイズ規格外」「色ムラ」「異物混入」など状態ごとに分類すれば異常発生原因の特定に役立ちますが、その分、学習の難易度は高くなります。
(4)転移学習
このように、ディープラーニングでは大量データを繰り返し学習することでニューラルネットワークの重み調整を行い賢くなります。しかし、大量データを用意して、繰り返し学習するのは容易ではありません。そこで、すでに別のところで訓練した学習済AIを持ってきて、大部分の重みバランスを凍結した状態で追加学習することで、少ないデータで短期間に学習できる転移学習(Transfer Learning)というテクニックが登場しました。
図3は、バラを判別できる学習済AIモデルを使って牡丹を見分けるAIを作るものです。通常の機械学習がイチから学習するのに対し、ここでは中間層の大部分の重みを凍結し、残りの少ない層のみで学習します。もともとバラを判別するのに適した重みとなっているので、似たような判別ならその重みバランスを利用して、少ないデータ、少ない回数で学習できます。
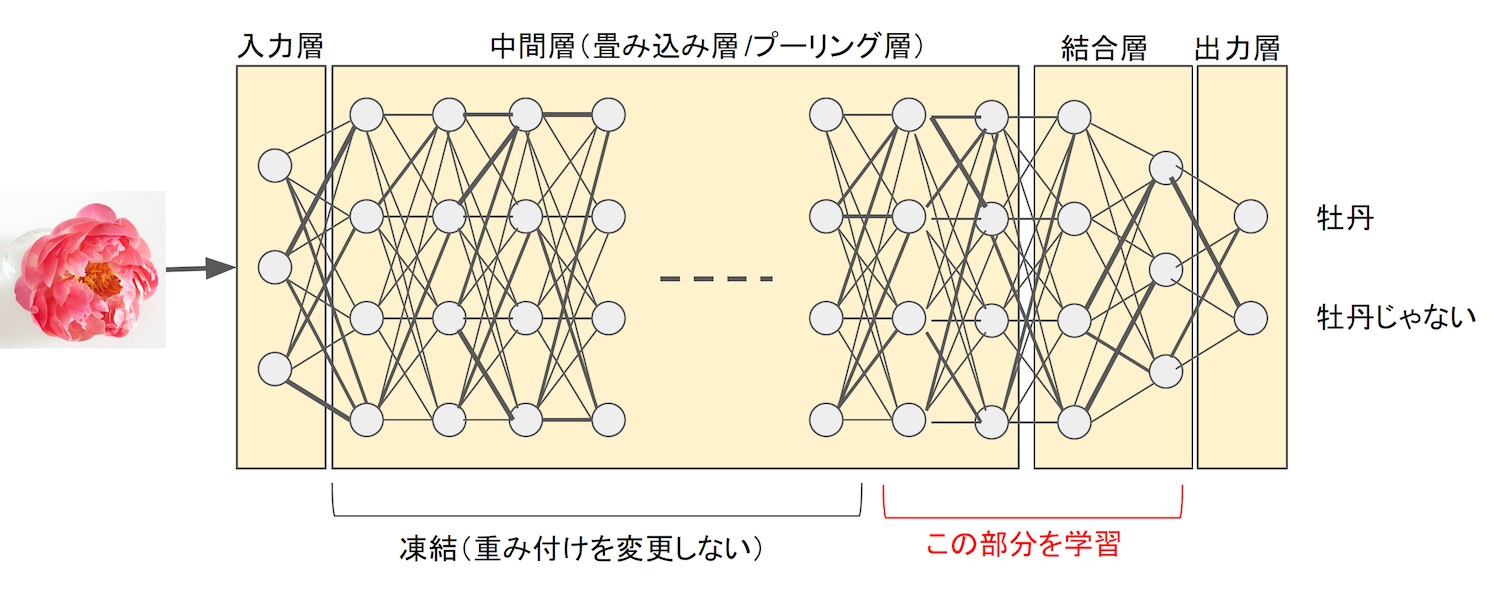
図3:転移学習
(4)ファインチューニング
転移学習は学習済モデルの重みを固定して学習していますが、類似性がそれほど高くないモデルを作る場合は逆にうまくいかない場合があります(Negative Transfer:負の転移)。そこで登場したのがファインチューニング(Fine Tuning)です。これは学習済モデルの重みを初期値として使い、そこから再学習をして重みを調整していく方法です。
(5)蒸留
知識の蒸留(Knowledge Distillation)についても説明しておきましょう。ディープラーニングは階層が深くてパラメータ数も多いモデルのほうが精度が高くなります。例えば、2010年から毎年行われた画像認識コンテスト(ILSVRC)の優勝モデルは、2012年は8層のCNN(畳み込みニューラルネットワーク)でしたが、2014年は22層、2015年152層、2016年は200超という具合に層が深くなっています。
ただし、階層が深くなればなるほど計算コストや消費電力が大きくなります。コンテストのような特殊目的なら良いのですが、実用には不向きであり、ILSVRCも本来の目的は達成したとの判断で2017年を持って終了しています。
前回、機械学習には学習プロセスと推論プロセスがあり、スマホなどに搭載する推論チップは小型軽量化、省電力化、低コスト化が必要と述べました。そのようなニーズに対応するために、層の深いモデルで得られた知識を軽量モデルの学習に利用することで、軽量なのに高い精度を得られる蒸留というテクニックが考えられました。
蒸留は、図4のようにTeacherが学習して得られた知識(Knowledge)をStudentの学習に使います。知識をそのまま適用して完成とする方法もありますが、通常は知識を適用した後で追加学習を行います。何を知識とするかはいろいろなモデルが次々と考えられていて、AIの実用化を背景に蒸留はホットなテーマの1つです。転移学習やファインチューニングが同じモデルなのに対し、蒸留は重量モデルから軽量モデルに適用する技の総称で、具体的な方法には多数があると覚えておいてください。
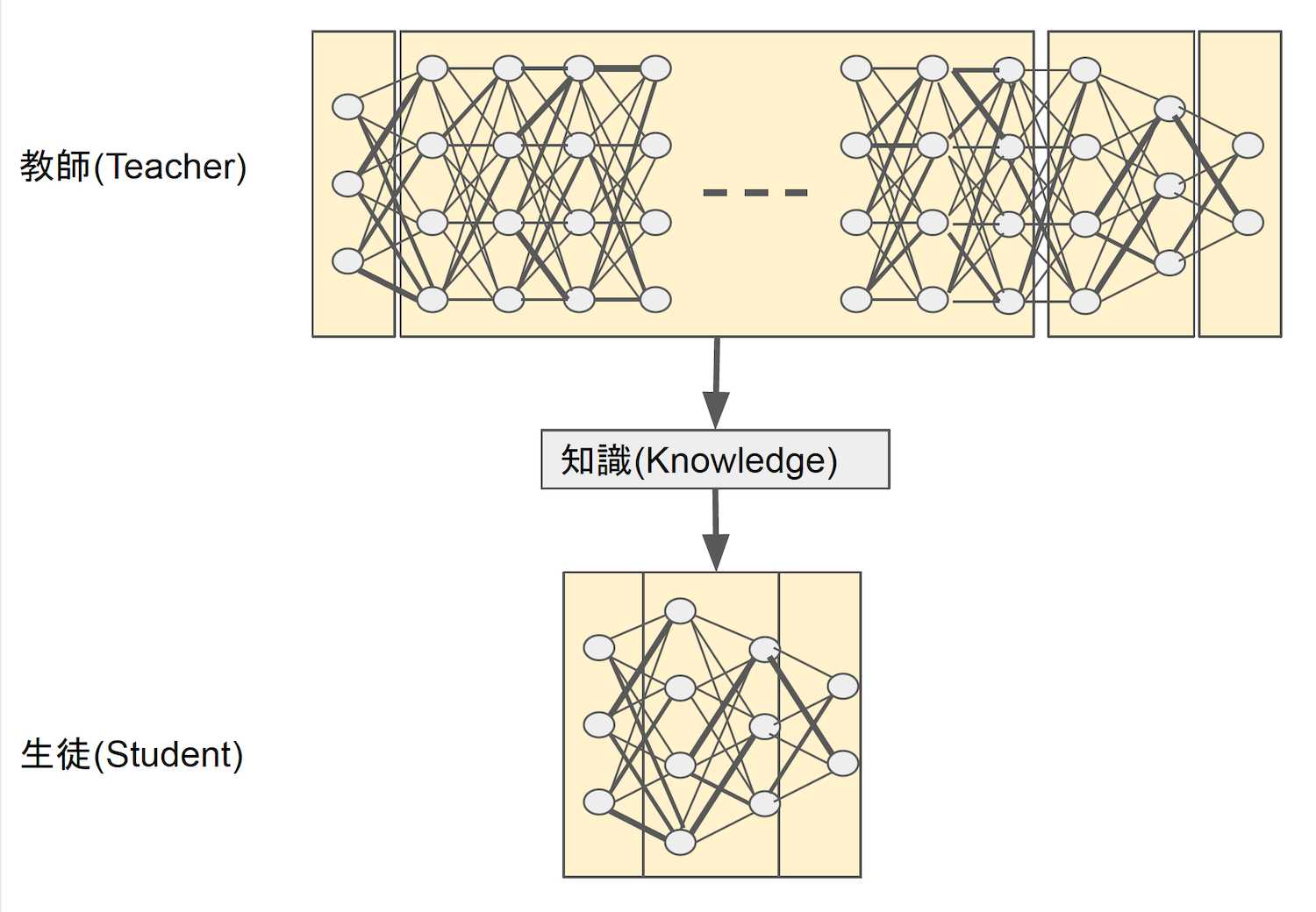
図4:蒸留(Knowledge Distillation)
説明可能なAI(Explainable AI)
説明可能なAIは、2019年と2020年に過度な期待のピーク期としてハイプ・サイクルに登場しています。統計的手法による従来型の機械学習モデルは、どのような計算やしきい値でAIが結論を出したかがわかります。一方、ディープラーニングは基本的にブラックボックスです。子どもがどのように考えて犬と猫を見分けているか脳の中がわからないように、犬と猫を見分けるトレーニングしたAIがどうして判別したのか普通はわかりません。
しかし、AIは幅広く社会に使われるようになってきましたが、ブラックボックスのままでは重要な役割を任せるわけにはいかないと考える分野もあります。例えば医療でなぜAIがそのような判断をしたかわからないまま治療を行い、もし悪い結果となった場合に責任が取れないわけです。この壁を乗り越えるために、AIがどのようなデータをどのように判断したかを、できる限り見える化する仕組みを用意したものが説明可能なAI(XAI)です。
例えば、グーグルは2019年にGCP(Google Cloud Platform)のサービスとして説明可能なAI(Explainable AI)を提供開始しました(β版)。例えば犬と猫を見分ける画像認識AIであれば、説明可能AIは画像のどの特徴量をどれくらい判断に使ったか(スコア)をヒートマップや数値で示してくれます。異常検知であれば、AIがどの部分を見て異常と判断したかをヒートマップで示すことで、人間が「本当に異常かどうか」を最終確認するのに役立ちます。
おわりに
今回はハイプ・サイクルに登場する技術をきっかけに、ディープラーニングの基本について説明しました。基本的なところは3年前と大きくは変わっていませんが、AIが研究室レベルから身近で使うものとなるにつれて注目度が高まっているファインチューニングや蒸留、説明可能AIなどの技術は覚えておいてください。
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
