はじめに
世の中は、とんでもないAIブームですね。「猫も杓子も」というと言い方が悪いですが、誰も彼も「AIを使えば」という魔法の呪文を唱えて、夢みたいなことを熱く語っています。こうしたブームに乗っかる人を「ドワゴン」(ワゴン車に乗ってラッパや太鼓をブカブカドンドン打ち鳴らしている連中)と呼ぶそうですが、「同じ阿呆なら踊らにゃ損々」とも言います。せっかくの機会に何もしないで傍観しているのもつまりません。
どうやらAIは単なるブームではなく、インターネットに匹敵する技術革新のようです。今、AIワゴンに乗らないことは3年後、5年後のビジネスにおいて大きなリスクと言えるでしょう。そのため、ここらで一度AIについてきちんと理解し、積極的にAIに関わって行きましょう。え、「今さら遅いよ」ですって? いやいや、まだ大丈夫です。AIの進化は著しく、昨日までの知識は瞬く間に古い歴史になってしまうので、今から飛び乗っても十分にキャッチアップできます。
ビジネスに活用するためのAI
ドワゴンでなくても、それなりにAIの本を読んだり、記事を読んで勉強したりした人も多いでしょう。でも、AIについて語られている文書の多くは、最初に第1次AIブームからの歴史物語やディープラーニングの仕組みなどの解説が出てきます。
歴史や原理を知ることが無駄というわけではありません。でも、ニューロンネットワークの原理を知ったからといって、今からその仕組みを作るわけではありません。Facebookの顔認証、OK Googleのパーソナルアシスタント、YouTubeのレコメンド、Amazon Echoなど、AIは既にさまざまな分野で実用化されています。非常に残念ながら、日本はこれらのAI要素技術でも遅れを取ってしまいました。
CPUやOS、ミドルウェアの作り方を知らなくても、コンピュータを使ってビジネスに役立つアプリケーションは作れます。同じように要素技術で後追いする代わりに、AIを使ってビジネスに役立つアプリケーションを作ることにフォーカスしましょう。アプリケーションはこれから大きく花開く市場ですし、日本の得意な分野です。これから5年後、10年後のAI市場拡大を考えれば、今の差はまだ小さいと言えます。現在は”周回遅れ”にいますが、このままずるずると後退するか、盛り返して先頭集団に追いつくかの分岐点が、まさに”今”なのです。
本連載の方針
さて、本連載では、「AIのことをなんとなくしか知らなかった人が、パッと全体像を把握できて、今何が起きていて、これからどうなりそうかイメージできる」ことを目指して書き進めます。分かりやすく「ドクターX」ライクでお伝えすると次のような感じです。
- ディープラーニング以前のAIの歴史について説明する……………「いたしません!」
- ニューラルネットワークの仕組みについて解説する………………「いたしません!」
- AIライブラリやAIプラットフォームの利用方法を解説する………「いたしません!」
- ベンダ発信のデータを元に、どちらが優れているか比較する……「いたしません!」
- AIが人間の仕事を奪って不幸をもたらすかの道義的論争…………「いたしません!」
でも、こうなると「じゃあ、何を書くんだよ!」と言われてしまいそうですね。本連載で取り上げる主な内容は、下記の3つです。
- ディープラーニング登場以降の5年間の流れを知り(過去)
- 現在のAI技術の全体像を把握し(現在)
- 5年後のAI活用イメージを想像する(未来)
上記で「いたしません!」とした解説は巷にあふれていますし、米国などの後追いの内容です。1周遅れのレーンをなぞっていたらいつまで経っても先頭には追いつけません。人は近未来の物語より、歴史物語や時代小説が好きです。無理にどうなるかわからない未来を想像するよりも、過去は安心であり癒しだからです。でも、ビジネスにおいて大事なのはこれからの展望です。未来をきちんとイメージできれば、そこに向けてやるべきことが見えてきます。
とは言っても、現状を大局的に理解していなければ正しい未来予測などできません。そこで本連載は2部構成とし、まず第1部で現在のAIの全体像を理解し、続いて第2部でこれからのAIについて大真面目に語っていきます。
AIの書物を読んで”ふんふん”とわかった気になったり、Google TensorFlowのチュートリアルでニューラルネットワークの仕組みを体感したりと、そんなふうに”つまみ食い”的にAIをかじっている人がたくさんいます。もちろん、新しい技術と出会う時は、そんなところからスタートするものなので、それは悪いことではありません(筆者の会社でも同じようなところからスタートしました)。
でも、そろそろ用意されたチュートリアルをやるといった受け身の学習ではなく、AIを使って何ができるかを考え、そのアプリケーションを実現するためのスキルアップやサービス作りという前向きな姿勢でAIに関わることにしましょう。
その第一歩として、今のAIの全体像を少し遠くから眺めてみます。AIのライブラリやプラットフォームにはどのようなものがあり、その上にどのような技術分野でAIが活用され、それらを応用してどのようなアプリケーションが続々と生まれているのか。そうした全体像を把握して、初めて「自分なりにどうAIと関わるべきか」という方向性が見えてきます。
図1は、現在のAIの全体像を階層別に示したものです。最下層にニューラルネットワークの高速処理を支える「ハードウェア(処理チップ)」があり、その上層にニューラルネットワークの処理を行うためのライブラリがいろいろと誕生しています。さらにその上層にこれらのフレームワークを使って目的別に開発されたAIサービスを提供するAIプラットフォームが各社から提供されており、これまたものすごいスピードで進化を続けています。
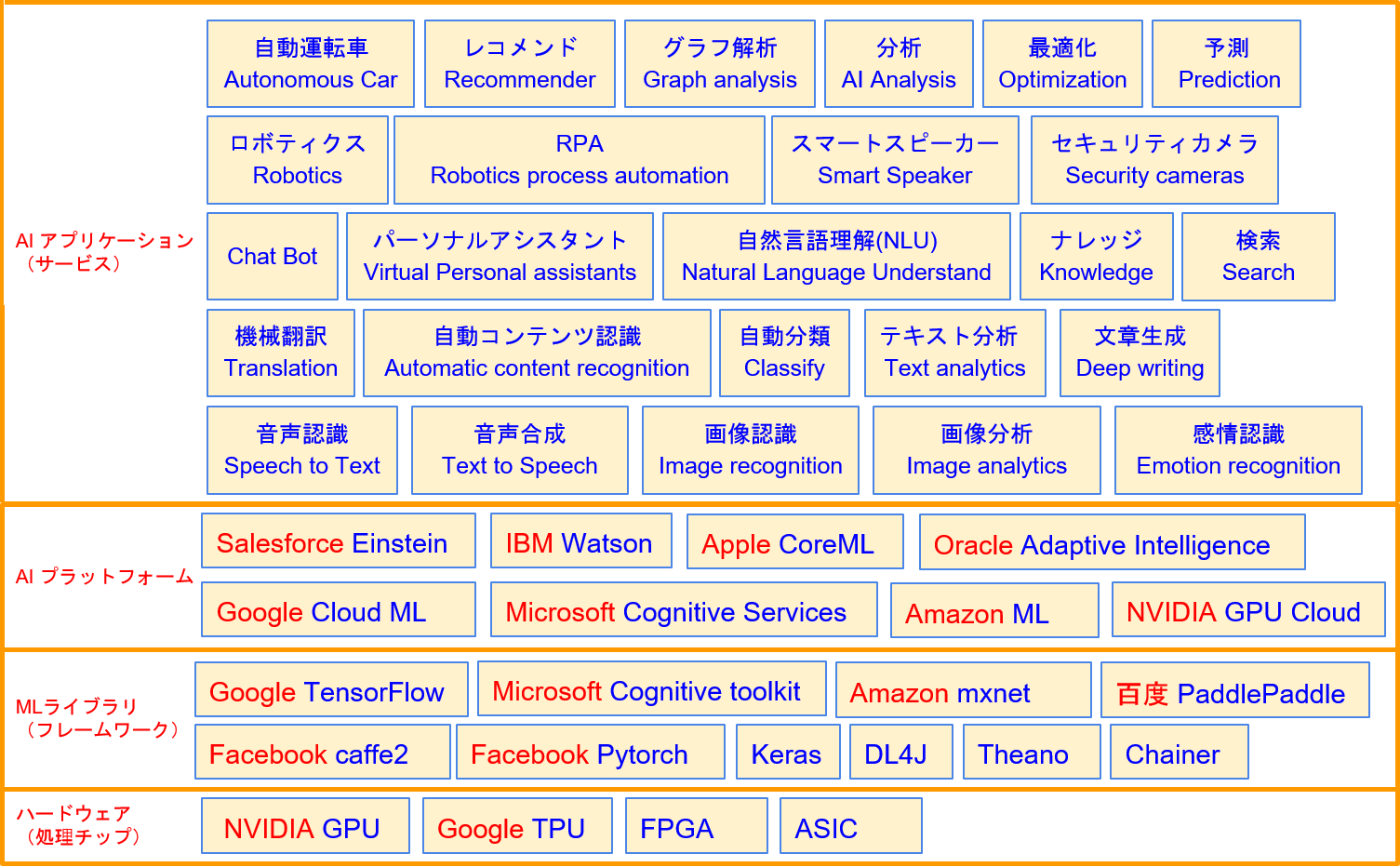
図1:AIの全体像(Overview)
こうしたAIプラットフォームが充実することで、人々はニューラルネットワークの基礎技術に入り込まなくてもAIを利用できるようになってきています。今のところAIライブラリを使いこなしたアプリケーションが多いですが、AIプラットフォームに乗ったサービスも続々と増えています。
図1ではひとまとめにしていますが、AIアプリケーション・サービスはさらに細かく3つの階層に分けられます。下層は音声認識や画像認識、機械翻訳といった単一要素のアプリケーションで、それぞれ進化が著しく実用レベルに到達しているものも多くあります。中間層はパーソナルアシスタント、ロボティクスなど、単一要素のアプリケーションを組み合わせたより高度なアプリケーションです。このように、最近のAIは複数のAI技術を組み合わせたものが多く、より人間に近いレベルに到達しています。
そして、上位層に位置づけられるのが、ビジネス活用AIアプリケーションです。医療や教育、製造業、小売業、農業など、さまざまな事業分野において今まさに世界中の企業が取り組んでいます。
2012年にGoogleがディープラーニングを使って猫の画像認識に成功してから、AIはビッグバン(大爆発)を起こし、今もなお急速に膨らんでいます。火山の大爆発をイメージしてみてください。下層から噴き出した噴煙は、今もまだすごい勢いで膨らみ続けている最中です。そして中・上位層がばっと大きく広がってきている超膨張がまさに今なのです(図2)。

図2:AIビッグバン(今の状態)
本連載では、これからもますます大きく広がる中・上位層(AIのビジネス活用)を中心テーマとします。AIについて学ぶだけでなく、自分の頭を使って携わっている業務、得意分野へのAIの活用を一緒に考えていってください。
ディープラーニングによるAI革命
第1次、第2次AIブームはさておき、この先を見通すために今回(第3次)のAIエクスプロ―ジョン(爆発)以降の流れについては抑えておきましょう。図3、図4はこの5年間のAI関連の主な出来事を時系列に並べたものです。これを見ると、年々活性化していること、ここにきて急速に加速していること、そして、まだここ数年のことでしかないことが分かると思います。

図3:ディープラーニング以降のAI(2012~2015年)
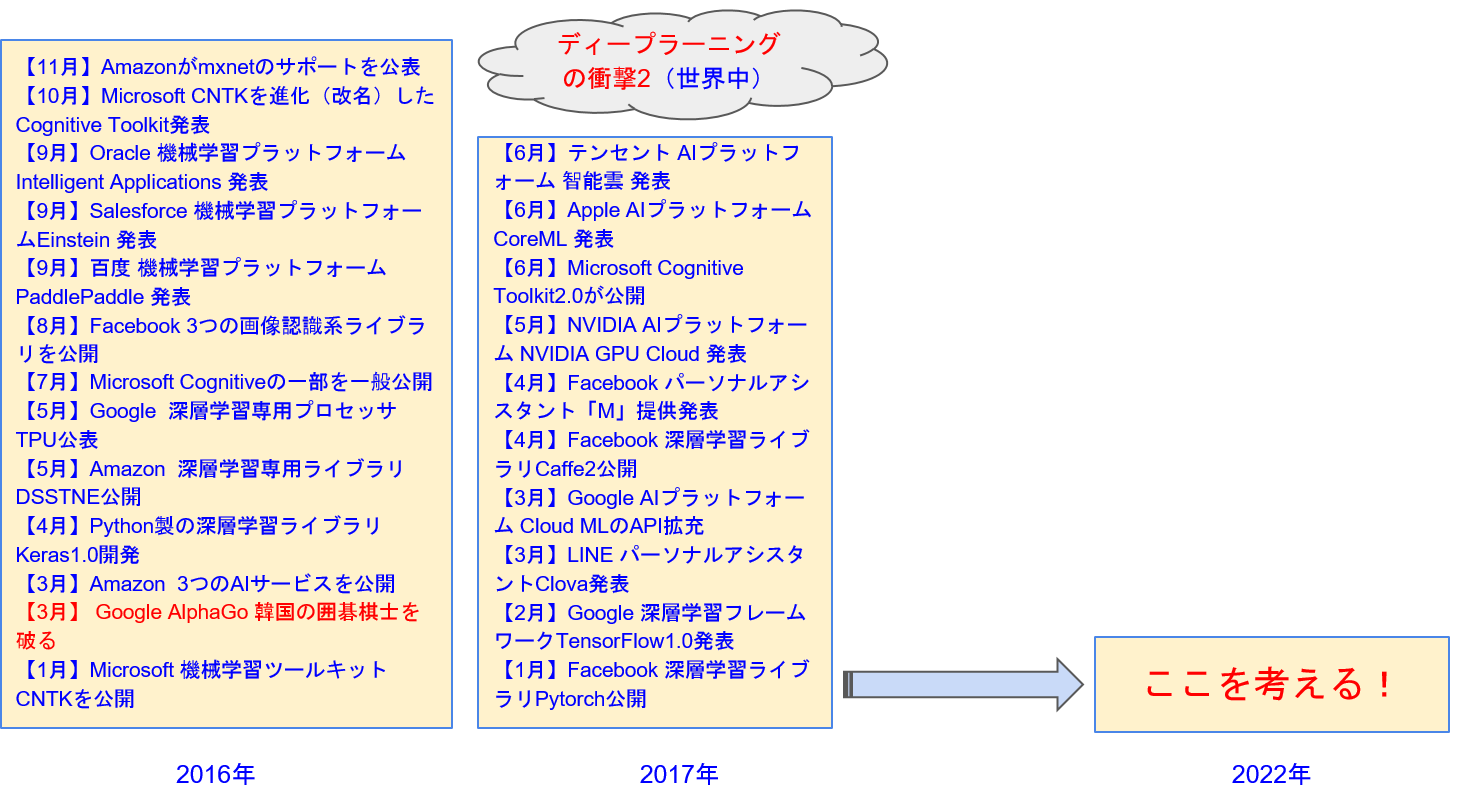
図4:ディープラーニング以降のAI(2016~2017年)
今回のディープラーニングによるAIブームは2012年に始まりました。この年、そのきっかけとなった出来事が2つあります。1つはGoogleがディープラーニングを使って猫の画像認識に成功したこと、もう1つはカナダ・トロント大学のGeofferey Hinton教授のチームが画像認識コンテスト(ILSVRC:ImageNet Large Scale Visual Recognition Challenge)でディープラーニングを使い、圧勝したことです。
この2つの出来事はとても大きな話題にもなり、それまでAIを研究してきた機関はもちろんのこと、さまざまな企業や大学でAIを新たな飯の種にしようというきっかけになりました。
そして、2016年に噴煙を加速する爆発が起きました。Google AlphaGoが韓国の囲碁トップ棋士イ・セドル氏を負かした出来事です。このニュースはまたたく間に世界中を駆け巡り、今では近所のおじさんでさえAIのことを話題にするようになりました。
主なイベントを詳細に見ていくと、最初(2012年の少し前くらいから)は大学などでさまざまなディープラーニング(ニューラルネットワーク)関連のライブラリが作られていたこと、直近の2年くらいでビッグカンパニーがAIを利用しやすい統合サービスにしたAIプラットフォームを提供している状況がわかります。
そして、この図には書いていませんが、いろいろな会社がこれらのライブラリやプラットフォームを利用して、よりミッションクリティカル(用途を限定した)なAIプラットフォームを提供したり、実用レベルのアプリケーションを続々と作って世に出したりしているのが現在です。
本連載ではこのアプリケーション部分にスポットライトを当て、AIのビジネス活用を考えていくわけですが、真の目的は図の一番右にある5年後です。5年後にどのような形でAIが社会に溶け込んでいるかを想像し、それを実現するキャストの中に自分も加わろうというのがメインテーマです。
先を急ぎたいところですが、良い発想をするためには基礎知識が大事です。今回は、まず、未来のAIアプリケーションを考える上で、それを支えるAIの要素技術について抑えておきましょう。
3分間でわかるディープランニング基礎
最初に、ごく初心者向けにディープラーニング(深層学習)の基礎のキソを簡単に説明しておきます。
(1)機械学習とディープラーニング
機械学習は古くからあるAIの手法の1つで、機械に学習させて人間と同じような認識、判断を行わせるものです。機械学習では最初に訓練データを用いて学習器に学習させ、できた学習モデルを使って未知のデータを判断・推定します(図4)。
ディープラーニングも機械学習の1つであり、学習モデルの構造が違うだけで処理の流れは同じです。ニューラルネットワーク(人間の脳モデルをシミュレートした数学モデル)を多層(ディープ)にして学習させる手法を用いているためディープラーニング(深層学習)と呼ばれています。
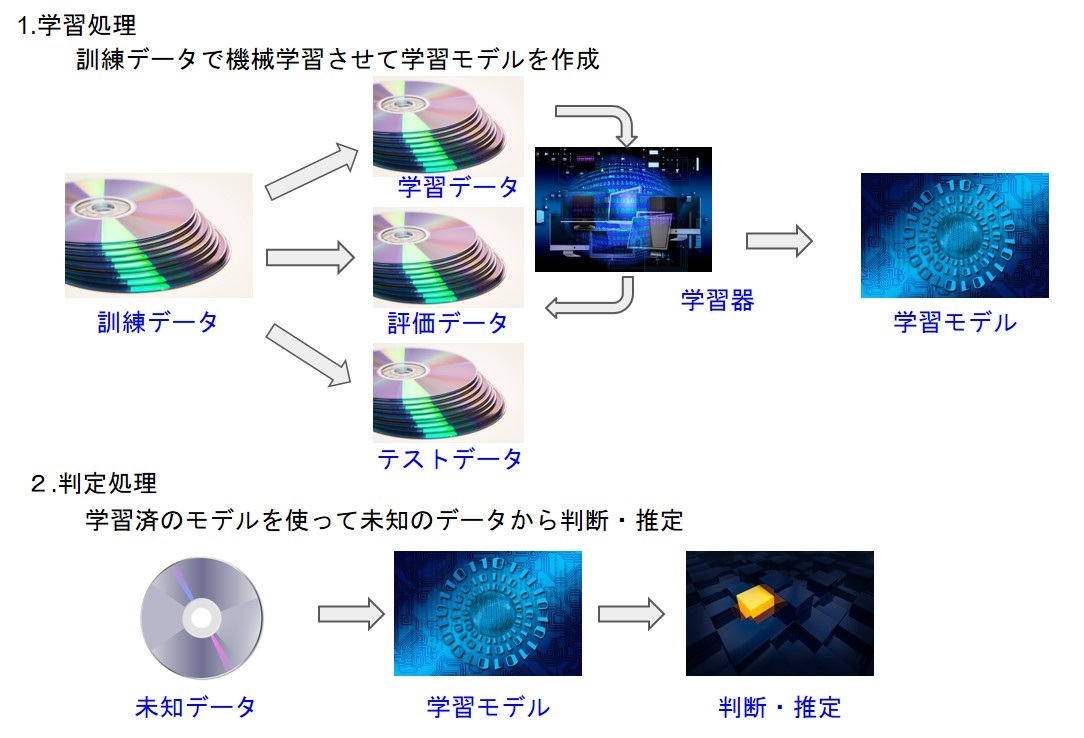
図5:機械学習の仕組み
(2)学習の繰り返しと「過学習」「ノイズ除去」
例えば10万件の訓練データが用意されていた場合に、それを全部学習(トレーニング)に使ってしまうわけではありません。例えば7万件を学習データ(Traning Set)として使用し、2万件を評価データ(Validation Set)、1万件をテストデータ(Testing Set)というように振り分けます。
機械学習の訓練フェーズでは学習データを使ってトレーニングを行い、評価データをもとに上達ぶりをチェックしてパラメータ調整を行います。訓練はデータを1回流して終わりではありません。何回も流すことによって、”さっきまでわからなかったけど、今ならわかるよ”と学習器が賢くなっていくので、上達がサチる(飽和する)まで繰り返し学習を行います。
ここで気をつけておかなければならないのが「過学習」と「ノイズ」です。特定の学習データで何回も訓練を行うと、その特定の学習データにだけ強い学習モデルになってしまい、逆にその他の汎用データに対する精度が落ちてしまいます。また、学習データに変なデータが多く含まれても精度が落ちてしまいますので、予め大量データの中からノイズとなるゴミデータを取り除く必要があります。
こうしてできた学習モデルの汎用性を確認するためにテストフェーズ用のデータを使い、汎用的な未知のデータでもきちんと実力を試せるものになったかを確認します。当然ながら学習モデルの精度は評価データではなくテストデータでの数値で測らなければなりません。
(3)「教師あり学習」と「教師なし学習」と「強化学習」
ディープラーニングには「教師あり学習」と「教師なし学習」と「強化学習」があります。例えば、画像の中から猫を認識する場合、様々な写真(訓練データ)の中から猫の写真だけに「猫」という正解ラベルを付けて学習させるのが「教師あり学習」です。
実は、2012年にGoogleが猫の認識に成功した出来事は「教師なし学習」でした。Web上のランダムな画像や動画をラベルなしで1週間読み取り、AIが自律的に猫を認識するようになったというので衝撃だったのです。これは幼児が毎日いろいろなものを見るうちに、自然と「こういうものが猫か」と認識していくのに似ています。
そして2016年に囲碁の名人を破ったAlphaGoは「強化学習」で強くなりました。教師あり学習と似ていますが、正解を与える代わりに”将来の価値を最大化する”ことを学習するモデルです(バンディット・アルゴリズムと言います)。碁のように必ずしも人間に正解がわかるわけではない場合でも学習できるので、人間を超える力を身につけることが期待できます。
現在のディープラーニングはほとんど教師あり学習です。でも、教師なし学習は、いちいち正解ラベルを付けずに済むため大量データを扱いやすく、自律的に特微量を見つけ出して人間の想像を超えた結果を引き出してくれるという期待があります。データマイニングなどの分野で驚くような成果が発表される日も近いでしょう。
最近、多くの人に期待されているのは強化学習です。中でもディープラーニングとQ学習を組み合わせたDQN(Deep Q Network)は今もっとも注目されているアルゴリズムです。目先の利益よりも最終的に勝つことを目的としたゲームや株取引などで”勝つ”ためのAIに向いています。試行錯誤を繰り返すうちに高い能力を身につけられる強化学習は、まさに「AI的なAI」であり、これから大きく発展すると思います。
さて、基礎のキソとしてのディープラーニングの解説はこの程度にしておいて、残りはキーワードが出てきた都度説明します。次回からは、図1の下層から順番にAI活用を実現する要素を解説していきます。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
