パーセプトロンを実装する
パーセプトロンを実装する
さて、以上の数式をプログラムで記述してみましょう。2.2 節「パーセプトロンの学習アルゴリズムをPython で実装する」では、クラスを用いてパーセプトロンを実装しています。ここでは、より簡単に実装してみましょう。
まずは、本書と同様の方法により Iris データセットを読み込みます。
In [1]: %matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['savefig.dpi'] = 180
In [2]: df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/' \
'iris.data', header=None)
df.tail()
Out[2]: 0 1 2 3 4
145 6.7 3.0 5.2 2.3 Iris-virginica
146 6.3 2.5 5.0 1.9 Iris-virginica
147 6.5 3.0 5.2 2.0 Iris-virginica
148 6.2 3.4 5.4 2.3 Iris-virginica
149 5.9 3.0 5.1 1.8 Iris-virginica
In [3]: y = df.iloc[0:100, 4].values
y = np.where(y == 'Iris-setosa', -1, 1)
X = df.iloc[0:100, [0, 2]].values
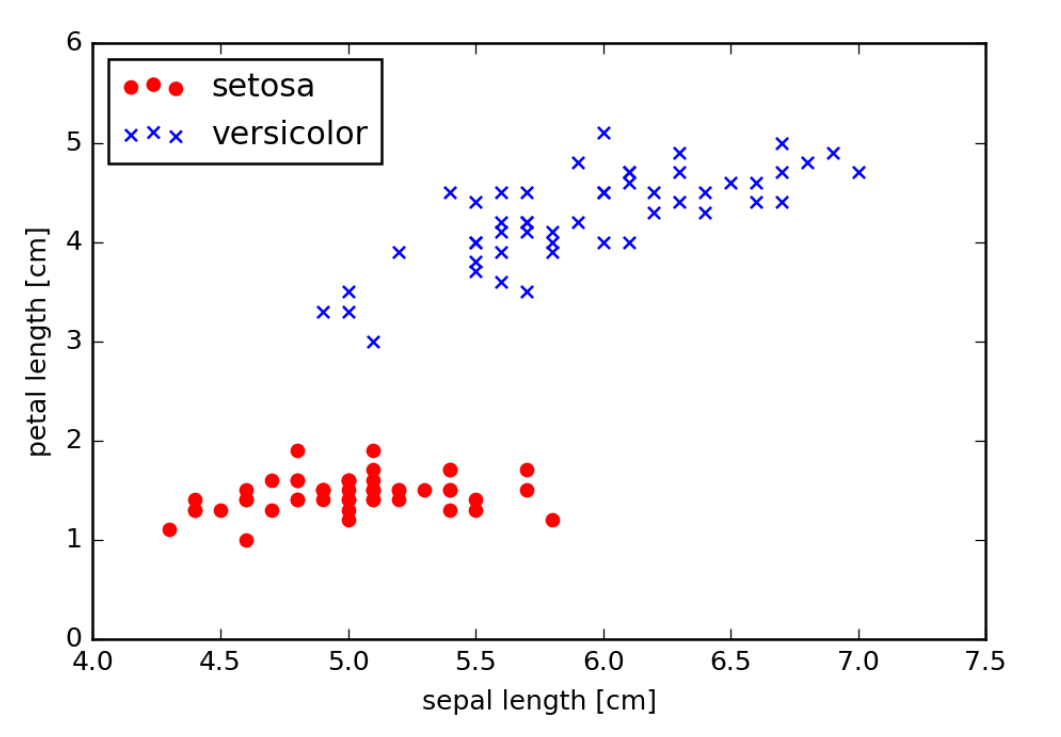
散布図をプロットすると次のようになります。
In [4]: # 品種setosaのプロット(赤の○)
plt.scatter(X[:50,0], X[:50,1], color='red', marker='o', label='setosa')
# 品種versicolorのプロット(青の×)
plt.scatter(X[50:100,0], X[50:100,1], color='blue', marker='x', label='versicolor')
# 軸のラベルの設定
plt.xlabel('sepal length [cm]')
plt.ylabel('petal length [cm]')
# 凡例の設定(左上に配置)
plt.legend(loc='upper left')
# 図の表示
plt.show()
パーセプトロンを以下の方針で実装してみましょう。
- 学習率 η:ここでは、 η = 0.01 と設定します。変数名は eta とします。
- 反復回数 N:ここでは、N = 10 と設定します。変数名は n_iter とします。
- 重み w0、w1、w2:本書内では NumPy 配列を使用していますが、ここでは変数 w0、w1、w2 を定義して、それぞれを 0 で初期化することにします。
In [5]: import numpy as np
eta = 0.01 # 学習率
n_iter = 10 # トレーニングデータのトレーニング回数
w0 = w1 = w2 = 0 # 重みを初期化
w0_, w1_, w2_ = [], [] ,[] # 重みを格納するリスト
errors_ = [] # 誤差を格納するリスト
for epoch in range(n_iter): # トレーニング回数分トレーニングデータを反復
errors = 0
for xi, target in zip(X, y): # 各サンプルで重みを更新
# 総入力の計算
net_input = w0 + w1 * xi[0] + w2 * xi[1]
# 総入力が0以上の場合は1、0未満の場合は-1と予測
pred = np.where(net_input >= 0.0, 1, -1)
# 重みを更新
update = eta * (target - pred)
w1 += update * xi[0]
w2 += update * xi[1]
w0 += update
# 誤差を算出
errors += int(update != 0.0)
# 重みを格納
w0_.append(w0)
w1_.append(w1)
w2_.append(w2)
# 誤差を格納
errors_.append(errors)
上記のソースコードは、2.3 節でクラスを用いて実装されているパーセプトロンのエッセンスのみを実装しています。Python のクラスにあまりなじみのない方は上記のコードで処理の流れを把握して、2.3 節の実装を確認すると良いでしょう。
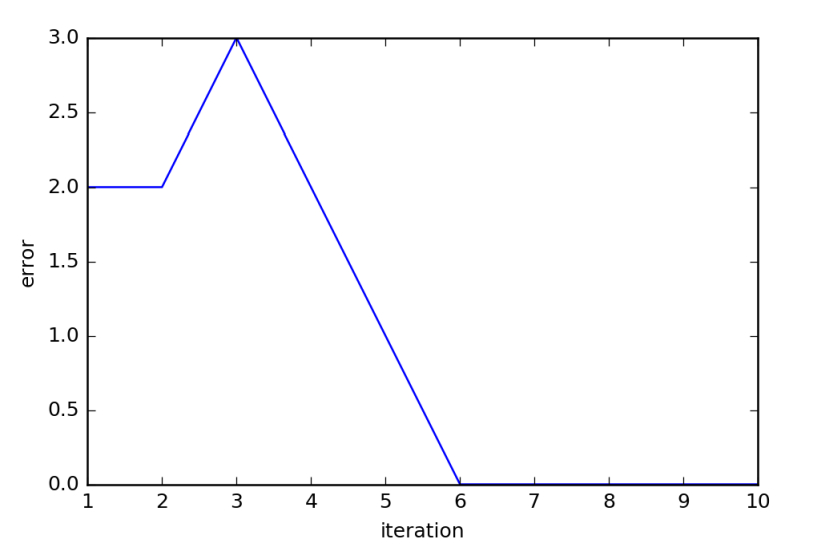
以上のコードを実行した結果、各反復の完了時点での誤差をプロットすると以下のようになります。6 回目の反復で収束していることを確認できます。
In [6]: # 各反復での誤差をプロット
iters = range(1, n_iter+1)
plt.plot(iters, errors_)
plt.xlabel('iteration')
plt.ylabel('error')
plt.show()
重み w0、w1、w2の変化をプロットすると次のようになります。
In [7]: plt.plot(iters, w0_, c='blue', label='w0')
plt.plot(iters, w1_, c='red', label='w1')
plt.plot(iters, w2_, c='green', label='w2')
plt.legend(loc='best')
plt.show()
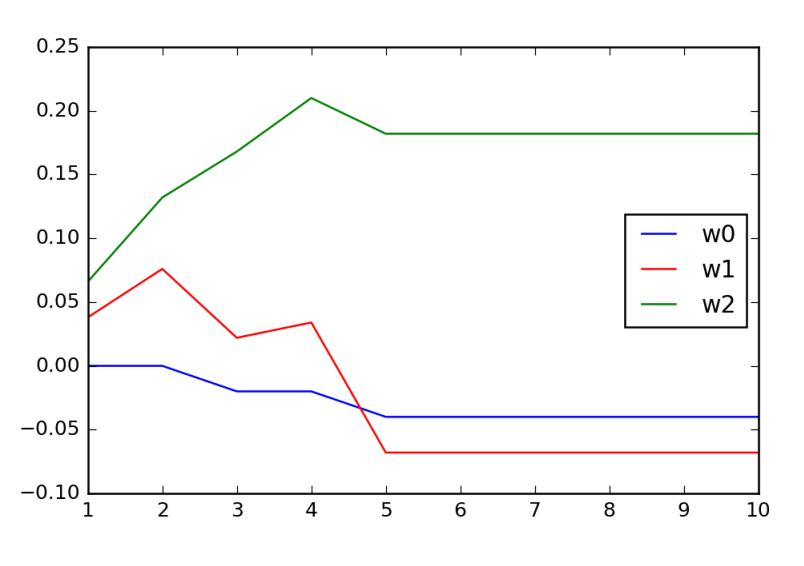
それぞれの重みは、5回目の反復で概ね収束していることを確認できます。

Sebastian Raschka 著/株式会社クイープ 訳/福島 真太朗 監訳 |
Python機械学習プログラミング 達人データサイエンティストによる理論と実践機械学習の考え方とPython実装法がわかる! 分類/回帰や深層学習の導入を解説--◎絶妙なバランスで「理論と実践」を展開 ◎Pythonライブラリを使いこなす ◎数式・図・Pythonコードを理解 --機械学習とは、データから学習した結果をもとに、新たなデータに対して判定や予測を行うこと。本書では、機械学習の各理論を端的に解説、Pythonプログラミングによる実装を説明。AIプログラミングの第一歩を踏み出すための一冊です(本書は『Python Machine Learning』の翻訳書です)。
|


- この記事のキーワード
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
