日本マイクロソフトは2017年5月23〜24日に、技術者向けイベント「de:code 2017」を開催した。基調講演でAIが中心テーマとなったほか、ブレークアウトセッションでも「Artificial Intelligence」のカテゴリーが設けられていた。
日本マイクロソフト株式会社の藤本浩介氏(デベロッパー エバンジェリズム統括本部 エバンジェリスト)によるセッション「目指せ、最先端AI技術の実活用! Deep Learningフレームワーク「Microsoft Cognitive Toolkit」へ踏み出す第一歩」では、Microsoft Cognitive Toolkit(CNTK)を使い始めるにあたっての要点について、画像認識を題材に解説と実演がなされた。

CNTKは、マイクロソフトが開発しGitHubで公開されているディープラーニングのフレームワークだ。対応言語はPython、C++、BrainScriptで、学習済みモデルはC#で動かすこともできる。OSはLinuxとWindowsに対応している。
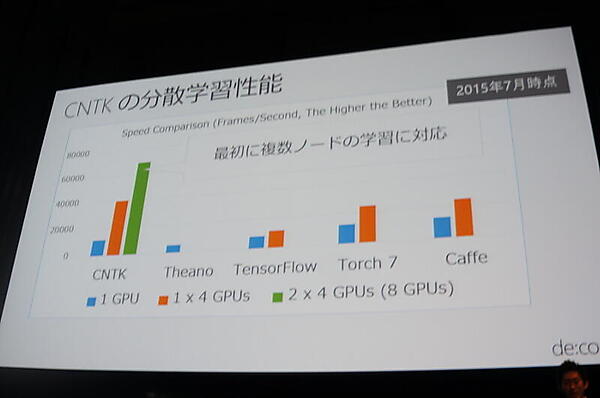
藤本氏によるとCNTKの特徴は「分散学習に対応していてパフォーマンスが出る」こと。同種のフレームワークの中で、最初に複数ノードの学習に対応したという。Microsoftの音声認識が2016年にエラー率5.9%を達成したが、CNTK以前は1回の学習に6〜8週間かかっていたのが、1週間に短縮されたという。
ここで、事例が紹介された。中国のShanghai Changzheng Hospitalでは、糖尿病の診断にCNTKによるディープラーニングを導入した。Azure上で分散学習し、いろいろなパラメータやアルゴリズムを試せたのがよかったという。
また、ごみ拾いSNS「ピリカ」を開発運営する日本の株式会社ピリカは、ディープラーニングにより街角の写真からごみを判別して位置を地図にマッピングする技術を開発している。学習データを集めながらトライアル&エラーを繰り返して全自動を目指すとのことで、トライアル&エラーを繰り返すためにCNTKに乗り換えたという。

ディープラーニングが注目されたきっかけは、画像認識コンテストのImageNetで2012年に、SuperVisionが圧倒的な認識精度を見せたことだった。また、それまで例えばバナナを認識するには、どこに注目する必要があるか人間が与える必要があったが、それが必要なかった。
SuperVisionのAlexNetのディープラーニングは8層のものだったが、2015年のMicrosoftのResNetでは152層にまでなっているという。
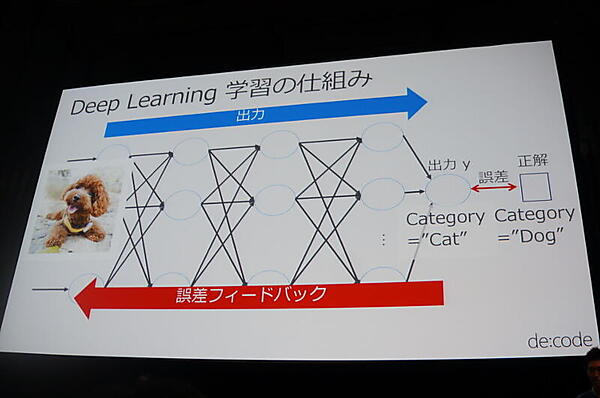
基本的な仕組みは、入力から重みづけして出力するパーセプトロンを何層も重ねるものだ。その出力と正解を比較して誤差フィードバックし、重みづけを更新する。行列計算が用いられるため、GPUが有利となる。
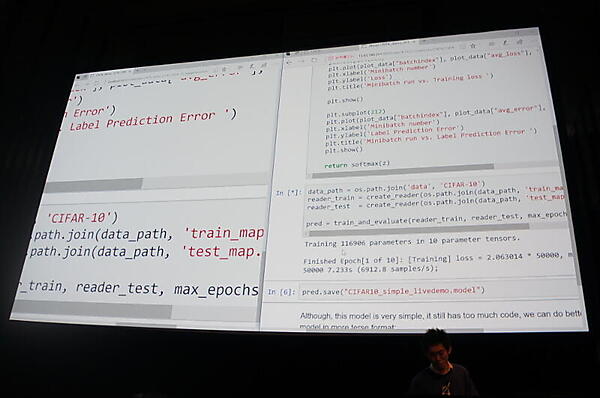
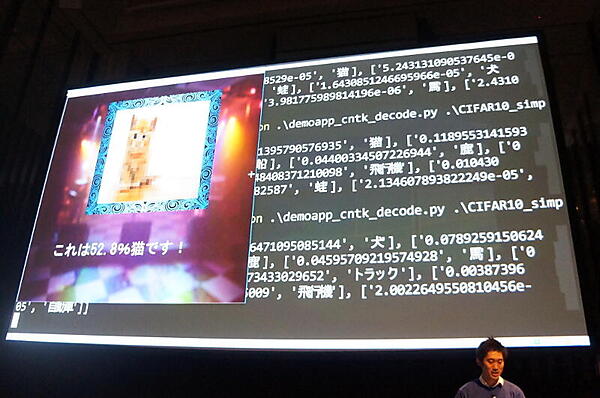
実演では、サンプルデータの画像を、「airplane」「automobile」「horse」など10種類に分類する例が解説された。サンプルデータは、CIFAR-10データセット。ここから32×32ピクセルの画像を、学習用に5万枚、評価用に1万枚使った。
作業の手順としては、まずデータを準備する。学習用に、画像のパスと分類番号とをタブ区切りで並べたマッピングのファイルを用意した。
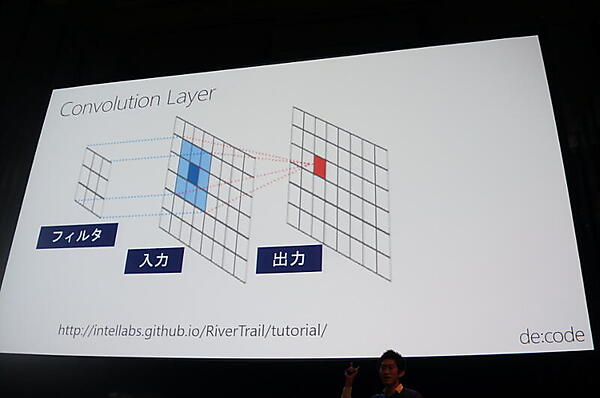
続いてモデルの定義。藤本氏は画像認識のアルゴリズムとして、フィルターをずらして掛けあわせていく「Convolution Layer」と、部分の最大値をとる「Pooling Layer」を合わせた「CNN(Convolutional Neural Network)」を解説した。CNTKでは、それぞれ関数が用意されており、AlexNetは3つの関数で書けるという。
その次が学習フェーズとなる。32×32ピクセル×3色で3072とおりの可能性から、10とおりの出力を得る。

作業としてまずすることは、環境構築だ。CPUで処理する場合はPythonのパッケージ管理ツールpipを実行するだけで入る。しかしGPUを使うにはGPUドライバーなどいくつかのソフトをバージョンを気にしながら入れる必要がある。そこで藤本氏は、AzureでGPU環境やCNTKを導入済みのデータサイエンス仮想マシン(Azure Data Science Virtual Machine:DSVM)を紹介した。
その上でコードを実行した。デモでは、ローカルマシン(CPU処理)とAure(GPU処理)を並べ、Webベースの対話型実行環境であるJupyter Notebookで実演した。学習はAzureで高速に実行し、学習結果を保存して、ローカルマシンで判定を試した。

藤本氏は最後に、CNTKのチュートリアルなどの情報源を紹介して、セッションを終えた。
この記事をシェアしてください
関連記事
de:code 2017開催、基調講演はAIがテーマに
2017年6月12日 15:14
LinuxやDocker対応に加えAI機能を搭載 進化したデータプラットフォーム「SQL Server 2017」
2017年10月11日 11:00
ディープラーニングの実社会での活用を推進ーDeep Learning Labキックオフセミナー
2017年7月25日 14:00
de:code 2018が開催。基調講演はクラウド、開発ツール、MRが語られる
2018年6月11日 12:00
MR・AI・量子コンピューティングが重要テクノロジー 〜Microsoft Tech Summit 2017レポート
2017年11月22日 6:30
Microsoft AzureのCTO「人工知能の進化はOSSとクラウドのおかげ」と語る
2018年3月30日 6:00
バックナンバー
この記事の筆者

筆者の人気記事
使って分かった国産クラウド「K5」のメリットとは
2018年1月31日 6:30
初めてでも安心! OCIチュートリアルを活用して、MySQLのマネージド・データベース・サービスを体験してみよう
2021年4月21日 12:39
Dockerを理解するための8つの軸
2015年7月29日 22:00
Dockerの誤解と神話。識者が語るDockerの使いどころとは? Docker座談会(前編)
2016年2月22日 0:00
【イベントリポート:Red Hat Summit: Connect | Japan 2022】クラウドネイティブ開発の進展を追い風に存在感を増すRed Hatの「オープンハイブリッドクラウド」とは
2022年11月10日 8:45
Kubernetes、PaaS、Serverlessのどれを選ぶのか? 機能比較と使い分けのポイント
2018年5月23日 6:30
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
