サービス・レベルの低下を引き起こす「サイレント障害」
サービス・レベルの低下を引き起こす「サイレント障害」
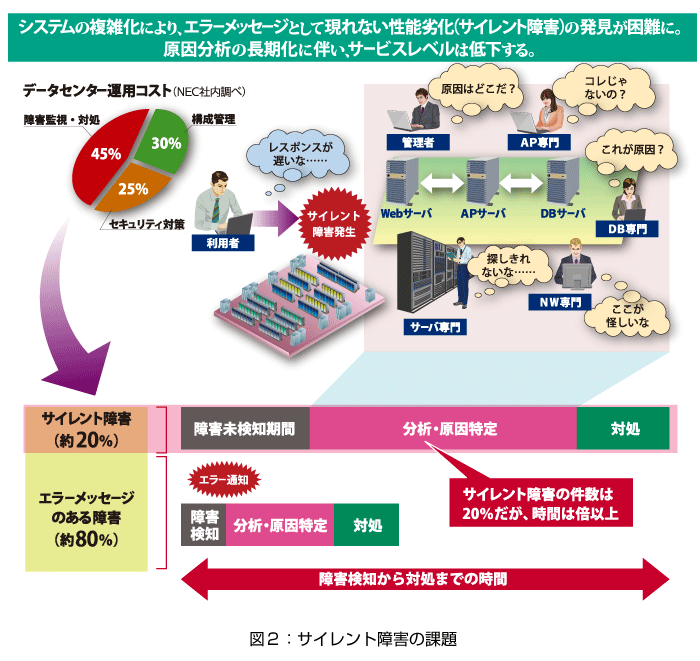
データセンターでは、主として障害監視と障害発生時の対処に運用コストの多くを割いていると言われています。実際、NECが自社システムを対象に調査したところ、障害監視と対処にかかるコストは運用コスト全体の45%にものぼっていることが分かりました。
一般的に、障害の約8割は、従来のシステム監視ソフトが導入されている環境下では、明確にエラー・メッセージとして通知されるため、障害個所の特定にかかるコストはそれほどかかりません。障害監視/対処コストを引き上げる最も大きな要因となっているのは、残りの約2割の障害です。
残りの2割がどのような障害なのかを説明すると、「サーバー単体ごとでは監視のしきい値に達していないのにシステム全体として処理がスロー・ダウンしている障害」や、「エラー・メッセージが出ていないのにレスポンスの遅延が発生している障害」になります。これらの障害は、システムに異常が発生しても音を立てない(メッセージが通知されない)という特徴から、「サイレント障害」と呼ばれています。
ここで、サイレント障害の具体的な事例を挙げてみます。
Webサーバー、アプリケーション・サーバー、DBサーバーからなる3階層モデルの業務システムが、これまでエラー・メッセージもなく正常に稼働していました。
サイレント障害発生の一報は、あるユーザーからヘルプ・デスクに対する問い合わせでした。「業務処理の結果は正常に返ってくるが、応答時間が以前よりかなり長くなっている」という内容で、管理者はようやく異常が発生したことに気が付きます。急いで状態を確認しますが、システムのどこからもエラー・メッセージが通知されていません。
結局、管理者1人では障害個所が特定できなかったため、サーバーやネットワークの管理者/専門家を集めて原因を探すことになり、その特定から復旧まで多大な時間を要することになってしまいました。
サイレント障害の課題 ~障害検知の遅れ~
このケースの根本的な原因は、アプリケーション・サーバー上のアプリケーションがフリーズしてCPUを占有してしまったことにあったのですが、これを検知できるようにあらかじめCPUの使用率が80%を超えた場合に障害としてエラー・メッセージを出すよう監視設定されていたはずでした。
ではなぜ、メッセージ通知されなかったかというと、実はこのサーバーには4つのCPUが搭載されており、アプリケーションのフリーズで占有されたのはそのうち1つだけだったのです。
この場合、サーバー全体のCPU使用率でみると25%が使用されているという状態のため、設定した80%というしきい値を超えることはなく、エラー・メッセージが通知されなかったのです。このように、サイレント障害はシステム監視ソフトでは検知されない(見落とされてしまう)危険性があります。
前述の事例はサイレント障害の一例ですが、これから読み取れるサイレント障害の課題について整理しましょう。
サイレント障害の課題は、障害発生から障害回復までの期間を長期化させることにあります。障害回復までが長期化する理由は2つです。
まず1つ目は、サイレント障害においては、発生したことに気がつくまでに時間がかかるという点です。
通常、システム監視ソフトで障害を監視している環境では、アクセス集中などによってCPUやメモリの使用率がしきい値に達した場合、エラー・メッセージが通知されるため、障害の早期発見が可能です。しかし、サイレント障害の場合は、従来のシステム監視ソフトでは検知されず、エラー・メッセージが通知されません。このため、障害の発生が見落とされ、多くの場合はユーザーからの問い合わせによって初めて障害の発生に気づくことになります。
次ページでは、サイレント障害において障害回復までの時間が長期化する2つ目の理由である、原因分析の難しさについて解説します。
- この記事のキーワード
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
