マイクロサービスの適用基準
マイクロサービスの適用基準
マイクロサービスを適用するか否か、その判断基準について、ファウラー氏は自身のWebサイトで言及しています(MicroservicePremium)。そのポイントは、対象システムが複雑であればマイクロサービス適用を検討する価値はあるが、対象システムが単純であればマイクロサービス化には向いていないというものです。その理由は、マイクロサービス適用に関するコストにあります。マイクロサービスのコンセプトを実現するには、CD等の自動化の仕組みを作らねばなりません。また複数のサービスから構成されるマイクロサービスは、必然的に超分散システムとなります。分散システムを統治する運用監視の仕組みや、データの整合性を担保する仕組み等、分散システムであるがゆえの対応策が求められます。当然これらの対処には、時間とお金が必要になります(ファウラー氏の記事のタイトル「MicroservicePremium」は、マイクロサービスに必要な割増料金とほぼ同義です)。数名/数週間でリリースできるような単純なシステムにとってみれば、マイクロサービスは高コストのソリューションになってしまうのです。
以上のような背景より、マイクロサービスは、モノリスとしては管理しきれないような複雑なシステムへの適用を検討します。ここでいう複雑とは、例えば業務の数が考えられます。システム化対象が複数の業務から構成されているならば、業務ごとに個別にリリースやメンテナンスを行うといった柔軟な開発と運用が求められたり、各業務ごとの処理量の違いからそれぞれ個別のスケーリング・ポリシーの適用が必要になったりするでしょう。あるいは、100名を超えるような多数のメンバーから構成される開発・運用チームも複雑さの一例です。各メンバーが、独立して能動的にシステム開発に取り組む仕組みが必要になります。このような複雑さの解決に、マイクロサービスが役立つのです。
MSA設計の基本
サービスとはビジネスを表すソフトウェア・コンポーネントであり、プログラミング・インターフェースとモデルを有します(図7)。
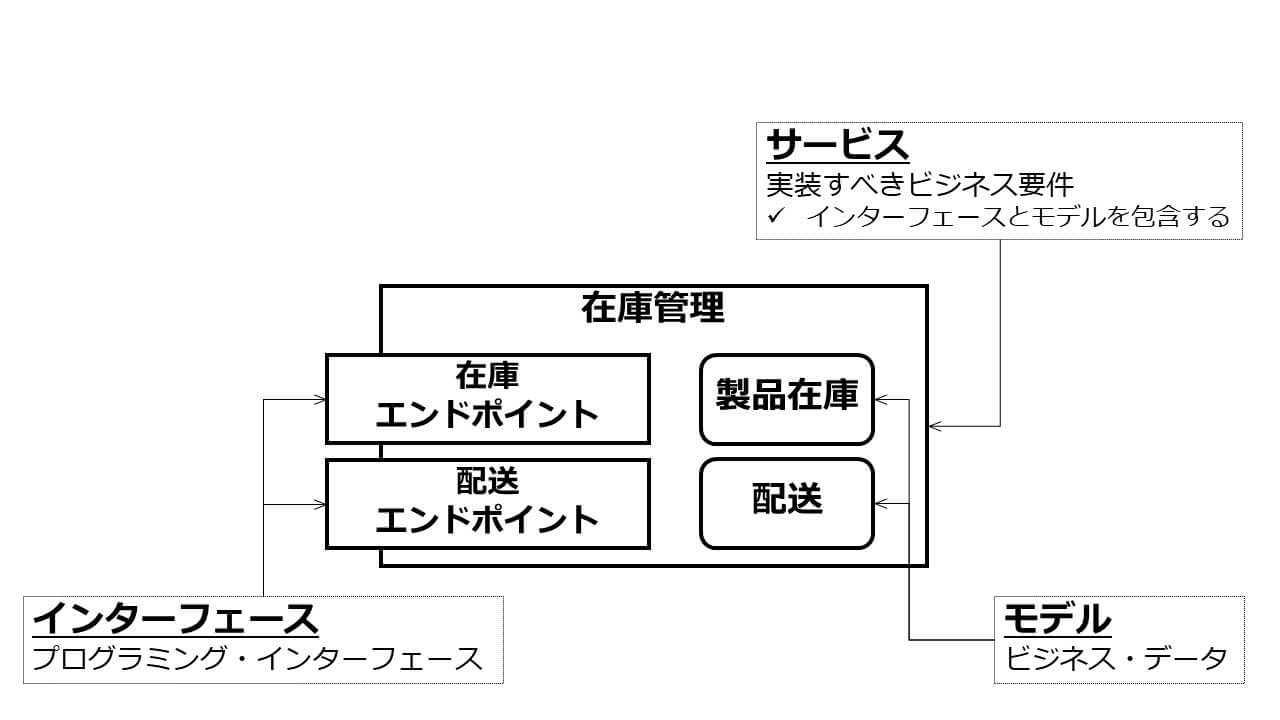
図7:マイクロサービスの構造
モデルとは業務データのことで、DB等で実装されます。すなわちDBはサービスの中に包含、隠蔽されており、DBにアクセスするにはサービスが提供するプログラミング・インターフェースを利用します。言い換えれば、MSAにおいては、サービスがDBに直接アクセスすることは推奨されません(図8)。万が一DBのスキーマに変更を加えた場合、その影響範囲を最小化するのがその理由です。サービス経由でDBアクセスしている場合には、DBを包含するサービスのみがメンテナンス対象となりますが、サービスがDBに直接アクセスすることを許容してしまうと、メンテナンス対象のサービスが不特定多数に上ってしまいます。素早く柔軟なメンテナンスを実現するには、サービス経由のDBアクセスが有利なのです。
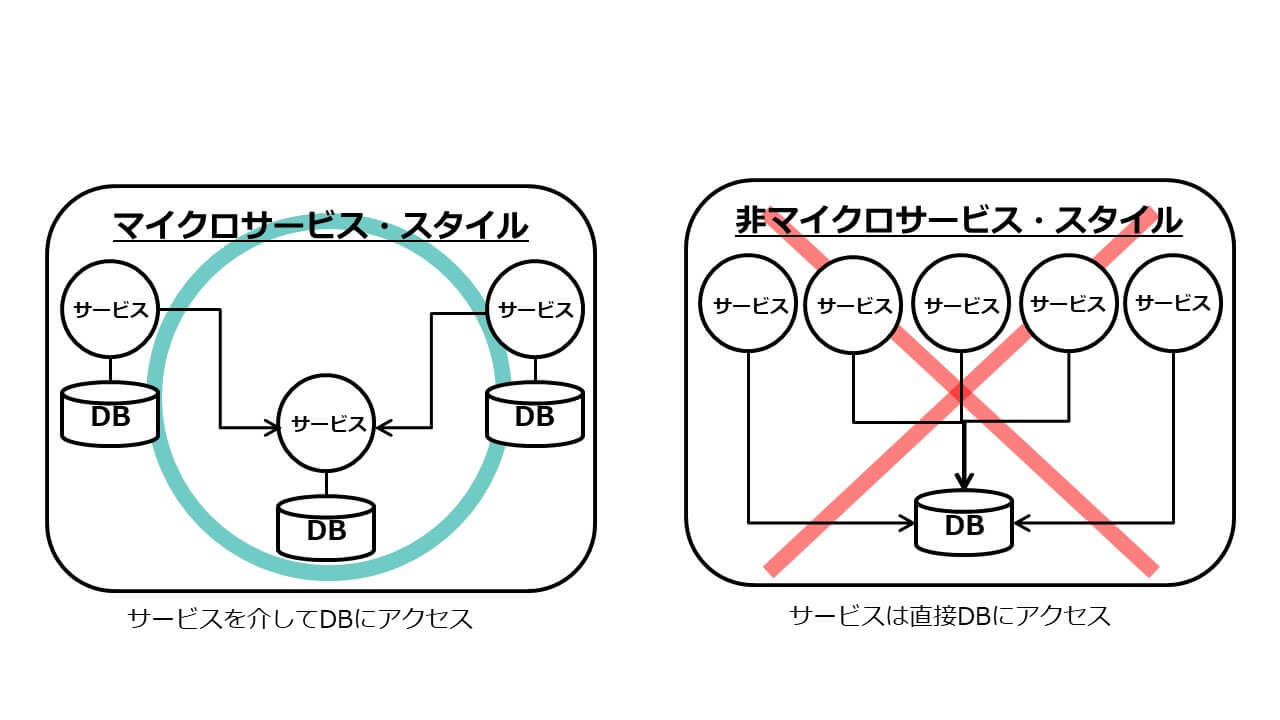
図8:マイクロサービスにおけるDBアクセス
DBアクセスに欠かせないのがトランザクションですが、ここにもMSAの推奨の作法があります。トランザクションには、1つのトランザクション内で1つのリソース(DB)処理のみ行うローカル・トランザクションと、1つのトランザクション内で複数のリソース処理を行うグローバル・トランザクションがあります。グローバル・トランザクションは分散トランザクションとも呼ばれ、その実装としてX/Open XAやSOAの時代にリリースされたWS-Transactionが知られています。MSAではローカル・トランザクションを薦める一方で、グローバル・トランザクションを推奨しません(図9)。
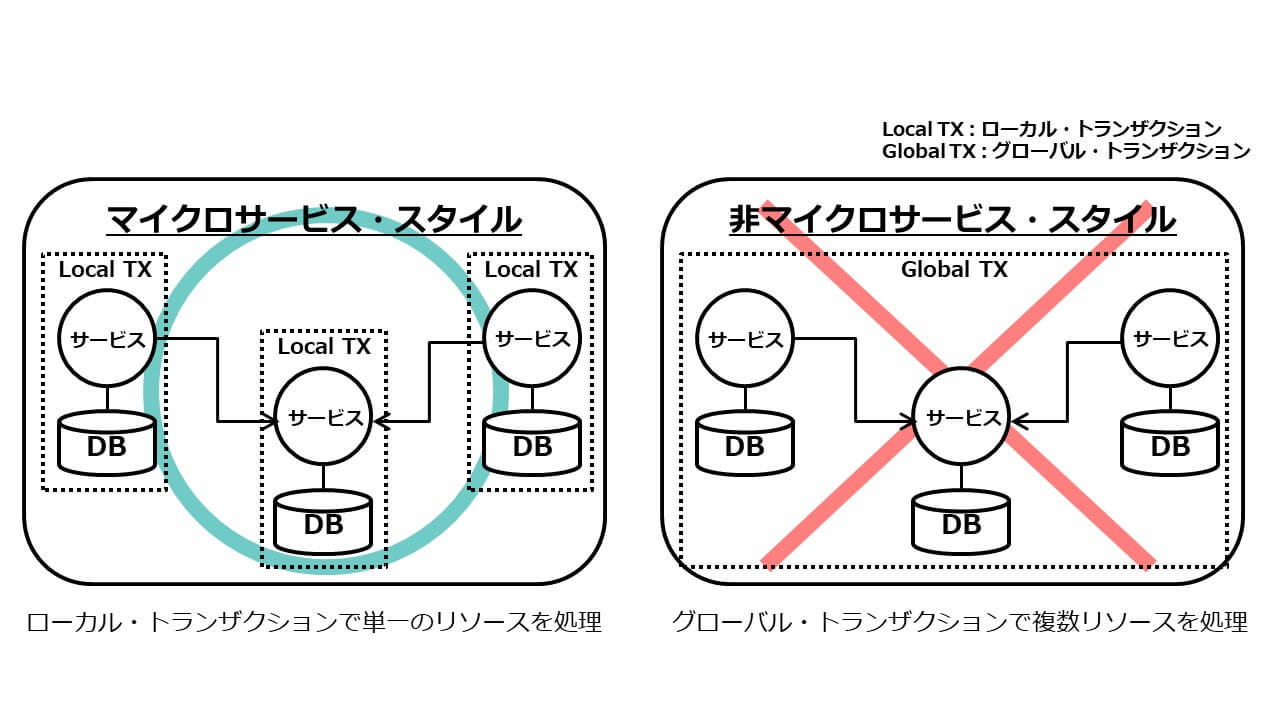
図9:マイクロサービスにおけるトランザクション
グローバル・トランザクションは、複雑で不具合の原因になる可能性があるというのがその理由です。分散トランザクション管理に代えてマイクロサービス・アーキテクチャーが推奨しているのは、結果整合性の利用です。
では分散トランザクションが推奨されないMSAでは、どのように複数リソースの同期を取るのでしょうか。その解決策の一つが、Sagaです(図10)。Sagaとはデザイン・パターンの一つで、リソースに対するローカル・トランザクション処理を、イベントまたはメッセージをトリガーにして複数連ねるものです。万が一、ローカル・トランザクション処理に失敗した場合、これまで適用した更新処理を元に戻す逆向きのトランザクション(補償トランザクションあるいはコンペンセーション・トランザクション)処理を起動します。これにより複数リソースの同期を取って、整合性を担保するのです。
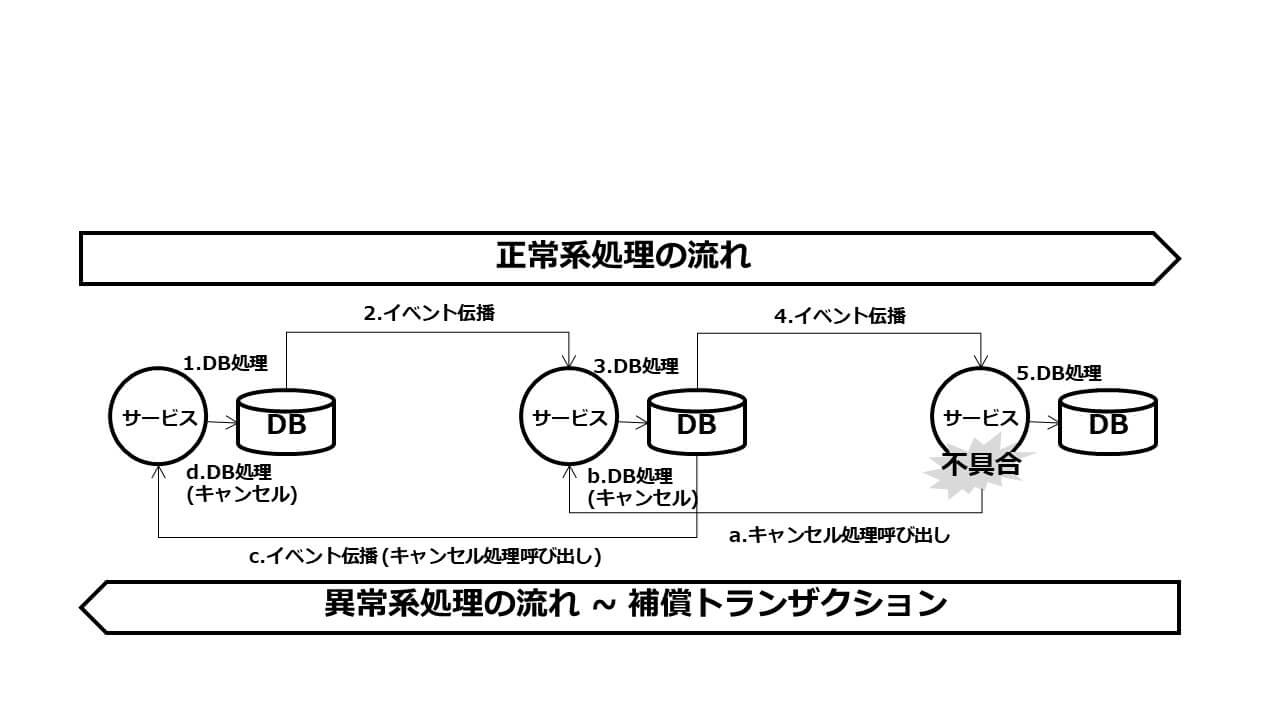
図10:Sagaパターン
サービス・メッシュ
独立稼動する複数のサービスが1つのアプリケーションを構成し、しかもサービスの数が多数に上るとなると、マイクロサービス化は過去経験したことがないような超分散システムに繋がります。各サービスが他のサービスと連携するために構成されるネットワークを「サービス・メッシュ」と呼びます(図11)。
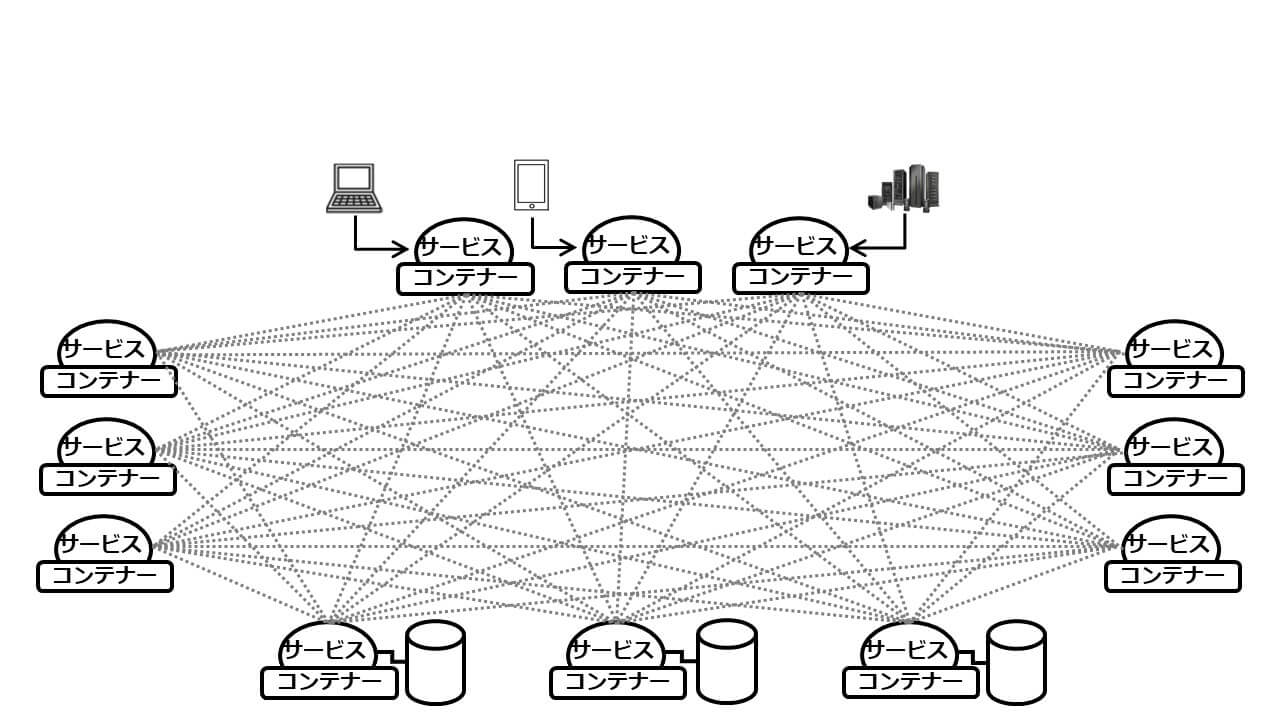
図11:サービスメッシュ
複雑に絡み合った通信経路の集合体を、網の目(メッシュ、mesh)になぞらえたネーミングです。マイクロサービス化を成功に導くには、サービス・メッシュを適切に運用管理することが求められます。そのためには、以下に挙げたポイントについて対応が必要となります。
- ルーティング
- サービスのリリース
- テスト
- 耐障害性
- 監視
ルーティング
サービス・メッシュでは、サービスの種類だけではなく、バージョンの違いや、通信ヘッダーに設定されているコンテキスト、さらには業務データのコンテンツに基づいたルーティングが求められることもあるでしょう。そうなると、基盤レベルに留まらず、より上位の通信スタックを意識したルーティングを考慮しなければなりません。
サービスのリリース
また、マイクロサービス化の対象となる複雑なICTシステムでは、仮に定期メンテナンスや障害で一部のサブシステムが停止していても、他のサブシステムは通常運用を求められることが少なくありません。連続稼動という命題を与えられている中で、新たなサブシステムのリリースや一部のサービスの追加・変更・除去を遂行しなければならないのです。ルーティングの仕組みを上手く活用して、システムの全面停止を避けながら、柔軟にかつ継続的に、サービスをリリースすることが期待されるのです。
テスト
ソフトウェア・コンポーネントの数が増え、それぞれがメッシュ状のネットワークで構成されるとなると、テストにも一工夫が必要です。テスト・ケースの数が増え、スタブやモック等テスト用ソフトウェア・コンポーネントの開発にコストがかかってきますので、少しでもコストを抑えるべく、サービス・メッシュを効率的かつ効果的にテストする仕組みが求められます。
耐障害性
分散システム運用の難しさは、障害発生時に露見します。システムの構成要素が多数に上るため、問題判別に時間と手間がかかります。また障害の影響範囲が広範に渡るだけでなく、思いもよらないところで二次災害が発生することも考えられます。サービスの連続稼動を担保するために、障害発生時の影響範囲を最小化する手立てが必要です。
監視
マイクロサービス化されたシステムは、多次元での監視が求められることになるでしょう。例えば、各サービスごと、各サービスのバージョンごと、さらにはサービスの集合体としてサービス・メッシュ全体といった様々な観点から、メトリクスや、ログとトレースを収集し、状態をタイムリーに表示あるいは通知しなければなりません。分散配置された各サービスからの情報収集と、表示と通知の仕組みが求められます。
以上のようなサービス・メッシュの最適化を、各アプリケーション・プロジェクトごとの個別実装で対応するのは、効率的ではありません。また、Kubernetes等コンテナ・オーケストレーション・フレームワークは基盤ソリューションであり、アプリケーション・レイヤーまで含むサービス・メッシュに関する全ての課題を解決できる訳ではありません。サービスを意識した、サービス・メッシュを最適化するソリューションが求められるのです。そのようなサービス・メッシュ最適化のソリューションがIstioです。次回は、サービス・メッシュ最適化にあたり、どのような機能や手法を提供するのか、Istioの概要を解説します。
- この記事のキーワード
関連記事
コンテナをさらに活用しよう! 「マイクロサービス」と「サーバーレス」
2021年4月6日 7:06
【CNDW2025】250環境を5人で運用、構築時間は30分に ーKINTOテクノロジーズが語るインフラ基盤組織の作り方
2025年12月18日 6:30
Oracle Cloud Hangout Cafe Season6 #1「Service Mesh がっつり入門!」(2022年9月7日開催)
2023年6月22日 6:30
CNDT2021、日本オラクルのエンジニアによるクラウドネイティブを再確認するセッション
2021年12月23日 13:49
マイクロサービスと「Red Hat OpenShift Container Platform with Runtimes」の基礎知識
2020年6月12日 6:30
CNDT2020シリーズ:メルペイのマイクロサービスの現状をSREが解説
2021年1月5日 8:16
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
