Gremlinがアプリレベルの障害注入ソリューションALFIを発表
カオスエンジニアリングのGremlinが初めてのテクニカルカンファレンス、ChaosConfをサンフランシスコで開催。アプリレベルの障害注入ソリューション、ALFIを発表した。
2018年11月7日 6:00
「カオスエンジニアリング」は、Netflixがオープンソースソフトウェアとして公開したChaosMonkeyというソフトウェアに端を発した「データセンターに意図的に障害を発生させるソフトウェア」群を総称する用語だ。昨今のIT業界では「壊れないシステム」を作るよりも「壊れることを前提として素早く復旧するシステム」を作る方向にシフトしている。これは分散ストレージやコンテナオーケストレーションのKubernetes、そしてインターネットそのものにも共通する発想である。
ChaosMonkeyを作ったのはNetflixだが、そのきっかけはKolton Andrus氏がNetflixに移ってからとみなすべきだろう。Andrus氏は、Netflixの前にはAmazonの巨大なトラフィックに耐えるECサイトのエンジニアだった。そしてそのAndrus氏がNetflixを辞めて2016年に創業したのが、今回紹介するGremlinだ。
Gremlinは「Failure as a Service」を標榜するカオスエンジニアリングの中心的なベンチャーと言っていいだろう。そのGremlinが、初めてのテクニカルなカンファレンス、Chaos Confを2018年9月28日にサンフランシスコで開催した。今回はそのカンファレンスで発表されたALFI(Application Level Fault Injection)と、AWSのVPであるAdrian Cockcroft氏のキーノートセッションを紹介しよう。
進化したカオスエンジニアリング
まずWelcomeスピーチのために登壇したのは、Gremlinの創業者兼CEOのKolton Andrus氏だ。Andrus氏はカオスエンジニアリングをいくつかのレベルに分け、ChaosMonkeyはランダムにサーバーやプロセスを終了させるというレベル1のものだったが、それをさらに進化させてより洗練させたものが、ALFIだと紹介した。ALFIはアプリケーションレベルの障害を注入することで、より細かく障害の内容を制御することができる。現在のバージョンではJavaのみに対応し、JVMにGremlinのライブラリーを追加してビルドすることで、アプリケーションが通信するパケットに対して遅延を発生させたりすることができるようだ。

ALFIを紹介するGremlinのCEO、Andrus氏
詳細は、以下のリンクからドキュメントを参照して欲しい。
任意のアプリケーションタイプを設定し、デバイスやトラフィックが発生する国を指定できるということは、障害の範囲を任意に設定できることを意味している。またトラフィックに障害を発生させる割合も指定できる。確かにこれはランダムにサーバーを落とすよりも洗練されているし、一部の障害が他のシステムにどのように伝搬するのかの監視もできるため、開発中のテストの一貫として使えるだろう。
同様にアプリケーションパフォーマンスマネージメントの領域にも、Ciscoが買収したAppDynamicsのようにJVMにフックしてアプリケーションからのパケットを測定し、遅延などの問題点を可視化するソリューションがあるが、GremlinはSRE(Site Reliability Engineering)の観点からアプリケーションレベルの障害注入に進出してきたと言える。それをGremlinのWebサービスと連携して「Failure-as-a-Service」に練り上げているところが、単なるオープンソースソフトウェアの会社ではないということがわかる。あくまでも障害発生をサービスとしてビジネス化していることが斬新だ。
このセッションでは、実際にiPhoneとAndroidのスマートフォンに対してトラフィックをシミュレートさせ、Androidだけ画像の表示が遅くなるというデモを紹介した。ユーザーエクスペリエンスのテストとしても応用できることを示した。

iPhoneとAndroidでの表示の比較。右の画面にはエラーを表すグレムリンの画像が表示されている
今後は、Java以外の言語やサーバーレスにも展開が予定されているということからもわかるように、将来的にはクラウドネイティブなアプリケーションにも適用可能になるだろう。

サーバーレスにもカオスエンジニアリングが必要
カオスエンジニアリングとAWS
次に、キーノートとして行われたAWSのVP、Adrian Cockcroft氏のセッションを紹介しよう。ここではカオスエンジニアリングの概要とAWSの取り組みが紹介された。

カオスエンジニアリングを紹介するAdrian Cockcroft氏
ここでは要約として「Experiment to ensure that the impact of failure is mitigated(障害の影響が緩和されることを確認するための実験)」であると解説した。そのためには様々な障害に対して認識を拡げなければいけないとして「インフラストラクチャー、スイッチング、アプリケーション、ピープル」の4つのレイヤーでの障害を想定するべきだと強調した。
その中で自身がNetflixにいた時に遭遇したバグを紹介した。これはスペイン映画のタイトルに「セディーユ(ç)」が含まれていた時に「<ç>」と表示しなければいけなかったコードの最後の「>」が漏れていたために、プレゼンテーションのコードが無限ループに入り、最終的にサイトがダウンしたというものだ。これは、開発されてから6年間も発見されていなかったバグであったという。このようなバグから発生する障害を実験するということが、カオスエンジニアリングの要点であるということだろう。

Netflixのセディーユバグを紹介するCockcroft氏
またカオスエンジニアリングの歴史について振り返り、2004年のAWS、2010年のNetflix、2016年のGremlin創業などから、カオスエンジニアリングがクラウドコンピューティングの本流に入ってきたことを紹介した。
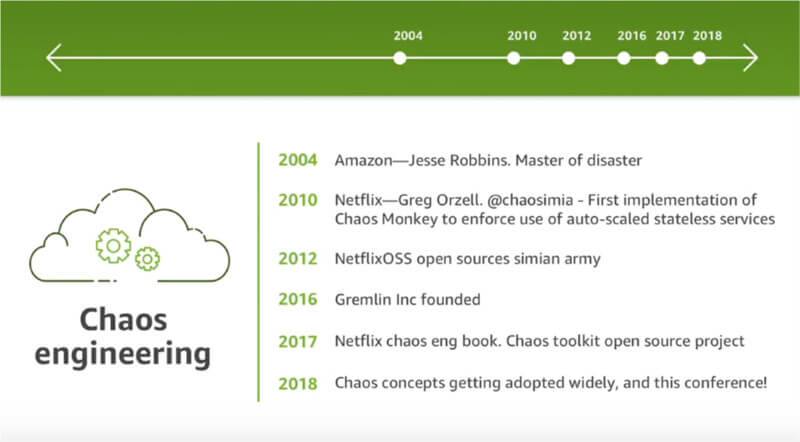
カオスエンジニアリングの歴史
またAWSのリライアビリティについても紹介を行い、各リージョンがお互いに依存することなく独立していること、アベイラビリティゾーンの考え方についても紹介を行った。

AWSのデータセンターについて解説するCockcroft氏
そしてCNCFにおいても、カオスエンジニアリングがサブグループとして活動していることを紹介。このカンファレンスにCNCFのCTOであるChris Aniszczyk氏も参加していたように、クラウドネイティブなシステムに関わっている人間には注目されていることがわかる。
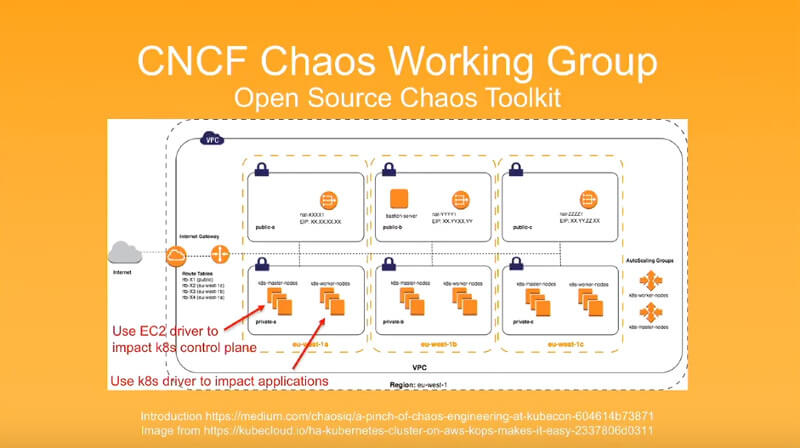
CNCFのChaos Working Groupの紹介
最後にCockcroft氏は、データセンターのディザスターリカバリーについて「現行のマニュアルでアドホックな方法からカオスエンジニアリングによるリカバリーの方式に転換していくだろう」と予言した。これは従来型の「壊れないことを信じて万が一のための対処を行う」という発想から「常に壊れることを想定していつでもリカバリーできる」という考え方にシフトすることを意味している。
クラウドプロバイダーのように大量のサーバーやストレージを使う企業からエンタープライズにまで、この「壊れながらも維持できるシステム」という発想が浸透することで、より堅牢なシステムが可能になるという予言だろう。
データセンターもカオスエンジニアリングにシフトする
他にもWalmartやTwitter、Microsoftなどのスピーカーが講演したカンファレンスも含めたすべての講演は動画で公開されているので、実際のセッションのようすを見てみたい方は、以下の再生リストから視聴してみて欲しい。
来年のカンファレンスにも参加してみたいと思わせる内容だった。
なおGremlinは最近、シリーズBのファンディングを行い、1800万ドルを調達した。これで合計2375万ドルの投資を受けて、ますます拡大の方向にある。
この記事をシェアしてください
関連記事
KubeCon Seattleでも耳目を集めたカオスエンジニアリング
2019年1月30日 6:00
Red HatがOpenShift向けカオスエンジニアリングツールKrakenを発表
2021年1月21日 6:45
CNCFのサンドボックスプロジェクト、カオスエンジニアリングのLitmus Chaosを紹介
2021年7月1日 7:29
Open Infrastructure Summit上海、LINEに聞いた大規模なOpenStackクラスター運用のポイントとは?
2020年1月29日 5:50
OpenStack Days Tokyo:ガートナーが予測する消えるエンタープライズデータセンターの衝撃
2018年9月11日 6:00
Japan Container Daysのキーノートで語られたCA、ヤフージャパン、メルカリの事例
2018年5月15日 10:51
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
