Webサイトやスマートフォンアプリの多言語化ソリューションを開発・販売するWovn Technologies株式会社(以下、WOVN)に、インタビューを実施した。今回のインタビューは2020年7月に公開したThinkITのインタビューと同様にZoomを介して行われた。サブスクリプションサービスを展開するZuoraの導入事例に次いでTreasure Dataへの導入が決まったこと、さらに2020年11月に米国で取得した特許に関する内容を解説するものとなった。
インタビューに参加したのは、COOの上森久之氏、開発チームの幾田雅仁氏、サポートチームの寺西哲平氏だ。
インタビューに応える開発チームの幾田氏
今回は日米で取得された特許の件とTreasure Dataへの新たな導入事例についてお訊きします。まず日米で取得した特許について解説してください。
上森:これは2020年11月11日に公開したプレスリリースで解説していますが、変更検知に関する詳細な部分については幾田のほうから解説させてください。ちなみに日本での特許登録は2018年5月11日、アメリカは2020年12月29日になっています。
参考:WOVN.io、米国で特許取得~変更箇所の自動検出技術で多言語サイトの推進を図る~
幾田:これはWOVNが提供する翻訳サービスを、より効率的に行うための仕組みになります。WOVNは機械翻訳を使ってWebサイトやスマートフォンアプリケーションの翻訳を行いますが、今回はWebサイトの翻訳に利用する機能です。
具体的な例を挙げて説明しましょう。例えば製品紹介のページがあるとします。そのページに新しいコンテンツが追加されたり、内容が修正されたりする場合、それを自動的に検出して翻訳を行うには、サーバーからサイトのページをスクレイピングするなどの方法が取られてきました。しかしこの手法には動的に生成されるページの場合に漏れが発生する可能性がありますし、またサーバー側の負荷が高くなるなどの問題点もありました。今回の特許技術はそれを解消するものです。
WOVNのサイトにあるプレスリリースのページにはその処理を表す図がありますが、これはブラウザーでそのページを閲覧した時にそれが変更されているのか?を検知してWOVNのサーバーに送って翻訳を行うという形になっていますが、もう少し具体的に説明してください。
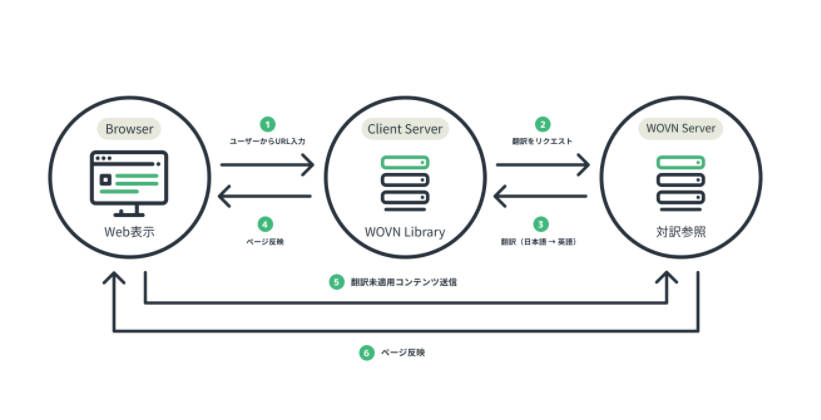
ブラウザー、Webサイト、そしてWOVNの翻訳サーバーの関係を解説
幾田:具体的にはブラウザーにJavaScriptで書かれたスクリプトをインストールして、それがページの変更を検知し、WOVNのサーバーに通知して翻訳するという流れになります。この場合、インストールされるブラウザーはそのWebサイトの持ち主である企業、つまりWOVNの顧客、具体的にはWeb担当者のブラウザーということになります。
つまりWebサイトの更新担当者のブラウザーにインストールしておくと、更新内容の確認のために閲覧すれば翻訳されるわけですね? エンドユーザーの環境になにかをインストールしてもらうよりは適切だと思います。
幾田:そうですね。この方式であれば動的に生成されるページであっても翻訳漏れがなくなるわけです。SPA(Single Page Application)でも対応可能ですし、実際にサーバーからスクレイピングして翻訳する方式よりもはるかに効率が良いと考えています。
日本の企業のWebサイトで、最初から多言語化を前提に構成してあるところは、ほとんどないというのが実情です。通常はテキストの部分に言語ごとのリソースファイルを用意して、日本語から他の言語への翻訳がアーキテクチャーとして可能なようにするべきなのです。しかし、それができている企業は、ほぼ存在していません。そのため、英語サイトから始まって日本語のサイトを後から作るみたいな流れになりがちなのです。そのような方法ですと、運用面でどうしても追いつかないということになってしまいます。
本社のほうはどんどん英語の情報を公開・更新しているのに日本語サイトは追いついてない、みたいな状況ですよね。同じ悩みを抱えている企業は非常に多いと思います。これの特許の根幹の部分は、ブラウザーがページの変更部分を検知してWOVNのサーバーに翻訳を依頼するというその部分ですね?
幾田:そうです。サーバーがスクレイピングするというのはもう誰もがやっていることですが、ブラウザーのスクリプトからトリガーがかかるという部分がコアですね。そのため、今後他社が同じことをやろうとしても特許で守られることになります。
それでは次に、Treasure Dataでの導入が始まった件について詳しく教えてください。
上森:Treasure Dataは日本から始まった会社ですが、今はアメリカで主に活動をしています。しかし日本にも彼らの重要な顧客がいますから、技術情報の日本語化も検討されていました。しかし全体で約1500ページの規模で、月間に100ページ程度が更新されるという製品情報の量ですので、人的な翻訳で提供するというのは不可能だったと伺っています。そこがWOVNによる機械翻訳でなんとかなると感じていただいて、取り組みが始まったという感じです。
Treasure Dataの翻訳例
Zuoraの場合はサブスクリプションということで、会計などの専門用語を正確に翻訳するのは難しかったと思いますが、Treasure Dataの場合は?
寺西:以前に事例として紹介したZuoraの場合は英語でしかFAQが公開されていなかったので、それを日本語化しようというプロジェクトが始まった時に「すべての翻訳の品質を人的翻訳のレベルにする」というのは最初から無理だと言う認識がありました。だからといって致命的な誤訳は避けたいということで、合同のプロジェクトとしてポストエディットをするというプロセスを実施しています。ここで数百文字から数千文字程度のサンプリングを行って翻訳の品質を評価するということをやりました。
機械翻訳と人的翻訳の品質の違いを数値化して、機械翻訳が1だとすると人的翻訳は5というように点数を付けて、全体では3を目指すというような方針でプロジェクトのゴールを決めて進めました。そこでのすり合わせに数か月掛かりました。実際にポストエディット作業が終わったのが、2020年10月22日なので、公開はそこから始まった感じですね。ZuoraのFAQは総量で言えば150万文字程度はあったので、それを徐々に翻訳していくというやり方です。Zuoraは会計に関わる情報や単語がありますので、それをキチンと日本語に翻訳するという部分に重点がありました。
Zuoraの翻訳例
上森:Treasure Dataの場合は製品情報の翻訳を行うというのが要件で、優先順位は品質よりもスピードでした。これは企業の要件によって変わるので、それぞれの企業や組織が何を求めているのか? これに合わせて対応していくということになります。
企業や業界、対象となる製品などによって目的が異なるわけですね。ちなみにサービスのトライアルは提供されていますか?
上森:現在は、フリートライアルは提供していないので、その都度、ご相談していただくことで予算感や目的、スケジュールを詰めていく形になります。WOVNは現在直販でビジネスをしていますので、そのご相談にはWOVNの営業チームが当たることになります。
営業チームはどれくらいの規模ですか?
上森:今は20名程度が案件の相談に対応しています。会社は成長していますし、組織も変化していますので、「2021年2月の段階での状況」になります。
現在は直販ビジネスとのことですが、国内には製造業などの業界に強いインテグレーターも存在します。いつかはパートナーと組んでビジネスを行う可能性はありますか?
上森:数年後にはあると思います。実際、今でもWOVNをよく理解してくれているパートナーと組んで取り組んでいる案件もあります。WOVNのビジネスの仕組みを理解してもらうのには時間がかかりますが、ある程度理解してくれれば、パートナーとして組むのはありかなと思います。
最後に、今回の変更検知の部分に関する将来計画などがあれば教えてください。
幾田:現状では、専門用語や翻訳しない部分などを手動で調整する作業があります。これをもう少し自動化することを考えています。後はコンテンツの文脈を理解するといったことも目指しています。
最近はチャットボットを使ってFAQを検索させるみたいな流れがありますが、それに対応することは可能ですか?
幾田:実はAPIを使えば今すぐにでも始められると思いますね。質問と回答のどの部分をどのタイミングで翻訳させるのか? これに関しては色々なやり方があるので、細かい調整は必要になると思いますが、使い方としては面白いと思います。
これまでのWOVNは、Webページにスクリプトを埋め込んで表示時に翻訳を行うという仕組みだったが、それをSPAや動的に生成されるページにも対応するために技術開発を行い、最終的に日米で特許を取得したというストーリーが理解できるインタビューとなった。
コンテンツホルダーの負荷を抑えて国際化が行える仕組みが、さらに進化していることを実感できた。Zuora、Treasure Dataのそれぞれサイトにアクセスして、実際にダイナミックに翻訳が行われているのを確認して欲しい。
Zuora:https://knowledgecenter.zuora.com/
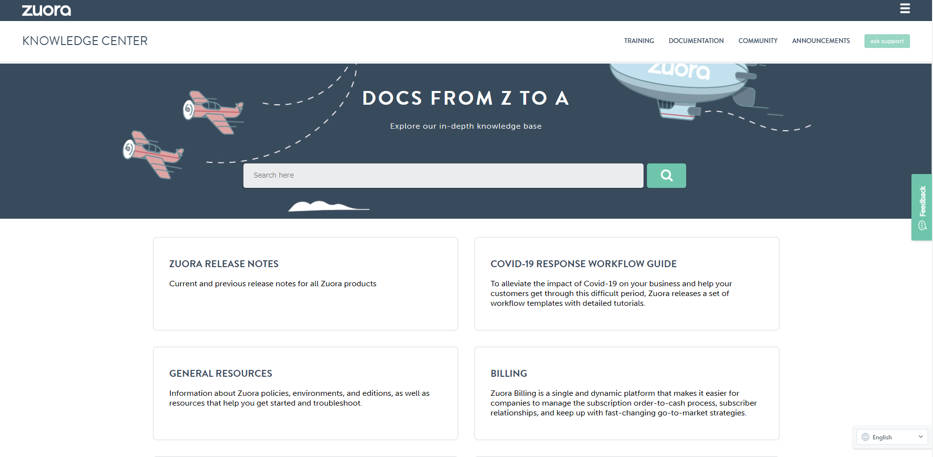
Zuoraのナレッジセンター
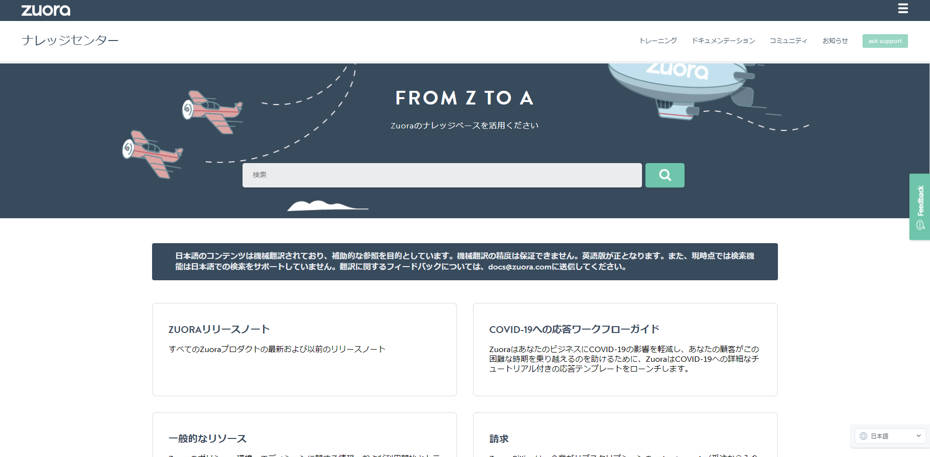
自動的に翻訳されたZuoraのナレッジセンター
Treasure Data:https://docs.treasuredata.com/
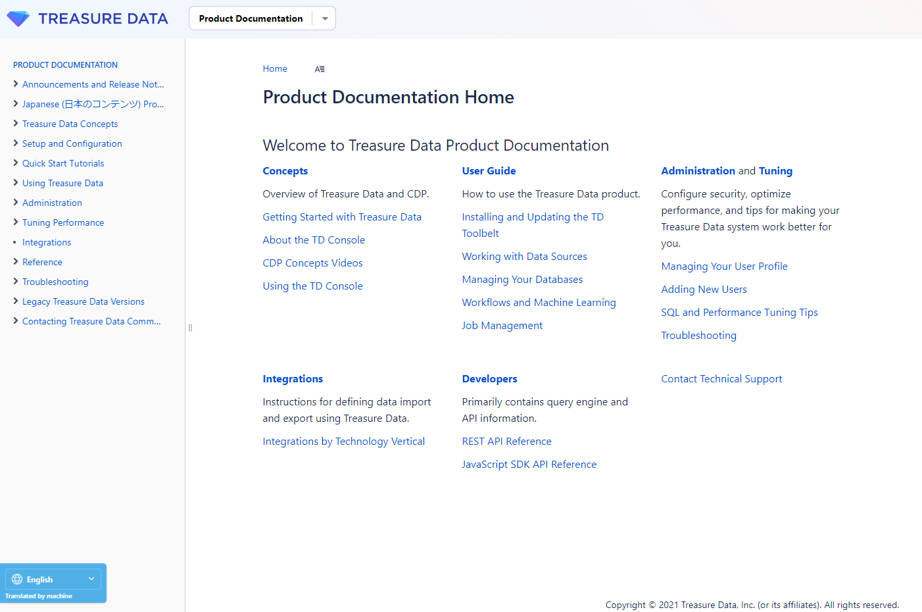
Treasure Dataのドキュメントページ
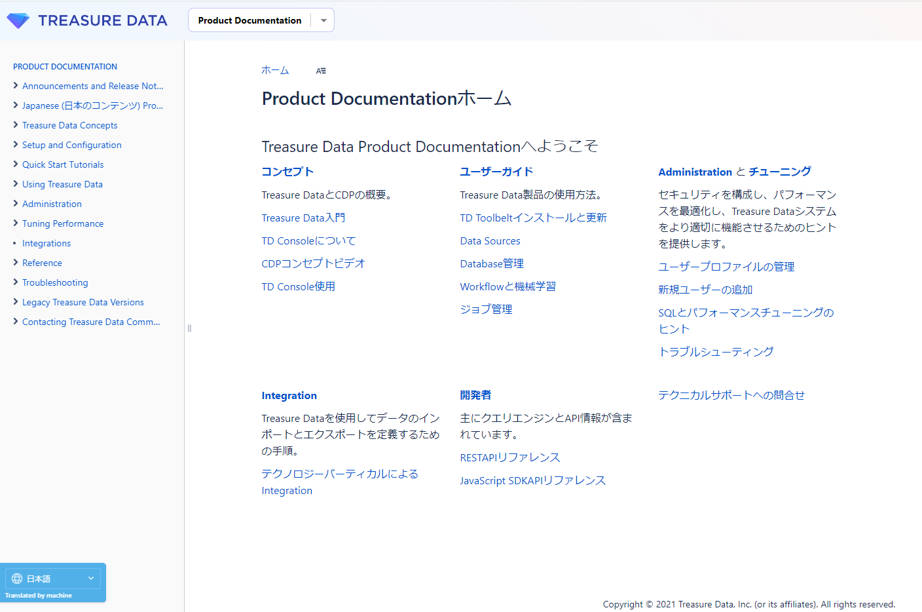
自動的に翻訳されたTreasure Dataのドキュメントページ
- この記事のキーワード
この記事をシェアしてください
関連記事
多言語化を支援するWovnのCEOにインタビュー。ハイパーローカライゼーションとは?
2023年7月10日 6:00
多言語化を支援するWovnがプライベートカンファレンスを開催。その概要を紹介
2023年7月3日 6:00
足つぼマッサージ店が業務システムを外販?! グローバル化による新たなビジネス展開
2017年9月27日 17:00
シスコのDevNet担当者に訊いたコミュニティの育て方とは
2018年8月14日 10:55
社内の翻訳用語を自社製ツールで管理、サイボウズ社のローカライズ戦略
2017年9月28日 9:00
Authenticate 2023から、導入事例を紹介したISRのセッションをインタビューとともに紹介
2024年2月6日 6:00
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
