Cloud Operator Days Tokyo 2021開催、New Relicとドコモのセッションを振り返る
パフォーマンスモニタリングのNew RelicがNTTドコモのユースケースを解説する。
2021年11月17日 6:00
クラウドネイティブなシステムの運用側のエンジニアが集うオンラインカンファレンス「Cloud Operator Days Tokyo 2021」が7月14日から配信を開始した。これはオンライン配信によるカンファレンスとなるが、通常のオンラインカンファレンスとは異なり、8月後半までの間に閲覧者による人気投票と審査員による評価を行い、アワードという形で視聴者も参加できる点が特徴となっている。54のセッションは「大規模システム運用」「運用苦労話」「運用自動化」「社内基盤」に分かれている。
また通信事業者の運用エンジニアによるミートアップ「Cloud Native Telecom Operator Meetup」と共同開催となっており、そちらのセッションも併設している形になる。
公式サイト:Cloud Operator Days Tokyo 2021
事前の解説記事:運用者目線で最新のクラウドネイティブなシステムを語るCloud Operator Days Tokyo 2021開催
ユーザーに語ってもらうスタイルのセッション
今回はNew Relicが、顧客であるNTTドコモと共同で行った2つのセッションを紹介したい。
動画:SREだけでサービスレベルを向上する方法 NTT ドコモ イノベーション統括部が実現したサービスレベル向上のユースケース
動画:SREのはじめ方 NTTドコモ サービスデザイン部"RAFTEL"が実践するサービスレベルの計測と可視化
どちらのセッションもNTTドコモの社名がタイトルに表記されているが、実際にはNew Relicのエンジニアが自社サービスの解説を行った後、顧客であるNTTドコモのシステムについてドコモのエンジニアが語るという構成になっている。プレゼンテーションをリードするのはNew Relicのシニアソリューションアーキテクトの清水毅氏、NTTドコモの宮川倫氏と神崎由紀氏だ。
New Relicは、2008年に創業したSaaSベースのパフォーマンスモニタリング&解析のベンチャーである。過去にアメリカ及び日本支社でのインタビューを行っているので参考にして欲しい。
アメリカで行ったインタビュー記事:ObservabilityのNew Relic、創業秘話と新しいプラットフォームについて語る
日本法人のメンバーに対して行ったインタビュー記事:パフォーマンス管理のNew Relicが掲げる「エンタープライズファースト」戦略とは?
この二つのセッションを取り上げたのは、ベンダーがユーザーを巻き込んで自社サービスの優位性をユーザーに語らせるというフォーマットが、非常に良く実践されているからだ。ベンダーが自社サービスや製品を語る場合、どんなに熱弁を奮っても「自社の宣伝」という立ち位置を超えるのは難しい。しかし同じ内容でも、自社での導入経験を元にユーザーが語るのであれば、その説得力は桁違いに大きくなる。ベンダーが自社製品のユースケースをオウンドコンテンツとして非常に重要視するのはそのためだ。さらにユーザーが業界で名の通った企業であればあるほど、説得力も増すことになる。
そういう意味ではNTTドコモのユーザー事例を使ったNew Relicは最適な選択をしたと言える。またこのオンラインカンファレンスでは、セッションの時間は20分が標準だが、New Relicはそれを2つつなげて40分という時間を使って2つのセッションを行っている。これはNew Relicがスポンサー枠を最大限に利用したと評価するべきだろう。
SREのはじめかた
最初に紹介するのは、NTTドコモの社内システムにおけるAPIゲートウェイに関する事例だ。SREを自社に作る際にために最初に意識するべきなのは観測性(Observability)であるというNew Relicにとっては当然の切り口から始まっている。

「SREのはじめかた」というタイトルのセッション
このセッションの目的として、SREの理解と並んで「サービスレベル計測の必要性理解」と書かれているのは、パフォーマンスモニタリングをサービスの根幹とするNew Relicらしいと言える。

SREにはモニタリングが必要であることを訴求する内容
清水氏は多くのビジネスがITによる変革を必要とするようになるとして、ソフトウェアがビジネスを変えていくことを訴求し、そのためには開発したソフトウェアを素早くビジネスに反映できる仕組み、すなわちDevOpsが必要となることを訴求した。一方で、DevOps自体は開発側と運用側において課せられたミッションが異なるとして、対立構造になりがちであることを指摘した。
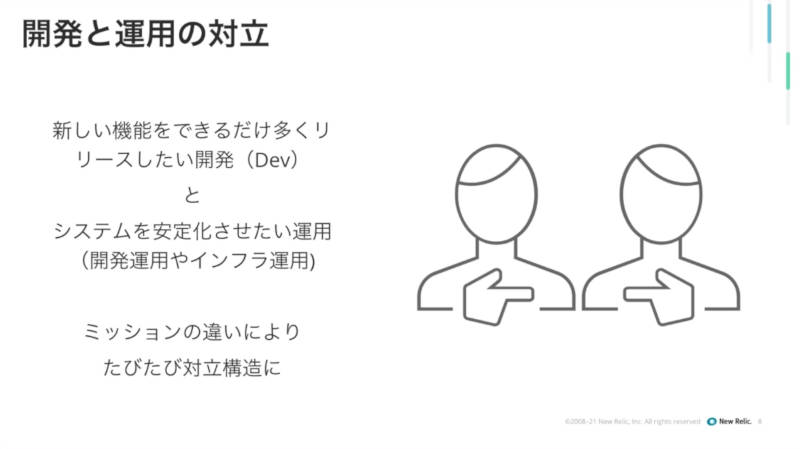
DevOpsの難しさにも軽く触れる
ただどのように組織がそれを実践したとしても、ITの視点からはサービスレベルを定義してそれを維持することを目標とするべきだとする。そのために、Googleが自社組織に導入したSite Reliability Engineering(SRE)を組織として提案。そこから、ビジネスを支えるシステムにおける運用の指針として単に稼働しているというだけではなく、ビジネスサイドが理解できるサービスのレベルを定義し、それを計測、最終的にその値がビジネスサイドと折り合いがつくのかを考えるべきであると解説した。
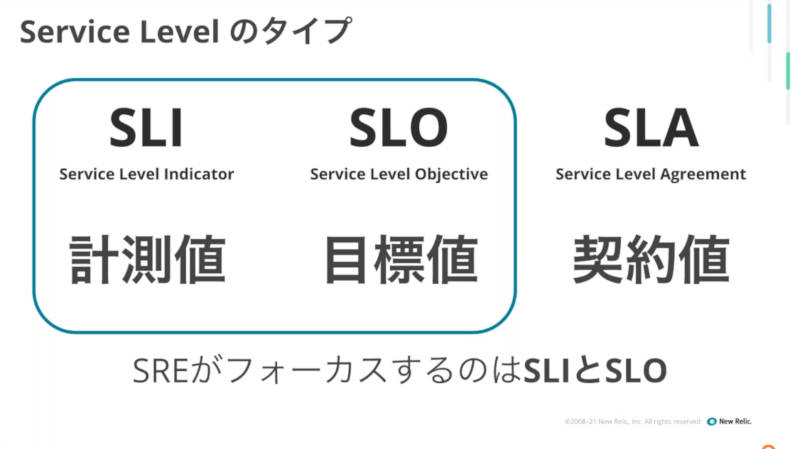
SLI、SLO、SLAを紹介
ここではシステムを運用する側、つまりSREはSLIとSLOに注目するべきであるとして、顧客であるNTTドコモの宮川氏にプレゼンテーションを交代した。

宮川氏がNTTドコモの所属部署を紹介
ここからはNTTドコモの社内システム、RAFTELの紹介が始まった。ここで注目すべきなのは、ドコモが提供するサービスを規格するビジネス部と実際にソフトウェアを開発するSIerの中間に、サービスデザイン部が存在しているという部分だろう。
これは後半の神崎氏のプレゼンテーションを見てもわかるが、ドコモの社内にはソフトウェアを開発するエンジニア、プログラマーは非常に少なく、ドコモ側は企画と設計、運用&管理を主に担当し、開発は外部のSIに発注していると想像できる。ドコモ社内のGitHubの有料アカウントは50人である一方、プロジェクト管理に関わるサービスのユーザー数はBacklogやSlackが18000人、JIRAが2000人という規模であることからもそれは類推できる。
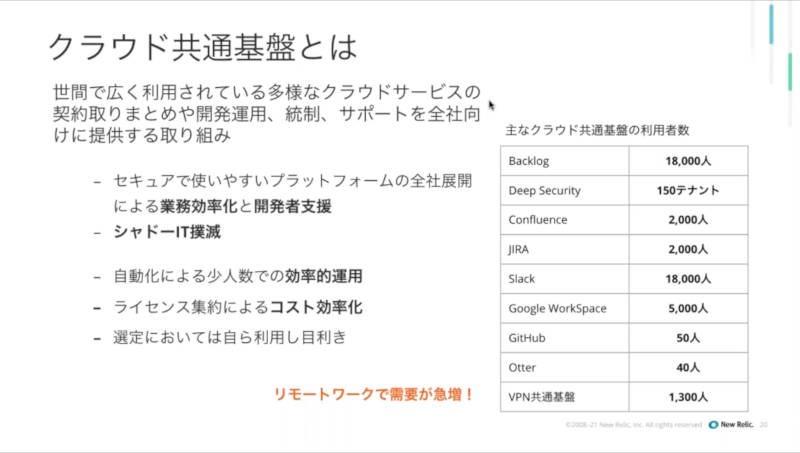
神崎氏のプレゼンテーションから。ドコモ社内の有料サービスのユーザー数概要
RAFTELのシステム概要について宮川氏が解説したのがこのスライドだ。

RAFTELの概要
RAFTELはドコモのサービスと社内の基盤システムを仲介するAPIゲートウェイとして機能することで個々のサービスが利用する認証やペイメントなどのシステムと個別に接続を行う必要性を下げ、開発を効率化できたと解説した。
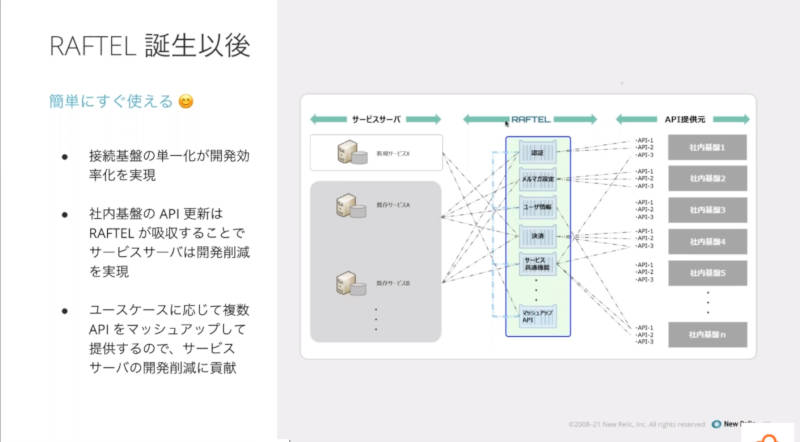
サービスと社内基盤の中間に位置するRAFTEL
次のシステム図はNew Relic導入前のシステム構成を表しているが、API GatewayはGoogleが買収したApigeeで、Tanzu Application Serviceと命名されているのはPivotalのCloud FoundryがVMwareに買収された以降の名称であることから、Cloud Foundryがベースになっていることが見てとれる。モニタリングや可視化にはElasticのOSSやGrafana、Kibana、Zipkinなどが利用されている。
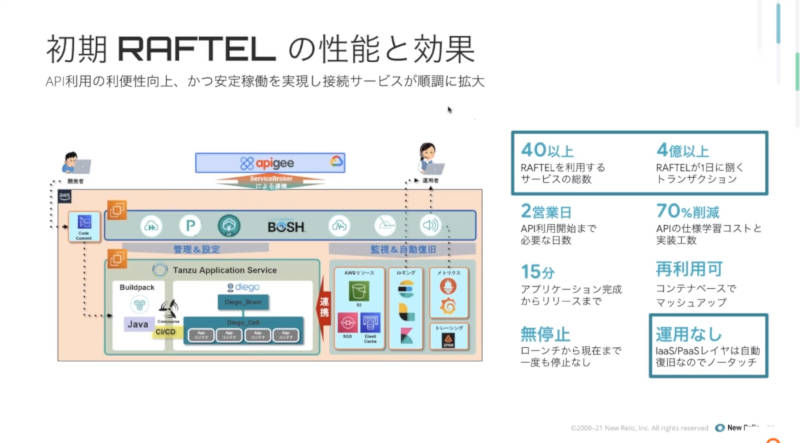
RAFTELはAWS上に構築されたCloud FoundryとApigeeで構成されているようだ
ここからはNew Relicを使ったことによる効果を解説した。

New Relicを使った効果を解説
このスライドでは導入検証においてNew Relicの清水氏の大きな貢献が「圧倒的感謝」という文字で表現されている。
また実際にNew Relicのダッシュボードでサービスレベルの値がどの程度なのかを商用環境、検証環境で紹介し、実際にSLI、SLOがどの程度なのかを解説した。
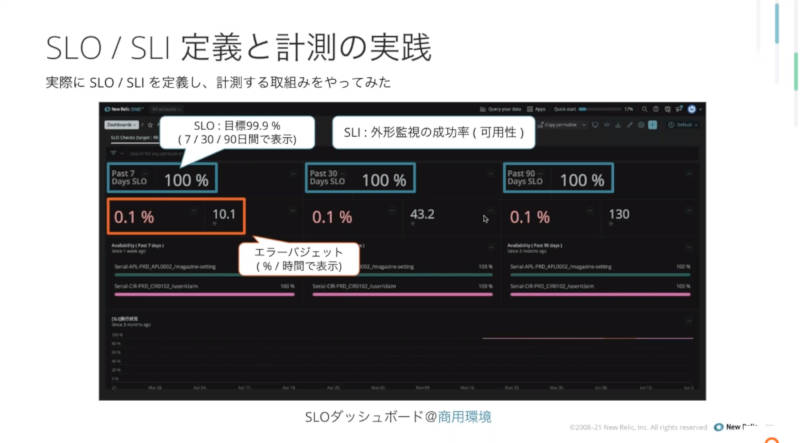
本番環境でのSLI/SLO
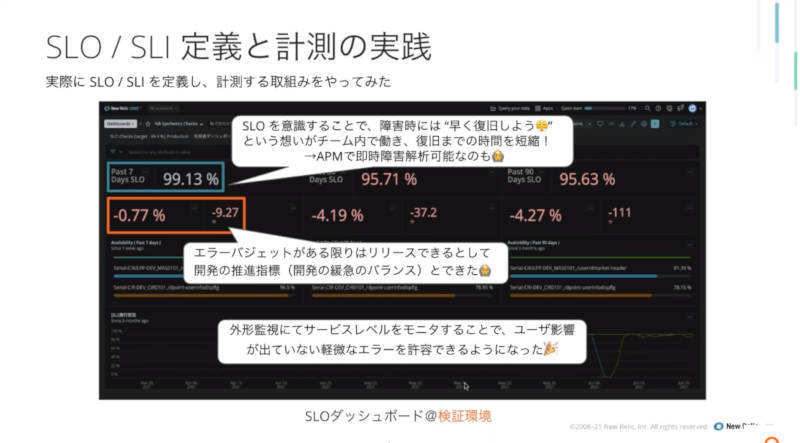
検証環境でのSLI/SLO
また今後の予定としてサービスデザイン部が担当するAPIゲートウェイ部分だけではなく、ドコモ社内の基盤側にもNew Relicを導入し、サービス全体をカバーする予定であることを紹介した。
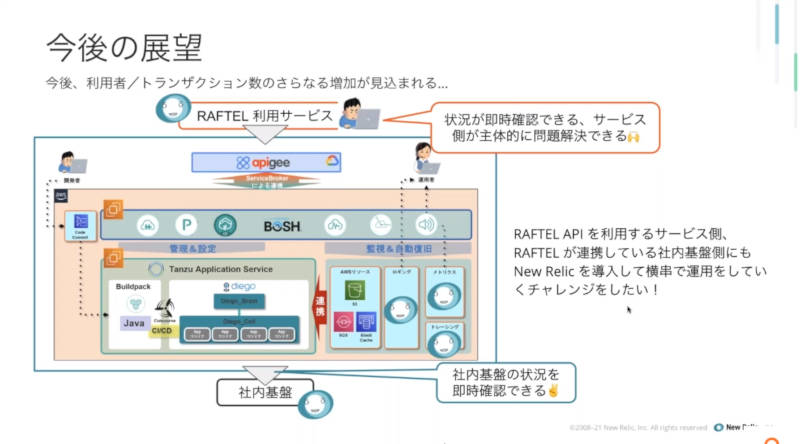
今後の展開予定を紹介
SREだけでサービスレベルを向上する
次の清水氏と神崎氏による「SREだけでサービスレベルを向上する方法」と題されたセッションでは、デジタルによるビジネス変革、SREの定義からNew Relicが提供するサービスの概要まで踏み込んで解説を行った後に神崎氏によるユースケースの解説となった。

NTTドコモイノベーション統括部のユースケース
清水氏はNew Relicが提供するNew Relic Oneについて解説し、APM(Application Performance Monitoring)についても解説を行った。これはこの後に登場する神崎氏がNew relicのAPMのユースケースであることの下準備としては充分な内容だろう。
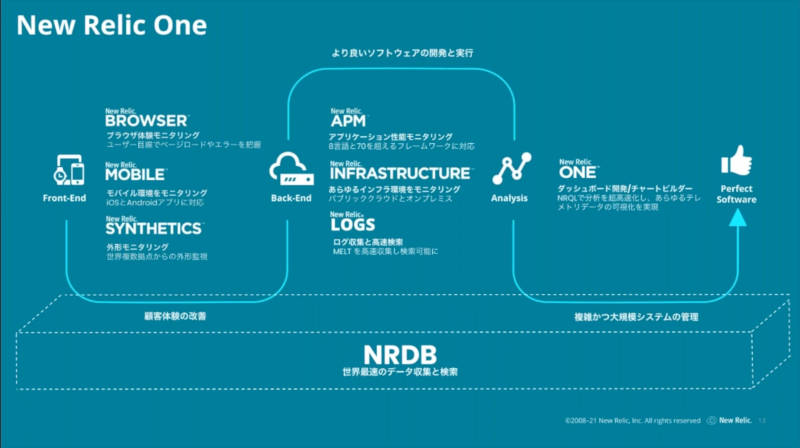
New relicのサービス全体を紹介
New RelicのAPMに絞って紹介。
神崎氏は最初に所属するイノベーション統括部、クラウドソリューション担当の職務について説明。主にパブリッククラウドを利用する際のコンサルティングやツールの提供、ユーザーの管理などを担当していることを紹介した。

NTTドコモ イノベーション統括部を紹介
そして今回のユースケースとなったBacklogの概要を紹介し、プロジェクト管理ツールとして社内に18000人のユーザーが利用していることを紹介した。これは開発部だけではなくビジネスを提供する側でも利用されていたとして、コロナ禍の中でトラフィックが増加していたと解説した。

Backlogの問題を解決するためにNew Relicを導入
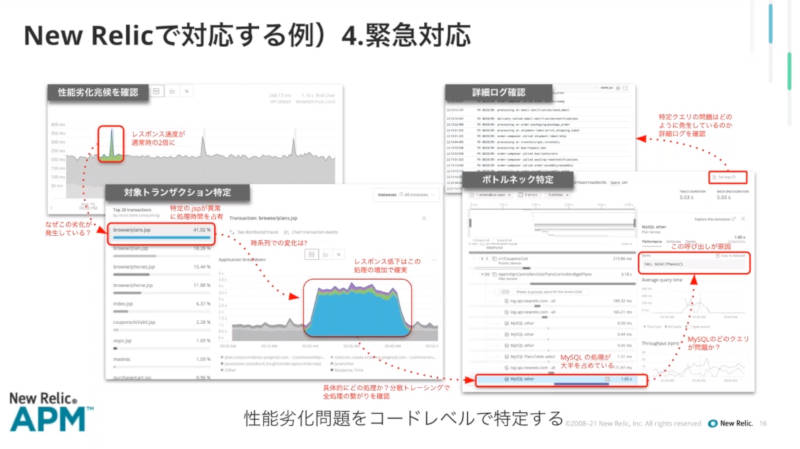
このスライドで注目したいのは「New Relicはアプリケーションパフォーマンスモニタリングのデファクトスタンダード」であると、NTTドコモの社員に語らせていることだろう。大規模なBacklog運用時における性能低下をある程度は対処できたものの、New Relic導入前は根本的な原因を解明できなかった。それがNew RelicのAPMによって、ボトルネックとなっている部分を見つけることができたと解説した。
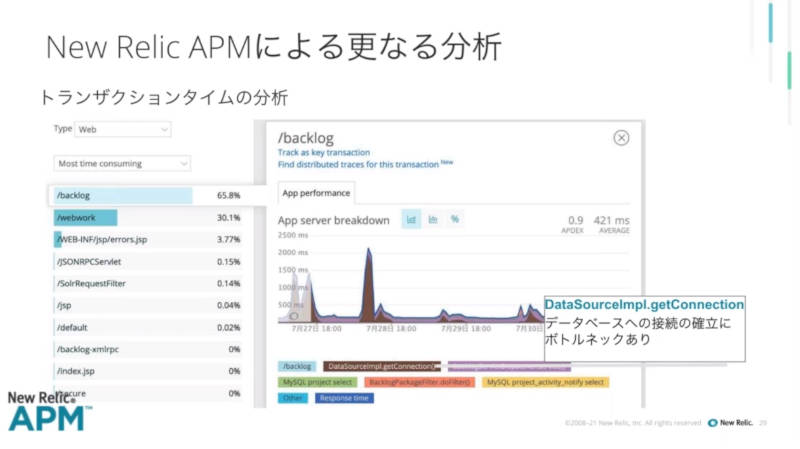
データストアであるMySQLのコネクションプーリング数に問題があった
問題解決までのプロセスも紹介し、トランザクション単位で可視化ができたことで問題を解決できたと説明した。
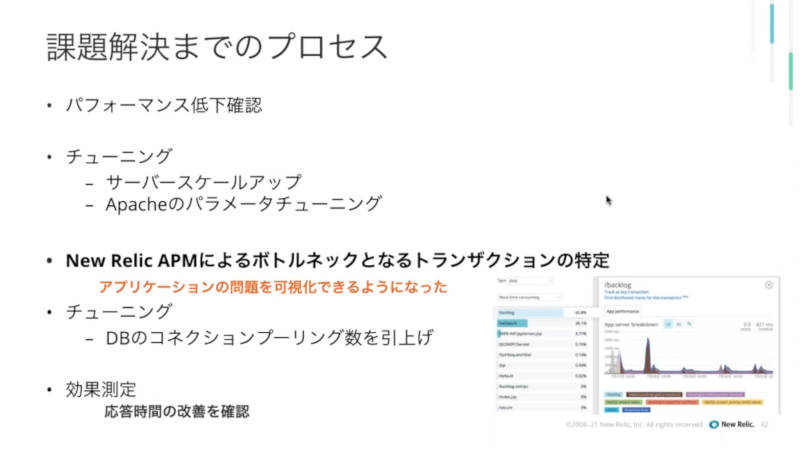
問題解決までのプロセスを紹介
この2つのセッションは40分という時間を効果的に利用して、DevOps、SREの解説、New Relicの宣伝、ユースケースである顧客の生の声で効果を訴求、最後にもう一度、可視化や計測性の重要性を訴求するという、定番のフォーマットで統一されている、ベンダーが顧客の口を借りて最大限に自社サービスの優位性を訴えるという目的のためには、最良の内容となったと言える。ただし、実際には機能だけではなくコスト面での分析なども必要となるだろうが、その部分は丁寧に割愛されていることも知っておくべきだろう。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
