TFMA以外のTensorFlowエコシステムで利用できるモデル分析ツールについて、簡単に紹介します。
Fairness Indicatorは、TFXのアドオンとして利用できるモデル分析ツールです。機能としてはTFMAとオーバーラップする部分が多いですが、有用な機能の一つとして、カットオフ値を変えながら、特徴量でスライスした指標を確認できる点が挙げられます。
次のようにEvaluatorの結果をFairness Indicatorに与えることで、対話的にモデル分析ができます。カットオフ値を変更しながら指標を確認するためには、Evaluatorの設定にカットオフ値を定義する必要があります。
01 | fairness_eval_config = tfma.EvalConfig( |
02 | model_specs = [tfma.ModelSpec( |
03 | label_key='income_xf', |
04 | preprocessing_function_names=['transform_features'] |
06 | slicing_specs = slices, |
08 | tfma.MetricsSpec(metrics=[ |
09 | tfma.MetricConfig(class_name='ExampleCount'), #サンプル数 |
10 | tfma.MetricConfig(class_name='Precision'), |
11 | tfma.MetricConfig(class_name='Recall'), |
12 | tfma.MetricConfig(class_name='F1Score'), |
13 | tfma.MetricConfig(class_name='AUC'), |
14 | tfma.MetricConfig(class_name='FalsePositives'), |
15 | tfma.MetricConfig(class_name='TruePositives'), |
16 | tfma.MetricConfig(class_name='FalseNegatives'), |
17 | tfma.MetricConfig(class_name='TrueNegatives'), |
18 | tfma.MetricConfig(class_name='FairnessIndicators', |
19 | config='{"thresholds": [0.25, 0.5, 0.75]}') |
カットオフ値を定義したEvaluatorの設定を使用してFairness Indicatorによる分析をするためのEvaluatorを実行します。
1 | fairness_evaluator = tfx.components.Evaluator( |
2 | examples = example_gen.outputs['examples'], |
3 | model = trainer.outputs['model'], |
4 | eval_config = fairness_eval_config) |
5 | context.run(fairness_evaluator) |

図2-7:Fairness Indicator用のEvaluator実行結果
Evaluatorの実行結果をもとに、Fairness Indicatorを実行します。
1 | fairness_eval_result = fairness_evaluator.outputs['evaluation'].get()[0].uri |
2 | fairness_tfma_result = tfma.load_eval_result(fairness_eval_result) |
4 | tfma.addons.fairness.view.widget_view.render_fairness_indicator(fairness_tfma_result) |
実行すると次のような画面が表示されます。この画面でカットオフ値の選択やスライスする特徴量の選択ができます。
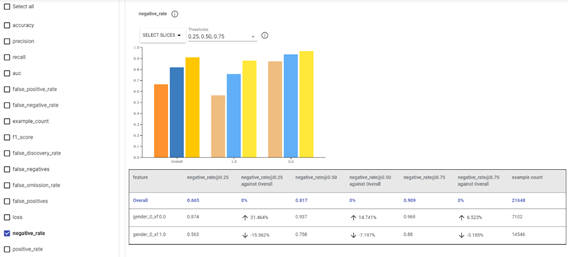
図2-8:Fairness Indicator
What-If Toolは、モデルの動作をより詳細に調べることができるツールです。このツールの有用な機能の一つとして、ある特徴量のデータを変更させると予測結果がどのように変わるのかという検証を、GUI操作で可視化しながら行える点が挙げられます。
What-If Toolを使用するためには、TFMAと同様にJupyter notebookの拡張機能をインストールして有効化する必要があります。
2 | !jupyter nbextension install --py --symlink witwidget --user |
3 | !jupyter nbextension enable --py witwidget |
5 | from witwidget.notebook.visualization import WitConfigBuilder |
6 | from witwidget.notebook.visualization import WitWidget |
「データ分割」のステップで出力した評価用データセットと、前回「チューニング」のステップで作成した学習済みモデルを読み込みます。データセットはサンプリングして1000個のデータだけを使用するようにします。サンプル数が多いとモデルの理解が難しくなってしまうためです。
1 | example_gen_train_uri = os.path.join(example_gen.outputs['examples'].get()[0].uri, 'Split-eval') |
2 | example_gen_train_tf_filenames = [os.path.join(example_gen_train_uri, name) |
3 | for name in os.listdir(example_gen_train_uri)] |
4 | wit_eval_data = tf.data.TFRecordDataset(example_gen_train_tf_filenames, compression_type="GZIP") |
5 | wit_eval_samples = [tf.train.Example.FromString(d.numpy()) for d in wit_eval_data.take(1000)] |
7 | model_dir = os.path.join(trainer.outputs['model'].get()[0].uri, 'Format-Serving') |
8 | wit_model = tf.saved_model.load(export_dir=model_dir) |
次にモデルの予測関数を作成します。
2 | test_examples = tf.constant([example.SerializeToString() for example in examples]) |
3 | preds = wit_model.signatures['serving_default'](examples=test_examples) |
4 | return preds['outputs'].numpy() |
What-If Toolの設定を作成し、設定をもとにノードブックで可視化をします。
1 | config_builder = WitConfigBuilder(wit_eval_samples).set_custom_predict_fn(predict) |
2 | WitWidget(config_builder) |
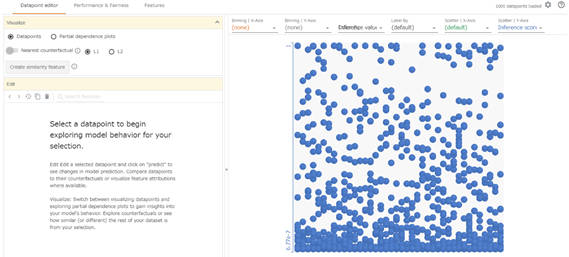
図2-9:What-If Tool
ここまでノートブック上でモデル検証を行ってきましたが、自動化された機械学習パイプラインでは、これらの検証を自動的に実行し、モデルの性能指標が要件を満たすことが確認できたら本番環境へデプロイするといった制御を行うことが重要です。Evaluatorでは、祝福(blessing)という概念を使って、予め定義した性能指標の閾値に基づいて、要件を満たしていることがわかった場合にそのモデルは祝福されて次のステップに進むという制御ができます。
次の例では、Evaluatorの設定にAUCが0.7以上で祝福し次のステップに進むという定義をしています。
01 | blessing_eval_config = tfma.EvalConfig( |
02 | model_specs = [tfma.ModelSpec( |
05 | slicing_specs = [tfma.SlicingSpec()], |
07 | tfma.MetricsSpec(metrics=[ |
08 | tfma.MetricConfig(class_name='AUC', |
09 | threshold=tfma.MetricThreshold( |
10 | value_threshold=tfma.GenericValueThreshold(lower_bound={'value': 0.70}) |
AUCの閾値を定義したEvaluatorの設定を使用して、Evaluatorコンポーネントを実行します。
1 | blessing_evaluator = tfx.components.Evaluator( |
2 | examples = transform.outputs['transformed_examples'], |
3 | model = trainer.outputs['model'], |
4 | eval_config = blessing_eval_config) |
5 | context.run(blessing_evaluator) |
図2-10:モデル検証の自動化をするEvaluatorの実行結果
結果は次のようにして確認できます。
1 | blessing_result = blessing_evaluator.outputs['evaluation'].get()[0].uri |
2 | tfma.load_validation_result(blessing_result) |
閾値以上の指標を満たし、祝福されると次のような結果を返却します。

図2-11:Evaluatorにより祝福された結果
学習済みモデルの出力
PusherというTFXコンポーネントを使って、学習済みモデルの出力を機械学習パイプラインに組み込む方法について解説します。
- Pusherとは
Pusherは学習済みモデルを保存する場所にアップロード(プッシュ)するTFXコンポーネントです。Evaluatorがそのモデルを祝福したかどうかをチェックし、祝福されていればPusherは指定された場所にモデルをアップロードします。
Pusherは主に次の入力を必要とします。
- 「モデル検証」のステップで検証済みのモデル
- Evaluatorコンポーネントの出力
- モデルを保存する場所(アップロード先のファイルパス)
まずはモデルを保存する場所を定義します。今回はMinIOにアップロードするようにします。
1 | param_push_destination = {"filesystem": {"base_directory": "%s/serving_model" % bucket_name_s3_prefix}} |
Pusherコンポーネントを実行します。
1 | pusher = tfx.components.Pusher( |
2 | model=trainer.outputs['model'], |
3 | model_blessing=evaluator.outputs['blessing'], |
4 | push_destination=param_push_destination) |
図2-12:Pusherの実行結果
モデルが指定された場所に正常にアップロードされると、モデルはデプロイ可能な状態になります。
おわりに
今回は「モデル作成」の最後のステップとなる「モデル検証」と「学習済みモデル」の出力についてTFXコンポーネントの解説と実装を行いました。次回はここまで実装したモデル開発のパイプラインをKubeflow上で実行するための手順の解説や、その運用において活用できるKubeflow Pipelinesの機能とTFXコンポーネントの機能について解説します。












