高度なデプロイ方法(カナリアリリース)
高度なデプロイ方法(カナリアリリース)
カナリアリリースを実現するためには、InferenceServiceに「canary」と「canaryTrafficPercent」の設定を追加する必要があります。
- canary:カナリアリリースで、一部リクエストを受信する新しいモデルサーバーの設定
- canaryTrafficPercent:新しいモデルサーバーにリクエストを振り分ける割合(パーセンテージ)
これを踏まえてノートブックを開き、先ほど作成したInferenceServiceにカナリアリリースに関する定義を追加します。
isvc_yaml = '''
apiVersion: serving.kubeflow.org/v1alpha2
kind: InferenceService
metadata:
annotations:
sidecar.istio.io/inject: "false"
prometheus.io/scrape: "true"
name: {}
spec:
default:
predictor:
minReplicas: 1
serviceAccountName: kubeflow-minio-sa
tensorflow:
runtimeVersion: 2.5.1
storageUri: {}
resources:
requests:
cpu: 0.1
memory: 1Gi
limits:
cpu: 1
memory: 1Gi
logger:
mode: all
url: http://message-dumper.anonymous.svc.cluster.local
canary:
predictor:
minReplicas: 1
serviceAccountName: kubeflow-minio-sa
tensorflow:
runtimeVersion: 2.5.1
storageUri: {}
resources:
requests:
cpu: 0.1
memory: 1Gi
limits:
cpu: 1
memory: 1Gi
logger:
mode: all
url: http://message-dumper.anonymous.svc.cluster.local
canaryTrafficPercent: {}
'''
カナリアリリースに関連するパラメータとして、使用する新しいモデルの格納先のパスと、リクエストの振り分けパーセンテージを設定しました。このパラメータを考慮して、KFServingコンポーネントのPython関数も修正します。
@dsl.pipeline(
name='census_income_kfserving',
description='A canary pipeline for KFServing.'
)
def kfserving_pipeline(model_name: str='census-income',
default_model_uri: str='s3://census-income/serving_model',
canary_model_uri: str='s3://census-income/serving_model_v2',
canary_traffic_percent: int=30):
kfserving_op(
action='apply',
model_name=model_name,
namespace='anonymous',
inferenceservice_yaml=isvc_yaml.format(model_name, default_model_uri,
canary_model_uri, canary_traffic_percent)
).execution_options.caching_strategy.max_cache_staleness = "P0D"
InferenceServiceの定義を修正し、改めてyamlファイルを出力します。
kfserving_pipeline_canary_yaml_file = os.path.join(yaml_dir, 'kfserving_pipeline_canary.yaml')
compiler.Compiler().compile(kfserving_pipeline, kfserving_pipeline_canary_yaml_file)
出力したパイプラインの定義ファイル(yamlファイル)を先ほどと同様にダウンロードし、Kubeflow Pipelinesにアップロードしてパイプラインを作成します。作成したパイプラインは次のようになります。

図3-8:カナリアリリースを行うパイプライン
・パイプラインの設定画面
パイプラインの設定画面を確認するとRun Parameters「canary_model_uri」と「canary_traffic_percent」の2つが追加されたことがわかります。
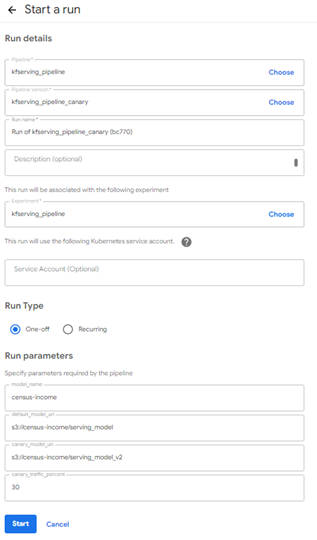
図3-9:カナリアリリースを行うパイプラインの実行設定
今回はデフォルト値のままInferenceServiceを作成しますが、パイプライン実行前にこの2つのパラメータを変更するだけで、カナリアリリースに関する設定を変更することができます。「Start」ボタンをクリックして、パイプラインを実行します。
・パイプラインの実行状況を確認
パイプラインの実行結果のLogsにて、「DEFAULT_TRAFFIC」が70、「CANARY_TRAFFIC」が30となっていることが確認できます。これにより、リクエストの振り分け設定の割合が確認できます。
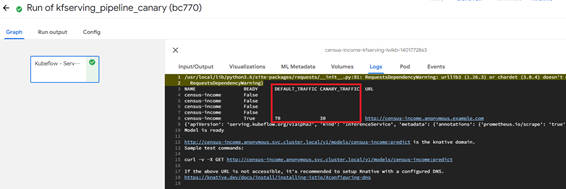
図3-10:カナリアリリースを行うパイプラインの実行結果画面
次に、実際に推論リクエストを送って、新しいバージョンのモデルサーバー (canary) に到達しているかログを確認してみましょう。
推論サービスの監視とログ出力
ここでは、推論サービスの監視とログ出力を行うための各種手順を解説します。
Inference Loggerを使った推論サービスのログ出力
Inference Loggerを導入するには、前述のInferenceServiceの定義内のloggerセクションにて設定したurlに対応する Message Dumperを作成する必要があります。なお、以下の手順は、Kubernetesクライアントのホスト上で実行します。
・Message Dumperの作成
まず、Message Dumperの定義(yamlファイル)を作成します。
cat <<EOF > message_dumper.yaml
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
annotations:
sidecar.istio.io/inject: 'false'
prometheus.io/scrape: "true"
name: message-dumper
labels:
app: message-dumper
spec:
template:
metadata:
annotations:
sidecar.istio.io/inject: 'false'
spec:
containers:
- image: gcr.io/knative-releases/knative.dev/eventing-contrib/cmd/event_display
EOF
yamlファイルを適用して、Message Dumperを作成します。
kubectl apply -f message_dumper.yaml -n anonymous
これでMessage Dumperの作成が完了しました。次の手順で推論サービスのログを取得することができます。
・ログ出力の確認
ノートブックから再びリクエストを送信してログを取得してみます。ログを取得するには下記のコマンドを実行します。
!kubectl logs $(kubectl get pod -n anonymous -l serving.knative.dev/service=message-dumper -o jsonpath='{.items[0].metadata.name}') -n anonymous user-container
図3-11のようにサービングのログを取得することができます。
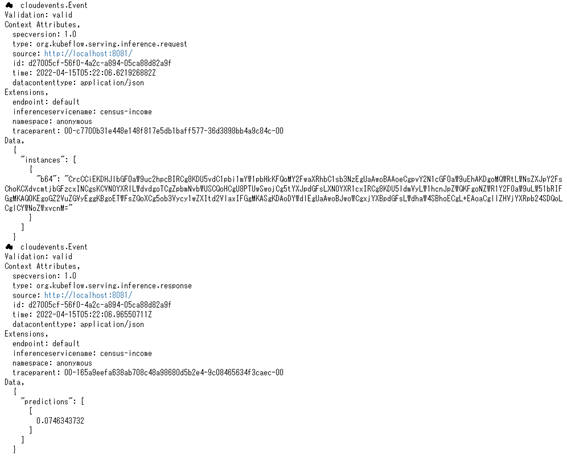
図3-11:Message Dumperで表示されるログ
さらに、ノートブックから何回かリクエストを送信した後に、ログ表示を確認してみると、リクエストが新しいバージョンのモデル(canary)に到達していることがわかります。

図3-12:canaryにリクエストが到達しているログ
本稿では、推論サービスのログ出力と取得までを解説しました。このログを分析して精度評価や可視化を行う方法については、次回解説する予定です。
PrometheusとGrafanaを使った推論サービスの監視
KFServingを使って構築した推論サービスは標準でPrometheusと連携でき容易に性能に関する指標を取得できますが、Grafanaを導入するとその推移など把握しやすくなります。ここではGrafanaを導入して可視化とダッシュボード化する手順を解説します。以下の手順は、再度Kubernetesクライアントのホスト上で実行します。
・Grafanaのインストール
Grafanaのインストールにはhelmを使用しますので、まずhelmをインストールします。
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
chmod 700 get_helm.sh
./get_helm.sh
次に、Grafanaをインストールします。Grafanaをインストールする先のNameSpaceとして新しく「monitoring」を作成します。
# Grafanaを構築するNameSpaceを作成
kubectl create namespace monitoring
helm repo add grafana https://grafana.github.io/helm-charts
helm install grafana grafana/grafana --namespace monitoring
インストールが完了すると図3-13のようなメッセージが出力されます。
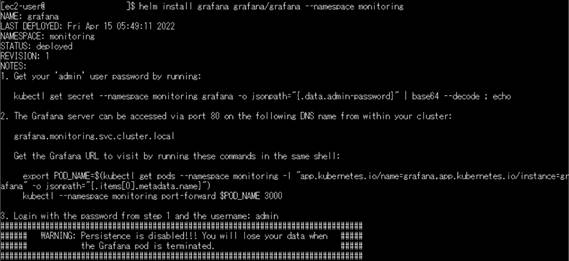
図3-13:Grafanaインストール完了時の出力メッセージ
出力されたメッセージに従い、Grafanaにログインするためのパスワードを取得します。
kubectl get secret --namespace monitoring grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
・Grafana UI
ブラウザからGrafanaにアクセスできるように、ポートフォワードの設定を行います。今回使用するポートは30080としています。
kubectl port-forward -n monitoring svc/grafana 30080:80
ブラウザから「http://localhost:30080」にアクセスするとGrafanaのログイン画面が表示されます。ユーザー名として「admin」を入力し、先ほど取得したパスワードも入力してログインします。

図3-14:Grafanaログイン画面
ログインすると、図のようなホーム画面が表示されます。
図3-15:Grafanaログイン後の画面
Prometheusと連携するために、左ペインのConfigurationから「Data Sources」をクリックします。
図3-16:Data Sources設定メニュー
「Add data source」ボタンをクリックします。
図3-17:ConfigurationのData Sources画面
さまざまなデータソースと接続することができますが、ここでは一番上にある「Prometheus」の項目をクリックします。
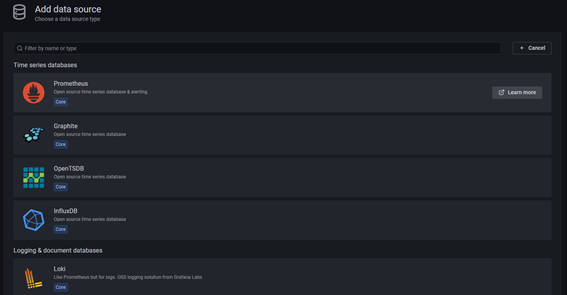
図3-18:Data Sources追加画面
Prometheusの接続設定画面に遷移します。ここで、URLの項目に「http://prometheus.istio-system.svc.cluster.local:9090」と入力します。入力する項目はこれだけなので、ページ下部にある「Save & test」ボタンをクリックして設定を保存しつつ、接続確認をします。
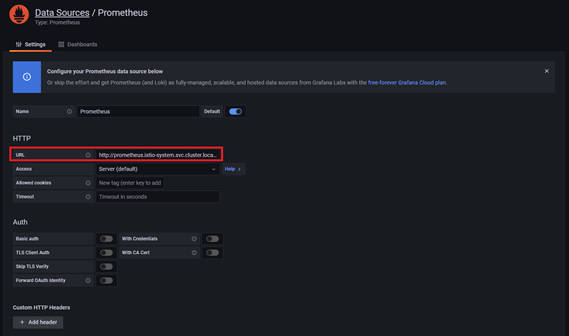
図3-19:追加するData Sources(Prometheus)の設定画面
ボタンクリック後に下図のように「Data source is working」と表示されれば、無事にPrometheusとGrafanaの接続が完了したことになります。
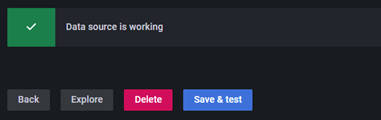
図3-20:Data Sourcesの追加完了
・ダッシュボードの作成
推論リクエストに対する応答時間(レイテンシ)を取得して、ダッシュボードとして可視化していきます。左ペインのCreateから「Dashboard」をクリックして、新しいダッシュボードを作成します。
図3-21:Dashboard作成メニュー
新しいダッシュボードが作成できました。「Add a new panel」をクリックしてレイテンシを表示するパネルを作成します。
図3-22:新規Dashboardの初期画面
画面下部にて取得するメトリクスのクエリを入力して、右上にある「Save」ボタンをクリックします。
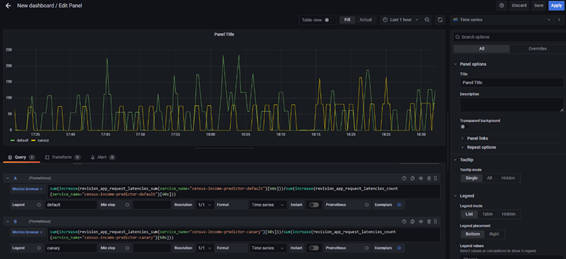
図3-23:Dashboardパネル作成画面
「Save」ボタンをクリックすると、ダッシュボート名を入力するポップアップが表示されるので、任意の名前を付けてから「Save」ボタンをクリックします。
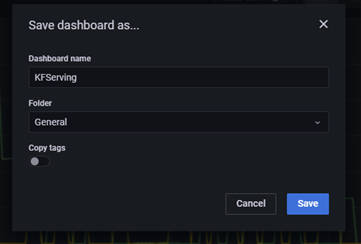
図3-24:Dashboard保存画面
これによりレイテンシを取得するパネルが作成でき、ダッシュボートでの可視化をすることができました。
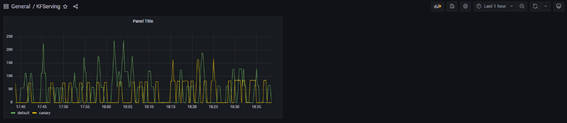
図3-25:作成したDashboardの画面
おわりに
今回は機械学習ワークフローの全体のうち機械学習モデルの運用についてKFServingを使ったモデルのデプロイを中心に解説しました。ここまでの解説で下図に示すコンポーネントをすべて紹介しました。
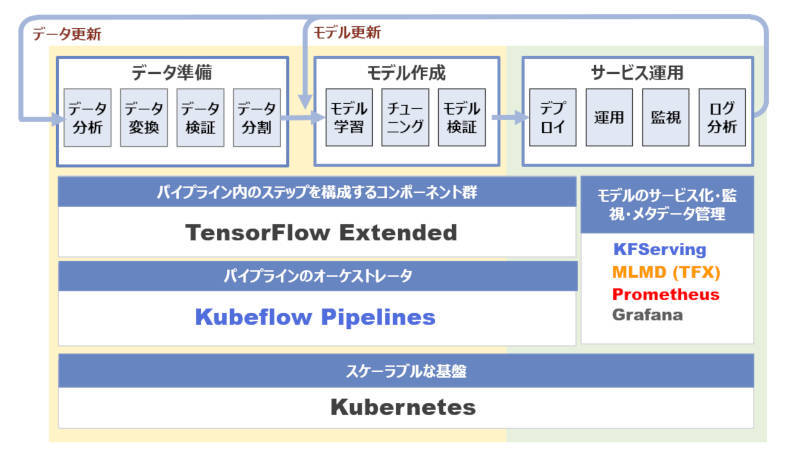
図4-1:Kubeflowで構築する機械学習プラットフォームの構成
次回は、機械学習モデルの開発と運用におけるパイプライン全体を協調動作させ、継続的にモデルを改善する仕組みの構築例や、データ・モデルの管理も含めた全体のアーキテクチャについて考察していきます。
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
