KubeCon Europe 2024開催。前日に開催されたAIに特化したミニカンファレンスを紹介
KubeCon Europe 2024の前日に開催されたAIに特化したミニカンファレンスを紹介する。
2024年5月9日 6:00
クラウドネイティブなオープンソースソフトウェアをテーマにした世界最大規模のソフトウェアカンファレンスKubeCon+CloudNativeCon Europe 2024が、2024年3月19日から22日までパリで開催された。
KubeCon Europe自体の3日間の会期に加えて、前日にはCo-located Eventとして多くのミニカンファレンスが開催された。

3月19日に行われたミニカンファレンスの一覧
このボードに書かれている共催イベントのリストから、その多様さを感じられるだろう。CNCFがホストするいくつかのプロジェクトに特化したミニカンファレンスに加えて、AIやWebAssemblyなどのテクノロジーやCNCFのプロジェクトに貢献しているコントリビューターのためのサミットなどが開催された。今回は過去最高の参加者数になるという告知が事前にされていたが、この日も多くの参加者が会場に集い、過去の共催イベントとは桁違いの参加者数となることが感じられた。その中から今回はCloud Native AI Dayのようすを紹介する。今回取り上げるのは午前中に行われたCERNの事例に関するセッションと、Red HatのOpenShift AIのマーケティング担当が解説する医療機関における事例のセッションだ。
CERNでの事例
最初のセッションは「Training & Optimisation of Large Transformer Models: ALTAS and CERN Use Case」、プレゼンテーションを行ったのはCERNのインフラストラクチャー担当であるRicardo Rocha氏とCERNのインフラストラクチャーを使って行われている研究のひとつATLASの概要を解説するオックスフォード大学の素粒子物理学者Maxence Draguet氏だ。
CERNについて

プレゼンターはオープンソースのカンファレンスではお馴染みのRicardo Rocha氏
Rocha氏は最初にCERNの概略を紹介し、そのコアであるLHC(Large Hadron Collider、大型ハドロン衝突加速器)については動画を用いて仕組みを示した。素粒子を光速に近い速度に加速し衝突させ、その反応を調べる世界最大の実験装置であるLHCでは短時間に大量のデータが採取され、その後スーパーコンピュータによって処理されるというのが概要だ。ちなみにLHCは円周の長さが27kmにも達し、これは山手線とほぼ同じ長さに相当し、地下100メートルに設置してあるという。

動画を用いてCERNの概要を紹介するRocha氏
Rocha氏はクラウドネイティブなソフトウェアをCERNがどのように使ってきたのか? について、線表を使って解説。実際にはカスタムメイドのハードウェアとソフトウェアによってHPCを実装してきたが、先端的なテクノロジーが商用CPUとGPUの利用に移行していった流れに沿って、Off the Shelf(既製品)のコンポーネントを使うようになってきたと説明。それと同時にKubernetesやSwarmなどのオーケストレーターの検証を始めたという。2016年から始まったという線表だが、CERNはOpenStackのユーザーとしても知られており、さまざまなプラットフォームを検証し利用していることがわかる。
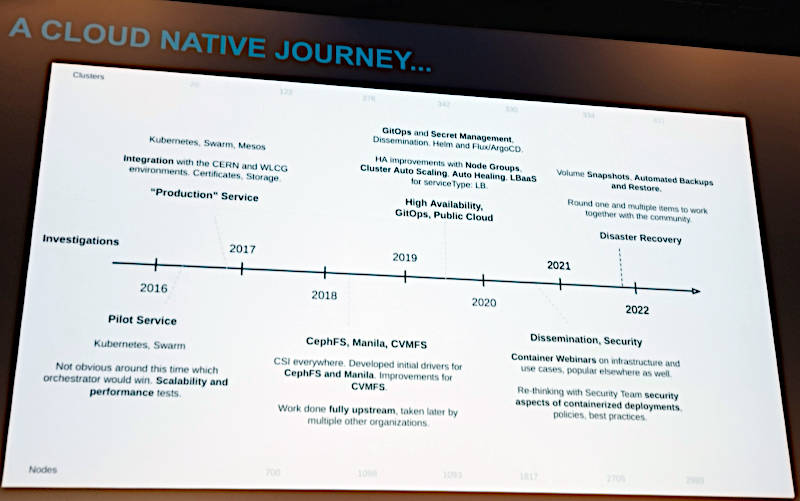
CERNにおけるクラウドネイティブなシステムの変遷
その中で特にこのセッションでは、CERNのHPCにおけるワークフローの中心となっているKubeflowについて解説を行った。

CERNで使われているクラウドネイティブなソフトウェアの紹介
ここではKubernetesやPrometheus、Cilium、ArgoCD、Fluentdなどのロゴが確認できる。そしてCERNの持つ課題としてHPCにおける電力消費と発熱、ハードウェアの進化のスピード、CPU/GPUとストレージのインターコネクトなどについて触れ、それらを満足させるためのソリューションが必要になっていると解説した。

オンプレミスとクラウド、オンデマンドとバッチのスケジューリングが可能な新しいインフラストラクチャーが必要
その中でKubernetesにおけるジョブのスケジューリングを実装するKueueについても簡単に触れ、HPCが要求するバッチジョブをKubernetes側から制御したいというCERNの要望が実現したことを説明した。
●参考:https://github.com/kubernetes-sigs/kueue
KueueはKubernetesのSIGの中で始まったサブプロジェクトで、Kubeflowとも連係することでHPCに必要なバッチ型のワークロードを実行できるようにすることが目的だ。
ATLASについて
そして後半はバトンタッチしたDraguet氏がATLASについて解説を行った。

ATLASについて解説するDraguet氏
ATLASはさまざまな形式のデータを変換する多層のモデルの実装型であり、モデルの学習のためには複数のGPUと大量のマルチタスクによるCPUタイム、具体的には1週間程度の実行時間が必要という大きなシステムである。
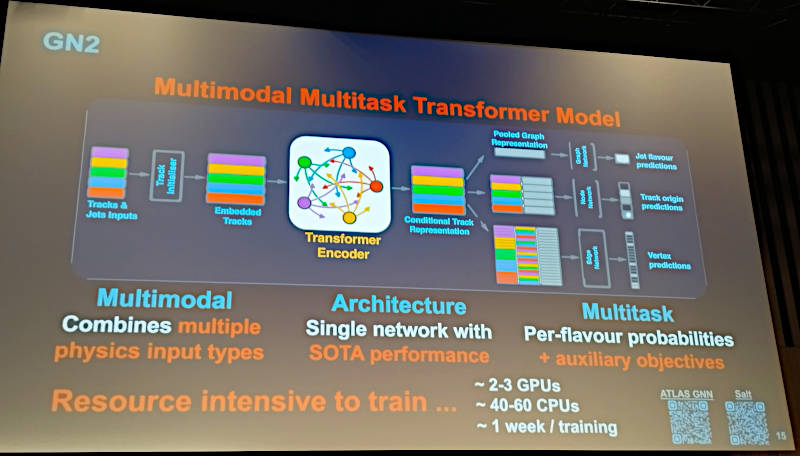
ATLASの処理の概要。大量のリソースと処理時間が必要
KubeflowがCERNの機械学習のコアのプラットフォームとなっているとして、その概要を解説。
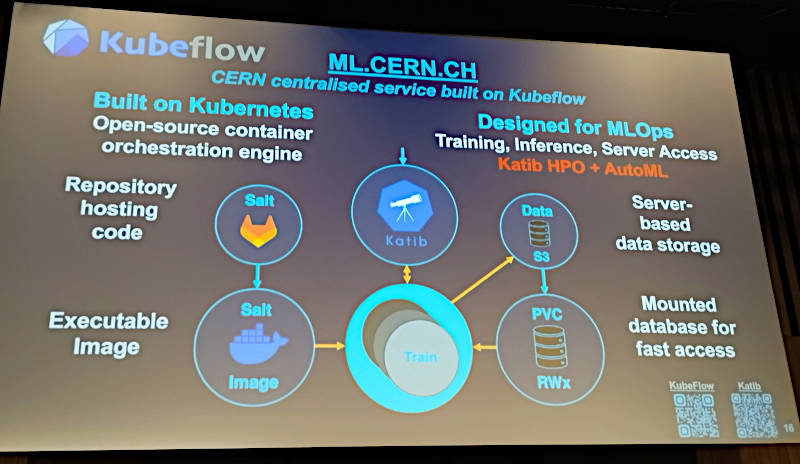
Kubeflowの概要を解説
Kubeflowは機械学習のワークロードをKubernetes上でスムーズに実装するためのツール群で、Pipeline、Notebook、Dashboard、AutoMLなどから構成されている。
ここからはハイパーパラメータの最適化の解説が主に行われ、数式に馴染みがない参加者(筆者を含む)にとっては辛い時間となったが、さまざまなパターンについてデータを採取して比較検討する姿勢はまさに研究者であり、それはKubeflowのセッティングにおいても変わらないことは理解できた。

Kubeflowとパラメータセッティングのまとめ
ハードウェアに依存しない機械学習の運用パターンが可能という点は、オンプレミスとクラウドサービスを使いこなしたい企業においては参考になるかもしれない。
セッションの動画は以下から参照して欲しい。
●動画:Training and Optimisation of Large Transformer Models: An ATLAS and CERN Use Case
- この記事のキーワード
この記事をシェアしてください
関連記事
KubeCon+CloudNativeCon Europe 2026開催。併設のカンファレンスからAIに特化したセッションを紹介
6月5日 6:00
KubeCon Europe 2025から、Red Hatが生成AIのプラットフォームについて解説したセッションを紹介
2025年6月19日 6:00
KubeCon North America 2024からAIワークロードのスケジューリングに関するセッションを紹介
2025年3月13日 6:00
KubeCon Europe 2024併催のCloud Native Wasm Dayから、FA機器にWebAssemblyを適用したセッションを紹介
2024年5月20日 6:00
KubeCon Europe 2024のキーノートからツァイスのWebAssemblyを使った事例を紹介
2024年5月24日 6:00
Kubernetesで機械学習を実現するKubeflowとは?
2018年6月1日 6:00
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
