Kubernetes上で機械学習のパイプラインを実装するKubeflowを紹介
Kuberentes上で機械学習を実装するKubeflowを紹介する。
2021年6月8日 7:12
Kubernetesの上で機械学習を実装するためのツール、Kubeflowを紹介する。今回、素材として使うのはCNCFが2020年2月28日に公開したWebinarの動画だ。CNCFはKubernetesのSIG Runtimeのミーティングの動画にもKubeflowに関するコンテンツを収録している。これはCNCFが、Kubeflowを機械学習の実装に要する大きなコストを吸収できるツールとして期待していることのあらわれであろう。
動画:Webinar: From Notebook to Kubeflow Pipelines with MiniKF & Kale
これは「From Notebook to Kubeflow Pipelines with MiniKF & Kale」と題して行われたもので、機械学習の実行に必要な周辺のタスク、データの準備やワークフローの作成など、実際に機械学習を実行する上で見落とされているものを、Kubeflowとその関連ツールがどのように埋めているのか? をデモを交えて解説している。

Kubeflow、Kale、MiniKFをデモを交えて紹介
セッションの登壇者はArriktoのエンジニアであるStefano Fioravanzo氏と、共同創業者でCTOのVangelis Koukis氏だ。Arriktoは2015年にギリシャのアテネで創業されたベンチャーで、Kubeflowとその縮小版であるMiniKF、機械学習のハイパーチューニングパラメーターを操作するためのKale、機械学習に特化したデータストレージであるRokなどをビジネスのコアとした企業で「Data as Code」を提唱していることでも知られている。
参考:Hello World, We're Arrikto!

機械学習の問題点はモデル設計以外の仕事が多いこと
ここで機械学習を実行するためのワークフローを定義することが難しく、それを本番環境で実行するのはさらに難しく、そして現在のエンタープライズ企業が求めるマルチクラウドで実装するのは非常に困難であることが問題だと解説した。
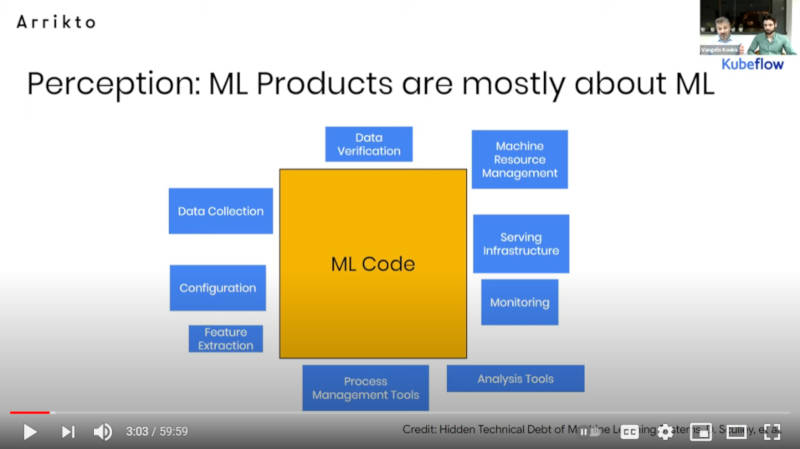
データサイエンティスト以外が考える機械学習のタスク量
このスライドでは、機械学習を実装するためには多くの時間がモデルの作成に使われていると思われているが、実際には違うと訴求した。
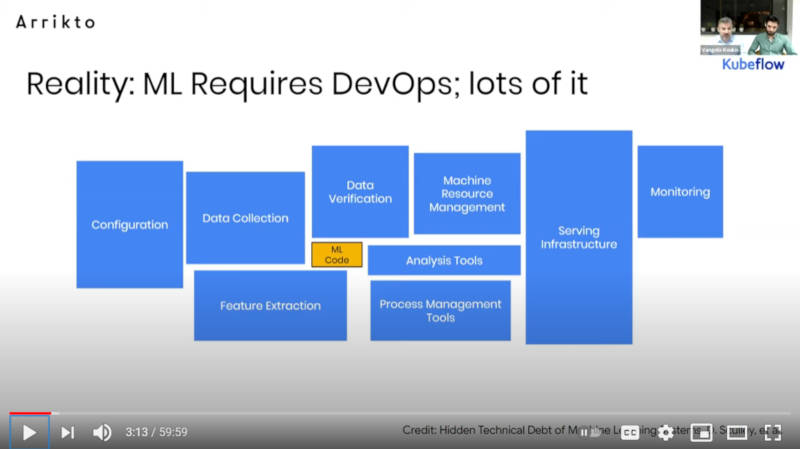
実行に必要なのは機械学習モデルそのものよりもその周辺のタスク
そしてどうして「Kubeflowを開発したのか?」を解説したのが次のスライドだ。

Kubeflowを作った背景
エンドツーエンド、イージーオンボーディングなどはデータサイエンティストにとって簡単に使い始められることを示唆している。またコンテナ化によるパッケージングというポイントは、オンプレミスとパブリッククラウドを行き来したいユーザーには訴求する点だろう。そしてこの後のデモでも見せていた途中でスナップショットを取ってやり直せる実験的な手法を取れるというのが、Arriktoが商用ソフトウェアとして提供するRokの機能だが、ここでは地味に訴求されているのが興味深い。
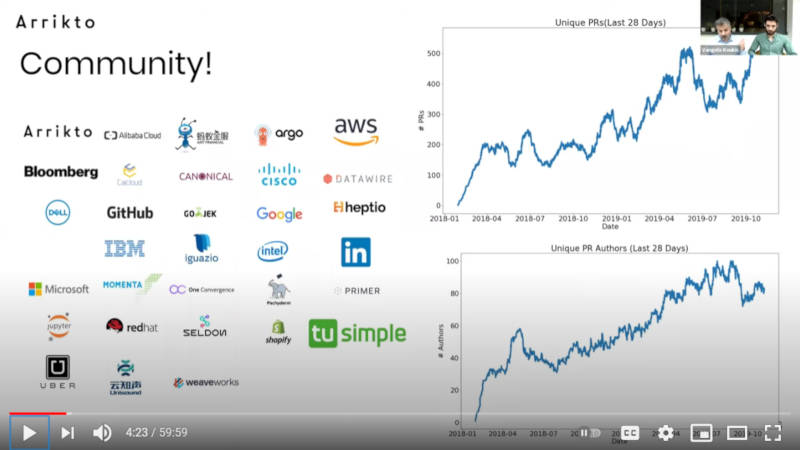
Kubeflowのコミュニティは拡大中
Kubeflowのコミュニティも拡大していることを見せたのが次のスライドだ。Arriktoはもちろんのこと、Microsoft、Google、AWS、IBM、Cisco、Bloombergなどもユーザーとして挙げられている。

企業が何に対して貢献しているのかを例として表示
このスライドではKubeflowだけではなく、Kubeflowの中で利用されているJupyter notebookやサービスメッシュのIstio、パイプラインで利用されているCDツールのArgo、Kubernetesに特化した機械学習のフレームワークであるSeldon Coreなども挙げられており、Kubeflowが数多くのソフトウェアから成り立っていることを示している。
ここからは、機械学習の例として知られているタイタニック号の生存者を予測するモデルをベースにデモを行った。

タイタニック号の生存者予測をベースにデモを実施
デモの最初のパートはKubeflowのインストールに費やされていたが、ここではArriktoが力を注いているMiniKFの解説をしておこう。

MiniKFはKubeflowを1ノードで稼働させるミニ版
このスライドにある通り、MiniKFは1ノードでKubeflowを稼働させるいわばKubeflowのミニ版だ。1ノードでKubernetesを実装するMinikubeの上にKubeflowを実装し、データストレージとしてArriktoが提供するRokを追加したパッケージである。

MiniKFの最新情報
MiniKFの最新のバージョンではKubeflow 0.7.1に対応し、GPUもサポートしている。このスライドの後半の3つのポイントはRokと呼ばれるデータマネージメント層に関するもので、デモでも登場するスナップショット機能を訴求するものだ。Jupyter Notebookでの実行や機械学習におけるパイプラインの中からその時のデータをスナップショットとして保存し、後から別のモデルやパラメーターで再実行するなどの使い方が説明されている。

MiniKFを作った背景。データサイエンティストが自分のノートPCで始められることが目標
データサイエンティストがKubeflowそのものを使えるようにするのが目標だったとあるが、MiniKFはKubeflowの下位互換となることを目標としていることがわかる。MiniKFで作られたモデルやアプリケーションがそのままKubeflowでも実行できるということは、自前のクラスターなどを持たないデータサイエンティストにとってはありがたいソフトウェアだろう。
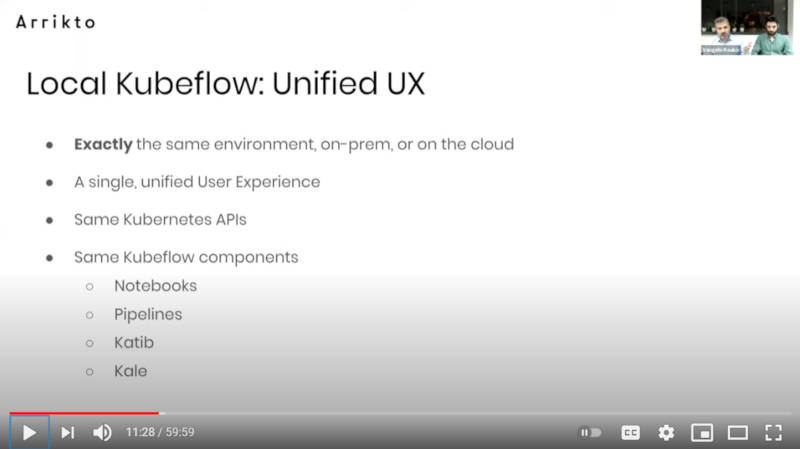
MiniKFはLocal Kubeflowである
ここではMiniKFがローカルで実行できるKubeflowであり、Kubeflowとの互換性を重視していることが強調されている。またユーザーエクスペリエンスや使われるツール、APIも同じであることが解説された。

パイプラインは機械学習の基本処理パターン
Kubeflowはパイプラインを実行することが基本であり、データの分析や変換、検証などのプロセスを経てモデルの作成、学習、推論、そして最終的にモニタリングまでが行われるというのがポイントだ。ここでは使い始めるバリアを下げるための機能と再実行のしやすさを重点的に解説している。するということが述べられている。

バリアを下げるのはKale、再実行のしやすさはRokで実現
この2つのポイントを実現するのがKaleとRokというソフトウェアだ。KaleはGUIを備えたJupyter NotebookをKubeflowのパイプラインに変換するツール、Rokは機械学習で使われるデータを管理するツールで、自動的にデータのバージョンごとのスナップショットを取って途中から再度、学習のプロセスをやり直すなどの機能を備えている。

Jupyter Notebookをパイプラインとして処理するメリット
機械学習の各ステップが明確に分離されること、ハイパーパラメータのチューニングが容易になること、そしてGPUへの対応がパイプライン化による利点だと解説した。

パイプライン化の前と後の違い
従来は機械学習のコードを書き、Dockerイメージを作成してKubeflowのパイプラインのための言語でコードを作成、最終的にKubeflowにアップロードして実行するというステップを踏んでいた。それがJupyter Notebookを作成して、それにタグを追加するだけでパイプラインとして実行できるという違いを説明した。
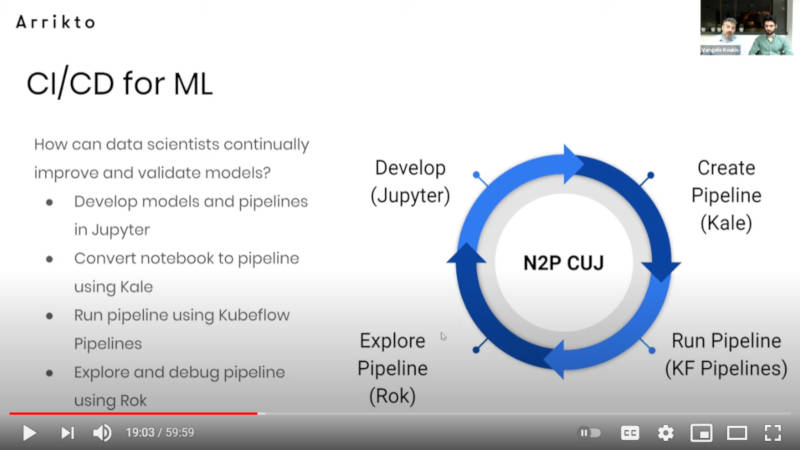
機械学習のサイクルを解説
そしてパイプラインをサイクルとして解説したのがこのスライドだ。「機械学習のCI/CD」と題して紹介されており、Jupyter Notebookで開発したモデルをKaleを使ってパイプラインに変換、それを実行しRokを使ってパラメーターなどを変えながらさらに試行するというサイクルになる。サイクルの中央に書かれているN2P CUJは「Notebook to Pipeline」「Customer Usage Journey」の略だということだ。

MiniKFをデモで紹介
ここからはKaggleでも多く参照されているタイタニック号の生存者を予測するモデルとデータを使ってデモを行うフェーズになった。
参考:【Kaggle初心者入門編】タイタニック号で生き残るのは誰?
この練習問題はチケットのクラス、年齢、性別といった乗員データから、誰が生存できたのか? を予測するというもので、約900件のデータを学習に使い、約400件のデータで実際に検証を行うという例題になる。
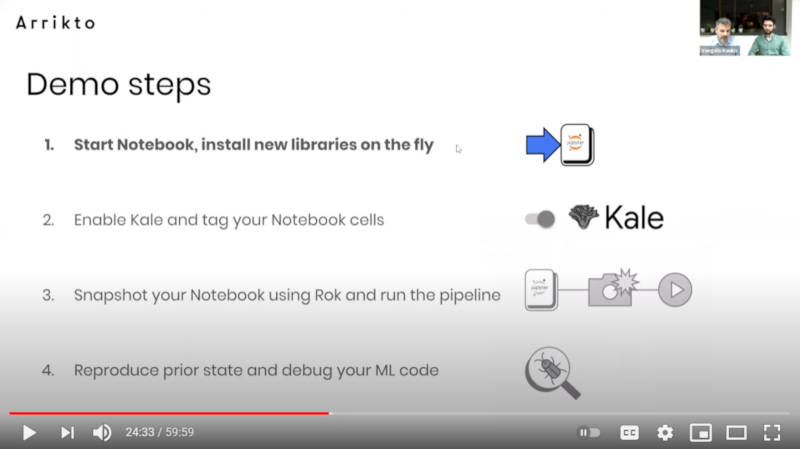
デモの流れ
デモではインストールからデータの読み込みまでに時間が掛かってしまっているが、デモの流れは、Jupyter Notebookのインストール、KaleでNotebook上のコードをパイプラインに変換、データのスナップショットを実行、機械学習のコードを変更して再度実行という流れになる。
デモに先立ってKaleの解説が行われた。KaleはJupyter NotebookをKubeflowのパイプラインに変換するツールで、ハイパーパラメータの変更なども行えるKubeflowのサブプロジェクトである。
参考:Kubeflow & Kale simplify building better ML Pipelines with automatic hyperparameter tuning
詳細は、このセッションの登壇者でもあるArriktoのエンジニアStefano Fioravanzo氏のブログに詳しく解説されている。
参考:Automating Jupyter Notebook Deployments to Kubeflow Pipelines with Kale
Jupyter Notebookのエクステンションとして実行されるコードがPythonのバックエンドを呼び出してコードを変換し、パイプラインとして実行するというのが仕組みのようだ。
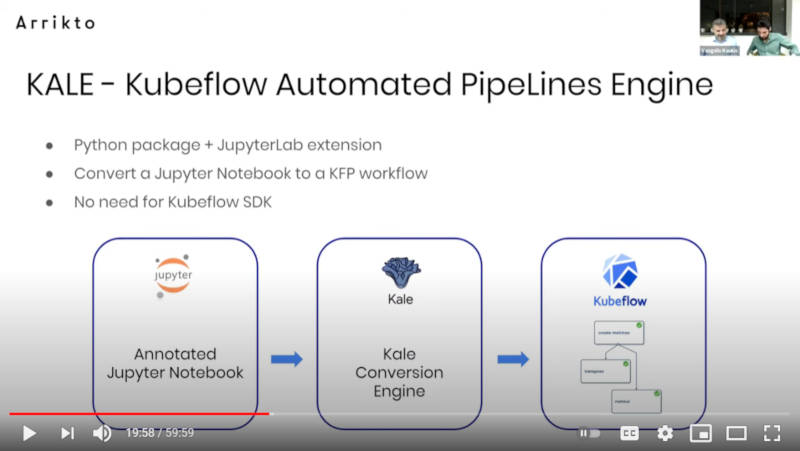
Kaleを使ってJupyter NotebookからKubeflowのパイプラインに変換
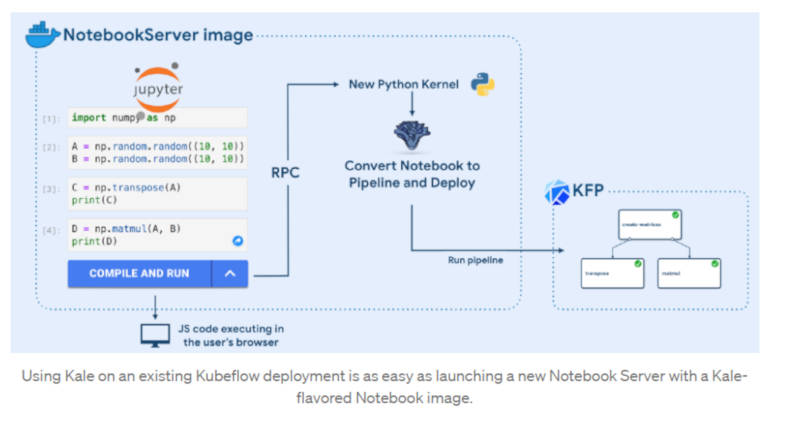
Kaleの動作概要
実際にデモの中でJupyter Notebookの画面を見せながらタグによって可視化されたパイプラインのプロセスが進んでいくことを確認できる。ここでも面倒なコマンドラインを入力せずにGUIだけでデータの準備から学習までが進んでいくのは、データサイエンティストにとってのバリアを下げるということを実証している形になっている。
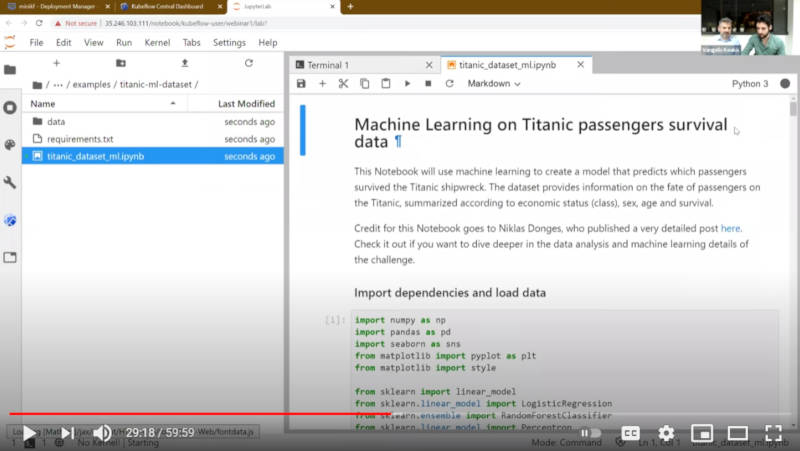
タイタニック号の生存者を予測するモデルを実行
デモの内容はセッションの動画を参照して欲しいが、このデモの一番の見せ場はJupyter Notebookからパイプラインに変換されたプロセスを途中から再実行するという機能だ。
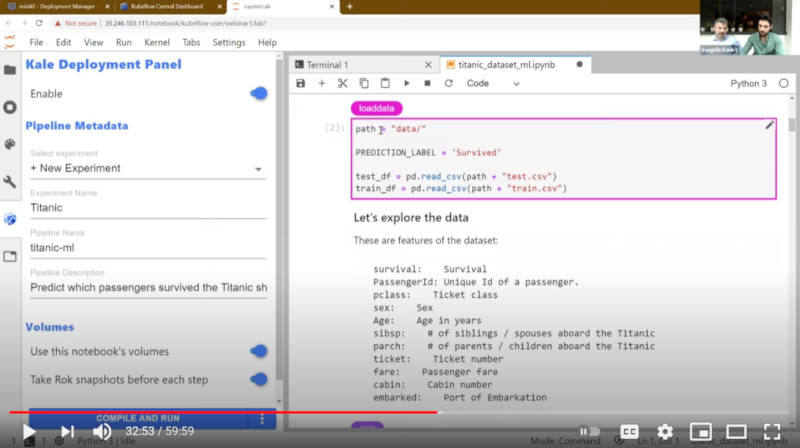
Jupyter NotebookからKaleを実行
このスクリーンショットの左下に「Take Rok snapshots before each step」というオプションがオンになっていることが確認できるが、これによってパイプラインのステップごとに使うデータのスナップショットが採取されることになる。
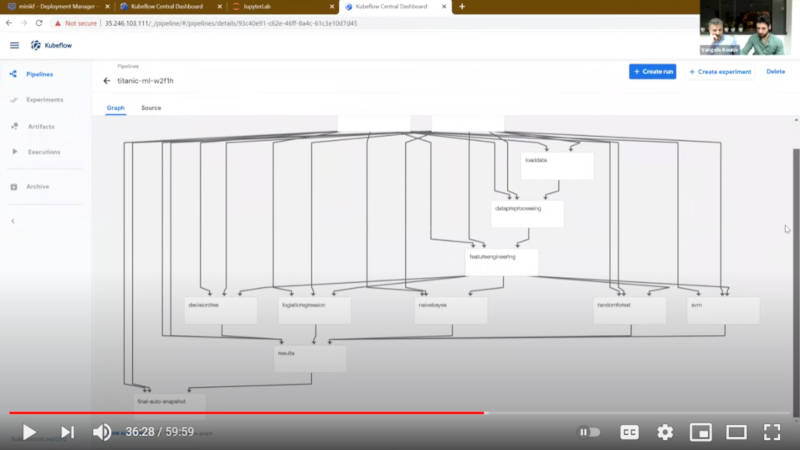
KubeflowのパイプラインをGUIで表示
Kaleには多くのモジュールが含まれていることを解説したのが次のスライドだ。
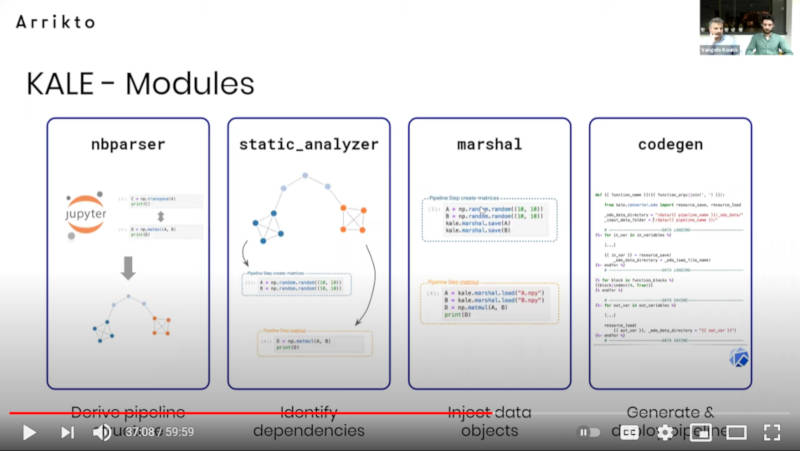
Kaleのモジュールを紹介
またパイプラインの中で使われるデータの管理に関して、Arriktoが多くの貢献を行っていることを紹介するスライドでは、Kubernetesのストレージ管理のコアであるPersistent Volume関連の多くの機能開発を行っていることを訴求した。

データマネージメント関連にArriktoが行った貢献を紹介
またKubeflowモジュール関連では2017年に開催されたKDD 2017の論文からの引用と思われるチャートを用いて機械学習に必要なモジュールがどのように構成され、それをKubernetes、Kubeflow、そしてArriktoが商用ソフトウェアとして開発するデータマネージメント関連のソフトウェアが受け持っているのかを解説した。この画像ではデータ分析から推論の実行までがTensorFlowで実装されており、その上下をKubeflowが担当して中核にKubernetes、最下部のデータマネージメントの部分にRokが位置していることを示している。
参考:KDD 2017
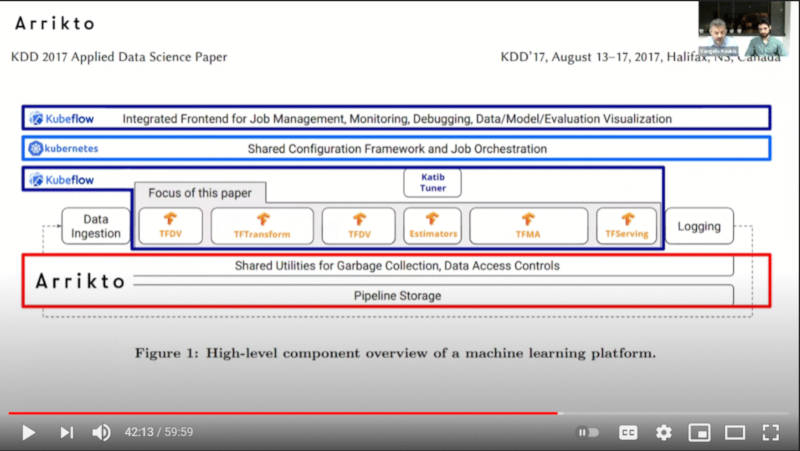
Kubeflowの役割がわかるチャート
デモの中ではデータが自動的にスナップショットされ、あとから別の実行ジョブとしてやり直せるようすを示している。ここで用いられているソフトウェアのうちKubeflowとKubernetesはオープンソースソフトウェアだが、RokはArriktoの商用サービスとして提供されている点には注意しよう。

ステージを変えてもポータビリティが保持されるデータマネージメント機能
Arrikto Rokは、機械学習のデータに再現性を持たせるための拡張機能として実行されると解説している。
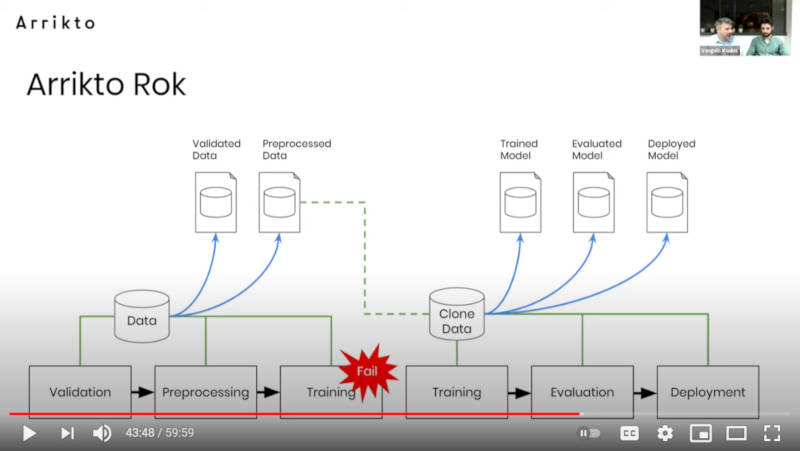
Arrikto Rokの紹介
デモの中ではステップごとにスナップショットが取られているため、どのステップからでもURLをコピーするだけですぐにパイプラインを実行できると紹介されている。
スナップショットのURLをコピー&ペーストするだけでパイプラインを実行できる
そしてKubeflowのパイプラインと一緒に、KaleとRokを使うことで得られる多くの利点を解説したのが次のスライドだ。

Kubeflow+Kale+Rokの利点
最後に今後の予定としてマルチクラウド、ハイブリッドクラウドへの実装、ハイパーパラメータのチューニング、そしてRokによるデータおよびメタデータのトラッキングなどを紹介した。

Kubeflowの今後の開発プラン
主にオープンソースソフトウェアで構成されるKubernetesのエコシステムだが、より利便性を高めるためのツールは商用サービスとしてクローズドで提供されるというのは、セキュリティなどのソリューションにはよく見られることだ。Rokもこのスタイルを採っている。
モデルの開発と実装までのスピードが機械学習、人工知能における競争のポイントなのであれば、スナップショットによって素早く試行のループを回せるRokは、十分に差別化のポイントとして訴求可能だろう(比較するソリューションがなければだが)。すでに評価の高いJupyter Notebookとの連携から、さらに利用が拡がっていくだろう。今後の発展が楽しみである。
なおKubeflowは、CNCFのSIG Runtimeのセッションでも紹介されている。この時はCOVID-19に関連したデモを行っていたのも興味深い。
2021年1月21日公開されたCNCFの動画:CNCF SIG Runtime 2021-01-21
この記事をシェアしてください
関連記事
Kubeflowとは
2021年9月24日 6:00
KubeCon Europe 2024開催。前日に開催されたAIに特化したミニカンファレンスを紹介
2024年5月9日 6:00
OpenShiftでデータサイエンティストとアプリ開発者が協調する流れをデモを交えて紹介
2021年10月27日 5:50
Kubernetesで機械学習を実現するKubeflowとは?
2018年6月1日 6:00
CloudNative Days Spring 2021開催。CNCFのCTOが語るクラウドネイティブの近未来
2021年5月6日 6:02
KubeCon NA 2021開催。プレカンファレンスのWASM Dayの前半を紹介
2022年2月16日 10:11
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
