検索ログと検索エンジン
全文検索システムの分類
直接検索は検索の方式によって大きく2種類に分けられます。1つは逐次検索方式、もう1つはインデックス検索方式です。
逐次検索方式は、検索したいそのときに対象ドキュメントを頭から末尾まで走査するというものです。UNIXのgrepコマンドやブラウザの検索機能などがこれにあたります。そのため、grep方式とも呼ばれています。
逐次検索方式は前処理が必要ないため、ドキュメントをその場で検索するのには適していますが、検索時に毎回ドキュメントを走査するため、大量のドキュメントを対象とする場合には、実行時間や効率の面から適しているとはいえません。ただし、逐次検索は範囲を絞れば十分に高速なので、インデックス検索と組み合わせて使われることもあります。
一方、インデックス検索方式はあらかじめ検索対象の索引(インデックス)を作成しておき、そこから検索を行うものです。
インデックスにはどの単語がどの文書に含まれるかが探しやすい形式で格納されているため、高速に検索が行えます。前処理としてインデックスを作成しておく必要はありますが、大量のドキュメントから何度も検索を行うのに適した方式です。検索ポータルサイトの検索も、このインデックス検索方式が使われています。
また、インデックスのデータ構造にもさまざまな種類があり、代表的なものとしては転置インデックスやシグネチャ方式のインデックス、接頭辞配列のインデックスなどが挙げられます。
今後紹介する全文検索システムでは転置インデックスが採用されています。
単語の分割
インデックスにドキュメントを登録するためには、インデックスへの登録単位である単語に文章を分割する必要があります。
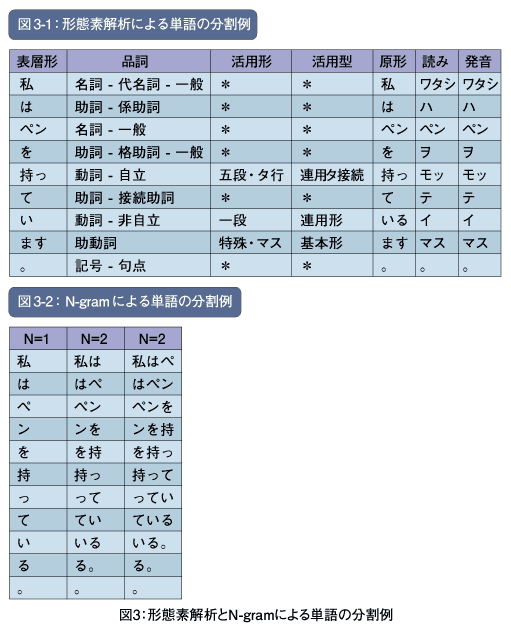
英語の場合にはスペースで区切ればよいのですが、日本語の場合にはそういうわけにはいきません。例えば、「I have a pen.」という英文は「I」「have」「a」「pen」「.」と分割できますが、日本語の「私はペンを持っています。」は区切られていませんので、コンピュータにはどこで分割すればいいか判別できません。そこで、形態素解析やN-gramといった手法を用いて単語を分割することになります。
形態素解析は文章を形態素という単位に分割する手法です。形態素とは語を構成する意味のある最小単位のことで、言語学の用語です。多くの場合では形態素=品詞として扱われます。
例えば、先ほどの「私はペンを持っています。」を形態素解析で分割すると、「私」「は」「ペン」「を」「持っ」「て」「い」「ます」「。」となります(図3-1)。
形態素解析では、辞書を使って文章中の形態素を認識し抽出します。そのため、単語へ分割する精度は辞書に依存し、辞書に無い単語(未知語)は正しい分割が困難です。
N-gramは文章を1文字ずつずらし、N文字ごとに分割するという手法です。N=1の場合にはuni-gram、N=2の場合にはbi-gram、N-3の場合にはtri-gramなどと呼びます(図3-2)。
例えば、「私はペンを持っています。」をbi-gramで分割すると、「私は」「はペ」「ペン」「ンを」「を持」「持っ」「って」「てい」「いま」「ます」「す。」「。」となります。
N-gramは分割ルールが単純なため、形態素解析に比べて高速に処理できます。また、辞書に依存しないため、どのような文章でもルールを正しく適用して分割できます。
以上、検索ソフトウエアの分類について解説してきました。
本連載で扱う全文検索システムは、直接検索であり、転置インデックス方式の検索ソフトウエアです。単語の分割は形態素解析とN-gramのどちらか、もしくは両方を使用可能です。
次回は全文検索システムを選ぶ上でポイントとなる性能や機能について解説し、オープンソースの全文検索システムを比較しながら紹介します。
なお、本記事に関して電気通信大学 尾内理紀夫氏と林貴宏氏からいただいたご支援、ご協力に深謝します。






