OpenStackや仮想化基盤に特化したインテグレーターの日本仮想化技術株式会社が恒例のセミナーを開催した。今回は、ディープラーニングに最適な演算プラットフォームであるGPUをリードするNVIDIAの製品に関する概要、OpenStackでGPUを活用するPoC(Proof of Concept、概念実証)、NTTコムによるGPU as a Serviceの作り方、そしてサイバーエージェントによるOpenStack上のコンテナオーケストレーションの解説、大量のログを人工知能によって処理するソリューションなどの講演が行われた。
最初に登壇したのはNVIDIAでHPC及びディープラーニングのソリューションを提案する佐々木邦暢氏だ。佐々木氏の講演はNVIDIAの持つ製品ラインナップの紹介から始まり、GRIDを導入した本田技研の事例、さらにグラフィックスを超えてGPUを並列コンピューティングのプラットフォームとして活用することの効果などを解説した。またGreen500という省電力なスーパーコンピュータのランキングを紹介し、これにランキングされている多くのスーパーコンピュータがNVIDIAのGPUを活用していることを紹介した。なかでも最も有名なのは、東京工業大学の松岡教授がリードするTUBAME 3.0だろう。

講演を行うNVIDIAの佐々木氏
参考:http://www.gsic.titech.ac.jp/sites/default/files/tsubame3-pc-matsu.pdf
NVIDIA製のGPUとインテルのCPUとを組み合わせたマッシブな計算ノードを、高速なバスで接続してクラスター全体で高速処理を実行、しかも消費電力は抑えることでデータセンター運用の大きな問題になっている電力コストを下げることに成功している。

Green500の上位のスーパーコンピュータで使われているNVIDIAのGPU
参考:GPUコンピューティングのNVIDIA、OpenStackでの利用拡大を狙う
次に行われたのは「GPGPU on OpenStack」と題されたセッションで、仮想マシンからハイパーバイザーをパススルーしてGPUを使うPoCに関する技術的な解説といったものだった。OpenStackの上の仮想マシンからハイパーバイザーをパススルーしてGPUを利用する際のノウハウをまとめたものであった。VMwareのESXiやXen Serverであればすでに可能なものをKVMの上から実行するというのは、確かにKVMをベースにしているクラウド環境においては重要だと思われるが、この場合GPUはひとつの仮想マシンに専有されることになり、プロダクションシステムとして使うには過渡期的と言わざるをえない実証実験だったように思われる。現状の制限は、あくまでも利用するハイパーバイザー側の制限であり、OpenStackに問題があるわけではないことを強調していたのが印象的だった。
参考:GPU on OpenStack - GPUインターナルクラウドのベストプラクティス - OpenStack最新情報セミナー 2017年7月
次に登壇したのはNTTコムの松本氏で、コンテナからGPUを「as a Service」として活用する際の検証結果に関するプレゼンテーションを行った。GPUを様々なワークロードから活用したいというニーズに対して、コンテナから利用する際の選択肢としてOpenStack Zun、Docker Swarm、Mesos、Kubernetesなどを比較検証したものだ。前提条件として「仮想マシンを利用するかのように即時に起動、停止、削除が可能であること」、「DockerはNVIDIA Dockerを使用すること」、そして「マルチテナントであること」が挙げられた。エンタープライズであればマルチテナントは不要かもしれないが、ここに挙げた条件はいかにもNTTコムといったところだろう。

プレゼンテーションを行うNTTコムの松本氏
参考:GPU Container as a Serviceを実現するための最新OSS徹底比較 - OpenStack最新情報セミナー 2017年7月
現状ではKubernetes 1.6以上のAlphaバージョンを使うことで、GPUのスケジューリングが可能になるという。またOpenStackからの管理という側面では、MagnumやHeatを使うのではなく、KubernetesからオーケストレーションするためのGPUクラスターを別に用意して、認証はOpenStackのKeystoneから行うという方法論が実行可能な選択肢として解説された。
これはこの後に登壇したサイバーエージェントのセッションとも類似する内容で、いかにGPUを装備したクラスターを社内のクラウド環境と透過的に結合し有効活用するのか? という命題に各社が試行錯誤しているということだろう。
次に登壇したサイバーエージェントの青山氏と長谷川氏の講演は、OpenStack Days Tokyo 2017のセッションと同じ内容だったが、やはりOpenStackの側からコンテナをオーケストレーションする試みを解説した。

プレゼンテーションを行うサイバーエージェントの長谷川氏
サイバーエージェントの環境では、ネットワーク構成からみてMagnumは合わない、だからと言って最新のZunを活用するにもリスクがある、ということで選択されたのはHeatと呼ばれるオーケストレーションツールのテンプレートをカスタマイズするという方本論に落ち着いたという。ここではOpenStackに存在する様々なプロジェクトのスペック、依存関係などを充分に検討した上で、最新のソフトウェアを使わずに下のレイヤーのソフトウェアを使って自社の環境にあった使い方をするという選択肢があることを強調していた。すでに多くのサービスをOpenStackで稼働させているサイバーエージェントならではの選択肢だと言える。
最後に登壇したNECネッツエスアイの山本氏の講演は、これまでのGPUやコンテナというテーマとは違い、ログの管理を効率化するソリューションの解説という内容だった。
OpenStack Summit Boston 2017で出会ったソリューションということで山本氏が紹介したのは、Loomと呼ばれる人工知能を使ったログの解析ツールだ。イスラエルのベンチャー企業であるLoom Systemsが開発したツールは、あるログが出力されることになった根本原因や解決策などを大量のログデータから解析できるという。

プレゼンテーションを行うNECネッツエスアイの山本氏
正常な状態のログをLoomのサーバーに送信するだけで異常時の原因と対応方法を提示してくれるソリューションということで、大量のログに悩まされているOpenStackのシステム管理者にとっては、魅力的なソリューションといえるだろう。
参考:AIの力で障害検知・解析をサポート!Loom(ログ解析ソリューション)のご紹介 - OpenStack最新情報セミナー 2017年7月
単純にエラーメッセージの内容を解析するのではなく、どのようなタイミングで発生するのかに対して異常を検知できるという。これは単にエラーメッセージに反応するということではなく、状況をみて異常や異変を検知することを意味しており、セキュリティソリューションでは定評のあるイスラエルの企業らしい特徴かもしれない。
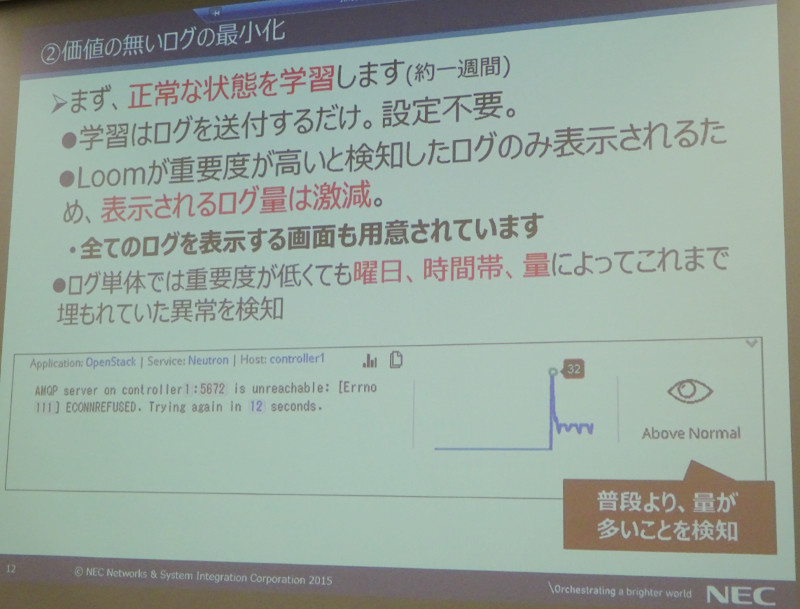
重要度が高いログだけを表示するという
今回も、いかにGPUとコンテナをOpenStackから利用するか、まだ試行錯誤の状態ではあるが、着実に知見が溜まっていることを確認できた。さらに大量のログ管理を解決する新しいソリューションの紹介もあり、OpenStackの管理者やこれからOpenStackの導入を検討している企業にとっては有用な情報ばかりのセミナーであった。
(編注:2017年9月20日2時00分更新)公開当初、日本仮想化技術の社名表記に誤りがありましたのでお詫びして訂正致します。- この記事のキーワード
関連記事
Japan Container Daysのキーノートで語られたCA、ヤフージャパン、メルカリの事例
2018年5月15日 10:51
OpenStack Summit Sydneyに見るOpenStackの今そしてこれから
2017年12月14日 5:50
OpenStack Days Tokyo 2017 関係者が語る本音ベースの座談会
2017年9月1日 11:00
OpenStack Days Tokyo:サイバーエージェントが明かす自社製Kubernetesサービス開発秘話
2018年9月7日 6:00
インテルがAIにフォーカスしたイベント「インテルAI Day」でPreferred Networksとの協業を発表
2017年4月25日 0:00
OpenStackの弱点、大量のログ発生問題を解決するNECネッツエスアイの取り組み
2016年9月13日 0:37
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
RustとWASMで開発されKubernetesで実装されたデータストリームシステムFluvioを紹介
2022年12月23日 6:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
