RancherとCI/CD
前回までの連載では、それぞれ以下の内容を紹介してきました。
- Rancherの紹介とインストール手順
- Rancherへのk8sクラスタのインポートとカタログ機能を用いたアプリケーションデプロイ
- カタログ機能の解説
今回から数回に渡って、ここまで説明してきたカタログ機能やその他のRancherの機能について解説しつつ、実際のシステム開発プロジェクトにてどのようにRancherを活用するかを紹介したいと思います。今回は、CI/CD(Continuous Integration/Continuous Delivery、継続的インテグレーション/継続的デリバリ)を中心としたシステムの実装とテストについて解説します。
CI/CDとは
CI/CDとは、ソースコードのコードリポジトリへのプッシュをトリガーに自動でビルドとテストを行い、本番環境にデプロイされるまでのプロセスを継続的に実行することを表します。
CIとは「継続的インテグレーション」、CDは「継続的デリバリ」または「継続的デプロイ」を表し、下図1に示すようなイメージで表されます。
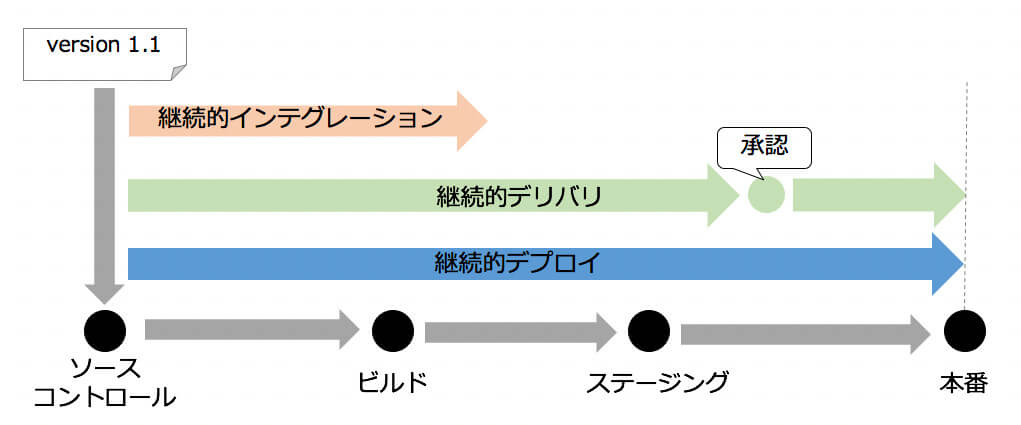
図1:CI/CDのイメージ(https://aws.amazon.com/jp/devops/continuous-integration/ の図を修正)
これだけではわかりづらいと思うので、CIとCDのそれぞれについて以降で解説します。
継続的インテグレーション(CI)とは
継続的インテグレーションとは、エクストリームプログラミング(XP)に含まれるプラクティスの一つです。
開発者がテスト駆動開発を開発者自身のローカル開発端末で実践し、その中でできたテストコードとアプリケーションコードをコードリポジトリにコミットします。
開発者がリモートのリポジトリ(例えばGitHubやGitLab.comにコードをプッシュしたタイミング、またはブランチのマージリクエストを作成したタイミングでテストを実行します。
このように、旧来の開発スタイルと比較して高頻度でテストを実行することで、早期に不具合の検出を行います。
では、ここで早期に不具合を検出することのメリットについて考えてみましょう。まず、比較のためにテスト頻度が非常に低い場合を考えます。テストを実行することなく、コードの追加、変更を長期間に渡って続けた後にテストを実行した場合、混入した不具合が検知されるのは大量のコード追加、変更が加えられた後になります。このような場合、コードを書いた本人であってもどこで混入した不具合なのかをすぐに判断することは困難になります(図2)。
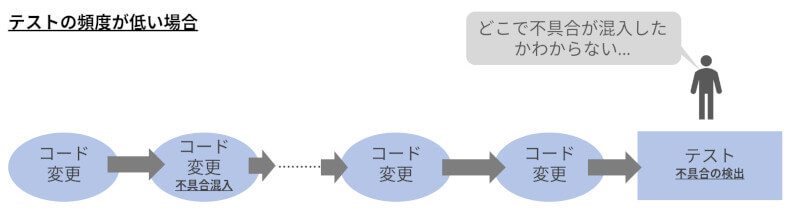
図2:テスト頻度が低い場合、不具合の原因特定は難しい
それでは高頻度でテストを実施した場合を考えてみましょう。この場合、最後にテストを通過してから実際にテストが失敗し始めるまでのコードの追加、変更量が少ないため、テスト頻度が低い場合と比較すると原因の特定は比較的容易になります(図3)。
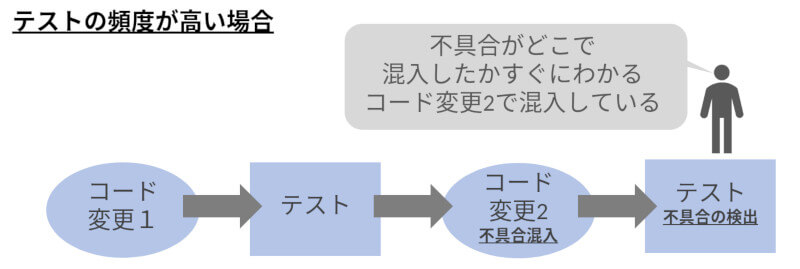
図3:テスト頻度が高い場合、不具合が混入した箇所の特定は比較的容易
しかしながら、テストは基本的に定型的な単純作業であり、開発者が手動で一日に何万回もテストを繰り返すのは現実的ではありません。そこでテストをコードで記述し、機械(CIツール)に実行させる(テストを自動化する)ことが重要です。
このようにテスト駆動開発と自動テストを組み合わせることで、仕様を充足しないコードや既存の仕様を壊すコードといった各種の不具合が、開発中のソースコードのmasterブランチにマージされることを予防します。
CIの導入により、短期的にはテストを記述するコストがかさむのは事実です。しかし中長期的には、プロダクトの成長に伴い肥大化したコードへの機能追加や機能修正、コードリファクタリングにおける開発効率の低下を防いでくれるため、最終的なコストは低くなります。
継続的デリバリ・デプロイ(CD)
CDについて述べるときに注意すべきこととして、「継続的デリバリ」と「継続的デプロイ」のいずれを指しているのかという点が挙げられます。
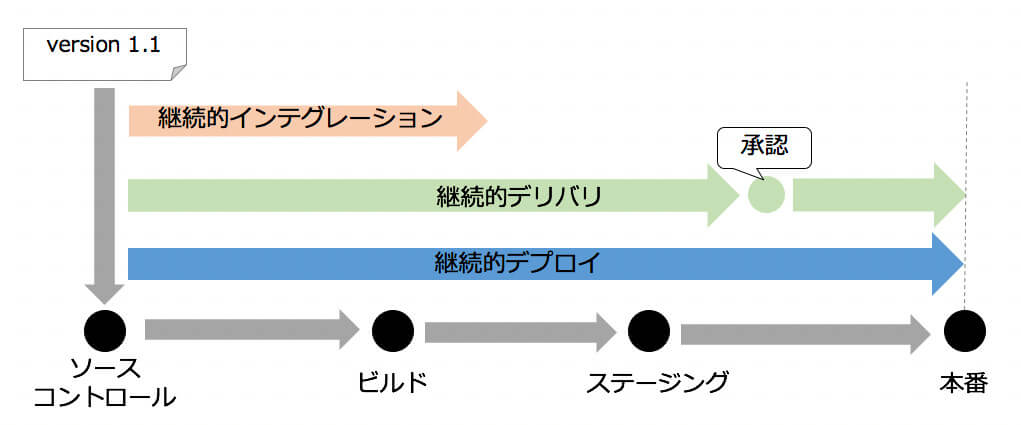
図1:CI/CDのイメージ(再掲)
継続的デリバリとデプロイの違いは、途中に人手による承認プロセスを挟むか挟まないかという点です。図1にあるように、ビルドとテストを行った後に人手による承認プロセスが挟まるのが継続的デリバリです。一方ビルドとテストをパスしたら、本番環境へのデプロイまで自動的に行われるのが継続的デプロイです。
承認のステップを除けば、コードがリポジトリにプッシュされたあとは、すべての工程が自動的に実行されているのが重要な点です。これによって、操作ミスが発生しやすく、人によって品質にばらつきが発生しがちな手動作業を排除することができます。これは結果として、安定かつ高頻度でのデプロイを可能にします(もちろんCI/CDのコード自体が十分な品質を備えていることが前提です)。
コンテナで構成されたアプリケーションとCI/CD
次に、コンテナで構成されたアプリケーションとCI/CDの関係について考えてみましょう。コンテナとCI/CDの関係を考える際には、Dockerが掲げている以下の3つのモットーが理解に役立つでしょう。
- Build
- Ship
- Run
Buildは誰がビルドを実行しても同じ成果物(この場合はDockerkコンテナイメージ)を提供すること、ShipはDockerレジストリを使ってビルド済みのDockerコンテナイメージを配布することです。そして最後のRunは、開発環境、ステージング環境、本番環境などの環境を問わず、同一のDockerコンテナイメージを使ってアプリケーションを動かすことを表します。Build、RunはCIに、ShipはCDの部分に特に影響します。
コンテナとCI
次に、上述した3つのモットーがCI、CDに与える影響について解説します。コンテナとCIで特に重要になってくるのが、DockerにおけるBuildとRunの部分です。
まず、BuildはDockerfileをベースにビルド手順を単純なDSLでコード化することで、ビルドの再現性、安定性を高めることを表します。
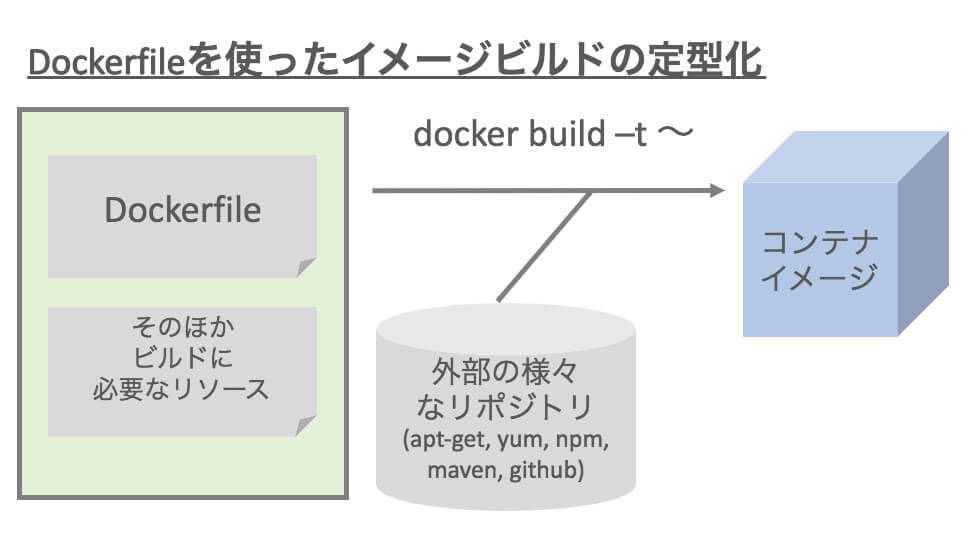
図4:Dockerfileの活用によるビルド手順の定型化
次にRun(厳密にはコンテナの特性を逆手に取ったもの)です。コンテナは基本的にコンテナのホストとなるマシン(VMでもベアメタルでも構いません)に、コンテナ内部で生成されたファイルを残しません。この特性を活かして、コンテナベースのCIでは繰り返しCIパイプラインが実行された場合も、過去のビルドの中間生成物に影響を受ける可能性を小さくできます(図5)。
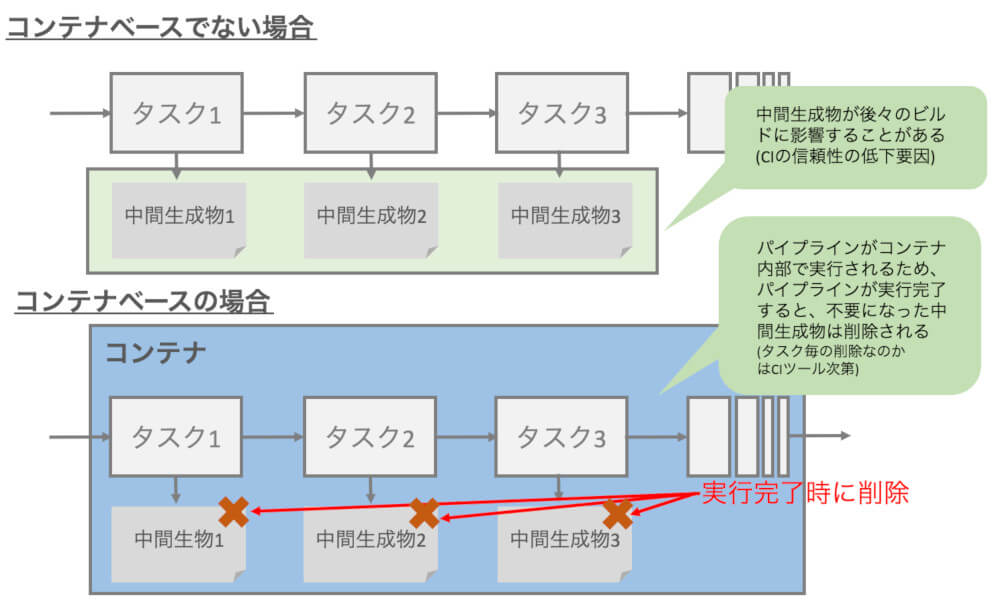
図5:コンテナベースでないCIとコンテナベースのCIの比較
コンテナとCD
コンテナとCDについて考える際には、DockerにおけるShipとRunの概念が重要になります。
イメージレジストリに保存されているイメージを取得(Shipの一部フェーズ)し、CIパイプラインを通過(=十分なテストがなされた)したイメージをデプロイすることができます。
例えば、単純な3層のWebアプリケーションであれば、以下の図6のように配置されるでしょう
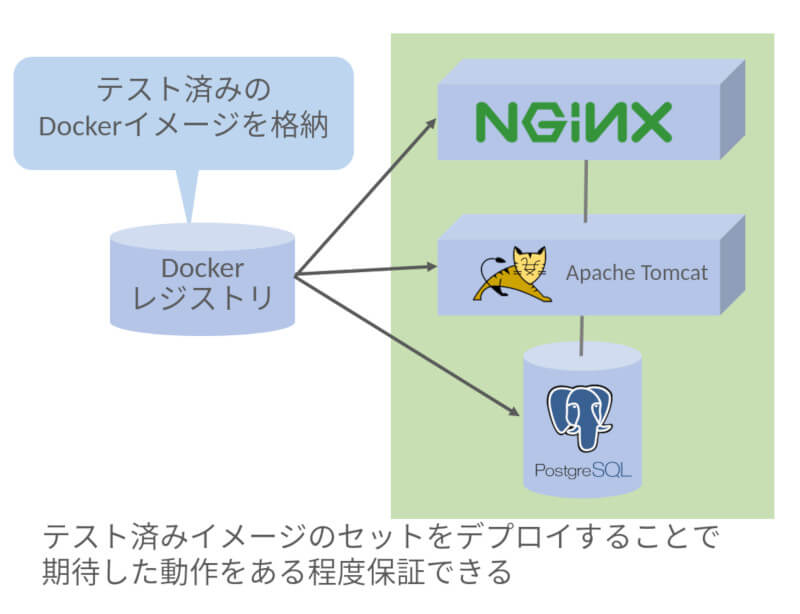
図6:イメージレジストリ(Dockerレジストリ)を介したテスト済みイメージの配布
しかし、これだけでは不足する部分が2点存在します。具体的には、一つはコンテナの非機能面の特性(おもに性能、可用性)への配慮、そしてもう一つが他のコンテナや外部サービス(AWSのRDSやS3など)との接続設定の記述※1です。
※1:これらの仕組み自体はコンテナ単独でも実現は難しくはありますが、不可能ではありません。
Kubernetesはこの2点について、それぞれ以下のようなリソースのマニフェスト定義の内部で実現しています。
- 非機能への配慮
- Deploymentsにおけるレプリカ数(replica)の指定
- Podにおけるリソース割り当て(limit, request)定義
- コンテナや外部サービスとの接続設定
- ConfigMapやSecretesによる環境変数、機密情報の取り扱い
これらのリソースをYAML形式のファイルとして記述し、デプロイすることでコンテナレイヤにおけるシステム全体の非機能要件と環境情報の取扱を実現し、これらの定義をKubernetesに読み込ませることでアプリケーションのデプロイが完了します。
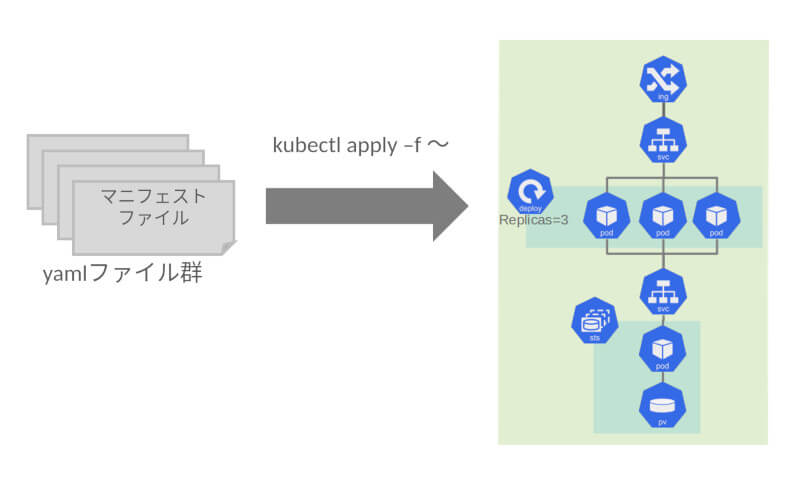
図7:Kubernetesのリソースマニフェストを用いたアプリケーションデプロイ
ここで一つ大きな疑問が生じます。実際のシステム開発では、開発・ステージング・本番環境と複数の環境が存在します。それぞれにおいて微妙に差分が存在するためこれらの差分を埋めるためにはどうすればよいかというところです。この疑問に対する解答が、前回(第3回)で解説したRancher Catalog機能です※2。
※2:他にもkustomizeやksonnetといった仕組みも存在します。これらについては解説しませんが一度調べた上でフィットする方を活用しましょう。
RancherとCI/CD
以上の説明をふまえて、ようやくここから「RancherとCI/CD」という本題に入ることができます。Rancherを中心に据えてアプリケーションを管理する前提で、CI/CDという観点で考えるとおもに以下のような整理ができます。
- RancherとCI
- Rancher Pipelines
- 他のサービスとの連携
- RancherとCD
- Rancher Catalog
- Rancher Pipelines
ここからはRancherのCI機能であるRancher Pipelinesと、外部にCIを依存する場合に利用するサービスとしてGitLab CI/CDを簡単に紹介します。Rancher Catalogについては前回に解説済みのため、紹介は省略します。
Rancher Pipeline
Rancher Pipelinesは、Rancherに統合されたCI機能です。パイプラインの実行にJenkinsを、各種アーティファクトの保管にMinioを、そしてコンテナイメージの保管にDockerレジストリを利用しています。
GitHubまたはGitLabのリポジトリと連携することで、コードのプッシュやプルリクエストの作成、特定コミットへのタグ打ちなどが行われたタイミングで、パイプラインの実行をトリガーすることができます。
設定としてはGUI上の指示に従ってOAuth Appとしての連携を行い、どのリポジトリを対象とするのかを選定すると当該リポジトリのルートディレクトリに含まれる「.rancher-pipeline.yaml」ファイルに記述された通りにパイプラインが実行されます。
今回は概要の紹介のみにとどめ、実際の利用方法等については次回以降の連載にて解説します。
Rancherが提供しているサンプルのパイプラインを使って、パイプラインを実行した結果が以下のようになります。
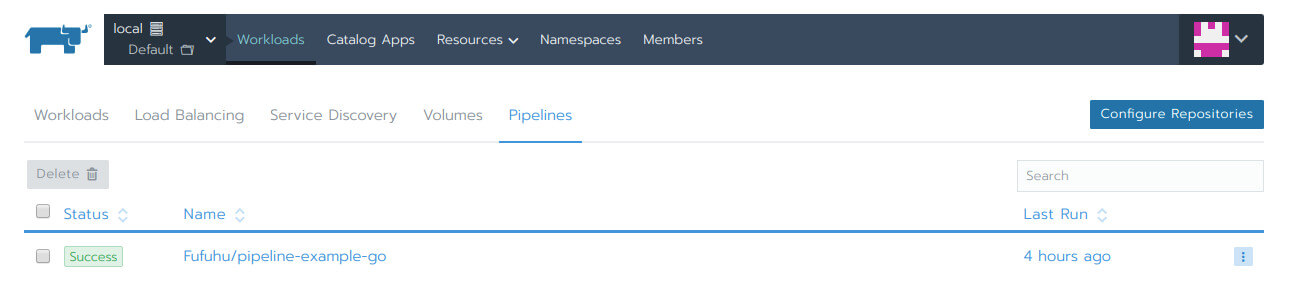
図8:Rancher Pipelinesのパイプライン一覧画面
Pipelineの一覧画面では、実際にパイプラインがリスト形式で概要とともに表示されます。パイプラインの実行ステータス(上図の場合はSuccess)と最後に実行された日次が表示され、名前(Name)の部分には、リポジトリの名前が表示されます。
パイプラインの詳細画面(図9)に移動すると、パイプラインのこれまでのアクティビティ一覧が表示されます。個々のアクティビティの状態(Status)や実行対象となったリポジトリのブランチ(Branch)、実行対象となったコミットのメッセージ(Commit)といつ実行開始したものか(Triggered)が確認できます。
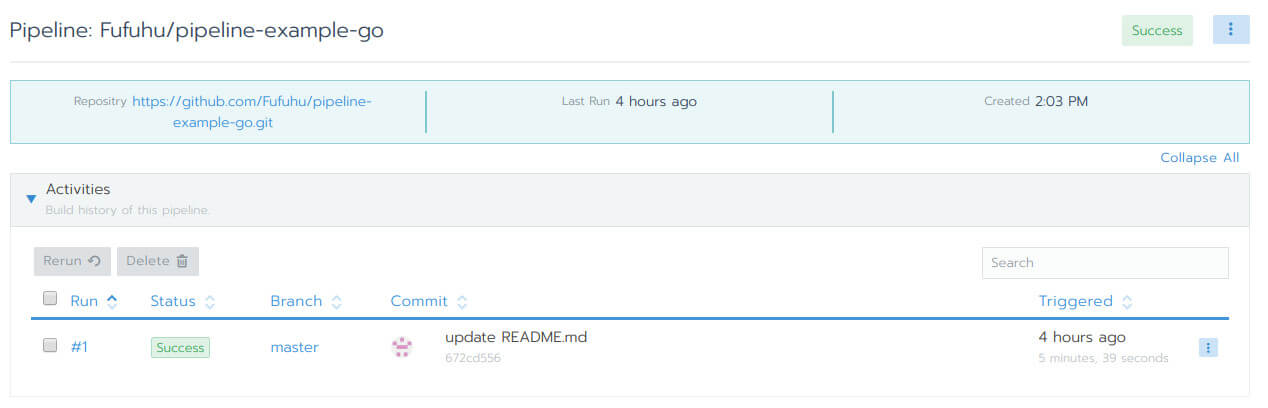
図9:サンプルのパイプラインのアクティビティ画面
さらに個別のアクティビティの内容を確認すると、パイプラインの中で定義されている実行ステップの詳細として標準出力(STDOUT)に出力されたメッセージの内容を後からでも確認することができます。
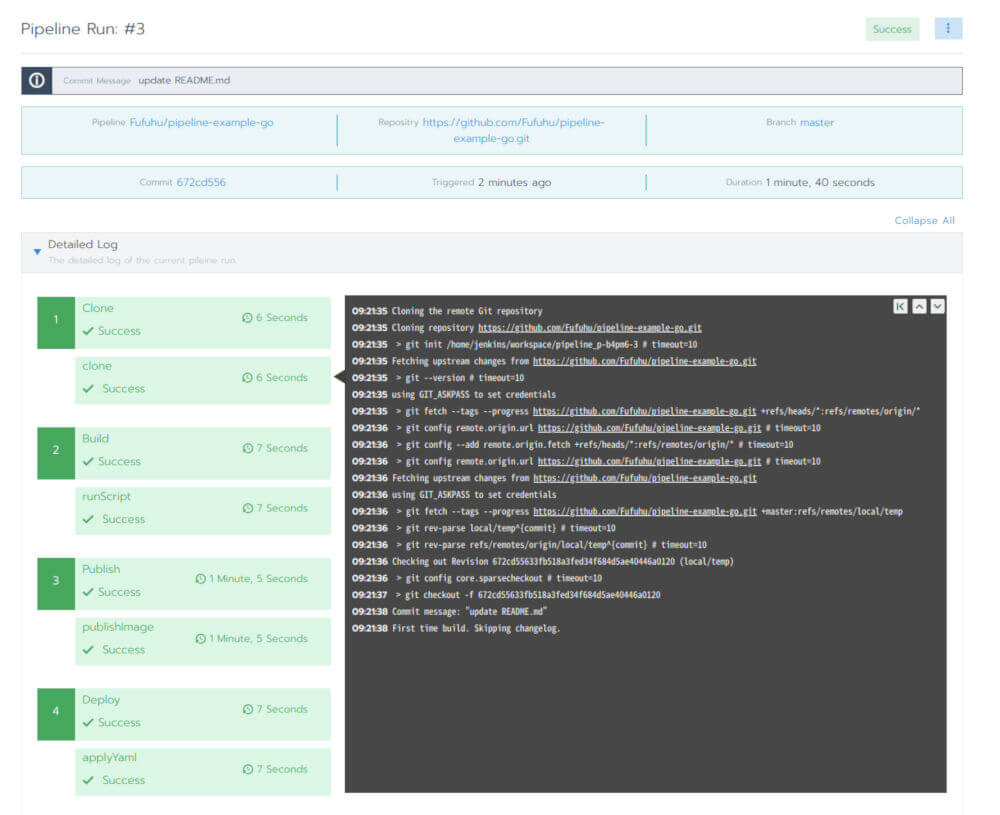
図10:Rancher Pipelineの実行詳細画面
GitLab CI/CD
GitLabは、GitHubと同様にgitのリポジトリサービスをベースとしたサービスです。SaaSで提供されるhttps://gitlab.com/だけでなく、オンプレミスで運用可能なバージョンも提供されています。
現在のGitLabは、単純なGitリポジトリサービスではなく、「A full DevOps toolchain.」を合言葉に、DevOpsの推進に必要となる一連の機能やツールをGitLab本体と統合する形で提供しています(図11)。
図11:GitLabの公式ページ(https://about.gitlab.com/)
この中でCI/CDについてカバーするのが、GitLab CI/CDです。SaaS版のGitLabであれば、月間2000分までCIの実行機能を無償で利用することができます(2019年3月時点)。
SaaSで提供されるCIとGitリポジトリをまとめて管理したいなどの状況では、特に有力な選択肢となり得るでしょう。
GitLab CI/CDを利用する場合は、Rancher Pipelinesを利用する場合と同様にリポジトリのルートディレクトリに、「.gitlab-ci.yml」を配置してパイプラインを定義します。
今回は主要な画面とその説明にとどめ、詳細な説明や実際の活用についてはRancher Pipelineと同様に次回以降とします。
まずGitLab CI/CDのパイプライン実行結果一覧(図12)から見ていきましょう。Rancher Pipelineのアクティビティの一覧画面(図9)と同様にパイプラインの実行状況が記述されます。
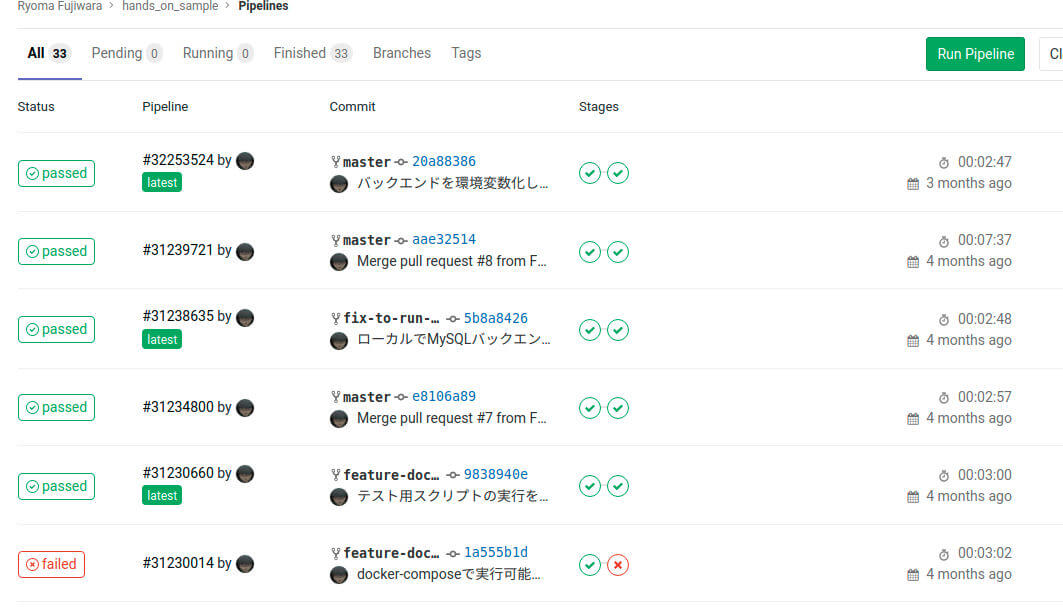
図12:GitLab CI/CDにおけるパイプラインの実行結果一覧
個別のパイプラインの実行状況としては、図13に示すような形になります。Rancher Pipelineとの大きな違いとしては、パイプラインを構成しているステップが、グラフの形で表示される点が挙げられます。タブを切り替えることでリストのように表示することも可能です。
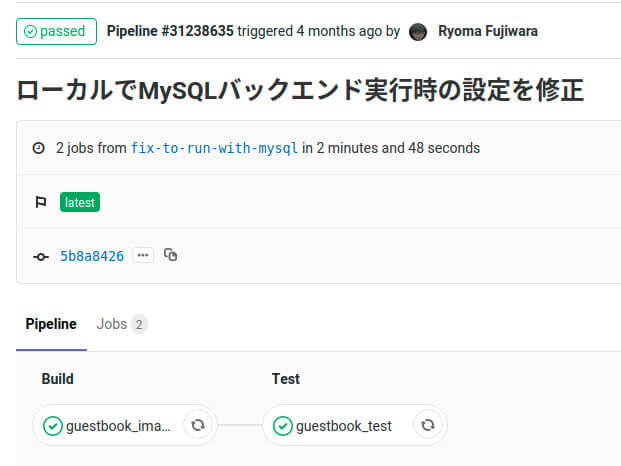
図13:GitLab CI/CDにおける特定のパイプラインの実行結果
さらに、パイプラインを構成する個別のジョブの詳細画面(図14)を見ていきましょう。Rancher Pipelineの実行詳細画面(図10)の場合と同様に、ジョブの中での標準出力(STDOUT)の内容が画面に出力されるようになっています。
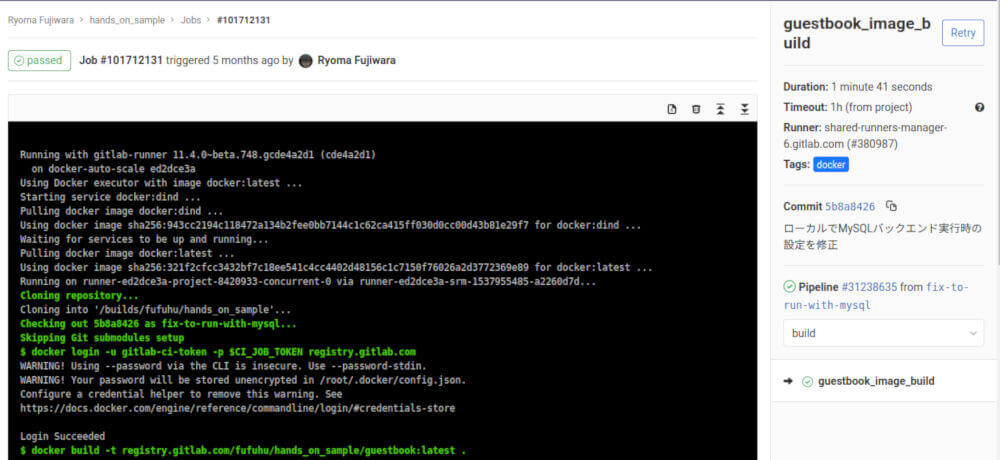
図14:GitLab CI/CDにおけるパイプライン内ジョブの実行結果詳細
Rancher PipelineではRancher内部にDockerレジストリを展開することで、レジストリを準備していました。GitLabでCIを実行する場合は、リポジトリに付属する形でGitLab Container Registry(以下、GitLab CR)が付属します(図15)。GitLab CI/CDを利用する場合はGitLab CRをコンテナイメージのレジストリとして利用するようにするのが良いでしょう。
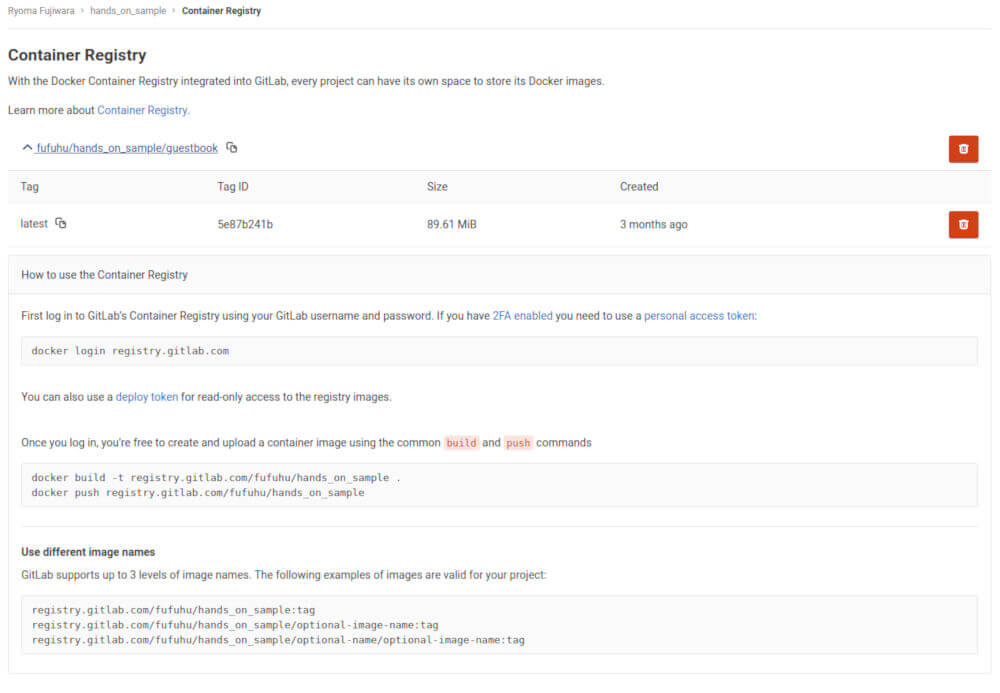
図15:GitLab CRの画面
まとめ
今回はRancherとCI/CDとテーマとして、そもそもCI/CDとは何なのか、Rancherとして提供しているCI/CDの関連機能としてどのようなものがあるのかを紹介しました。また、Rancherと組み合わせて利用することでよりCI/CDの充実に役立てることができるサービスとして、GitLab CI/CDとGitLab CRを紹介しました。
解説はここまでとして、次回以降は実際のサンプルアプリケーションを開発する中で、RancherとGitLabを組み合わせてどのように進めていくのかを解説します。
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
