クラスタソフトウェアの導入にあたって
HAクラスタリングの普及における背景 電子商取引や基幹業務アプリケーションの拡大に伴い、ミッションクリティカルなシステムの需要は益々高まるばかりです。
2005年11月16日 20:00
HAクラスタリングの普及における背景
電子商取引や基幹業務アプリケーションの拡大に伴い、ミッションクリティカルなシステムの需要は益々高まるばかりです。
止められないシステムを構築するためには、まずシステムが停止する原因を考え、それぞれの対策を検討することになります。
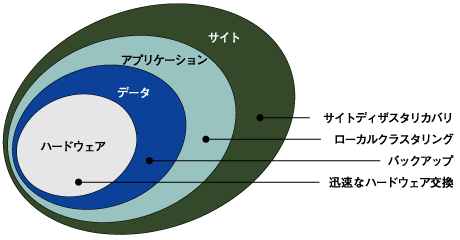
図1:レイヤーと障害対策
表1は一般的な障害の原因を分類したものです。
- ハードウェア障害
- サーバ本体のコンポーネント障害(メモリ/ファン/電源/
ハードディスク/各種コントローラ) - ネットワーク機器障害
- ストレージ機器障害
- サーバ本体のコンポーネント障害(メモリ/ファン/電源/
- データ消失
- オペレーターミス
- ウィルス
- ハードディスクの故障
- ソフトウェアの停止
- OSのハングアップ
- ドライバのハングアップ
- OSやファームウェア、ドライバのバージョンアップ
- ローカルなサイト災害
- 火事
- 落雷
- テロ
- 電源設備障害
- 地域的なサイト災害
- 地震
- 洪水
- 停電
レイヤーが低い障害ほど低コストで実現できる対策ですが、その分システムのダウンタイムや損害が大きく復旧までにかかる時間やコストが業務に大きな影響を与える可能性が大きくなってきます。以下に企業規模と障害の関係をあげます。
- SOHOレベルの企業の場合
- ハードディスクのRAID化がなされていないのはもちろん、データのバックアップすら考慮されておらず、ハードウェア障害時にはデータが消失してしまうケースも。
- 中小企業の場合
- ファイルサーバやデータベースサーバのデータ自体のバックアップをしているケースは多いですが、システム自体はクラスタリングされていないため、ハードウェア障害時には復旧まで数時間、時には1日程度かかる場合もあり、その間業務は停止状態に。
- 拠点数が少ない中〜大企業の場合
- システムがクラスタ化されているため、システム障害の発生は限りなく低く抑えられていますが、ハードウェアに対する火事や自然災害などの障害には対応できません。
- グローバルな大企業および金融/証券などの地域を越えた運用継続性の保証が必要な場合
- ネットワーク回線を使用するなどして、異なる地域で運用できるようグローバルなクラスタリングやディザスタリカバリを実施している。
これまで企業の規模や業種によってシステム障害への対策がなされてきました。
しかしながら最近ではビジネスの主体が電子商取引のような時間を問わないものに移り変わってきており、中小企業でもミッションクリティカルなシステムの需要が高くなっています。
従来はミッションクリティカルなシステムといえば、商用UNIXが中心だったのですが、ここにきてLinuxやWindowsなどの安価なハードウェアを使用したシステムの活用が目立ってきています。
図2のグラフはインプレスおよび矢野経済研究所の調査による、「ユーザ企業のサーバーOS別の今後のサーバ導入の考え方」です。図2から商用UNIXのかわりにLinuxを導入する傾向が見て取れます。
安価なハードウェアを導入するのはよいのですが、その分単位時間あたりのハードウェア障害の発生確率は高くなる傾向にあります。つまりその部分をクラスタソフトウェアで補完しようということなのです。
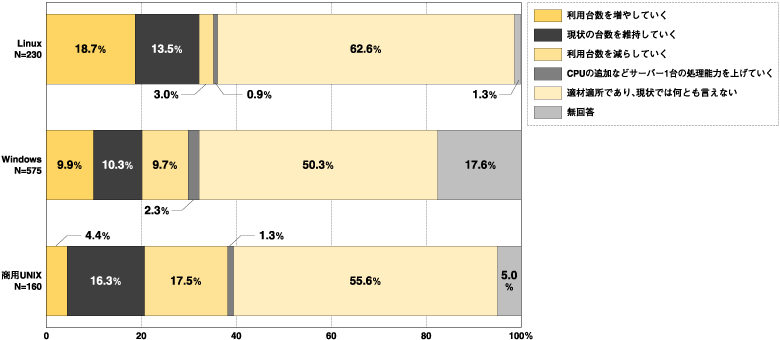
図2:サーバーOS別今後のサーバー導入の考え方
出典:Linuxオープンソース白書2006
(c)インプレス/矢野経済研究所2005-2006
(画像をクリックすると別ウィンドウに拡大図を表示します)
需要をさらに後押しするのが、OSベンダーやクラスタソフトウェアベンダーによるクラスタソフトウェアの機能の充実とコモディテイ化にあります。
OSベンダーの場合、例えばマイクロソフトのWindows Server 2003 Enterprise EditionおよびDatacenter Editionでは8ノードまでのクラスタが構成可能となるMSCS(Microsoft Cluster Service)が利用できます。またLinuxのディストリビュータであるRed Hatの場合には、OSとは別製品としてCluster Suiteがあり、68,000円という安価な価格で提供されています。
クラスタソフトウェアベンダーの場合、従来は商用UNIXが中心となっていた対応プラットホームをLinuxやWindows対応への拡充を行ったり、導入がしやすいような機能の拡充を行っています。
企業のシステムへの依存度が高まるにつれて、データ保護止まりであった企業へのクラスタシステムの採用は、今後増えると考えられます。
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
