統計情報の最適化
統計情報を確認するPostgreSQLの問い合わせオプティマイザは、統計情報をもとにインデックスを使うかどうかなどの判断をしています。たとえば、図9の場合はインデックスが使われるのに、図10の場合はインデックスが使われないのは、オプティマイザが結果件数が多い場合は順スキャンの方が速いと判断するから
2005年6月15日 20:00
統計情報を確認する
PostgreSQLの問い合わせオプティマイザは、統計情報をもとにインデックスを使うかどうかなどの判断をしています。たとえば、図9の場合はインデックスが使われるのに、図10の場合はインデックスが使われないのは、オプティマイザが結果件数が多い場合は順スキャンの方が速いと判断するからです。
test=# EXPLAIN SELECT * FROM accounts WHERE aid 100;
 QUERY PLAN
QUERY PLAN
---------------------------------------------------------------------
Index Scan using accounts_pkey on accounts (cost=0.00..4.90 rows=67 width=100)
Index Cond: (aid 100)
(2 rows)
test=# EXPLAIN SELECT * FROM accounts WHERE aid 900000;
QUERY PLAN
---------------------------------------------------------------------
Seq Scan on accounts (cost=0.00..2890.00 rows=99991 width=100)
Filter: (aid 900000)
(2 rows)
こうした判断の材料となるのがシステムカタログのpg_statsにある統計情報です(注3)。統計情報は列ごとに管理されており、先ほどの例では、図11のようにすればaid列に関する統計情報を参照できます。
test=# SELECT * FROM pg_stats WHERE tablename = 'accounts' AND attname = 'aid';
-[ RECORD 1 ]-----+------------------------------------------------------
schemaname | public
tablename | accounts
attname | aid
null_frac | 0
avg_width | 4
n_distinct | -1
most_common_vals |
most_common_freqs |
histogram_bounds |
{33,10058,19754,30338,40134,49894,59318,68553,79195,89820,99970}
correlation | 1
統計情報についてそれほど詳細に立ち入る必要はありませんが、histogram_boundsとmost_common_valsには注意を払う必要があるかもしれません。これらは検索の結果抽出される行数を計算するために使われる値で、インデックスを使用するかどうかに大きな影響を与えます(注4)。
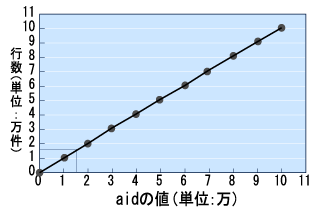
異なる値が多い場合は、histogram_boundsがNULL以外の値になり、テーブル行数を10等分したときに、境界となる列の値が配列として記録されます。これをグラフで表すと図12のようになります。
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
