インデックスの活用によるチューニング
インデックスの活用 インデックス(index)は検索処理を高速化するデータ構造です(日本語で「索引」と呼ばれることもあります)。インデックスを使うと、検索処理が高速化する一方、更新処理時のオーバーヘッドが増加して、処理速度に悪影響を与えます。したがって、インデックスは作ればよいというものではあ
2005年6月8日 20:00
インデックスの活用
インデックス(index)は検索処理を高速化するデータ構造です(日本語で「索引」と呼ばれることもあります)。インデックスを使うと、検索処理が高速化する一方、更新処理時のオーバーヘッドが増加して、処理速度に悪影響を与えます。したがって、インデックスは作ればよいというものではありませ ん。必要十分なインデックスを作ることが基本です。
PostgreSQLにはB-treeインデックス、ハッシュインデックス、R-treeインデックスなどがあります。R-treeインデックスは 幾何データ型専用です。デフォルトで使用されるのはB-treeインデックスです。実装が一番洗練されているので、特に理由のない限りB-treeイン デックスの使用をお勧めします。本稿でも以下「インデックス」と言えばB-treeインデックスを指すことにします。
B-treeインデックスとは
B-treeインデックスを有効に利用するためには、その動作原理を理解してお くことが必要です。詳細は拙著『今すぐ導入!PHP×PostgreSQLで作る最強Webシステム』(技術評論社、2003年)などをご覧いただきたいのですが、ここでは概略のみを説明します。
図5は、「100, 101, 105, 112, 119, 220, 231, 237, 242」の9個の値を登録した整数型の列に対してB-treeインデックスを作成したときの状況を表しています。
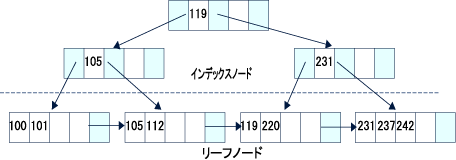
図5:B-treeインデックスの構造
『今すぐ導入!PHPxPostgreSQLで作る最強Webシステム』
(石井達夫著、技術評論社、2003年、ISBN-4774116475)から引用
値の検索は、一番上のノード(ルートノード)から始まります。たとえば、220を検索する場合は、119よりも大きい値なので、119の右側のポイ ンタ(灰色の部分)を通じて231の入っているインデックスノードに導かれます。119は231よりは小さいので、今度は231の左側のポインタを通じて リーフノードに導かれ、119と220の入っているノードに辿り着いて検索が完了します。リーフノードにはテーブル本体へのポインタが格納されており、最終的にテーブル本体にアクセスしてインデックスのデータが正当なものであるかどうかが確認されます(注1)。
重複の多いデータには不適
B-treeインデックスの構造から推測できるように、B-treeインデック スは値の重複がない場合に最大の効果を発揮し、重複データが増えるにつれ、効率が落ちていきます。極端に重複の多いデータ、たとえば性別などのデータに対してはほとんど効果がありません。また、このようなデータの場合は、PostgreSQLもインデックスの使用を避けるため、インデックスを作成しても無 意味です。
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
