連載の最終回となる今回は、実施した同時書き込み性能検証の結果をご説明していきます。
前回は、検証目的と観点、検証方法についてご説明しました。本検証では、KVSのクラスタ台数を見積るための基礎データ取得を目的として、センサーデータ蓄積で重要となる同時書き込み処理に注目しました。
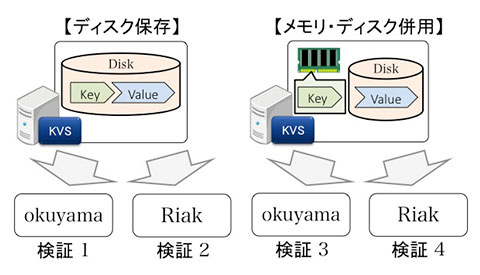
図1:検証の一覧
本検証では図1に示す4つの検証について、クライアントからの同時アクセス数を段階的に増加させて同時書き込み負荷をかけ、スループットのピーク性能とレイテンシを検証しました。以下では4つの検証ごとに、検証結果をご説明していきます。なお、検証方法の詳細については、本連載の第2回をご覧下さい。
検証1 (okuyamaディスク保存)の検証結果
検証1は図2の構成で実施しました。クラスタ台数を1台から4台まで変えて、検証しました。
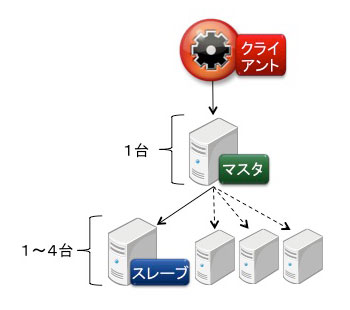
図2:検証1の構成
検証結果を図3に示します。グラフ上の点は、一定の同時アクセス数(それぞれ1、10、30、100、300件)で大量の件数を書き込んだ際の平均値です。また、スループットの単位[ops/sec]は「1秒当たりの平均書き込み件数」、レイテンシの単位[ms]は「1000分の1秒(ミリ秒)」です。グラフの色分けはクラスタ台数の違いを表しています。

図3:検証1のスループットとレイテンシ(クリックで拡大)
表2:検証1のピーク時のスループットとレイテンシ
| クラスタ台数 | ピーク時の同時アクセス数 | ピーク時のスループット | ピーク時のレイテンシ |
|---|---|---|---|
| 1台 | 10件 | 25.7 ops/sec | 379.8 ms |
| 2台 | 10件 | 45.1 ops/sec | 212.6 ms |
| 3台 | 30件 | 67.9 ops/sec | 427.3 ms |
| 4台 | 30件 | 83.6 ops/sec | 340.3 ms |
スループットは、同時アクセス数が10~30件の付近でピークをとり、それ以上アクセス数が増えてもほぼ一定の性能を示しました。ピーク性能は表1の通りです。クラスタ台数を増加させることによりピーク性能が向上し、最大で83.6 ops/secを記録しました。
レイテンシについては、同時アクセス数の増加にほぼ比例して性能が低下し、クラスタ台数の増加により、性能が向上しました。数値の大きさとしては、上述の最大スループットをとったときの値で340.3 msとなりました。性能ボトルネックについてハードウェアの稼働状況を確認したところ、同時アクセス数が30件以上になるとCPUがほぼディスクI/O待ちになっていました。そのため、ディスクI/Oがボトルネックであると予想しています。
検証2 (Riakディスク保存)の検証結果
検証2は図4の構成で実施しました。検証1と同様、クラスタ台数は1台から4台まで検証しています。
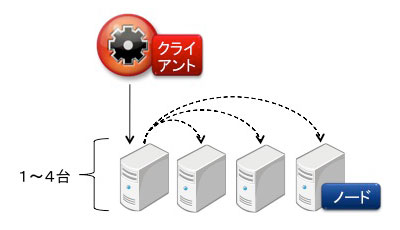
図4:検証2の構成
検証結果を図5に示します。グラフの見方は検証1と同じです。
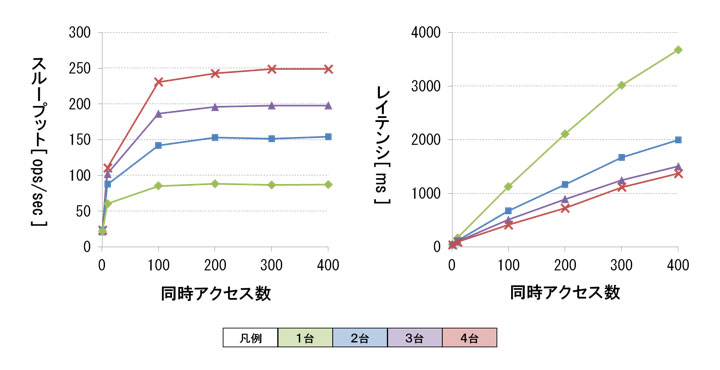
図5:検証2のスループットとレイテンシ(クリックで拡大)
表2:検証2のピーク時のスループットとレイテンシ
| クラスタ台数 | ピーク時の同時アクセス数 | ピーク時のスループット | ピーク時のレイテンシ |
|---|---|---|---|
| 1台 | 200件 | 88.2 ops/sec | 2108.5 ms |
| 2台 | 400件 | 154.3 ops/sec | 1997.5 ms |
| 3台 | 300件 | 197.9 ops/sec | 1244.0 ms |
| 4台 | 300件 | 249.1 ops/sec | 1115.4 ms |
スループットは同時アクセス数が200件以上になるとほぼ一定の性能となり、300件前後でピークをとりました。ピーク時の性能は表2の通りです。クラスタ台数を増加させることにより、ピーク性能が向上し、最大スループットは249.1 ops/secとなりました。
レイテンシは同時アクセス数の増加にほぼ比例して性能が低下し、クラスタ台数の増加に対して性能向上しました。数値の大きさとしては、上述の最大スループットを記録した際の値で1115.4 msとなりました。
性能ボトルネックについてハードウェアの稼働状況を確認したところ、同時アクセス数が100以上になるとCPUがほぼディスクI/O待ちになっていました。そのため、検証2でもディスクI/Oがボトルネック要因であると予想しています。
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
