ストレージの容量削減テクノロジ
電子データの爆発的な増加に伴い、ITプラットフォームを支えるストレージに注目が集まっている。この数年間だけでも、サーバー仮想化やクラウド・コンピューティングを支える重要なインフラとして、ストレージは急速な進化を遂げている。本連載では、代表的なストレージの最新テクノロジをピックアップして解説する。"デ
2010年7月6日 20:00
電子データの爆発的な増加に伴い、ITプラットフォームを支えるストレージに注目が集まっている。この数年間だけでも、サーバー仮想化やクラウド・コンピューティングを支える重要なインフラとして、ストレージは急速な進化を遂げている。本連載では、代表的なストレージの最新テクノロジをピックアップして解説する。
"データ容量の削減"が最大の課題
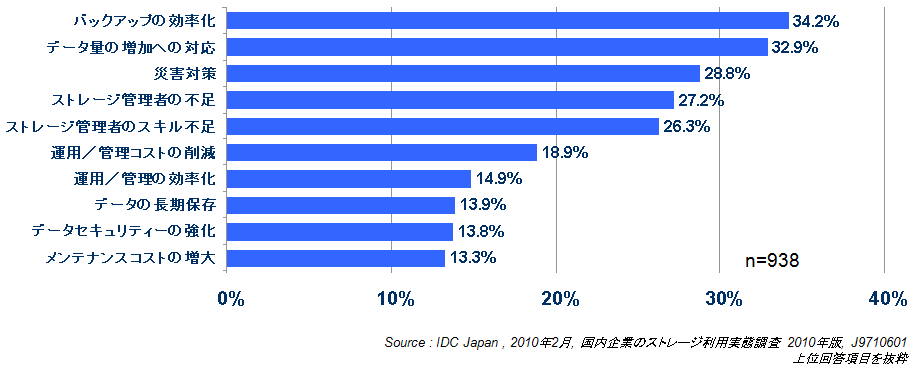
まずは、IDC Japanが2010年2月に発行した調査レポート「国内企業のストレージ利用実態調査 2010年版」(図1)から、「ストレージ管理の課題」に関するデータをご覧いただきたい。
これによると、「ストレージ管理の課題」の上位2つは、いずれもデータ容量に関する課題で占められている。「バックアップの効率化」(34.2%)と「データ量の増加への対応」(32.9%)である。
サーバーとストレージの統合によってデータが集約され、管理者がカバーするストレージ容量が増えたため、その課題が浮き彫りになっていると考えられる。今後のインフラの設計において、データ増加の課題に対する施策を誤ると、非効率でコストを無駄に浪費する運用を強いられることが予想される。
|
| 図1: ストレージ管理の課題(クリックで拡大) |
重複除外テクノロジでデータを削減
レポートによると、ストレージの管理で最も大きな課題と認識されているのは、「バックアップの効率化」(34.2%)である。通常、バックアップは何世代にもわたって取得・保持するものであるため、実際に使用しているデータ容量に対して数倍~数十倍のバックアップ容量が必要となる。このため、データ容量の増加に伴う影響が顕著に現れる。
このような課題を、ストレージのテクノロジで解決することはできないのだろうか?
実は、バックアップ・データを効率的に削減するテクノロジは、既に存在している。それは「重複除外(de-duplication)」である。一般的に、重複除外(重複排除とも呼ばれる)には、ファイル単位で重複除外を行う手法(シングル・インスタンスとも呼ばれる)や、データを固定長または可変長サイズに細かく分割して、そのデータ単位で重複除外を行う手法などがある。
重複除外は、以前からバックアップ関連の製品に実装され、既に利用者もかなり増えている。重複除外機能を搭載した製品の代表例としては、バックアップ専用ストレージ(アーキテクチャはNAS)でトップ・シェアを維持している米EMCの「Data Domain」が挙げられる。この製品は、バックアップするデータをストレージ(Data Domain)に保存する前段階で、重複除外を利用してデータ容量を大幅に削減する処理を行う(図2)。
|
| 図2: Data Domainによる重複除外バックアップの仕組み |

Data Domainは、可変長データ単位で重複除外を行う。この手法について、簡単に解説する。
バックアップ・サーバーから送られてくるバックアップ対象のデータ(ファイル)は、Data Domain上で可変長のサイズ(4K~16Kバイト)に小さく分割される。可変長サイズに分割することによってファイル同士の共通データ部分を検出しやすくなるため、重複除外の効率が高くなる(図3)。
|
| 図3: 可変長データ単位の重複除外 |
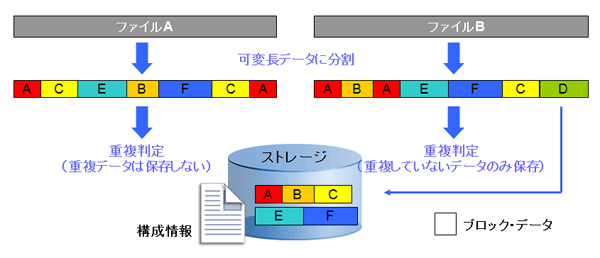
その後、分割されたデータ単位で、既に保存しているデータとの重複判別を行い、重複していないデータだけをストレージに残す。一方、あらかじめ作成する構成情報(ファイルの設計図)によって、重複除外後のデータとファイルが関連付けられているため、いつでもファイルを復元できる。
このように、Data Domainの重複除外によって、繰り返し同じファイルが保存されるという無駄を避けることができる。これにより、長期間保管されるバックアップ・データを大幅に削減できる。また、既存のバックアップ・ソフトをそのまま利用できるため、これまでのバックアップの運用手法を大幅に変更する不要がない、というメリットもある。
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
