論理データ・モデリングでデータを細かく整理
論理データ・モデリングでは、前工程で作成した概念データ・モデルをベースに、システム化の対象範囲にあるデータを細かく整理していきます。ビジネスの進む方向に沿って、決まったルールに則ってデータを整理し(正規化)、重複を排除し(最適化)、誰でも使えるように項目を直し(一般化)、さらに将来的なビジネスの変化に迅速に対応できるよう「安定性検証」を行います。
|
|
| 図1: 論理データ・モデリングの流れ(クリックで拡大) |
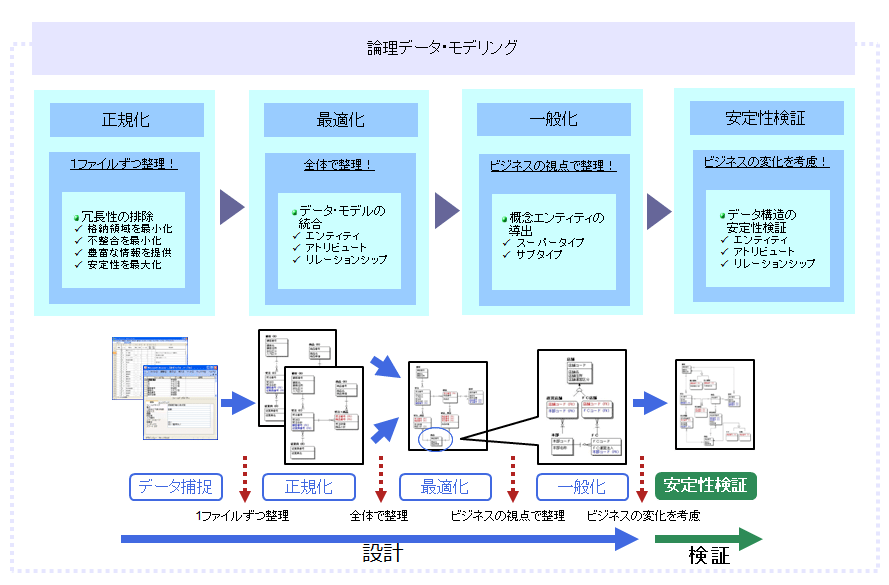
- (1)正規化
-
正規化とは、「One Fact in One Place(1つの事実は1つの場所に)」の考えに基づいて、論理的に矛盾のないデータ構造を構築するために、段階的にデータの関係を検証していく作業です。正規化は、1ファイルずつ実施するため、整理対象の数が膨大になることもあります。
正規化で重要なポイントは、誰が実施しても均一な品質を維持できるようにすることです。データの標準化がなされていれば最善ですが、そのようなことは稀なので、事前準備をしっかりしておくことが必要です。例えば、「データを整理する前に、業務が分かるユーザーにデータの意味をヒアリングするか、そのユーザーを設計工程に参画させる」などです。
- (2)最適化
-
正規化は、帳票や既存ファイルなどに対して、1ファイルずつ実施します。このため、全体的にデータ・モデルを見直した場合、「顧客エンティティが複数個存在している」ことや「顧客エンティティと取引先エンティティが、名称は異なれど実は同じものだった」ことに気付きます。
最適化とは、ファイル単位で正規化されたデータ構造について、全体最適を考慮して見直す作業です。最適化によって、システム内で重複するデータを排除し、ビジネス・ルールや業務プロセスの全体像を確認することができます。
- (3)一般化
-
ある企業において、法人顧客と個人顧客によってサービスが異なるとします。このような場合、法人顧客と個人顧客を同じ扱いにするか、それとも別々に管理するか、といった判断が必要になります。一般化では、最適化によって重複を排除したデータ構造を、よりビジネスの実態に合ったデータ・モデルに変更し、データの独立性を高めます。
- (4)安定性検証
-
安定性検証では、正規化、最適化、一般化の順に構築されたデータ構造を検証し、ビジネス変化に対して柔軟に対応できる安定したデータ構造になるように変更します。つまり、この段階で、ビジネスの変化に耐えられる、強いデータ構造にするのです。
正規化技法により、データを管理すべき最小限の単位へ
正規化の目的は、エンティティの独立性を最大限に高めると同時に、エンティティのデータを挿入、更新、削除した場合に「データ間に不整合が生じないようなデータ構造にする」ことです。
一般的な正規化手法では、第1正規化、第2正規化、第3正規化と進めながら、エンティティの分離と、リレーションシップやフォーリン・キーの設定を繰り返すことで、重複がない最小限の単位にデータを整理していきます。
表1: 一般的な正規化手法
| ポイント | 説明 | |
|---|---|---|
| 第一正規化(1NF) | プライマリ・キーの設定 繰り返し項目の分離 |
繰り返し項目をキーとともに別エンティティとして分離する |
| 第二正規化(2NF) | キー:非キー=1:1 | 複合キーの中の一部にのみ従属しているアトリビュートを別エンティティとして分離する |
| 第三正規化(3NF) | 非キー:非キー=1:1 導出項目の排除 |
アトリビュート間の従属関係を排除する 導出項目を抽出する |
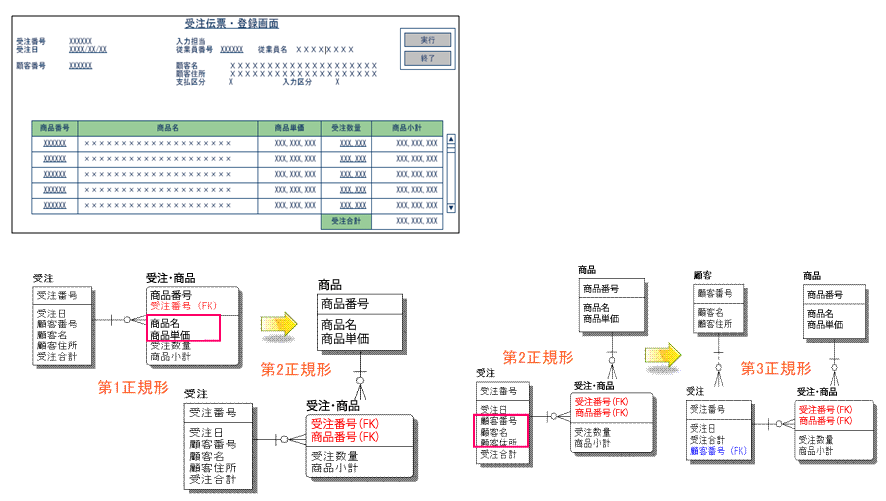
- (1)第一正規化
-
対象となるデータ群のプライマリ・キーを決め、繰り返し項目を、そのプライマリ・キー(複写)とともに、別のデータ群として分離します。図2の例では、繰り返し項目は、商品番号、商品名、商品単価、受注数量、商品小計です。これらの項目を、元のキーの「受注番号」とともに分離しています。
- (2)第二正規化
-
分離したデータ群の複合キーに、他のデータ群が完全に従属するかどうかを検証します。完全に従属しない、つまり、部分的に従属する場合は、さらに別のデータ群として分離します。例えば、受注番号が決まっても、商品名や商品単価は分かりません。しかし、商品番号が決まれば商品名や商品単価は決まります。従って、商品番号に従属している商品名、商品単価を、別のエンティティとして分離します。
- (3)第三正規化
-
第二正規化で整理対象とならなかったデータ群の中に、キー以外に従属する属性(アトリビュート)があるかを検証し、別のデータ群として分離します。例えば、第一正規化後の受注エンティティにある顧客名や顧客住所は、受注番号ではなく顧客番号に従属するため、顧客エンティティとして分離します。
|
|
| 図2: データの正規化手順(クリックで拡大) |
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
