データ・モデルを安定させる
「最適化」は全体をみて整理する正規化では、1ファイルずつデータを整理します。このため、正規化されたデータ構造を全体的に見直すと、顧客エンティティが複数個存在することや、顧客エンティティと取引先エンティティが、名称は異なるが実は同じものだった、ということに気づきます。この問題を解決するため、「最適化」
2010年10月21日 20:00
「最適化」は全体をみて整理する
正規化では、1ファイルずつデータを整理します。このため、正規化されたデータ構造を全体的に見直すと、顧客エンティティが複数個存在することや、顧客エンティティと取引先エンティティが、名称は異なるが実は同じものだった、ということに気づきます。
この問題を解決するため、「最適化」と呼ぶ工程で、システム内で重複する属性(データ項目)を排除し、ビジネス・ルールや業務プロセスの全体像を確認します。
|
| 図1: 「最適化」のイメージ |
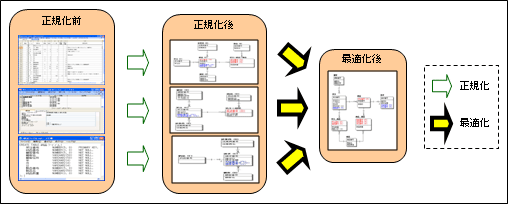
最適化の手順は、以下の通りです。
- 同一のプライマリ・キーを統合
- 属性を1つのエンティティに統合
- リレーションシップを再設定
1. 同一のプライマリ・キーを統合
名称が同じものや、データの意味が同じものに着目して、同一のものは1つにまとめます。
例えば、「取引先番号」と「顧客番号」のように、名前が異なっても同じ意味内容を持つ"シノニム(異音同義語)"、同じ「担当者名」であっても「社内担当者名」の場合と「顧客担当者名」の場合がある"ホモニム(同音異義語)"、「製造番号」という標準名のほかに「製番」という短縮名などの"エリアス(別名)"、に注意してデータを整理します。
- シノニム(異音同義語)
- ホモニム(同音異義語)
- エリアス(別名)
2. 属性を1つのエンティティに統合
属性(アトリビュート)が重複しないように、各属性を1つのエンティティに従属させます。ここでは、プライマリ・キーと同様、属性の名称や意味にシノニム、ホモニム、エリアスが存在しないかどうかを確認します。
例えば、製品エンティティと商品エンティティがある場合、製品番号と商品番号を同一キーとみなし、製品エンティティに商品名という属性と製品名という属性を従属させるとします。製品名と商品名が同じデータ値を管理しているのであれば統合できますが、製品名が英数字の型番で、商品名がカタログ上の日本語であれば、統合することはできません。
3. リレーションシップを再設定
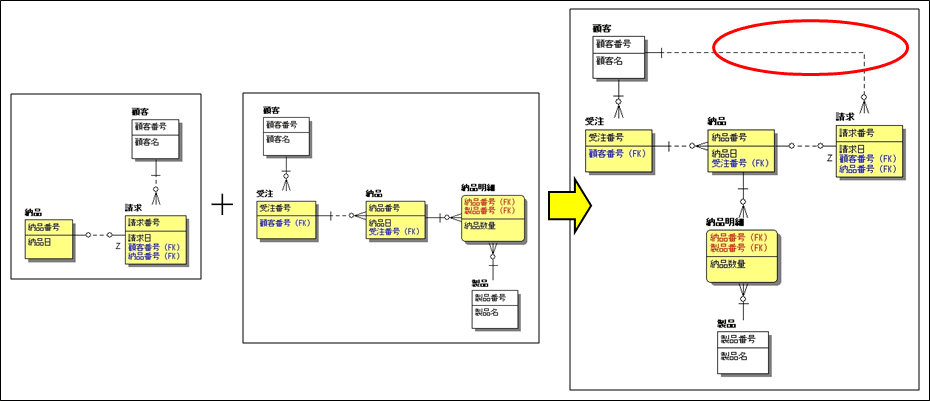
エンティティを統合する前から存在しているリレーションシップを、抜け漏れなく再定義します。図2の例は、エンティティを統合した結果、顧客と受注、顧客と請求という2つのリレーションシップが発生してしまったケースです。
リレーションシップが冗長であれば、削除します。しかし、図2の例で「請求先と受注先は異なる」というビジネス・ルールがあった場合は、削除できません。このように、自社のビジネス・ルールと合っているかどうかを検証する必要があります。
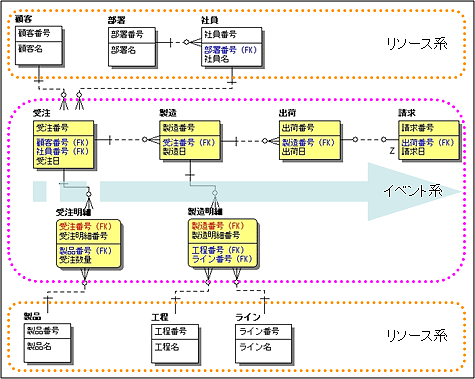
ビジネス・ルールと照らし合わせる際には、図3のようにイベント系エンティティを左から右に時系列で配置すると、後でだれがみても分かりやすいデータ・モデルになります。
|
| 図2: リレーションシップの再設定(クリックで拡大) |
|
| 図3: エンティティの配置 |
「一般化」によって、運用できる形に直す
一般化は、類似するものを無理に統合するのではなく、ビジネスの実態に応じて変更していく作業です。自社のビジネス・ルールに応じて、エンティティの汎化または特化を検討します。
例えば、同じ顧客でも、提供するサービスが違うのであれば、サブタイプとして「法人顧客」と「個人顧客」に具体化して管理する、といった具合です。また、「顧客」という上位タイプ(スーパータイプ)に抽象化して管理した方がよい場合もあります。
一般化により、特定のエンティティやビジネス・ルールを、より分かりやすく表現できます。
例えば、図4の左側に示したデータ・モデルでは、店舗にどのような運用形態があるのか分かりません。さらに、すべての店舗がFC(フランチャイズ)と関連があるように見えます。一方、図4の右側に示した、一般化作業を経た後のデータ・モデルでは、店舗には直営店舗とFC店舗があり、直営店舗は本部にのみ関係することが分かります。
一般化を経ることによって、データの自立性が高まります。これにより、店舗網全体の情報活用が進むだけでなく、直営店舗はアンテナ・ショップとしてのマーケティング情報を、FC店舗はローコスト・オぺレーションとしての管理情報を、具体的に活用できるようになります。
一般化の対象は、リソース系エンティティだけでなく、イベント系エンティティにも適用できます。さらに、サブタイプ化の数や階層の数には制限がありません。
|
| 図4: 一般化の例 |

この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
