Xeon初のSoC、マイクロサーバー向けプロセッサのアーキテクチャ(後)
前回に引き続き、Xeon Dのアーキテクチャについて各部分について見ていくことにしましょう。CPUコアまずは、CPUコア部分です。この部分は、パソコンなどと同じくBroadwellですが、パソコン向けの第5世代CoreプロセッサのCPUコアとは同一ではありません。ただし、同じHaswellマイクロア
2015年5月27日 17:00
前回に引き続き、Xeon Dのアーキテクチャについて各部分について見ていくことにしましょう。
CPUコア
まずは、CPUコア部分です。この部分は、パソコンなどと同じくBroadwellですが、パソコン向けの第5世代CoreプロセッサのCPUコアとは同一ではありません。ただし、同じHaswellマイクロアーキテクチャを採用しているため、ブロックダイアグラムなどでみると、非常によく似た構成になっています。
CPUコアはLLC(Last Level Cache。レベルとしては第3レベルに相当)と対になっていて、それをリング状のバスが接続する構造です(図1)。パソコン向けのCoreプロセッサでは、このリングにシステムエージェントとGPUがさらに接続していますが、Xeon Dでは、GPUは搭載されていないため、I/Oを接続するIIOとHigh Availabilityメモリコントローラーが接続しています。メモリコントローラーは、Coreプロセッサではシステムエージェントに含まれていました。
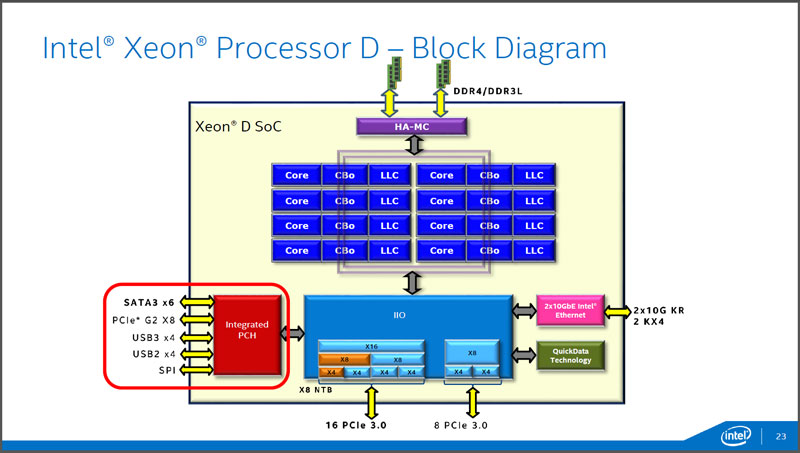
図1:Xeon Dの内部構造。CPUコアとLLCが対になったブロックをリング状のバスが接続、そこにメモリコントローラーとIIOがつながっている。IIOには10GビットイーサーやPCI Express 3.0およびPCHが接続されている(出典:インテル)。
IIOは、I/O関連を束ねており、10GビットイーサーネットやPCHもIIO経由でCPUコアと接続しています。また、このIIOに16レーンと8レーンのPCI Express Gen.3が搭載されており、新規設計となるため、インテルの従来のPCHにはなかった機能としてCRCによるエラー検出、訂正が搭載されています。
また、既存のXeon系プロセッサが持つデータ転送をハードウェアで行い、ネットワークによる通信を効率化する「クイックデータテクノロジー」も搭載されている。
RAS機能
Xeonシリーズとなるためには、RAS関連機能が必要ですが、Xeon DのCPUコアにもRAS機能が搭載されています。MCAとよばれるMachine Check Architectureは、エラーを検出して自身で修正を行い、OSへ通知を行って、リカバリー動作を起動するなど、システムの信頼性を高めるための技術で、Xeon Dにもこうした機能が搭載されています(図2)。このあたりは、同じSoCを使ったAtom系のサーバー向けプロセッサとは違う部分です。もっとも、こうした機能がなければ、Xeonという名称にはならなかったはずです。
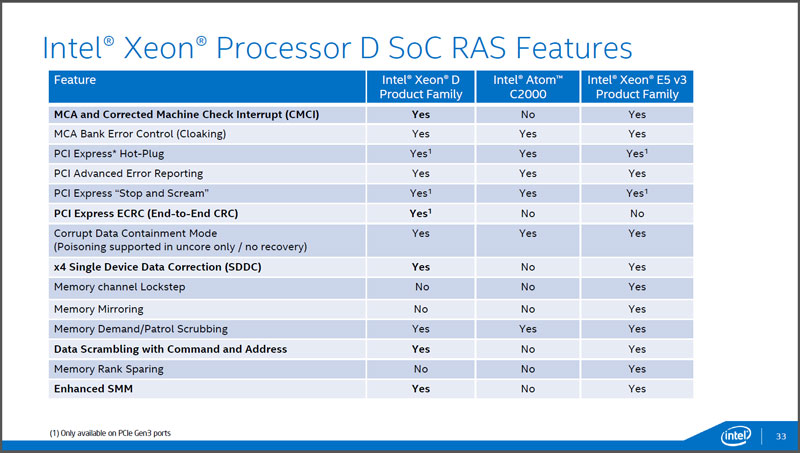
図2:Xeon DとXeon E5 v3、およびAtom C2000シリーズのRAS機能比較。C2000に比べてXeon Dは、MCAなど多くのRAS機能を搭載するが、接続可能なメモリが少ないため、メモリ関連のRAS機能には実装されていないものもある(出典:インテル)。
ただし、上位プロセッサに比べるとメモリ搭載量(接続DIMM数)が限られているため、一部のRAS関連機能は省略されています。
キャッシュ(LLC)に関しては、上位のEシリーズほど大量のキャッシュメモリを搭載しているわけではありません。この点では、Xeon Eと比べると、比較的負荷の軽いアプリケーションを想定しているようです。D-1540は、8コアで12Mバイト、D-1520は、4コアで6MバイトのLLCを搭載しており、1コアあたり1.5Mバイトになります。キャッシュメモリは、ダイ上で大きな面積を占めるため、キャッシュサイズを大きくすると、コストが急激に上昇します。また、性能的にも近いE3との差別化を図る意味でもキャッシュサイズを調整しているのだと考えられます。
また、パソコン用のCoreシリーズとの大きな違いとして、TSX(Transactional Synchronization Extension)が有効になっている点があります。TSXは、以前「トランザクショナルメモリ」と呼ばれていた技術で、1つ前の世代であるHaswellで実装されました。しかし、バグがあったため、後継の第5世代Coreプロセッサでも回路は搭載されているものの、機能としては無効になったままでした。
TSXは、Lockプリフィックスによるロック機能によるシステムの停止を抑え、マルチスレッドで共有メモリをアクセスする処理を高速化することが可能な技術です。利用条件さえ満たせれば、システムを高速化可能なのですが、書き込みなどを検出して処理を巻き戻すといった複雑な動作を行うものであるため、最初の実装は、うまくいきませんでした。
今回、TSXが復活したのは、改良が行われ、既知の問題を解決したためと思われます。インテルは、数年以上前からこのトランザクションメモリについて技術的な発表を行うなど、ある種の「目玉」機能だったのですが、バグで無効化されるなど、あまりいい立ち上がりではありませんでした。また、次世代のSkylakeマイクロアーキテクチャまで修正されないというウワサもあったのですが、Xeon Dで修正を行い、機能を復活させました。今後発表されるであろう、Broadwellを採用するXeon Eプロセッサなどでも復活する可能性があり、インテルとしては、サーバー向けアプリケーションなどからTSXを普及させたいと考えていると推測されます。
ベンチマーク
発表時点では、Xeon Dを搭載した製品がなく、インテルは、社内で行った、プロトタイプのXeon Dを使ったベンチマークなどを公開している。比較対象は、従来のSoC型のサーバープロセッサであるAtom C2000。ベンチマークの目的は、C2000でカバーできない領域をXeon Dがカバーしているところを示すためのもの。
1つは、汎用演算機能を比較するもので、STREAM OpenMPによるメモリバンド幅測定とSPECintによる整数演算性能。Atom C2750の結果を1とすると、メモリバンド幅は1.78倍、整数演算は2.63倍という結果になっている。

図3:汎用演算のベンチマーク。C2750と比較してメモリのバンド幅で1.78倍、SPECintテストで2.63倍の性能がある(出典:インテルホームページより)。
※ベンチマークの内容、条件などについては、以下のURLを参照ください
http://www.intel.co.jp/content/www/jp/ja/benchmarks/server/xeon-d/xeon-d-general-technical-compute.html
ネットワークサーバーとしての性能比較としてはクラウドベンチマーク、サーバーサイドJava、ダイナミックWebサービングなどのベンチマークが行われており、それぞれ2.27倍、3.15倍、3.40倍となっている。
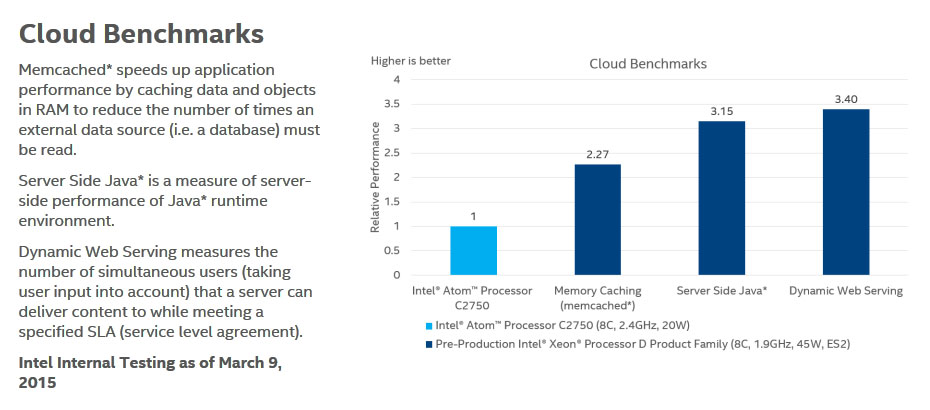
図4:クラウド用途でのベンチマーク。サーバーサイドJavaの性能などで、C2750の2.27~3.40倍の性能(出典:インテルホームページより)。
※ベンチマークの内容、条件などについては、以下のURLを参照ください
http://www.intel.co.jp/content/www/jp/ja/benchmarks/server/xeon-d/xeon-d-cloud.html
ストレージ用途向けでは、IO速度のベンチマークが行われおり、512Kバイトの大型パケットを使うストリーミングI/Oでは、C2750の1.34倍、4KバイトのちいさなパケットのトランザクションI/Oの測定では2.52倍という結果が出た。
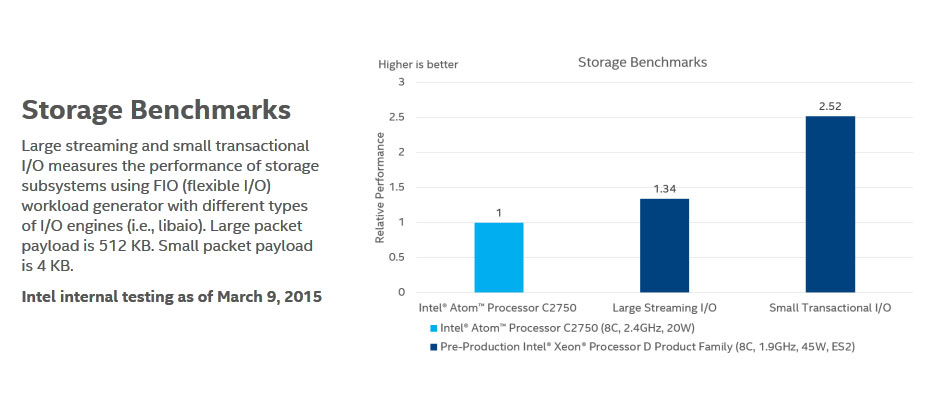
図5:ストレージ向けのIO処理性能では、C2750の1.34~2.54倍の性能があるという(出典:インテルホームページより)。
※ベンチマークの内容、条件などについては、以下のURLを参照ください
http://www.intel.co.jp/content/www/jp/ja/benchmarks/server/xeon-d/xeon-d-storage.html
ネットワークでは、レイヤ3パケットの転送速度を大小2つのパケットサイズで測定。こちらも1528バイトのパケットで2倍、64バイトのパケットで3.09倍という結果が出ている。
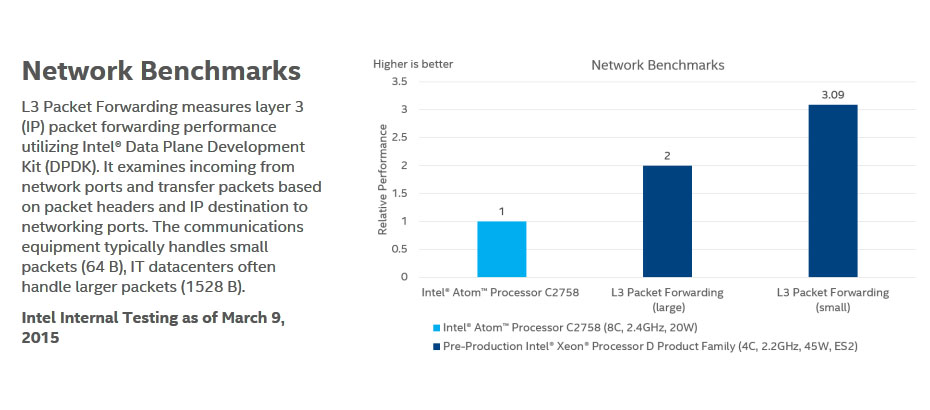
図6:ネットワーク関連のベンチマーク。パケットの転送性能では、C2750の2~3.09倍の性能がある(出典:インテルホームページより)。
※ベンチマークの内容、条件などについては、以下のURLを参照ください
http://www.intel.co.jp/content/www/jp/ja/benchmarks/server/xeon-d/xeon-d-network.html
こうした結果をもとにインテルは、Xeon DはC2750に対して3.4倍程度の性能を持つとしています。
Xeon Dは、これまでのXeonプロセッサ(Xeon E)を下方向に拡大し、ネットワークで「エッジ」と呼ばれる領域をカバーすることを狙った製品です。この領域は、これまで、無理してXeon Eを使うか、パソコン向けのCoreシリーズで実現されていた領域で、どちらかといえば、空白地帯といえる領域です。とりあえずは、D-1520とD-1540を「様子見」として投入し、普及に応じて製品ラインアップを強化していくことになると思われます。また、下位にあたるAtom C2000シリーズもXeon Dの登場で終わるのではなく、下位シリーズとして継続するようです(図7)。
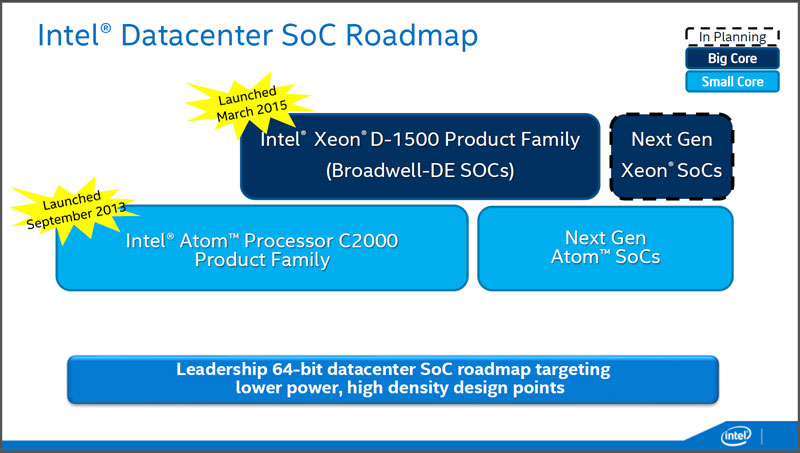
図7:インテルのデータセンターSoC製品のロードマップ。Atom C2000ファミリもこれで終わりではなく、次世代のSoCが予定されており、さらにXeon Dも後継製品が登場する。(出典:インテル)
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
