Xeon E7 v3のアーキテクチャ(後)
今回は、Xeon E7v3の内部構造、強化機能の詳細、性能評価についてインテルの公開しているベンチマーク結果について、見ていきます。Xeon E7v3の内部構造次に内部構成などを見ていくことにしましょう。まず最大コア数が18コアとなったことで、内部のリングバス構造が変わりました。前世代のIvyBri
2015年5月29日 17:00
今回は、Xeon E7v3の内部構造、強化機能の詳細、性能評価についてインテルの公開しているベンチマーク結果について、見ていきます。
Xeon E7v3の内部構造
次に内部構成などを見ていくことにしましょう。まず最大コア数が18コアとなったことで、内部のリングバス構造が変わりました。前世代のIvyBridge-EXでは、各コアに2本のリングバスが接続するように、コアを3つのグループにわけて3つのリングバスを使っていました。これに対してHaswell-EXでは、コアを2つのグループにわけ、グループ内で2つのリングバスを使ってコア間を接続し、グループ間でリングバスを接続するBuffered Switchを間に持つ。ただし最大18コアであるため、片方のグループは8コアが、もう一方のグループには10コアが含まれる。コア数ではアンバランスですが、8コア側のグループのリングバスには、2つのQPIチャンネル(10コアグループでは1チャンネルのみ)があり、さらにPCI Expressなどを含むIIO(Integrated IO)ハブモジュールが接続しています。なお、メモリは、両グループとも2チャンネル接続が可能なコントローラーがあります。
リングバスを使う構成は、Sandy Bridge世代で登場したが、コア数が増えるにしたがってリングバス構成にも変化が出てきた。Xeon E7v3では、コアや周辺モジュールなどのリングバスにつながるコンポーネントを2つのグループにわけ、その間をBuffered Switchで接続するという構成になりました。
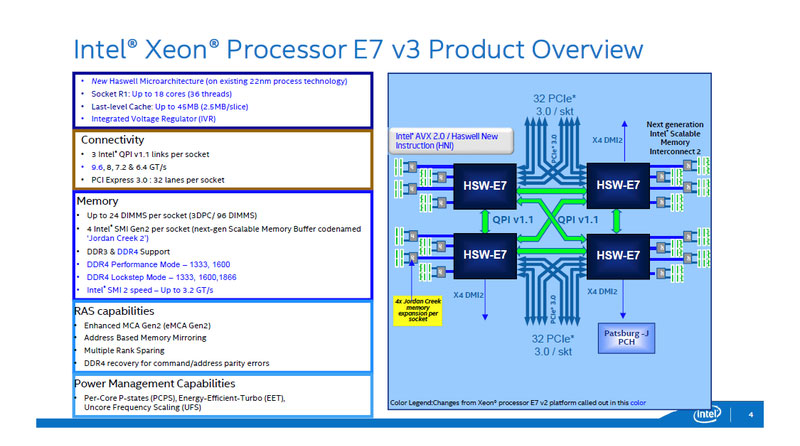
図1:E7v3の内部構造①。4ソケットの場合のE7v3のシステム構成例。QPIでCPU間を接続し、それぞれのCPUにメモリが接続します。(出典:インテル)
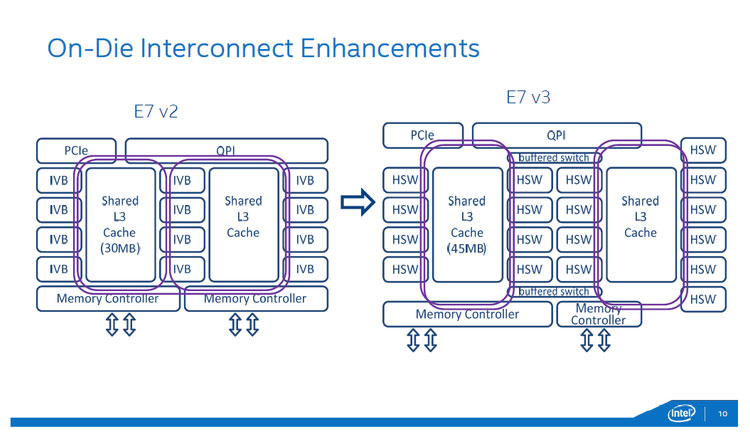
図2:E7v2とE7v3の内部接続リングバスの構成の違い。E7v3では、2重のリングバス同士をBuffered Switchで接続します。(出典:インテル)
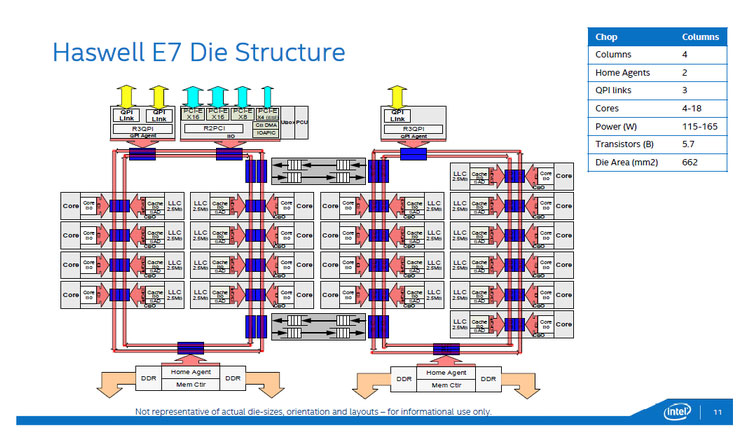
図3:詳細な内部構成。CPUコアは8個と10個のグループに分かれ、その間をBuffered Switchが接続します。8コアグループ側にIIO(Integrated IOハブ)が接続し、両グループにメモリコントローラーとQPIインターフェイスがあります。(出典:インテル)
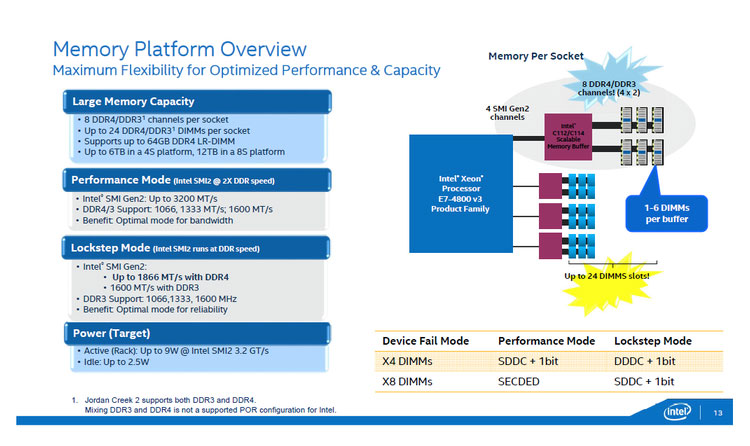
図4:Xeon E7v3のメモリアーキテクチャ。Xeon E7v3は、メモリコントローラーを内蔵していますが、メモリには、Intel C112/114を介して接続します。このC112/114は、DDR4、DDR3対応になっています。(出典:インテル)
Xeon E7v3の強化機能の詳細
ここでは、Xeon E7v3で追加された機能を細かくみていくことにしましょう。まず、現時点でE7v3のみに搭載されている機能は、強化されたRAS機能(Run Sure Technology)だ。E7系列は、高可用性サーバーに採用されることも多く、かつてはメインフレームが担ってきた作業を行うこともあります。このため、他のXeonと比較するとRAS機能が特に強化されています。
この強化されたRAS機能の内訳は以下の通りとなっています。
- 第二世代eMCA(Enhanced Machine Check Architecture)
- Address Base Memory Mirroring
- Multiple Rank Sparing
- DDR4 recovery for command/address parity errors
第二世代eMCA
まず第二世代eMCAですが、これは、Xeon Ev2に装備されていたeMCAをベースに、Itaniumに装備されていたファームウェアモデルを取り入れたものです。第2世代eMCAが採用するファームウェアモデルをFirmware First Model(FFM)といいます。この第2世代eMCAでは、ハードウェア側でリカバリしたエラーやリカバリが不可能なエラーを含め、すべてのエラーをファームウェアで受け取ることが可能になりました。第1世代のeMCAでは、ファームウェアが受け取ることができない訂正不可能なエラーがありました。また、eMCA実装以前の初期のXeonのMCAでは、エラーは基本的にオペレーティングシステム(あるいは仮想マシン用ハイパーバイザー)がエラーを処理することになっていました。
ファームウェアは、いわゆるBIOSやUEFIのようにハードウェアに直接搭載されているソフトウェアで、通常はフラッシュメモリなどに格納されて、ハードウェアに組み込まれる。このファームウェアは、ハードウェアベンダーが実装し、特殊なモード(SMM。System Management Mode)で動作するため、利用しているオペレーティングシステムなどに依存せず、エラー時にも必ず動作できるようになっています。すべてのエラーをファームウェアが処理することが可能になるため、確実にエラーの記録が行え、また、ハードウェア構成などの知識を利用して、オペレーティングシステムに通知するエラーをファームウェア側で制御することができるようになります。 Xeon E7v3に実装された第2世代eMCAでは、Xeon内部のエラー関連のレジスタにファームウェアが書き込むことが可能になり、オペレーティングシステム側にエラーを通知する場合にファームウェアがエラー情報を加工することができます。
Address Base Memory Mirroring
「Address Base Memory Mirroring」は、メモリを2重化(ミラーリング)して、信頼性を上げる技術で、メモリがエラーで読み出せなくても、もう一方のコピーを使うことで、メモリ上の情報を回復できます。従来のメモリ・ミラーリングでは、同一チャネルに接続している同容量のDIMM2枚でミラーリングを構成していたが、「Address Base Memory Mirroring」では、オペレーティングシステムやファームウェア側でミラーリングを行う領域を物理的なメモリ構成に関係なく、メモリアドレスで指定できます。これにより、用途に応じて二重化が必要な領域のみを保護することができようになります。ミラーリングは信頼性を高めることはできるものの、利用できるメモリ容量は減ってしまう。従来のミラーリングはDIMM単位で、物理メモリ範囲でしかミラーリングを指定できなかったため、不要な部分までミラーリング領域に含まれる可能性があった。しかし、アドレスを使ってオペレーティングシステムがこれを指定することで、必要な領域のみをミラーリングすることが可能になりました。たとえば、プログラムコード領域はミラーリングせず、データを格納している領域のみをミラーリングするといった使い方が可能だ。最近では、データをファイルに置かずオンメモリで処理することで高速化する手法などが普及しつつあり、ミッション・クリティカルな分野でもミラーリングを併用することでこうした手法を利用可能になります。
Multiple Rank Sparing
「Multiple Rank Sparing」は、同じメモリコントローラーに接続している、ランク単位でスペアを設定する機能。ランクとはDIMM内のメモリ動作単位。64bit幅のメモリを構成するメモリチップのグループに相当します。シングルランクDIMMは、ランクを1つしか含まないDIMMをいう。DIMMによってはランクを2または4含むものもあります。これらをそれぞれデュアルランク、クワッドランクと呼ぶ。実際にメモリコントローラーが制御する単位がランクで、DIMMスロットが余っていてもランク数が上限に達しているとそれ以上メモリを接続することはできない。
Rank Sparingは、メモリコントローラーに接続されているランクの一部をスペアとして設定し待機させておいて、メモリエラー頻度が高くなったときに、スペアに切り替えるもの。もともとXeonに装備されていた技術ですが、従来のランクスペアリングでは、構成方法が固定になっていたが、Xeon E7v3の「Multiple Rank Sparing」では、同一メモリコントローラー内でDDRチャンネルあたり最大4つのスペア用ランクを指定できます。なお、この機能は、ファームウェア側でシステム構成として行うもので、オペレーティングシステム側は関与しない。訂正可能なECCメモリエラーなどの発生率が一定以上になるとスペアメモリにデータがコピーされ、エラーが多発したランクはシステムから切り離される。スペアがあるため、必ずしもメモリエラーが発生したらメモリを交換する必要がない。これにより、メンテナンスやサーバー停止の間隔を延ばすことが可能で、管理コストを削減できます。
DDR4 recovery for command/address parity errors
「DDR4 recovery for command/address parity errors」は、DDR4メモリへのコマンド送出などにおけるパリティエラーからのリカバリを可能にするものです。DDR系のメモリは、メモリコントローラーからコマンドを送って、読み書きなどを指示しています。信号線の名称などは昔のアドレスを分割して送信しているときと同じですが、現在では、かつてのアドレス信号線にコマンドが流れています。このため、コマンド/アドレス信号と呼ばれるようになっています。DDR4では高速化の代償としてノイズなどのエラーに弱くなるため、コマンド/アドレス信号でパリティチェックを行うための信号線が新規に定義されました。これは、メモリコントローラーがコマンド/アドレス信号を送出するときにパリティビットを計算してこの信号線に乗せ、DDR4メモリ側で送られてきたコマンド/アドレス信号でパリティによるチェックを行う。このとき、1ビットの違いがあれば、パリティエラーとなります。「DDR4 recovery for command/address parity errors」とは、このときにリカバリを行うしくみだ。パリティエラーがあれば、DDR4メモリ側からパリティ信号線を通してエラーがメモリコントローラーに通知される。その後のリトライなどは、エラーを通知されたファームウェア側などで行う。
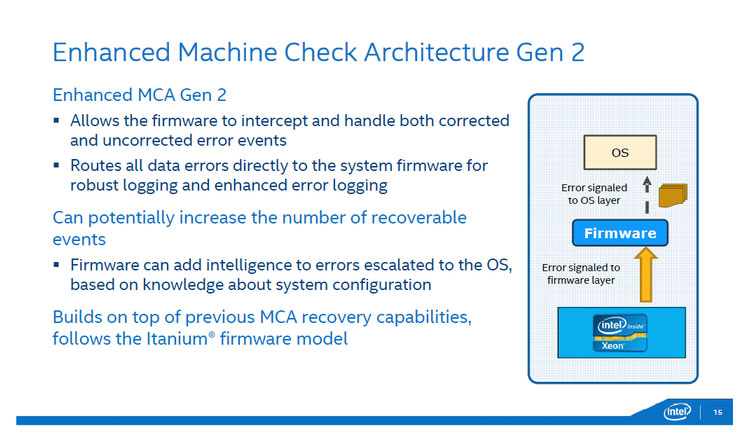
図5:第2世代eMCA。すべてのエラーはファームウェアで細く可能で、E7v3では、CPUのエラー情報レジスタの書き換えも可能。(出典:インテル)
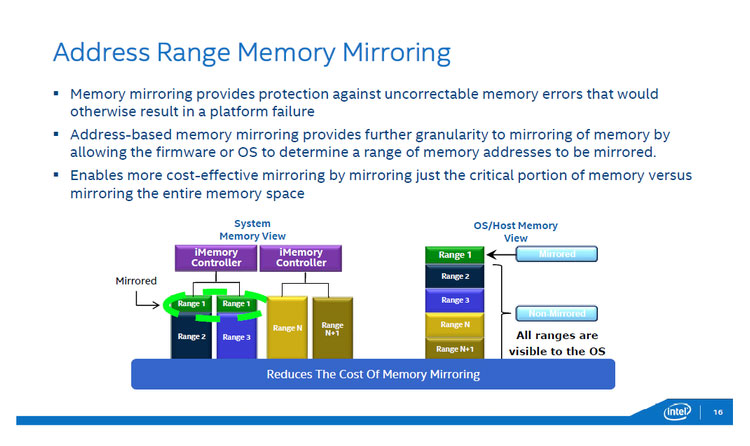
図6:Address Range Memory Mirroring。DIMM単位ではなく、アドレスでミラーリングの範囲を指定できる。(出典:インテル)
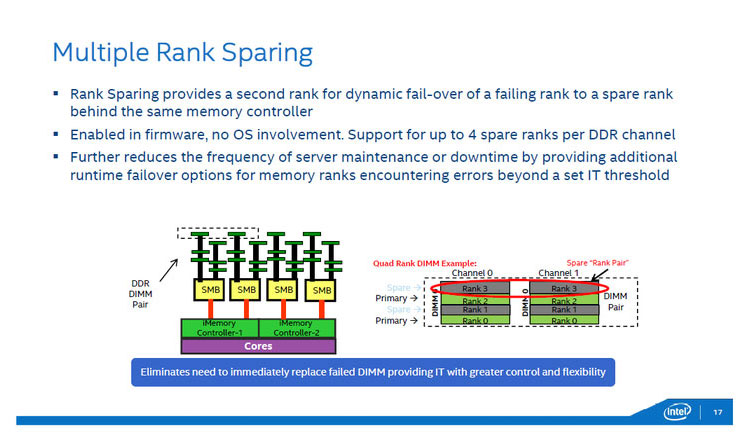
図7:Multiple Rank Sparing。DDRメモリの動作単位であるランク(64bitデータを構成するメモリチップのグループ)単位でスペア、通常利用を設定し、エラーが多発したときにスペアに切り替えを行う。(出典:インテル)

図8:DDR4 Command/Address Parity Error Recovery。DDR4メモリが持つコマンド/アドレス信号のパリティチェック機能を使って、コマンドなどのエラーを検出し、リカバリが可能。(出典:インテル)
AVX2とTSX
RAS関連の機能は、ファームウェアやオペレーティングシステム側で処理される機能であるため、オペレーティングシステムのカーネル開発者などは利用する機能ではあるが、アプリケーションを開発する一般の開発者はほとんど扱うことがない。これに対して、Xeon E7v3がもつAVX2命令やTSXに関しては、一般アプリケーション開発者が利用する可能性のある機能だ。
インテルは、浮動小数点演算やSIMD演算に関して、AVXという新たな命令セットを追加しています。そもそもSIMD演算は、古くはPentium世代で実装されたMMXに始まる。MMXはその後ずっと拡張されSSE(Streaming SIMD Extensions)と呼ばれるようになりました。インテルは、SandyBridge世代で、命令デコードやのちの拡張が容易なVEXと呼ばれる3オペランド構成のAVXを導入しました。これは、256ビットを使ってSIMD演算を行うもので、既存のSSE命令相当の機能をVEX形式でも持つ。
Xeon E7v3に搭載されたのは、その拡張版で命令が追加され、256ビットのSIMD整数演算などが可能になりました。また内部的な改良により、演算性能が向上しており、積和演算などで、Sandy Bridge/Ivy Bridge世代の倍の性能を持つ。
TSXは、かつて「トランザクションメモリ」などと呼ばれていた技術で、マルチスレッドでの処理中に処理の元になるデータが書き換えられたことを検出して、処理をやり直す機能やロック命令プリフィックスによるCPUの停止を回避するなどして総合的な処理性能を向上させる機能だ。多数のスレッドを使う並列処理などに効果があります。このTSXは、一度クライアント向けのCoreプロセッサで導入されたものの、出荷後に不具合が見つかり、現在では、機構そのものは回路として残っているものの、マイクロコードで無効にされています。
インテルは、最近発表したXeon-DでこのTSXを復活させた。Xeon用にHaswellを改良する際に、不具合を修正したのだと思われる(ただしE5v3では無効にされたままだ)。
TSXは、簡単にいうと、計算に使ったメモリの値が書き換えられたら、最初から計算をやりなおす、書き換えられなかったらそのまま計算を続ける、という仕組みであるため、監視対象とするメモリ領域で書き換えが起こらなければ、そのまま計算を続けることができるため、プログラムが簡単になり、処理時間が短縮される。
E7v3のパフォーマンス
最後に、Xeon E7v3の性能をベンチマークなどから見ていくことにしましょう。インテルのサイトには、いくつもベンチマーク結果があるが、まずは、浮動小数点演算を多用するLINPACKベンチマークだ。これによれば、E7v3は、E7という型番が始まった最初の世代(Westmereコア)に対して6倍弱、前世代のIvy Bridgeコアに対しても75%の性能向上があります。これは、主にAVX2による性能向上やクロック周波数、スレッド数(コア数)の違いが効いています。しかし、E7-4890v2は、15コアとE7-8890v3とコア数が大きく変わらず、クロック周波数は2.8GHzと高くなっている(E7-8890v3は2.5GHz)。
次は、メモリの帯域幅を測定するベンチマークですが、これも、Xeon E7-4870の2.6倍の性能があります。ただし、E7-4890v2との性能差は8%とさほど大きくない。
最後はデータベース関連でSQL Serverを使ったOLTP(On Line Transaction Processing)のベンチマークですが、やはりXeon E74870の2倍という性能になります。ただし、E7-4890 v2とは、25%増しの性能しかない。
これらのベンチマークを見るに、Xeon E7v3は、Westmereコアを採用した初代Xeon E7以前のXeonに対しては圧倒的な差があることがわかる。これらは導入されてすでに数年以上がたつため、まずは、これらのリプレースがE7v3の主なターゲットとなるでしょう。

図9:浮動小数点演算の速度を測るLINPACKベンチマークの結果。E7-4870の結果を1とした場合、E7-8890v3は6倍弱の性能を示す。(出典:インテル)

図10:SQL ServerによるOLTPベンチマーク。E7-8890v3はE7-4870の2倍の性能を出せる。(出典:インテル)

図11:メモリ帯域のベンチマーク。E7-8890v3はE7-4870の2.6倍の差がある。(出典:インテル)
Xeon E7v3は、Xeon系列では、ハイエンド向けの製品で、各社のハイエンドサーバーなどに採用されていますが、今回のE7v3により、全体的な処理性能が向上しているため、以前のE7や7000系列のXeonを使ったサーバーと比較すると同程度の処理ならば、複数ラックが必要だった構成を、単純な3Uなどのハードウェアに集約できる可能性が出てきました。あるいは、他のサーバーも含め仮想化でさらなるサーバー集約化も可能になりました。
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
