Web UI からデータを登録してみる
Web UI からデータを登録してみる
BigQueryを利用するには、まず「データセット」を作成しておく必要があります。データセットはテーブルをグループ化するためのものです。前述した例ではクエリで「publicdata:samples.wikipedia」という指定をしましたが、ここで「publicdata」はプロジェクトID、「samples」がデータセット名、そして「wikipedia」がテーブル名にあたります。Web UIでは、プロジェクトを選択した状態であるため、プロジェクトIDを省略できます。
それでは、Web UIからデータを登録してみましょう。プロジェクト名(図5ではMy First Project)の横にあるアイコンをクリックし、[Create new dataset]を選びます。ここでは、Dataset IDとして「thinkit_bigquery」を入力しています(図6)。
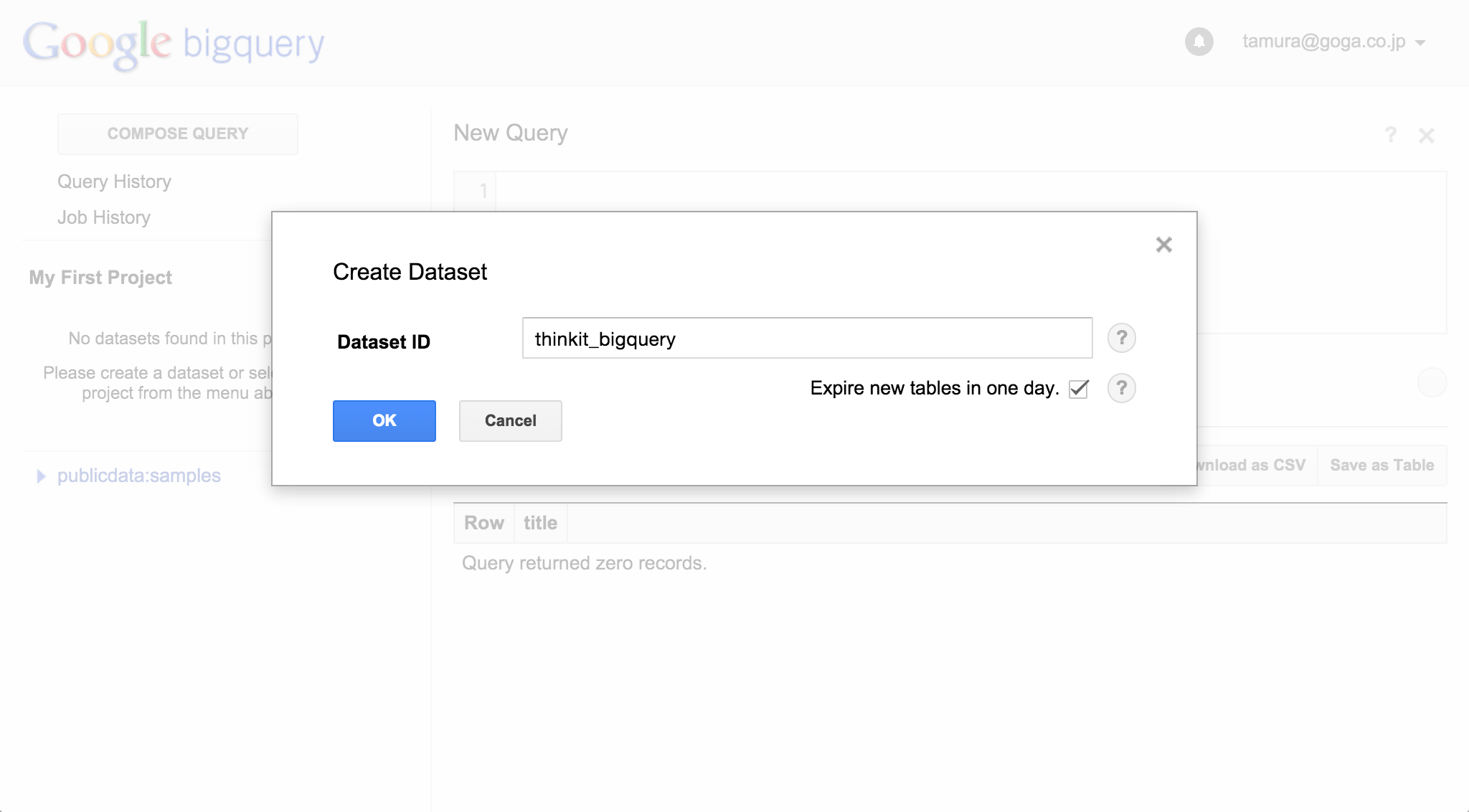
図6:Web UIのデータセット作成画面
データセットはすぐに作成されます。次に「thinkit_bigquery」横のアイコン(▼)をクリックし、[Create new table]を選びます。[Choose job template]では、過去にテーブルを作成した際の設定を流用できるものですが、ここでは使わずに[Choose destination]に進みます。この画面では、データセットとテーブル名を指定します。今回はデータセットに「thinkit_bigquery」を指定し、テーブルに「access_log」と名付けています。
![[テーブル作成画面]テーブル名の指定](/sites/default/files/634607.png)
図7:[テーブル作成画面]テーブル名の指定
続いて[Select data]の項目です。この画面では、インポートするデータを選びます(図8)。データの形式としてはCSV、JSON、およびCloud Datastoreのバックアップが選べます。またインポートの方法としてはWeb UIからのアップロードと、Cloud Storageからの転送が選べます。今回はWeb UIからCSVファイルをアップロードしてみます。CSVの内容は以下の通りです。
2015-01-01 09:00:00.000 +09:00, GET, /index.html
2015-01-02 09:00:00.000 +09:00, HEAD, /index.html
2015-01-03 09:00:00.000 +09:00, GET, /index.html
2015-01-04 09:00:00.000 +09:00, HEAD, /index.html
2015-01-05 09:00:00.000 +09:00, GET, /index.html
2015-01-06 09:00:00.000 +09:00, HEAD, /index.html
2015-01-07 09:00:00.000 +09:00, GET, /index.html
2015-01-08 09:00:00.000 +09:00, HEAD, /index.html
2015-01-09 09:00:00.000 +09:00, GET, /index.html
2015-01-10 09:00:00.000 +09:00, HEAC, /index.html
![[テーブル作成画面]データの選択](/sites/default/files/634608.png)
図8:[テーブル作成画面]データの選択
続いて[Specify schema]の画面でテーブルのスキーマを指定します。[Add field]でカラムを増やし、それぞれ「timestamp」、「method」、「uri」とします。また「timestamp」だけは、Typeを「TIMESTAMP」にします。それ以外は「STRING」のままでOKです(図9)。また、次の[Advanced options]画面では、データの形式などについて詳細な設定が行えますが、今回は必要ありませんので、画面下部の[Submit]を押してテーブルを作成しましょう。
![[テーブル作成画面]スキーマの定義](/sites/default/files/634609.png)
図9:[テーブル作成画面]スキーマの定義
すると「thinkit_bigquery」の下に「access_log」が作成され、「(loading)」と表示されています。Web UIやAPIを使用してファイルをBigQueryに送信する方法(Bulk load)では、処理がジョブという形で登録され、完了を待つことになります。
図10:テーブル作成ジョブ実行中
「loading」の表示が消えたことを確認したのち、作成したテーブルに対してクエリを発行してみましょう。
SELECT * FROM thinkit_bigquery.access_log;
と入力して[RUN QUERY]を押すと、CSVのデータが登録されていることを確認できます。
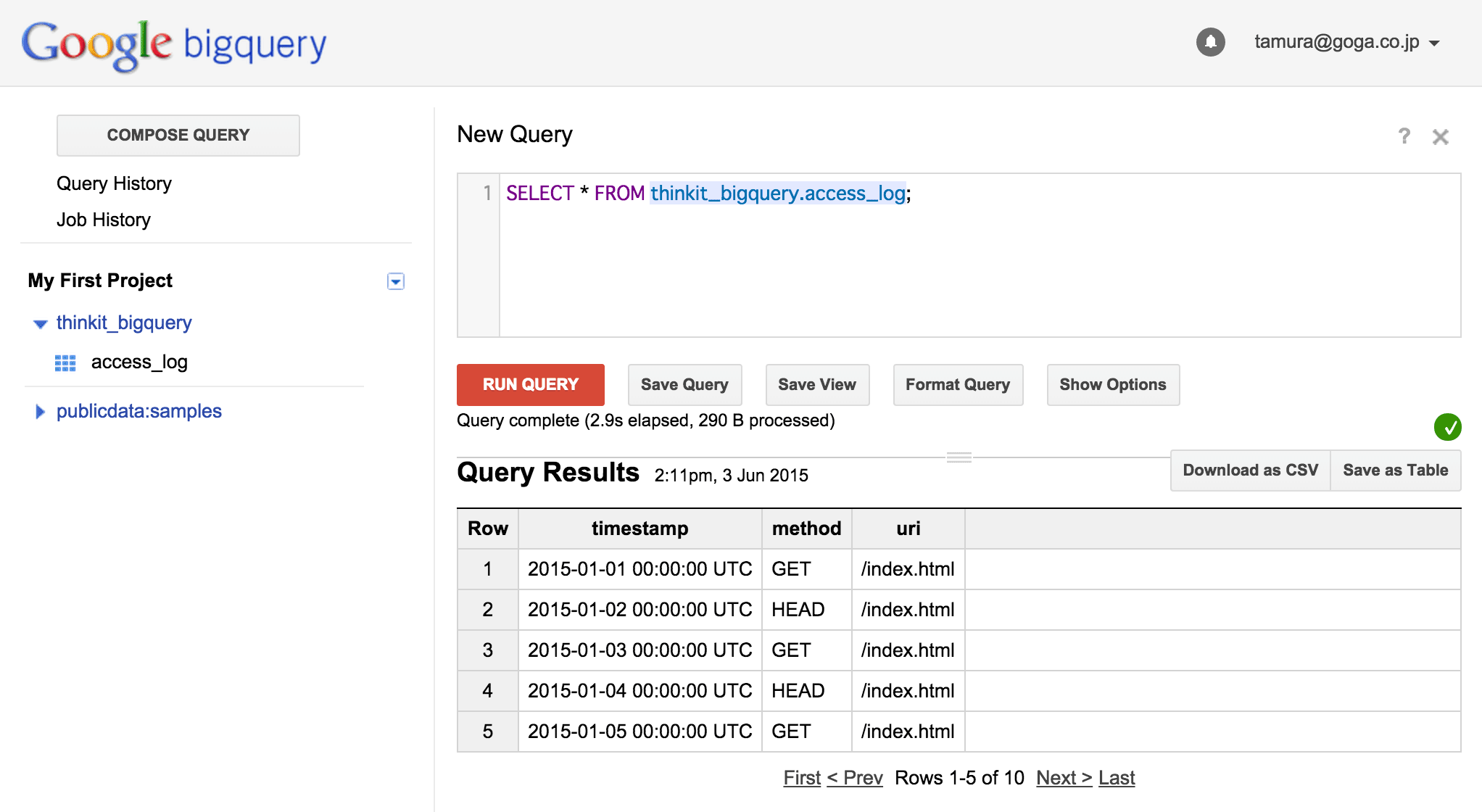
図11:作成したテーブルへのクエリを実行し、正しく作成されていることを確認
Streaming Insertを利用してデータを登録する
Streaming Insertは、データをリアルタイムに投入するための機能です。前述したBulk loadでは、ジョブとしてバッチ処理を登録する形であるため、データ投入を指示してからBigQueryで処理可能になるまでにタイムラグがあります。そのため、たとえば「直近1分間におけるユーザの行動ログを毎分分析する」といった用途には向いていません。
Streaming Insert機能は、Google APIの一部として提供されています。APIを呼び出してデータのアップロードが正常終了すれば、即座にテーブルへ反映されます。APIの呼び出しにはプログラムの作成が必要ですが、Google API Client LibraryとしてJavaやPythonなどの言語に提供されているライブラリを利用することで、記述しやすくなっています。
Bulk loadではデータ送信は無料でしたが、Streaming Insertでは有料となります。また、Bulk loadとは異なる制限もいくつかありますので、ここにまとめておきます。
表2:Streaming Insertの制限および料金
| 1レコードのサイズ | 1MB |
|---|---|
| 1リクエストのサイズ | 10MB |
| 1リクエスト中のレコードの数 | 500 |
| 1秒あたりのレコードの数 | 100,000(テーブルごと) |
| 1秒あたりのサイズ | 100MB(テーブルごと) |
価格については、2015/08/12に200MBごとに$0.01と改訂されました(以前は100,000レコードごとに$0.01)。また1レコードは、下限サイズを1KBとして計算されます。よって、各レコードがすべて1KB以下のケースであれば、20万レコードごとに$0.01となり、改定前とくらべて価格は下がりました。
それでは実際にStreaming Insert機能を使用してみます。認証処理のPython版サンプルコード(https://cloud.google.com/bigquery/bigquery-api-quickstart?hl=ja#authorizing)に、以下のコードをつけ加えます。「projectID」については、適宜変更してください。また、認証処理のためにGoogle Developer ConsoleからクライアントIDを作成し、client_secrets.jsonをダウンロードしておく必要があります。
リスト1:
from datetime import datetime
timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S +09:00')
body = {"rows":[
{"json":{"timestamp":timestamp, "method":"GET", "uri":"/index.html"}}
]}
print body
response = bigquery_service.tabledata().insertAll(
projectId="xxx",
datasetId="thinkit_bigquery",
tableId="access_log",
body=body).execute()
このスクリプトをstreaming_insert.pyとして保存し、実行してみましょう。初回実行時には、認証を行うためブラウザが開きます。
python streaming_insert.py
続いて、たとえば以下のようにwatchコマンドを使用して一定時間ごとにスクリプトを実行します。Web UIからクエリを発行すれば、レコードが追加されていくことを確認できるでしょう。
watch --interval 5 python streaming_insert.py
Table Decoratorを利用してアクセスするデータ量を減らす
Table Decoratorは、データを投入した時刻に応じてアクセスする範囲を指定する機能です。指定方法は2通りあります。ひとつは、ある時点でのスナップショットとしてのテーブルにアクセスする方法です。もうひとつは、ある範囲内で登録されたデータのみにアクセスする方法です。
また時刻の表現も2通りあり、プラスの整数で1970/01/01からの経過ミリ秒数を指定するもの(絶対時刻)と、マイナスの整数でクエリ時点から遡ってのミリ秒数を指定するもの(相対時刻)です。以下の例では、ある範囲内のデータに相対時刻でアクセスしてみます。過去60秒間に登録されたものを抽出するには、以下のクエリを発行します。
SELECT COUNT(*) FROM [thinkit_bigquery.access_log@-60000--1];
ここでは-60000と-1を指定していますので、1ミリ秒前から60秒前という範囲になります。1ミリ秒前でなく0秒、つまり現在時刻からの範囲にするには以下のように省略することが必要になります。
SELECT COUNT(*) FROM [thinkit_bigquery.access_log@-60000-];
指定が相対時刻なので、このクエリを毎分発行することで、毎分のアクセス回数を集計できます。たとえば以下のように、過去10秒間のデータを時刻順に取得するクエリを、前ページのスクリプトを実行しながら何度か発行してみると、得られるデータが変化していくことを確認できます。
SELECT * FROM [thinkit_bigquery.access_log@-10000-] ORDER BY timestamp;
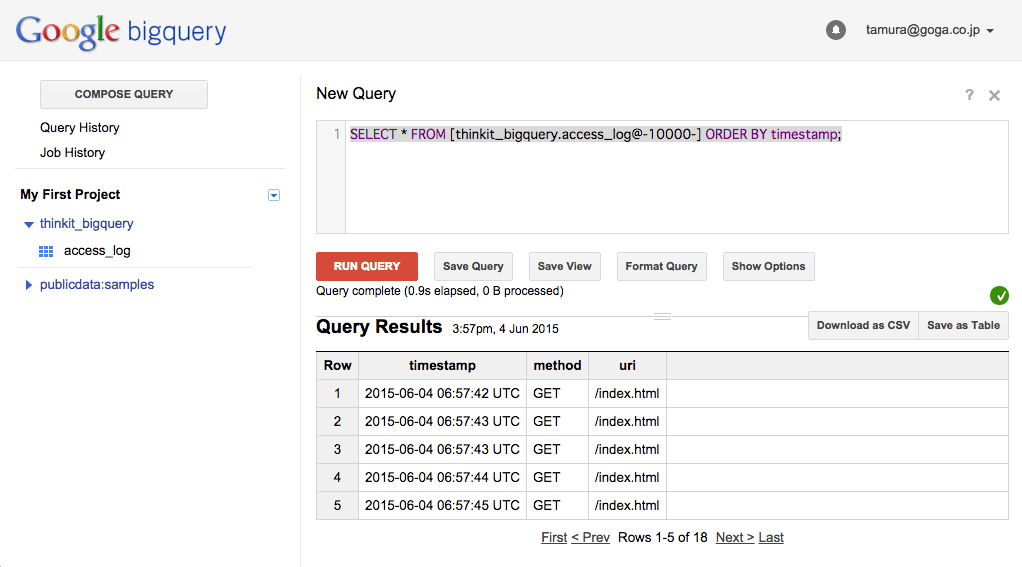
図12:Table Decoratorを用いたクエリの例
このように、Streaming InsertとTable Decoratorを組み合わせると、アクセスログのようなユーザの行動ログというストリームデータを、低コストでリアルタイムに解析できます。
BigQueryとAmazon Redshiftを比較する
クラウドによるビッグデータ解析プラットフォームは、BigQueryだけではありません。Amazon Web Serviceも、同種のサービスとしてAWS Redshiftを提供しています。以下では、これらの比較を行います。まずは料金などについてまとめてみます。
表3:BigQueryとAmazon Redshiftの比較
| AWS Redshift | BigQuery | |
|---|---|---|
| 主な料金 | 計算機リソースに対する従量制 | 解析対象のデータ量に対する従量制 |
| 計算機リソースのセットアップ | Web UI、もしくはAPIを使ってユーザが行なう | 必要なし |
| クエリ発行のインターフェース | ODBCもしくはJDBC対応クライアントで接続 | REST API、コマンドラインツール、Web UI |
AWS Redshiftは、大雑把に言って計算機クラスタをレンタルできるサービスです。料金もEC2インスタンスに対するものと同様に、時間単位での課金となります。また、この計算機クラスタは、ユーザがセットアップする必要があります。データ配置の工夫など、ユーザによるチューニングが行えるメリットはありますが、その半面、手間がかかります。クエリ発行については従来のツールが使えるため、既にそういったツールを用いてデータ解析を行っていた方であれば、移行がしやすいでしょう。
それに対してBigQueryでは、計算機リソースの指定を行いません。本記事で体験したように、データをロードしてクエリを発行すれば、解析が行えます。この手軽さはBigQueryの特徴です。一方でクエリ発行についてはGoogle APIなどを利用するように変更する必要があるため、移行に際してはこのあたりのコストを検討しましょう。
パフォーマンス、特にクエリの実行時間についてはどうでしょうか? BigQueryとAWS Redshiftは料金体系や計算機リソースが大きく異なるため、同条件での比較は困難です。そこで本記事では、計算機リソースを指定しないというBigQueryの性質が実行時間におよぼす影響を確認してみます。
以下のようにpublicdata:samples.wikipediaのデータに対して正規表現でのマッチングを行うクエリにて実行時間を測定しました。同一のクエリだと結果がキャッシュされ実行時間が測れないため、Google、Cloud、Platform、Big、Query、Analyze、Streaming、Insert、Table、Decoratorの10語で計測を行いました。
SELECT title FROM publicdata:samples.wikipedia WHERE REGEXP_MATCH(title, r'Google');
また、アクセスするデータ量を変えるため、結果に含めるカラムを以下のように変えたクエリでも同様に計測を行いました。
SELECT title,comment FROM publicdata:samples.wikipedia WHERE REGEXP_MATCH(title, r'Google');
結果を以下の表に示します。
表4:BigQueryでのクエリ実行時間
| データ量 | 平均(秒) | 範囲(秒) |
|---|---|---|
| 6.79GB(title) | 2.48 | 1.4〜4.1 |
| 18GB(title,comment) | 3.54 | 2.1〜6.5 |
アクセスするデータ量が2.6倍程度になった場合でも、実行時間の平均は1.4倍程度の増加になっています。これは、BigQueryではクエリを実行するための準備にかかる時間があるため、データ量によらず一定の時間が必要なことが原因です。実際、前述した本記事で用意したデータ(290B)に対するクエリも2.9秒かかっていました。
また、固定の計算機リソースではないため、実行時間にも幅があります。今回実験した中でも6.79GBより18.0GBに対するクエリのほうが短くなるケースがありました。さらに、より極端なケースとして、クエリが失敗することも考えられます。
まとめ
BigQueryは、Googleの提供するビッグデータ解析プラットフォームで、以下のようなメリット・デメリットがあります。
メリット
- 計算機リソースを指定する必要がない
- ストリームデータを扱うための機能がある
デメリット
- 計算機リソースに対するチューニングはできない
- 計算機リソースを確保できないことによる不安定さがある
計算機リソースのセットアップなしで手軽に解析できることや、あるいはストリームデータをリアルタイムに解析できることが、BigQueryの大きな特徴だと思います。本記事がBigQueryの理解を助け、適切なビッグデータ解析プラットフォームを選ぶ際の参考になれば幸いです。
- この記事のキーワード
関連記事
SAPジャパン、SAP HANAプラットフォームの最新版「SPS11」を発表
2015年12月11日 0:12
MySQL Clusterの主要な設定、設定変更時の注意点
2015年8月17日 22:00
「Oracle Linux 6.9」リリース
2017年4月2日 0:35
「Oracle Linux 7.3」リリース
2016年11月17日 0:50
SAPジャパン、SAP HANAプラットフォームの最新版「SAP HANA, express edition」を発表
2016年10月2日 1:18
MySQL 5.6での機能強化点(その2) - NoSQL APIとパフォーマンス・スキーマ
2014年1月8日 20:00
バックナンバー
この記事の筆者

Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
