Dockerは、多くのITエンジニアに注目され、継続して成長している技術である。DockerはlibcontainerというLinuxカーネルのAPIを呼び出すためのドライバーと、OSごとに対応したファイルシステム(aufs、device-mapper等)によって、コンテナという仮想環境を構築する。詳細は、以前の連載「Dockerを知る -周辺ツールと業界動向-」にて解説されている。Dockerが注目を集める理由は、このコンテナという仮想環境が、従来のハイパーバイザ型の仮想環境と比べて軽量でオーバヘッドが少ないことや、実行環境を素早く提供できるという点にある。また最近では、Dockerを管理するための周辺技術も注目されており、代表的なものとしてGoogleがOSSとして公開しているKubernetesやDocker社公式のDocker Swarmなどが挙げられる。さらに、近年話題となっているクラウド基盤ソフトウェアのOpenStackにも、Magnumという機能が追加された。MagnumはOpenStack Containers Teamによって開発されたもので、Dockerコンテナを扱うための機能である。Magnumを使うことによって、コンテナクラスタのデプロイおよび制御を、OpenStack上で行えるようになる。
そこで本記事では、実際にOpenStack Magnumの環境構築およびコンテナの制御を行ってみる。
OpenStack Magnumの仕組み
図1に、OpenStack Magnum公式の構成図を示す。
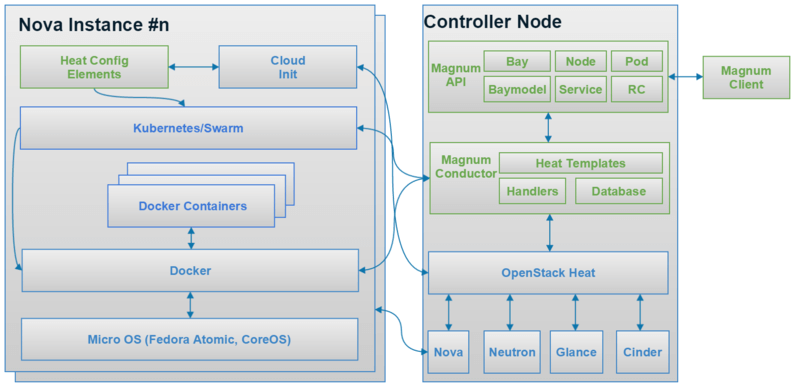
図1:OpenStack Magnumの構成図(出典:https://wiki.openstack.org/wiki/Magnum)
Magnumは、既存のAPIであるNova、Neutron、Glance、Cinderなどよりも上位のレイヤーに存在する。Magnum APIのBayは、OpenStackのオーケストレーション機能であるHeatによりNovaやNeutron、Glance、Cinderを操作して、コンテナをクラスタリングするための環境を構築し提供する機能などを備える。環境が提供された後はMagnum APIのNode、Pod、Service、RC等を使ってコンテナを制御できる。また、Magnumによるコンテナのオーケストレーション処理は、既存のオーケストレーションツールであるKubernetesやDocker Swarmを、OpenStackに取り込むことで実現している。
環境構築
今回はDevStackを使用して、OpenStack MagnumをUbuntu 14.04上に構築する。
まずは、構築に必要となるパッケージをインストールする。
$ sudo apt-get update
$ sudo apt-get install -y python-dev libssl-dev libxml2-dev \
libmysqlclient-dev libxslt-dev libpq-dev git \
libffi-dev gettext build-essential
次に、OpenStackを構築するためのツールであるDevStackを取得する。DevStackは開発者向けのOpenStack導入ツールであり、今後OpenStackのコンポーネントに対して更新があった場合は、今回の手順通りに動作しない可能性がある。ただし、後述のlocal.confでバージョンは指定できる。
$ sudo mkdir -p /opt/stack
$ sudo chown $USER /opt/stack
$ git clone https://git.openstack.org/openstack-dev/devstack /opt/stack/devstack
DevStackは、local.confというファイルにOpenStack構築時の設定を記述する。<password>となっている部分には、任意のパスワード設定をしている。
$ cat > /opt/stack/devstack/local.conf << END
[[local|localrc]]
DATABASE_PASSWORD=<password>
RABBIT_PASSWORD=<password>
SERVICE_TOKEN=<password>
SERVICE_PASSWORD=<password>
ADMIN_PASSWORD=<password>
# nicに応じて変更
PUBLIC_INTERFACE=eth1
# Magnumのリポジトリ
enable_plugin magnum https://git.openstack.org/openstack/magnum
VOLUME_BACKING_FILE_SIZE=20G
END
DevStackを実行する。環境によって異なるが、今回の環境では30分程度で構築が完了した。
$ cd /opt/stack/devstack
$ ./stack.sh
認証のための変数を読み込む。引数にユーザ名およびテナント名を指定するが、今回は両方ともadminとする。
$ source /opt/stack/devstack/openrc admin admin
OpenStackの構築および認証が問題なく行えていることを確認するためにサンプルの仮想マシンイメージを表示させる。
$ glance image-list
+--------------------------------------+---------------------------------+-------------+------------------+-----------+--------+
| ID | Name | Disk Format | Container Format | Size | Status |
+--------------------------------------+---------------------------------+-------------+------------------+-----------+--------+
| 7f5b6a15-f2fd-4552-aec5-952c6f6d4bc7 | cirros-0.3.4-x86_64-uec | ami | ami | 25165824 | active |
| bd3c0f92-669a-4390-a97d-b3e0a2043362 | cirros-0.3.4-x86_64-uec-kernel | aki | aki | 4979632 | active |
| 843ce0f7-ae51-4db3-8e74-bcb860d06c55 | cirros-0.3.4-x86_64-uec-ramdisk | ari | ari | 3740163 | active |
| 02c312e3-2d30-43fd-ab2d-1d25622c0eaa | fedora-21-atomic-5 | qcow2 | bare | 770179072 | active |
+--------------------------------------+---------------------------------+-------------+------------------+-----------+--------+
このようにイメージが表示されていれば問題はない。
Bayの作成
ここから実際にMagnumを使用していく。BaymodelおよびBayのイメージ図を以下に示す。
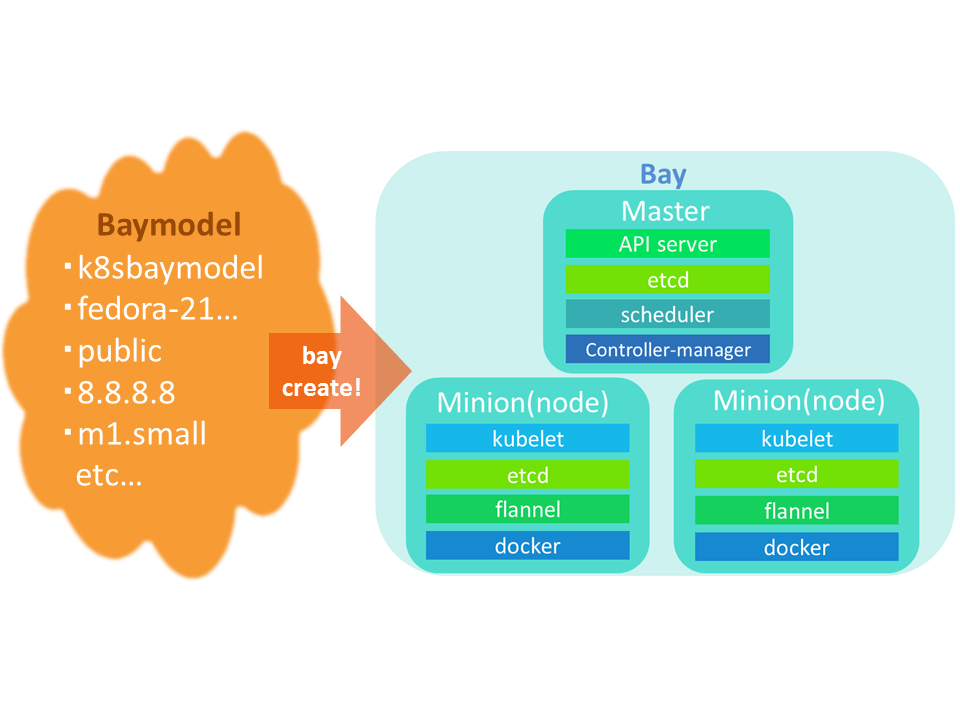
図2:Baymodel、Bayの構成イメージ
図2に記載されているBayという枠は、Magnumで構築するクラスタの単位であり、Baymodelという「ひな形」をもとに作成される。Baymodelには構築するノードのOSやネットワーク、使用するクラウドオーケストレーションエンジンなどを指定する。Bayを作成すると、Baymodelをもとにインスタンス、ネットワーク、オーケストレーションエンジンを動かすための環境などを自動的に設定、構築してくれる。Bayという単位で管理することによって、クラスタごとの削除、ノード数の変更を容易に行うことができる。今回はKubernetesのエンジンを使用するため、作成されるインスタンスは、コンテナを配置する場所であるMinionとAPIを実行してMinionに対してコンテナの制御などをさせるMasterである。
まず、Baymodelで使用する鍵を作成する。
$ test -f ~/.ssh/id_rsa.pub || ssh-keygen -t rsa -N "" -f ~/.ssh/id_rsa
次に、novaに鍵を登録する。
$ nova keypair-add --pub-key ~/.ssh/id_rsa.pub testkey
鍵の登録が完了したら、Baymodelを作成する。
$ magnum baymodel-create --name k8sbaymodel \
--image-id fedora-21-atomic-5 \
--keypair-id testkey \
--external-network-id public \
--dns-nameserver 8.8.8.8 \
--flavor-id m1.small \
--docker-volume-size 5 \
--network-driver flannel \
--coe kubernetes
baymodel-createコマンドで使用したオプションの一覧を、以下の表にまとめた。
| オプション名 | 説明 |
|---|---|
| name | Baymodelの名前を指定する |
| image-id | 作成するノードのマシンイメージを指定する。今回はデフォルトで入っているFedoraのイメージを使用する |
| keypair-id | ノードの認証に使用する鍵を指定する。今回はひとつ前の手順で作成したtestkeyを使用する |
| external-network-id | 外部ネットワークを指定する。今回はデフォルトで入っているpublicを使用する |
| dns-namesever | DNSサーバを指定する |
| flavor-id | 作成するノードの構成を指定する。今回はデフォルトで入っているm1.smallを使用する |
| docker-volume-size | Dockerで使用するボリュームサイズを指定する |
| network-driver | コンテナ間で通信するためのネットワークドライバーを指定する |
| coe | coeはCloud Orchestration Engineの略で、使用するエンジンを指定する。今回はkubernetesを使用する(他に指定できるのは、現時点ではswarmとmesos) |
このBaymodelをもとに、Bayを作成する。今回使用した環境では、15分程度でBayの作成が完了した。
$ magnum bay-create --name k8sbay --baymodel k8sbaymodel --node-count 1
bay-createコマンドで使用したオプションの一覧を、以下の表にまとめた。
| オプション名 | 説明 |
|---|---|
| name | Bayの名前を指定する |
| baymodel | Bayの作成時に使用するBaymodelを指定する。今回は作成したk8sbaymodelを使用する |
| node | 作成するノード数を指定 |
watchコマンドで5秒ごとにコマンドを実行し、statusがCREATE_COMPLETEに変わったことを確認する。
$ watch -n 5 magnum bay-list k8sbay
+--------------------------------------+---------+------------+-----------------+
| uuid | name | node_count | status |
+--------------------------------------+---------+------------+-----------------+
| 9dccb1e6-02dc-4e2b-b897-10656c5339ce | k8sbay | 1 | CREATE_COMPLETE |
+--------------------------------------+---------+------------+-----------------+
次にノード数を増やしておく。node_countオプションで、ノードの数を指定する。
$ magnum bay-update k8sbay replace node_count=2
statusがUPDATE_PROGRESSからUPDATE_COMPLETEになり、node_countが2になっていることを確認する。
$ magnum bay-list k8sbay
+--------------------------------------+---------+------------+-----------------+
| uuid | name | node_count | status |
+--------------------------------------+---------+------------+-----------------+
| 9dccb1e6-02dc-4e2b-b897-10656c5339ce | k8sbay | 2 | UPDATE_COMPLETE |
+--------------------------------------+---------+------------+-----------------+
- この記事のキーワード
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
