IIJ社における分散DB技術「ddd」(1)
P2P方式によるノード一覧管理
コンシステントハッシュ法では、あらかじめノードの一覧表があれば担当ノードを高速に割り出せると述べました。一覧表とは、具体的には、存在している全ノードのIDと、通信するためのIPアドレス/ポート番号の対応表です。dddでは、その一覧表の情報をP2P方式でやり取りしています。
P2Pとは、ネットワーク上の多数のコンピューターノードが対等な関係で通信しあうというものです。各ノードは、中央管理ホストを持たないpure P2Pのネットワークを構成します。
新規にノードを追加する場合は、既存のどれか1つのノードに接続して起動します。新規ノードは、その既存ノードからほかのノードの情報(IPアドレスなど)を得ます。同時に、新規ノードの情報はほかの既存ノードに伝達されて広がっていきます。
dddは、起動している間ずっとほかのノードと情報を数秒おきに交換しあっています。各ノードの情報を直接・間接的に、すべてのノードの間でやり取りし、それぞれのノードが自分を含めた全ノードの一覧表を持ちます。
この方式の利点は、どのノードにおいても、キーの担当ノードを割り出すためにほかのノードに問い合わせる必要がなく、高速な処理が可能となることです。逆に、欠点は、ノード数が増えると一覧のやり取りだけでかなりの負荷になる恐れがあることですが、今のところdddではまだ問題になっていません。
データの自動的な冗長化
dddでは、冗長化のためにすべてのデータは必ず異なる3つのノードに複製されるようになっています。同時に3つのノードが壊れない限り、どこかにデータは残っているので、データ保全の信頼性は高いと言るでしょう。
前述の通り、コンシステントハッシュ法で、キーのハッシュ値から反時計回りに最初にあたったノードに値を格納するわけですが、さらに2番目と3番目のノードにも同じデータをコピーします。
ただし、バーチャルノードによって、2番目、3番目のノードが、実体としては1番目と同じノードというようなこともあり得るため、実際には実体が異なる3つのノードを選びます。
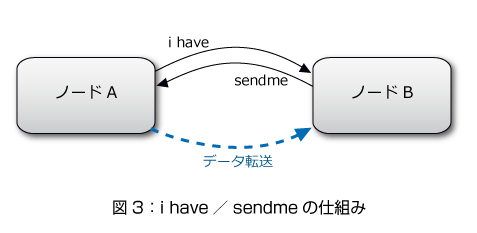
データの複製は、ddd独自のi have/sendmeと呼んでいる仕組みで行われます。ちなみに、i have/sendmeという名前は、NetNewsにある同名の制御メッセージに由来しています。
まず、各ノードは自分の持っているキーをリストアップします。キーの値から、コンシステントハッシュ法により、そのキーを担当しているべきノードを割り出せるので、そのノードに向かって、キーのリストを送ります。これを、i haveメッセージと言います。
i haveメッセージを受け取った側は、リストに含まれているキーと自分の持っているキーを比べて、もし持っていないキーがあればそのデータの送信要求を返します。これをsendmeメッセージと言います。sendmeを受け取ったノードは、要求元にデータを送信します。
実際には、キーの数は大量であり、一度にすべてのキー情報を交換するのではなく、少しずつ分割してやり取りします。
ノードの数が増減した場合は、その影響を受ける範囲のキーのみがコンシステントハッシュ法で割り出されるi have送信先が変化します。例えば、2Pの図2で、ノードBがなくなった場合、薄い緑色で示される範囲のキーの担当は「ノードB、A、D」から「ノードA、D、C」に変化し、新たに担当になったCにA、Dのいずれかからデータが転送されることになります。
dddは、i have/sendmeのやり取りを何度も延々と繰り返しており、結果として若干のリードタイムで複製数を3に保っています。
dddではノードのハードウエアコストを低く抑えるために、RAIDなどのディスク冗長化技術は採用していません。そのかわり、より上位のレベルでデータを冗長化して、いつノードが故障して脱退しても全体として問題なく稼働する構成となっています。
■冗長化により引き起こされる不整合
一方で、分散ストレージでは、同じデータを複数ノードで分散保持するために、データの一貫性を保つことが常にできるとは限りません。複数ノードにまたがって、すべて同時にデータを更新することは困難であり、タイミングによってノード間で持っているデータが食い違うことがあり得ます。
多数のノードで構成される分散システムでは、一部のノードが故障したり、ネットワーク的に分断される可能性があり、システムの可用性とデータの一貫性はトレードオフの関係になります。
多くの場合、データの食い違いが発生するタイミングはごく短く、時間経過により一貫性が保たれるような機構にすることにより、不整合を許容して可用性を高めることを優先しますが、アプリケーション側で不整合に対処することも必要です。
IIJでは、前述のフロー情報や、各種サーバーのログなどをdddの分散ストレージに格納しています。フロー情報もログ情報も、一度書き込んだ情報は不変であり、更新する必要がないため、幸いなことに上記の一貫性が保証されない特性は、ほとんど問題になりません。
ただし、ノードの増減に伴うデータの複製が発生している瞬間は、あるはずのノードにデータがないということが起こりえます。その場合、dddを使うアプリケーション側で、2番目・3番目の候補のノードにリトライしてデータを取得するようにしています。
IIJで開発したdddという分散システムのストレージ部分について説明しましたが、いかがでしたでしょうか。
次回は、蓄積した大量のデータを検索/処理するための仕組みであるMapReduceについて説明します。
【参考文献】
[1]「Consistent Hashing and Random Trees:Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web (1997)」(http://portal.acm.org/citation.cfm?id=258660 )(アクセス:2009.09)
[2]「Consistent Hashing -- Tom White's Blog」(http://www.lexemetech.com/2007/11/consistent-hashing.html)(アクセス:2009.09)






