Google File System(GFS)
Google File System(GFS)
Googleが最初に作り上げたシステムは、巨大な分散ファイルシステムでした。
彼らは世界中のページをクロールしてそのデータをすべて取得し、それに検索が容易になるようにインデックスを付けることを計画しました。
世界中のWebのページを格納するには巨大な容量のファイルシステムが必要となりますが、彼らはそれを自分たちで、Scale-outする分散ファイルシステムGoogle File System(GFS)として作り上げたのです。
一つのPCに2Gのメモリーと500Gのディスクが付いていたとしましょう。この容量は決して大きなものではありませんが、こうしたPCが2000台あったとすれば、それだけで全体の容量はメモリーで4T(テラ)、ディスクの容量は1P(ペタ)にもなります。
重要なことは、こうした分散環境を協調動作させるメカニズムさえ作れば、ノードのPCをどんどん追加して、いくらでもシステムのメモリー・ディスクの容量を拡大することができるようになることです。
こうしてGoogleは、WebスケールのWebページの情報をそっくり格納することのできるファイルシステムを作り上げました。
このように、目的に応じて、その目的を実現するために、ハードとソフトを組み合わせてシステムを設計することを「Co-Design」と呼びます。
こうした問題解決の手法も、Googleの技術の大きな特徴になります。例えば、私たちはエンタープライズのIT技術で、そうしたやり方をとりません。たいてい行うことは、汎用のサーバーに汎用のミドルウエアを載せて、汎用のデータベースを利用することです。
確かに、こうしたやり方でも問題は解決できます。しかし、サーバーにしてもミドルウエアにしても、データベースにしても、私たちはその全機能を使っているわけではありません。そこには無駄があります。
GoogleのCo-Designのアプローチは、システムの目的に合わせて、必要な機能をハードとソフトを同時にスクラッチから設計して新しいシステムを構成するものです。
Webスケールのデータ処理とMapReduce
Webスケールのデータの処理は、とても手間がかかります。あるページがどれくらいアクセスされているかは、ログを解析すれば分かります。基本的には、ログの中に、あるページのURLが何回現れるかをカウントすればいいのですが、ログファイルはWebスケールのとても巨大なものです。
また、あるページが、どこのページからリンクするかを数えるという問題もあります。
この処理をするには、Webスケールのページのデータを自分自身と突き合わせる必要があります。処理のスケールは、「Webスケール×Webスケール」のさらに巨大なものになります。
こうした問題は、Googleがクロールして集めた情報を検索して、その結果をどのように表示するかという問題と関係しています。
たくさんアクセスされるページや、たくさんリンクされているページは、皆の関心の高いページだと考えることができます。そうしたページを検索結果の上位に表示することは、検索利用者にとって便利なサービスになります。
それだけではなく、このページのランク付の問題は、Googleが展開しようとしていた、検索と広告を結び付けるというビジネスの課金体系の心臓部分を構成しています。
Googleが、この問題で取り組んだことも非常に野心的なことでした。Webスケールのデータ処理の専用のシステムをスクラッチから作り上げたのです。それが「MapReduce」です。
MapReduceは、Googleの分散処理を支える基本的なアルゴリズムであると同時に、基幹をなす分散処理システムの実装系の別名でもあります。
MapReduceのプログラミングスタイルにしたがって、MapとReduceの2種類のコードを書けば、MapReduceのシステムライブラリの助けを借りて、数千台のマシンが協調動作する分散処理のプログラムを作成することができるのです。
その上、MapReduceのコードを生成する「Sawzall」というDSLを作り上げて、初心者でも数十行のSawzallのスクリプトを書けば、数千台のマシンを操って巨大なデータ処理ができるようなシステムを作り上げます。
残念ながら、SawzallにはMapReduceのHadoopようなオープンソース版が存在しません。今のところ、Sawzallの便利さを知るにはGoogleに入るしかありません。
■MapReduceのアルゴリズム
MapReduceのアルゴリズムは、一見すると単純で、その成り立ちから考えても、その応用範囲は限定されているように見えます。
しかし、近年、MapReduceはGoogle内部にとどまらず、いろんな分野への応用が広がっています。筆者は、このMapReduceの単純さこそ、分散処理可能性の基本的なエッセンスを表現していると考えています。
簡単にそのアルゴリズムを紹介してみましょう。
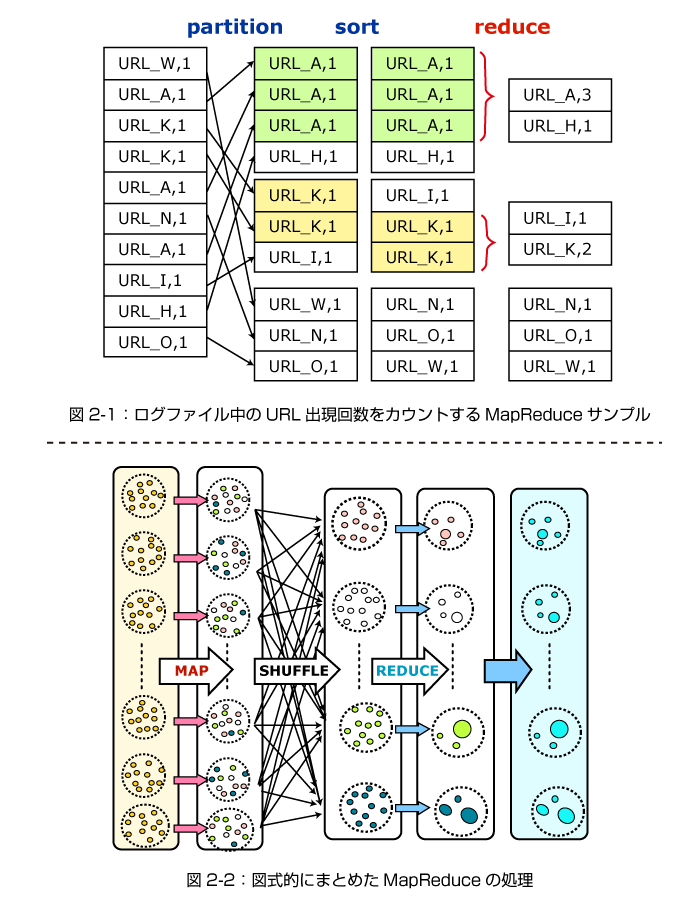
図2-1は、先に挙げたログファイル中のURLの出現回数をカウントするMapReduceのサンプルです。
Mapは一般に
まず、Map関数はデータ中にURLを見つけると
続いて、このMapの出力はKeyごとに(この例では同じURLごとに)グループ分けされます。グループ分けは「Shuffling」と呼ばれ、一般にはKeyによるsortが用いられます。
Reduceは、同じキー(URL)の1を足し合わせていきます。こうして、元のデータ中のURLの個数がカウントアップされることになります。
一般に、ReduceはMapの出力を受けてMapと同様に<Key,Value>形式の出力を持つのですが、Reduceは同じkeyのグループに働きかけて、その出力は、Mapと異なり、同じkeyのグループにとどまることに注意してください。
図2-2は、MapReduceの処理を図式的にまとめたものです。
以下の点に留意してください。
1.MapとReduceは、同一ノード内で処理が終わる、同じタイプの処理です。
2.Mapによって出力のKey領域はさまざまに変更されますが、Reduceの出力は、入力と同じkey領域にとどまります。
3.MapReduceのアルゴリズムの中で、Shufflingは重要です。実際の処理時間でも、Shufflingによって各ノード間を一斉にデータが移動する、この過程がもっとも大きな部分を占めます。
4.MapReduceの出力は(直接的にはReduceの出力は)、再びMapの入力になりえます。
Googleは、こうして、リアルタイムの処理が難しい、Webスケールの複数の巨大なデータ同士を突き合わせる処理についても、まったく新しい処理のスタイルを確立したのです。
MapReduceというアルゴリズムとその処理系であるMapReduceは、Googleの大量データ処理の心臓部分として分散処理のアルゴリズムに大きな影響を与えました。
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
