データ統合/ETLを使う
Pentahoデータ統合/ETLとは第1回では、オープンソースBI「Pentaho」の全体像、Pentaho BIスイートの特徴や入手方法、BIサーバーのインストール手順を解説しました。第2回の今回は、個々の情報システムのデータを分析できるようにするミドルウエア「Pentahoデータ統合/ETL」
2010年3月12日 20:00
Pentahoデータ統合/ETLとは
第1回では、オープンソースBI「Pentaho」の全体像、Pentaho BIスイートの特徴や入手方法、BIサーバーのインストール手順を解説しました。第2回の今回は、個々の情報システムのデータを分析できるようにするミドルウエア「Pentahoデータ統合/ETL」を解説します。
データ・ウエアハウス(DWH)を構築してデータを分析するためには、業務システムのデータをデータベースに収納する必要があります。このために利用するのがETLツールです。ETLのEはExtract(データの抽出)、TはTransform(データの変換)、LはLoading(データの格納)のことで、DWHが必要とするデータをさまざまなデータ・ソースから抽出し、利用しやすいように適切な形式に変換して対象のデータベースに格納します。
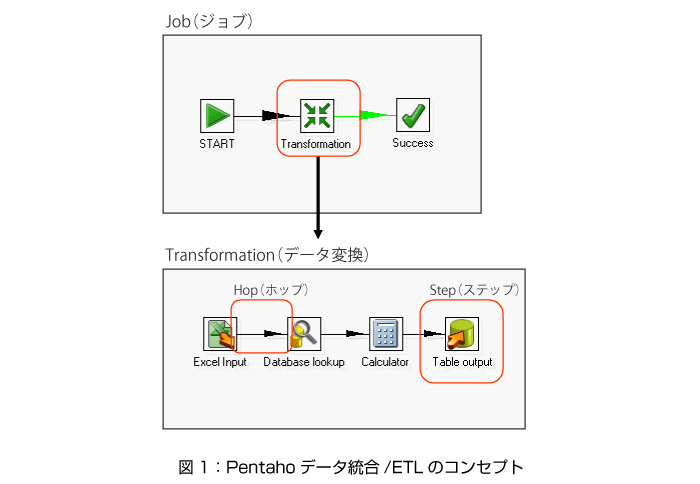
Pentahoデータ統合/ETLは、Transformation(データ変換)、Job(ジョブ)という2つの基本コンセプトがあります。Transformationとは、複数のソースからデータを入力し、変換処理を実行して複数の出力にデータを格納するタスクです。一方、Jobとは、1つもしくは複数のTransformationやほかのJobを順に実行するタスクです。通常、Jobはスケジューリングし、定期的に実行します。
Pentahoデータ統合/ETLは、以下のコンポーネントで構成します。
(1)Spoon(スプーン)
TransformationとJobを設計するGUI(グラフィカル・ユーザー・インタフェース)やエディタを搭載する、デスクトップ・アプリケーションです。ソース・コードを書くことなく、複雑なETL処理を作成できます。
(2)Pan(パン)
Transformationを実行するための、スタンドアロンで動作するコマンド・ライン・プロセスです。“Transformationエンジン”であり、さまざまなデータソースからデータを読み、さまざまなデータソースに書き込みます。
(3)Kitchen(キッチン)
Transformationを実行するための、スタンドアロンで動作するコマンド・ライン・プロセスです。Spoonを用いて設計したJobの、XMLファイルやデータベース・リポジトリを実行するプログラムです。
(4)Carte(カルテ)
ETLサーバーのコンポーネントです。HTTPリスナー(Webサーバー)として動作し、リモート(サーバー側)でTransformationやJobを実行します。
Pentahoデータ統合/ETLの特徴と機能
Pentahoデータ統合/ETLの特徴と機能は、以下の通りです。
- 設計したETL処理は、ファイルとして保存できるほか、共同開発用のリポジトリ・データベースに格納して管理できる。
- 入力・出力、変換を含む100以上のコンポーネント部品を組み立てるだけで、簡単にTransformationやJobを作成できる。
- データベース接続処理をGUIで簡単に作成でき、Transformationで複数のDB接続を定義できる。
- データベース・スキーマをGUIで簡単に定義できる。
- ステップをホップで接続してデータの流れを定義する。また、データを複数のステップにコピー、分配できる。
- ファイル・サイズに制限はない(ただし、システム・メモリの制限を受ける)。
- 「どのようにしたいか」ではなく、「何をしたいか」を設定するだけでよい。
- 余分なコードを生成しないため、メンテナンスが容易。
- セットアップが単純で、プラグインで機能を拡張できる。
- Javaで実装されているため、クロス・プラットフォーム環境で動作する。
- クラスタリング構成により、ほぼ無制限のスケーラビリティ(拡張性)を備える。
- Carteを用いてTransformationやJobをリモートで実行できる。
- エンタープライズ・エディション(EE)では、エンタープライズ・コンソールを用いてWebブラウザで実行状況をモニタリングできる。
次ページからは、Pentahoデータ統合/ETLの使い方を解説します。
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
