バズワードではないDX、3大クラウドベンダーのビッグデータ分析サービス
2020年10月9日 6:30
はじめに
デジタルトランスフォーメーション(DX:Digital Transformation)の盛り上がりや、クラウドベンダーが提供するサービスの進化によって、データ活用分野のサービスが注目を集めている。
これまでのデータ活用では、さまざまなデータをETL(Extract=抽出、Transform=変換、Load=ロード)で集め、データウェアハウスやデータマートを構築して分析することが一般的だった。しかし、IoTやモバイルデバイスの浸透により、ストリームデータをリアルタイムもしくはニア・リアルタイムで探索するニーズが増えている。
また、ユーザーエクスペリエンスがビジネスを左右するWebサイトやSaaSアプリケーションでは、利用状況を常に監視し、改善し続ける必要がある。そのためにはログ分析基盤の整備は当然として、使いやすく生産性の高いプラットフォームが欠かせない。
これらの処理は従来の基盤では苦手とする分野だったが、近年各ベンダーからさまざまなソリューションが登場している。ただし、さまざまなソリューションが登場した結果、同一ベンダー内でも似たソリューションが存在することになり、専門家でもわかりづらい状況になっている。
そこで本連載では、データ活用分野全体を俯瞰するとともに、知っておくべき基本知識を解説する。そしてIoTやログなどのストリーム処理が得意なAzure Data Explorerについて説明するとともに、この分野で先行する2社のサービス(Google BigQuery、Amazon Athena)との比較も行う。
なお、本連載では読者対象として次のような方々を想定している。
- DXに興味があるかた
- データレイクについて知りたいかた
- ストリームデータ分析について知りたいかた
- データ活用分野のクラウドサービスを知りたいかた
- Azure Data ExplorerやGoogle BigQuery、Amazon Athenaに興味があるかた
ビッグデータ分析を取り巻く世界
本題へ入る前に、われわれを取り巻くデータ活用の世界やトレンドについて説明する。
データ活用のトレンド
ビッグデータやデータサイエンスなどのキーワードが登場して10年以上が経過している。当初はHadoopなどの基盤が注目されていたが、その後のコンピューティング・テクノロジーの進化によって、さまざまなサービスが登場し、限られた一部の人たちが使うものから、より多くの人たちで使うものへと変化している。
特に近年はDXの盛り上がりから、データ活用分野での進化・多様化がめざましい。3大クラウドベンダーを筆頭に、多くのベンダーは競争に勝つべく、さまざまなサービスをリリースしている。
ひと言でデータ活用といっても範囲が広い。「データウェアハウス」や「データマート」「ビジネスインテリジェンスツール」のように昔から存在し認知度の高いものもあれば、IoTやAIのように用語は分かっていても具体的に説明しづらいものもある。また近年よく取り上げられる「データレイク」についても、共通認識があるとまでは言えないだろう。
今回取り上げるのはIoTデバイスやWebアプリケーション、オンラインゲームなどから大量に生成されるリアルタイムログの扱いだ。
従来はバッチで処理することが多かったが、近年はこれらの大量ストリームデータに対して、さまざまなクエリーを、リアルタイムに近い、オンザフライで探索したいというニーズが増えている。リアルタイムに近ければ、データが発生した直後に、異常、および傾向を迅速に特定するといった新しい活用方法も可能になる。
改めてDXを考える
近年、さまざまなメディアでDXという言葉が当たり前のように使われている。バズワードと考えている人もいるだろうが、現実には多くの企業が推進し、実績を上げている。特に2010年以降のテクノロジー革新は激しく、「ビッグデータ」「クラウド」「IoT」「AI」などは完全に実用段階に入り、一般化したテクノロジーとして利用されることも多い。
経済産業省が2018年に「DX推進ガイドライン」を公表してからは、多くの経営者層に知られるようになり、露出機会が増加している。DXの定義が漠然としていることもあり、バズワードと考えられがちだが、少なくとも欧米企業の取り組みは真剣である。
現在のDXをよく表しているのは、以下に紹介する「経済産業省のDX推進ガイドラインの定義」だろう。
経済産業省のDX推進ガイドラインの定義
「企業がビジネス環境の激しい変化に対応し、データとデジタル技術を活用して、顧客や社会のニーズを基に、製品やサービス、ビジネスモデルを変革するとともに、業務そのものや、組織、プロセス、企業文化・風土を変革し、競争上の優位性を確立すること」
ガイドラインでは、重要な二本柱として次のことを取り上げている。最も重要なのは経営者としての戦略やビジョンであり、次に重要なのは実現する道具としてのITである。
- DX推進のための経営のあり方、仕組み
- DXを推進する上で基盤となるITシステムの構築
本連載の目的からは外れるのでここでは触れないが、DX実現のためには、経営層の強力なコミットが必要であることを忘れてはならない。
DXと言われても、まだピンと来ないかもしれないが、ショッピングサイトのリコメンドエンジンやGoogle AnalyticsのようなWeb解析は多くの人々が知るテクノロジーだ。
また、インターネット上の広告配信技術アドテクノロジーは、ビックデータやリアルタイムデータを活用し、きわめて高度に進化している。Web広告のバックエンドでは、Web閲覧者や広告主、広告媒体、それぞれの最適化のため、短時間に膨大なやりとりがなされている。
IT企業以外でも、製造業を中心にGEやボッシュ、シーメンスなどの先駆者だけでなく、多くの企業がIoTに取り組み成果を上げている。さらに流通系でも物流効率化や顧客ニーズの把握のため果敢にDXにチャレンジしている。これらの事実は、IoTやビッグデータ、AIなどのDXに取り組むことが競争優位性の確保に重要であることに他ならない。
日本語版ウィキペディアでデジタルトランスフォーメーションを調べると、
「ITの浸透が、人々の生活をあらゆる面でより良い方向に変化させる」
という、スウェーデンのウメオ大学のエリック・ストルターマン教授が提唱したとされる定義が紹介されている。そして、この定義を引用しているメディアも多い。
しかし、英語版ウィキペディアは、まったく異なる内容で、次のように書かれている。
「デジタルトランスフォーメーションとは、「新しく」「速い」「頻繁に変化する」デジタル技術を問題解決に利用することだ(Digital Transformation is the use of new, fast and frequently changing digital technology to solve problems.)」
この説明で始まり、2進法やトランジスタなどの歴史、そして「今後の可能性や課題」として分野ごとの可能性について言及している。つまり、これまで人類が経験してきたテクノロジー革新の一つという位置づけだ。エリック氏の名前はまったく登場しない。
ためしに、米国の検索エンジンで「Erik Stolterman Digital Transformation」を検索すると、日本企業の英語サイトが多くヒットする。なぜ、日本だけこのような状態になったのか謎である。
各クラウドベンダーのDXへの取り組み
DXの特性がクラウドの特徴である「初期コスト削減(CAPEX(Capital Expenditure:資本的支出)からOPEX(Operating Expense:運用費)へ)」「スピーディーな導入」「必要な分だけ利用できる柔軟性」にマッチしていることから、各クラウドベンダーはデータ活用分野の開発に力を入れている。
デジタル技術には多くの分野がある。そのなかでもホットな分野が「集める」「ためる」「分析する」といった機能を提供するサービス群だ。データウェアハウスやデータレイク、ETLツール、BIツール、AIなど、さまざまなサービスが提供されている。
これらのデータ活用基盤では、最低でも「集める」「ためる」「分析する」という3つのアクションが必要だ。下図は、その全体像を表したものである。

クラウドベンダーの各サービスを調べたことがある方ならわかると思うが、それぞれのサービスを把握するのは簡単ではない。もともとビッグデータ系のエコシステムは数が多くて複雑だった。さらに、OSSのソフトウェア開発方式を解説したエリック・レイモンドの名著「伽藍とバザール」ではないが、中央集権的な開発ではなく、それぞれがスピードと利便性を追求した開発を行っているため、多種多様なサービスが存在するのだ。
従来ならばRDBMSやAPサーバーの比較のような、ある程度同一軸での評価が可能だった。しかし現在は、同じジャンルの製品・サービスでも、それぞれに味付けがなされ、同一軸の比較が難しくなっている。また同じクラウドベンダーのサービスでも機能がオーバーラップし、容易には理解できない複雑さになっている。
つまり「あることをやりたい」といっても、実現可能なソリューションが複数存在する。そのため、それぞれのサービスの特徴を理解し、自身の実現したいこととの適性を照らし合わせ、最適なものを組み合わせて使用することになる。また局面によっては、複数のクラウドサービスを組み合わせる「マルチクラウド」が必要になるだろう。
各社のサービス概要
冒頭でも少し触れたが、本連載で取り上げるのは「Azure Data Explorer」や「Amazon Athena」「Google BigQuery」だ。そこで、以降ではMicrosoft Azure、GCP(Google Cloud Platform)、AWS(Amazon Web Services)のそれぞれが展開するデータ活用系サービスの概要を紹介する。
サービスを「収集」「変換」「保存」「分析」「視覚化」の5つに分類しているが、複数の機能を持つサービスも多いため、便宜上の分類と捉えていただきたい。また、各クラウドベンダーのサービスをなるべく同じ視点で分類したいので、ベンダーの分類と異なることもある。
そしてRDBMSやNoSQLなどのデータベースは、分析基盤として利用するのではなく、データレイクやデータウェアハウスのデータソースとして利用することが多い。そのため、今回の図からは除外している。
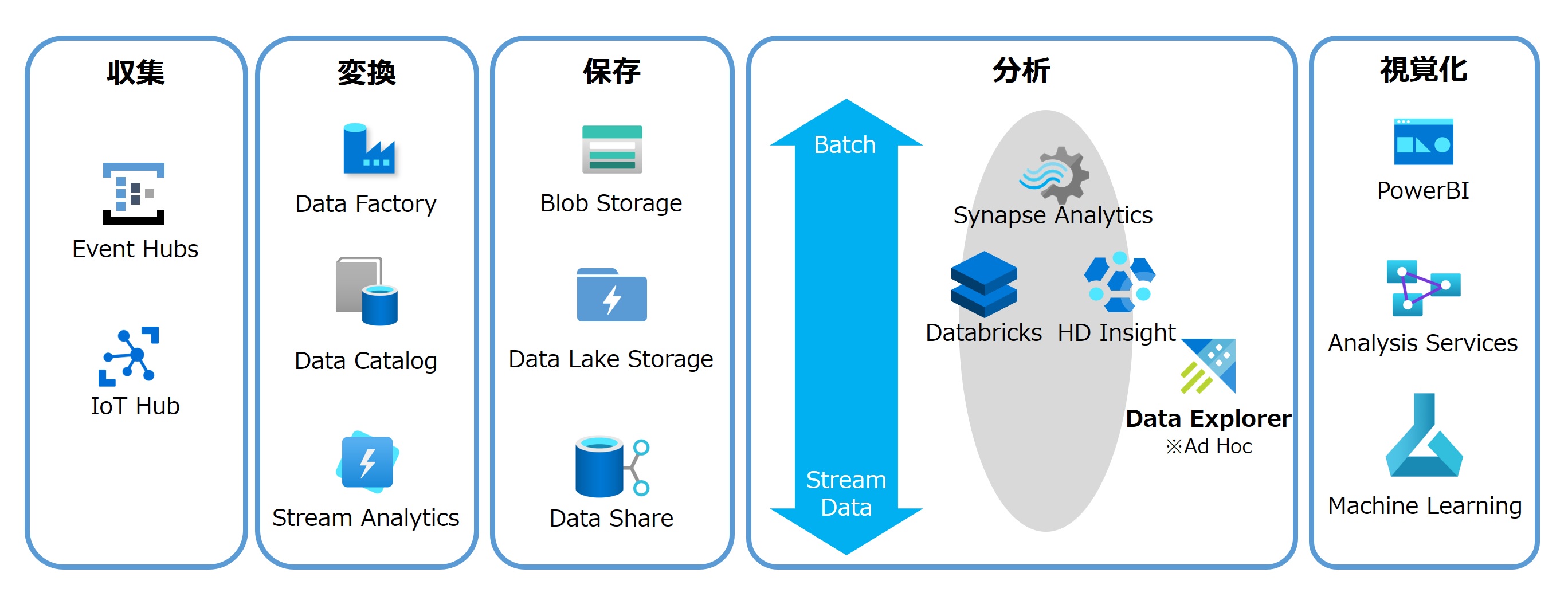
Microsoft Azure
Azureでは、バッチ処理やリアルタイム処理のそれぞれに多くのサービスを展開している。DWHを含む分析基盤の「Azure Synapse Analytics」、Sparkベースの分析基盤「Databricks」、ETLツールの「Azure Data Factory」などだ。
そしてオブジェクトストレージの「Azure Blob Storage」、Blob StorageにHDFS互換の機能を持たせた「Azure Data Lake Storage Gen2」、セキュアにさまざまなデータを共有する「Azure Data Share」などがある。
Azure Data Explorerは、大量に生成されるログデータやテレメトリーデータを高速に検索するマネージドサービスだ。Azure Data Explorerの詳細は第3回以降で解説する。
GCP(Google Cloud Platform)
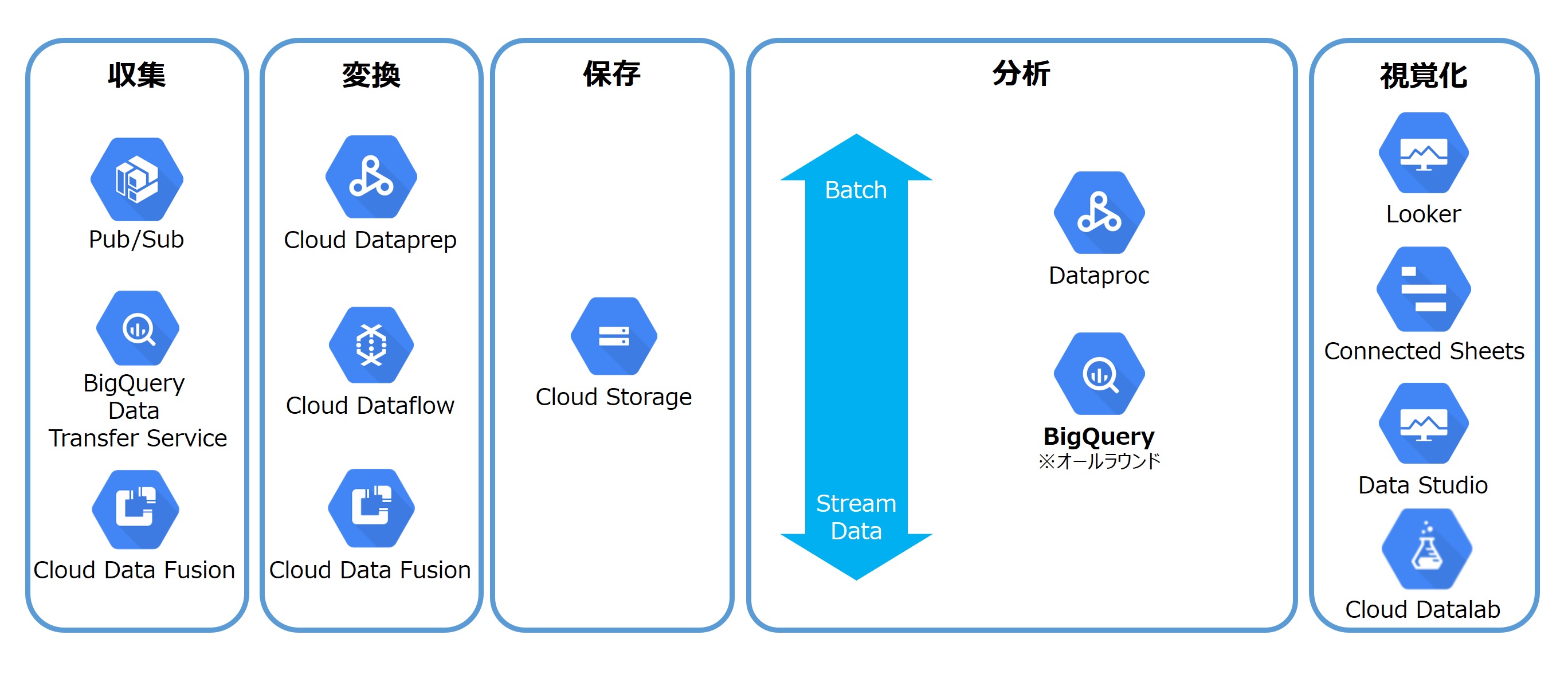
GCPも多くのデータベース系サービスを提供しており、その中でも特徴的なのはDWHサービス「Google BigQuery」だろう。使い勝手もさることながら、テラバイト級の数兆件のデータを含むファイルを数秒で検索できると言われている。Googleは自社で大規模データを扱うことから、BigQueryは大規模分散処理で優位にあると言える。
データレイクとしては、オブジェクトストレージの「Google Cloud Storage」もあるが、相対的に「Google BigQuery」の存在が大きい。BigQueryはサーバーレスであり、管理コストもきわめて低い。ただし、スキャンしたデータ量に依存する従量制課金が基本なので、慎重なコスト管理が必要だ。
他社と比べて特徴的なのは、他社がデータ分析系のソシューションを複数展開しているのに対し、BigQueryは検索ソリューションのオールラウンドプレイヤーであることだ。コストさえ考えなければ、BigQueryに放り込んでおけば良い、というわかりやすさがある。
AWS(Amazon Web Services)
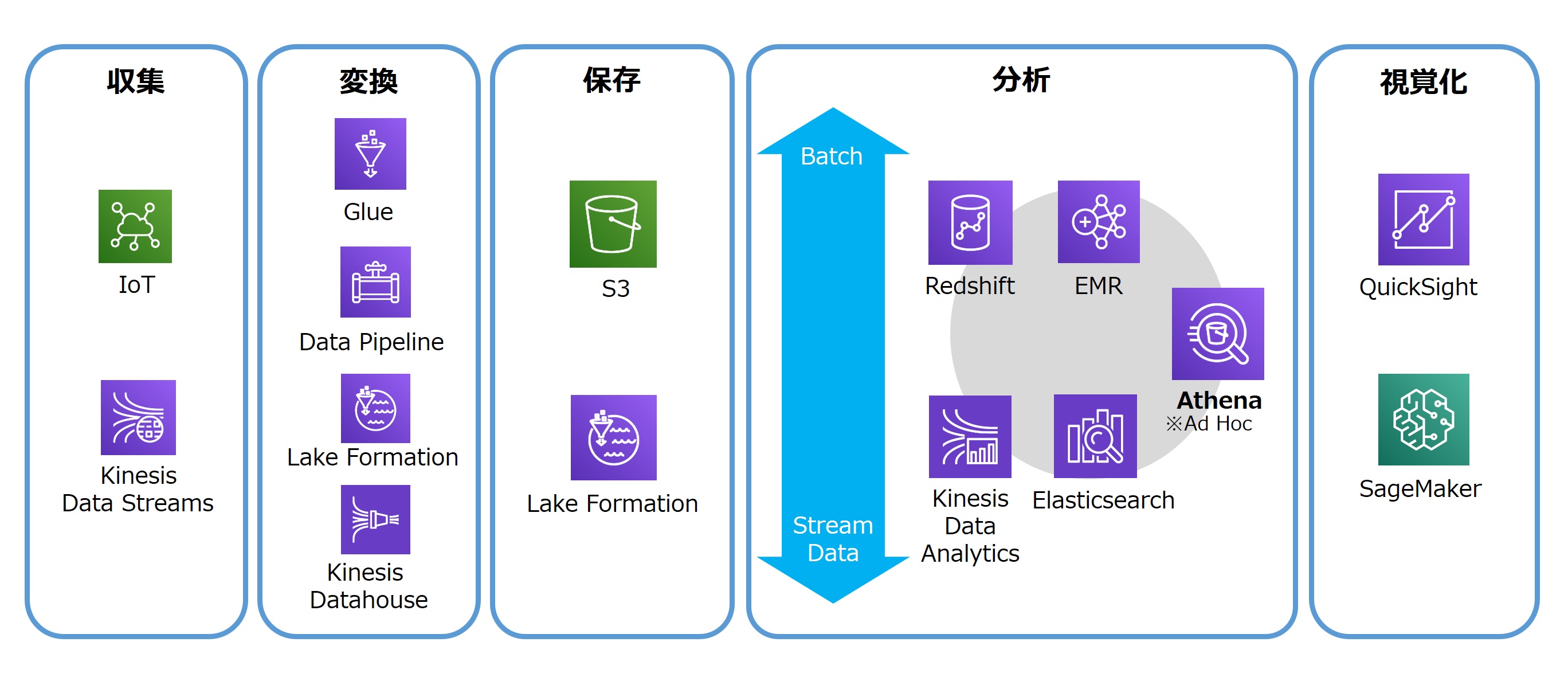
AWSではDWHの「Amazon Redshift」をはじめ、ETLツールの「AWS Glue」など、さまざまなサービスを提供している。これらのサービス群の中心に位置するのはオブジェクトストレージの「Amazon S3」だ。すべてのデータをS3にロードしてデータレイクを構築し、AWS Glueでデータフォーマットを整え、そこから各種ツールを使ったデータ分析を行う。
このとき、S3上のデータセットに対して、直接SQLでクエリーできるのがAmazon Athenaである。
おわりに
今回は連載第1回目として、DXとは何か、また各社のデータ活用系サービスの概要を説明した。次回以降では、データウェアハウスとデータレイクとの違い、ストリームデータ処理など、各社のサービスを理解するうえでの基礎知識を解説していく。
この記事をシェアしてください
バックナンバー
この記事の筆者


筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
