ビッグデータ処理基盤とRDBの連携の必要性およびPostgreSQL FDWの概要
2018年5月22日 6:00
はじめに
過去の連載(「ユースケースで徹底検証! HBaseでIoT時代のビッグデータ管理機能を試す」)で説明したように、RDBとNoSQLやHadoop上のデータの扱いは、データ構造やアクセス方法、トランザクション有無など大きく異なるため、用途ごとに使い分ける必要があります。しかし、使い分けるという事は複数のデータ格納場所ができるという事であり、実際の業務システムで使うにはそれぞれの間のデータ連携を考える必要があります。
本連載では、データ連携の方法を調査・検証した結果と、そこから得られたデータ連携のノウハウを紹介します。
今回は連携の必要性と懸念点、連携先となるRDBについて説明します。
連携の必要性
「はじめに」でご説明したように、トレース情報やライフログ、センサー情報等のIoTデータは、画像や音声、ログ等の構造化されていない多種多様(Variety)、 かつ、大量のデータ(Volume)が、高頻度(Velocity)発生する、といった「3つのV」に対応しなければなりません(これに、価値の「Value」、もしくは、正確性の「Veracity」を加えて「4V」と言われることもあります)。そのため、HBaseやHDFSといったビッグデータ処理基盤を新たに構築し、処理基盤をデータレイクとして運用しているケースをよく見ます。
データレイクとは、「データの湖」という和訳に示す通り、多種多様なデータ形式を集中的に貯めておけるような大容量の格納領域のことです。単に貯めておくだけでは意味がないので、効率的に参照(活用)できる形であることが必要です。
下図は、弊社が推進しているIoTプラットフォームである「Lumada」の概念図です。多くのデータをデータレイクに蓄積し、そのデータを核として顧客協創による新たな価値創出ができるような仕組みを提供しています。
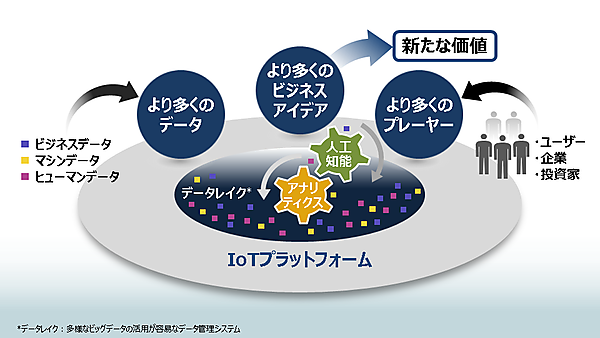
このデータレイクに蓄積された膨大なデータ(以下、IoTデータ)を分析することによって、今までの定型的なシステムでは得られなかった新たな価値が創出されていますが、最近はこのIoTデータの活用範囲がさらに広がっている状況です。その一つが、既存の業務システムにある基幹データとIoTデータを組み合わせて、新たな価値を創出する(既存システムのサービスを強化する)事を目的とするものです。
例えば、業務システムに蓄積したユーザ情報とIoTデータを組み合わせて、利用ユーザに対して利用状況をリアルタイムに「見える化」したものを提供する、といったことです。このような付加価値を提供することにより、競合といち早く差別化でき、ビジネス的に優位に立つことができる可能性があります。
懸念点
しかし、システムを連携するには大きな課題があります。それは、企業内のシステムの多くが、目的ごとに独立してシステム設計・構築(サイロ化)をされてきた結果、「他システムのデータを活用するのにコストや手間がかかる」という点です。
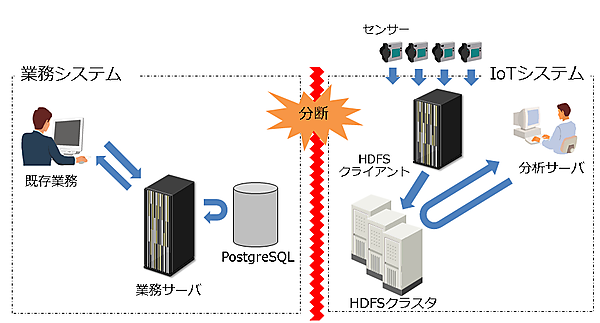
そのため、サイロ化されたシステム間でデータを活用するためには、何らかの施策で連携を検討する必要があります。連携の検討にあたっては、既存の枠組みのままデータの連携のみ追加するパターンと、データを片寄せし統合してしまうパターンの2種類が考えられます。それぞれ具体的な手段をまとめたのが下図になります(本連載では、ETLツールの説明は割愛します)。
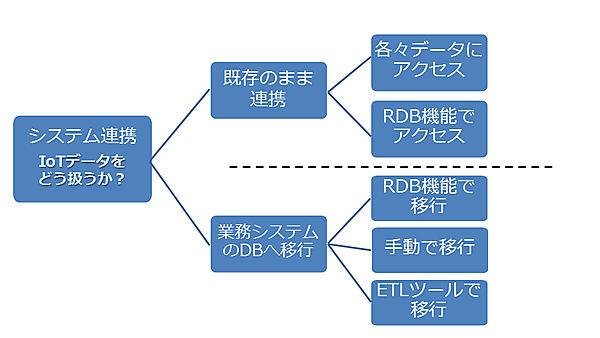
「RDB機能でアクセス」や「RDB機能で移行」など、RDBの機能を利用した連携を実現するには、RDB自身がその機能(と性能)を充足している必要があります。
一方で、近年OSS機能の発展を受け、OSSが活用されるケースが増えてきました。これはデータベース領域も同様で、OSSのデータベース(以下、OSS-DB)においても機能の発展により、優れた連携機能を持つものがあります。
本連載では、優れた連携機能を持つPostgreSQLを活用した例を紹介します。
PostgreSQLについて
PostgreSQLは、PostgreSQL Global Development Groupで開発されているオブジェクトリレーショナルデータベースで、非常に多くの機能や最新の機能をサポートしています。ライセンスは、The PostgreSQL LicenseというMITやBSDに似たライセンスで、個人利用・商用利用に関わらず誰でも無償で利用・変更・配布できます。
昨年10月にPostgreSQL 10がリリースされ、パーティションやレプリケーションなどの設計が容易になる「宣言的パーティショニング」や「ロジカルレプリケーション」など新たな機能が追加されていると同時に、性能面でもパラレルクエリの改善やFDWの強化(後述)などが行われており、バージョンアップされるに従ってより使いやすいRDBMSとしての進化が続いています。PostgreSQL10の新機能は「PostgreSQL: Documentation: 10: E.3. Release 10.1」を参照してください。
また、PostgreSQLは、DB-enginesの「DBMS of the year 2017」にも選ばれました。これは、年間で最もスコアを増やしたデータベースに贈られる賞であり、PostgreSQLはこの1年間でさらに注目されたRDBMSであるといえます。補足ですが、スコアは人気度を独自計算したもので、計算方法は「DB-Engines Ranking - Method」で確認できます。
FDWの概要
PostgreSQLの注目すべき機能の一つに、「FDW(Foreign Data Wrapper)」という独自機能があります。これはその名の通り、PostgreSQLの外部に格納されているデータにアクセスできる仕組みですが、これによりFDWが対応したどのようなデータにもSQLでアクセスできるというメリットがあります。
PostgreSQL本体に取り込まれているFDWは、外部のPostgreSQLにアクセスが可能になる「postgres_fdw」と、OS上の外部ファイルにアクセスが可能になる「file_fdw」が準備されています(バージョン9.3~)。なお、file_fdwは参照のみとなっていますが、postgres_fdwは更新にも対応しています。これらはcontribモジュール(デフォルトではインストールされないPostgreSQLの拡張モジュール)として追加されているため、使うには設定・構築が必要になります。今回は、postgres_fdwを例に、FDWを紹介いたします。
FDWには、PostgreSQLに同梱されているものだけでなく、非公式に開発されているものもあります。その中から次回、ビッグデータ基盤とPostgreSQLの連携用に開発されているFDWを紹介します。
まず、postgres_fdwの基本的な処理の流れは次の通りになります。
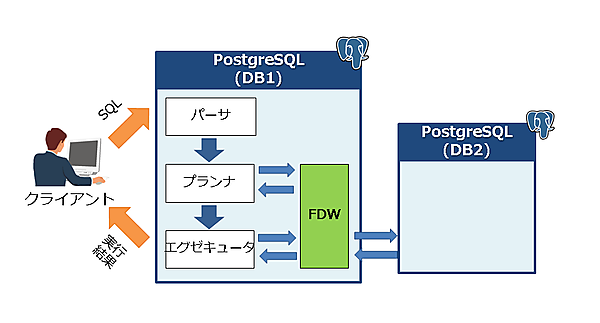
- クライアントからSQLを発行する
- パーサが構文解析する
- プランナが実行プランを選択する。外部表の場合にはFDWに実行プランを聞きにいき最適プランを導き出す。
- エグゼキュータが処理を実行する。外部表の場合にはFDWに処理を委譲する(pushdown※により、集計や結合処理が同じ外部サーバであればそれらの処理も委譲する)
- 外部データを取得する
- 読み取った結果をPostgreSQLの内部表現に変換する
- クライアントに返却する
といった流れになります。
※pushdownとは、外部サーバでSQLの条件式(where句や集約関数、結合など)を処理できることで、pushdownによって処理の分散やデータ転送量の減少が図れます。その結果、全体処理の高速化が見込めます。
なお、未対応の場合は、外部サーバのテーブルデータ全体をローカルに持ってきて処理するため、負荷が高くなります。
FDWの構築手順
次に、postgres_fdwを使ったFDWの構築手順を紹介します。構築手順の基本的な流れはどのFDWも似ていますが、正しくはそれぞれのFDWのマニュアルを参照してください。
初めに構築結果イメージを下図に示します。具体的には、DB1に接続したユーザがDB2のpgbench_accountsのデータをそのままを参照したい、というものです。
なお、連携するデータベースはそれぞれ構築済みであることを前提に説明します。
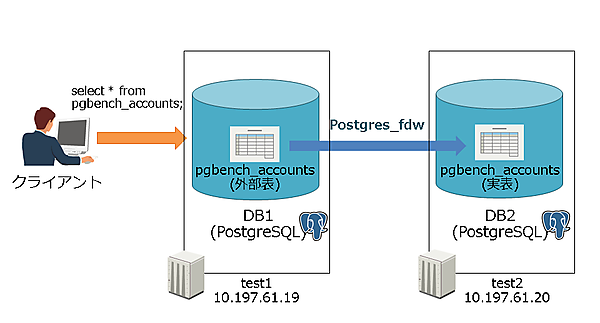
FDWの構築は、参照する側(DB1)で行います。
- postgres_fdw拡張をインストールします。
postgres_fdw拡張をインストールしていない場合は、最初にインストールを行います。ソースを使うパターンとバイナリを使うパターンの2つの方法がありますので、それぞれ説明します。なお、本連載では、バイナリはrpmを使用することにします。- ソースを使う場合:contrib/postgres_fdwフォルダでmake、make installを実行します。
- rpmを使う場合:postgresql10-contribパッケージをインストールします。
- PostgreSQLにログインして、create extensionコマンドでpostgres_fdwエクステンションをインストールします。

- create serverコマンドで、接続するリモートデータベースの外部サーバオブジェクトを作成します。

- create user mappingコマンドで、接続するデータベースのユーザマッピングを作成します。

- reate foreign tableコマンド、もしくはimport foreign schemaコマンドで、外部テーブル表を作成します。後者の方が設定をミスしづらいため、import foreign schemaコマンドを使った例を示します。

- 設定した結果として、pgbench_accountsテーブルの行数を取得します。

- ソースを使う場合:contrib/postgres_fdwフォルダでmake、make installを実行します。
併せて、explain analyzeを使って、実行計画を確認します。その結果、外部表を見に行っていることが確認できます。
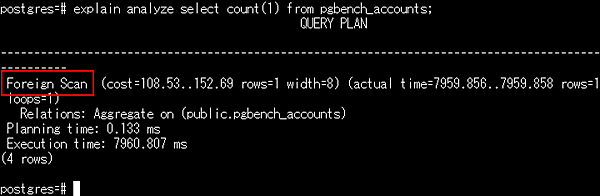
このように、FDWは比較的簡単に構築できます。
各種オプションの説明等、詳しくはpostgres_fdwのマニュアルを参照してください。
なお、postgres_fdwはバージョンアップに従って開発、機能強化が進んでいます。最新バージョンであるPostgreSQL 10の主要な強化点は、Aggregate pushdownやJoin pushdownの機能強化が挙げられます。これは、「FDW概要」に記したpostgres_fdwの処理の概要のうち、「④エグゼキュータが処理を実行する。外部表の場合にはFDWに処理を委譲する」に当たります。その他詳しくは、PostgreSQL 10のリリースノートを参照してください。
また、現在は次期バージョンであるPostgreSQL 11の開発・提案が進められています。postgres_fdwは主にシャーディングに関連する機能の提案が行われている、と言われています。
PostgreSQLをベースにフォークされたシャーディング可能なDBとして、Pivotal社のGreenplum Databaseや2nd Quadrant社のPostgres-XL等があります。このようにシャーディング関連機能の開発が積極的に行われていることから、このpostgres_fdwが将来拡張していくことにより、以下の様な事が実現できると筆者は考えています。
- 現在ボトルネックになっているPostgreSQLの更新負荷分散(更新スケールアウト)に対応することで、FDW機能のみで更なる大規模DBやIoT基盤のデータレイクといったSoE分野に適用範囲を広げていく事が可能となる
- GreenplumやPostgres-XL、また、Hadoop基盤を使う場合と異なり、アプリケーションの変更が不要なので既存資産を最大限活用しながら性能向上をはかることができる
次回は、ビッグデータ基盤とPostgreSQLの連携用に開発されているFDWをご紹介します。
最後に、postgres_fdwの今後につきまして、NTT OSSセンタの澤田雅彦様にご助言をいただきました。ありがとうございます。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
