目次
- はじめに
- RPAの仕組み
- RPAに必要な機能
- RPAの利用用途
- RPAの3つのクラス
冒頭でRPAは”機械学習モノ”ではなく”ロジックモノ”だと書きましたが、RPAにAI要素を取り入れてより賢いRPAを目指す取り組みがなされています。そうした観点からRPAは3つのクラスに分けられています(図4)。
現在主流のRPAはルールベースで動作するクラス1です。画面操作手順を記憶して、ワークフローで設定した通りを忠実に実行します。クラス2とクラス3は機械学習による自立型AIの要素が入ります。この2つの差は明確に定義されていないのですが、クラス3が人間のようなAI(一般に強いAIと呼ばれているもの)で、クラス2は先ほど紹介した構造認識AIのような特定の処理においてAIを取り入れるレベルと捉えておけば良いでしょう。RPAの弱点
RPAの弱点は「ロバスト性」です。ロバスト性とは、外乱の影響があったときでも持続できる対応力のことで、車に例えればサーキットに最適化したF1カーより、悪路でも走れるSUVの方がロバスト性は強いと言えます。
RPAは決められたことを忠実に再現しますが、画面に通知メッセージが表示されたり、処理するデータに想定外のものが入っていたりすると、すぐにエラーで止まってしまいます。そして、セットした夜間処理が全く行われなかったのを知らずに出社して、ガーンとショックを受けるわけです。
どのようなエラーでストップするのか、あらゆる想定を立ててエラーを検知する仕組みを設定するのはかなり大変です。例えば、ウィルスソフトの通知ポップアップでエラーになった場合は、一定時間後に通知が消えるのを待ってもう一度処理するか、消えないポップアップなら閉じる操作を行わせなければなりません。
データに不備があって入力が完了せず、画面上にエラーメッセージが出ている場合はどうでしょうか。こんな簡単なケースでも、実はRPAに「エラーが出ていますよ」と教えるのは意外と難しいです。エラーメッセージ表示エリアにエラーメッセージ(ラベルコントロール)が表示されていたら、エラーと判定してそのデータはスキップするなどのエラー処理を記述することになります。
また、画面上の1項目ずつを入力するとき、人間は無意識に相手(コントロール)が反応したかを目視しながら次の項目の入力に移るのですが、RPAは(今のところ)このような認識ができません。そこで1項目ずつタイマーで遅延させて、(たぶん)反応しただろうというタイミングで次の入力に移るよう対処するケースもあります。
最初にすべての想定を設定できれば一番良いのですが、通常は何度も痛い想いをしながら少しずつ例外処理対応を付け加えてロバスト性が高めていきます。過去のエラーを学習してロバスト性を高める、そんなAIも欲しいところです。
RPA製品の違い
もともとRPAという言葉を使い始めたのはイギリスのBlue Prism社ですが、今では海外および国内から非常に多くのRPA製品が出ています。急速に市場が広まっているため、まだ発展途上な面もありますが、製品をチェックする上のポイントをいくつか説明します。(1)RPAの基本機能
一般にRPAに必要とされる基本的な機能は次の通りです。RPAを選定する際は、これらの機能がどのように実装されているかを確認する必要があります。 ・キーボードやマウスの操作を記憶する
・画面上の表示文字や画像情報を取り込める
・ワークフロー(処理手順)を作成・カスタマイズできる
・ワークフローに従ってキーボードやマウスを自動化できる
・エラー処理やログ記録機能を持つ
・データをもとに分析できる (2)サーバー型とクライアント型
RPAには、ソフトをクライアント端末にインストールする「スタンドアローン」または「クライアント/サーバー型」とサーバーにインストールする「サーバー型」、そしてクラウドでサービスを提供する「クラウド型」があります。 (3)WebとWindows
製品の生い立ちにより、Webに強いタイプとWindowsに強いタイプがあります。最終的には、両方とも「どんとこい」になるでしょうが、現状はまだ得意不得意が見られる製品があります。 (4)記録機能
人間の操作を自動記録して処理フローの初期設定を行えるタイプと、記録機能がないタイプがあります。もちろん、記録機能のある方がずっと初期設定をしやすいのですが、実際には記録した通りになぞるだけではやりたい処理は行えません。繰り返しや分岐、例外処理などのフローをどこまで実務を想定してわかりやすく設定できるかが重要なポイントとなります。(5)フロー設定
処理フローをScript(リスト形式)で記述するタイプ、マウス操作でフローチャートを作成するタイプ、プログラミング言語で記述してゆくタイプがあります。新しい作業や作業の変更などに柔軟に対応するためには、できるだけ現場で簡単にフローを作成・変更できる必要があります。その際に重要なのが、実際の作業に即したライブラリの充実度です。ライブラリをユーザーが作成・追加できる仕組みも備えているタイプであれば、利用しながら自社に合った処理を追加できます。 RPAの今後 RPAは急速に世の中に広まりつつあり、さまざまな製品がわっと現れ、またそれぞれの製品が進化しはじめており発展途上です。利用料金もまだ割高で、ユーザーの導入事例がニュースになったりしているわけですが、こうしたことは黎明期にありがちな現象です。いずれは、各製品ともコモディティ化して似たような機能に収束してゆき、価格も大幅に下がってゆくものと思われます。 みなさんはExcelの価値をどう思いますか。企業の業務に欠かせない便利なツールの価値を先入観なしで考えてみると、数百万円と言われても導入するだけの価値はあります。 そしてRPAはExcelのようなものとも考えられます。特定の目的のために導入するものではなく、どの企業にも装備され、利用できそうな作業があったときにパッと設定して使うというツールになるかも知れません。そういう意味からも、ERPやSFAのようなソフトではなく、Office365のようなユーティリティ的なソフトの1つとして提供されることになると一人で予想しています。 - RPAの弱点
- RPA製品の違い
- RPAの今後
はじめに
今回のテーマはRPA(Robotics Automation Processing)」です。日本でもこの1、2年で急速にRPAが知れ渡り、多くの製品が出回るようになりました。
RPAは厳密に言うと自立型AIの”機械学習モノ”ではなく、人間が教えた通りに実行する”ロジックモノ”なのですが、非常に関心が高まっています。
RPAの仕組み
RPAは、「人間が設定した手順通りに操作する”端末操作ロボット”」です。ロボットと言っても形があるわけではなく、あくまでもソフトウェアの機能として次のような処理を行います(図1)。
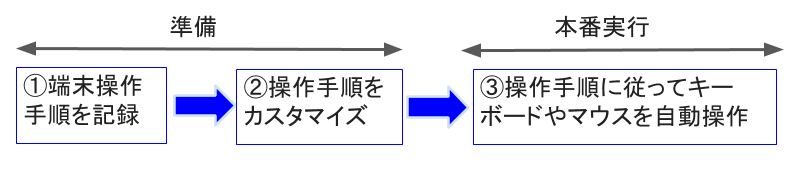
図1:RPAの処理手順
①端末操作手順を記録
ビデオの”録画モード”と同じように、RPAを”記録”モードにしてから端末を操作すると、カーソルやマウスの動きと位置(座標)が忠実に記録されます。ただし、RPAによってはこうした記録機能がなく、人間がイチから処理フローを組み立てるタイプもあります。
②操作手順をカスタマイズ
記録した操作手順を画面表示して確認し、必要に応じて条件分岐を付け加えたり、エラー発生時の処理を加えたりして処理フロー(シナリオ)を作成します。ファイルを開くやタブを切り替える、メールを受信するなど、よく利用する操作に関しては、その操作に特化したライブラリが用意されています。こうしたライブラリを自分で作成・追加できるタイプもあります。
RPAによって処理フローの作成方法は異なります。現場部門で手軽に操作を仕込めるようにリスト(Script)形式で作るものもあれば、もっとビジュアルにマウス操作でフローチャートを作成するタイプもあります。一方でJavaやC#、Rubyなどでプログラミングして処理フローを作成するRPAもあり、こちらは複雑な処理もきちんと組み込める柔軟性がメリットです。
③操作手順に従ってキーボードやマウスを自動操作
設定した処理フローに従って、キーボードやマウスを自動操作します。例えば、あるフォルダに入っているExcelファイルを開き、データを1行ずつ読み出してERPの画面に入力してゆく作業があるとします。その手順を設定しておけば、フォルダにExcelファイルが100個あり、さらにそれぞれのファイルにデータが1000行あっても、RPAは黙々とその作業を繰り返して十万件のデータを画面に入力し続けます。 ただし、処理速度はそれほど速くないので、それなりの時間を要します。
また、単純に記録した処理を繰り返すだけでは同じファイルを何度も入力してしまいます。そのため、例えば次のようなFor Loop的な繰り返し処理フローを作成して、きちんと目的の業務が遂行できるようにする必要があります。
フォルダを開く
Excelファイルを開く
1行目のデータを読む
データをチェックする
処理する
次の行のデータを読む
次のExcelファイルを開く
フォルダを閉じる
処理結果を通知する
RPAに必要な機能
(1)OCR機能
Excelのような定形フォーマットのデータではなく、FAXで送られてきた注文書だったり、紙の伝票だったりする場合はどうでしょうか。この場合は、それらをOCR(光学式文字認識)でデータ化してから読み取って入力することになります。
実はRPAはこうした紙の処理への期待が大きく、OCR機能を内蔵しているタイプも多くあります。その際に注目されているのが手書き文字認識AIです。AI技術を使うことで最近は日本語でもまずまずの認識率を達成しており、なお進化し続けています。
なお、最近はデータで送受信することが多いので、OCRだけでなくEAI(Enterprise Application Integration)ツールと連携する事案が増えています。
(2)座標認識
人間がマウスを目的の項目に移動できるのは、画面上のどこに何の入力項目があり、どこにどんなボタンがあるか見えているからです。では、RPAはどうやってそれを認識しているのでしょうか。
1つは座標情報を記録する方法です。対象のブラウザやWindow画面を指定した上で画面上のコントロールの位置情報(座標)を記録し、その座標情報を頼りにマウスを動かしていきます。メインフレームのような画面向けにエミュレーションモードを持つタイプもあります。
(3)画像認識
座標情報だけではかなり制約があります。解像度が異なっていたり、文字サイズを変更したりするだけですぐにRPAは行き詰ってしまいます。また、メッセージが出てその分位置がずれたり、文字が折り返して複数行になったりするだけで目指すコントロールが出来なくなります。
この問題を補完するのが画像認識です。テキストボックスやボタンなど操作対象のコントロール付近の画像をキャプチャして位置情報と一緒にRPAへ登録し、操作実行時に記録したイメージと画面のイメージを照合して操作対象を特定します。 イメージは予め設定した一定範囲を自動取得するほか、手動で範囲を指定できるものもあります。
(4)画面要素認識
操作対象の画面がIEなどのブラウザであれば、HTMLの情報を読み取ってコントロールごとに付けられたIDとコントロールの種類(テキストボックスやボタンなど)を認識できます。位置情報と画像情報に加えてIDとコントロール種別も情報として持つので、より認識精度を高めることができます。
(5)ファイル構造認識
操作対象がExcelあればファイル名やシート名、セルで対象データを特定できるので扱い易いです。CSVでもファイル名や行番号、カンマ区切りの何番目かで特定できます。
RPAは、操作対象に応じて上記の認識技術を組み合わせて認識します。対象がメインフレームならエミュレータによる座標認識のみですが、それ以外なら座標認識と画像認識を併用できます。さらにブラウザであれば画面要素認識も付け加えられるわけです。
複数の認識技術を組み合わせると、ウィルスソフトやチャットbotの通知ポップアップにも対応でき、表形式でデータ表示がされていても、「これは表だ」と正しく認識してきちんと値を読み取れます。
最近、当社でAIの画像認識技術を利用して画面デザインを解析するツール「AISIA Design Recognition」を作成しました。画面キャプチャを読み取って、画面上の個々のコントロールをオブジェクトとして検知し、コントロールの種類(テキストボックスやラベル、ボタンなど)とコントロール座標を認識し、さらにAI-OCR機能を使って画面上の文字を読み取る仕組みです。
図2は、認識後の画面です。オレンジがテキストボックス、ブルーがラベル、グリーンがボタン、イエローがチェックボックスというように、個々のコントロールの種別を判定していることがわかります。
元々はアプリケーション設計書の逆生成という全く違う目的で作成したツールですが、このようなAI技術を使えばコントロール単位でイメージと座標を認識できるので、RPAのロバスト性向上に役立つなと思っています。

図2:画面デザインを認識する「AISIA DesignRecognition」
RPAの利用用途
RPAは、ホワイトカラーの業務を代行するデジタルレイバー(Digital Laber)として期待されています。実際、一度使ってみるといろいろな応用方法が頭に浮かびます。反面、使ってみないとなかなか使い方がイメージできないようです。RPAがどのような業務で有効なのか、ここでは4つの利用パターンを紹介します。
(1)データの入力作業
データの入力作業にRPAを使う場合は、「大量」で「多品種」な「単純作業」がキーワードになります。例えば、RPAの導入事例としてよく出て来る日本生命保険は、2014年にRPA「日生 ロボ美」を導入して社内のさまざまな入力業務に提供しています。担当業務は金融機関窓口販売商品の手続きなどで、新規申込や保存手続き、支払いなどの事務処理を年間15万件も処理しています。紙の申込書の記載内容を基幹業務システムに入力するような単純作業をRPAに置き換えることで、業務効率化に成功しているとのことです。
こうした社内の入力作業をRPAに置き換える動きは、三菱東京UFJ銀行やオリックスなど多くの企業で実施され着実に効果を上げているようです。
RPAは、コンピュータによる自動処理と手入力の中間に位置します。普通に考えれば、前述の例に掲げたExcelデータの入力作業が日常的に発生するなら、データ取り込みプログラムを作って自動処理した方が手っ取り早いといえます。しかし、現実的にはシステム部門のバックログは積み上がっており、システム化が間に合っていない業務は社内にごろごろしています。
また、キーワードに「多品種」と書きましたが、ビジネスは常に変革しており、業務処理も次々と変化していきます。そうした変更をいちいちシステム部門に依頼していては、ビジネスのスピードについていけなくなります。そんな状況において、”現場部門で”迅速に処理を覚えさせられるRPAは、これからの多くの企業の業務効率化、ホワイトカラーの生産性向上に役立つ”現実解”だと言えます。

図3:RPAの位置付け
(2)複数のシステムにまたがる業務処理
情報システムによる業務自動化が完璧に行われている企業はありません。同一システム内ならある程度データ連携ができていますが、複数のシステムを導入している場合はシステム間のデータ連携が不十分で人手で補っているケースがままあります。
RPAは、このような情報処理自動化の隙間を埋める役割を果たします。この場合のキーワードは「煩雑な作業」を「定期的」に「ミスなく」行うというものです。
例えば、中途社員を採用して人事システムに社員情報を追加し、その情報を基幹業務システムや他のシステムの社員マスタにも登録するとしましょう。こうした複数システムにまたがるデータ処理は、なかなかシステム化が行き届いてなく人手に頼ることが多いわけですが、RPAにやらせれば手間が省けると同時に入力を忘れることも防げます。
こうした複数システム連携は社内のシステムだけとは限りません。例えばネットショッピングを行っている会社は、自社のECサイトだけでなく楽天やYahoo、Amazonなど複数サイトでも販売していることがよくあります。そうした場合にそれぞれのサイトにログインして商品を登録したり、在庫情報を入力したりする必要がありますが、これをRPAに行わせれば作業を軽減できます。また、それぞれのサイトから流れてくる注文データを処理する作業も、サイトごとの手順をRPAに覚えさせて自動化できます。
(3)システムからExcelファイルを作成する業務処理
経営会議や販売会議などの定形会議ではExcelベースの資料で報告が行われています。本来はBIなどを使って自動的にデータが収集・加工され、グラフや表が画面に映し出されるのが理想なのですが、現実はなかなかそこまでいかなくて、人があちこちのシステムからデータをかき集めてExcelに転記して資料を作成しています。
また、システム業界でも全社的見地から社内のプロジェクトを監視しているPMO(Project Management Office)が、いろいろなプロジェクトの進捗状況をチェックしてレポートにまとめ、経営層に報告しているようなケースがよくあります。
RPAは、こうしたExcel報告書の作成も得意です。Excelは行と列で特定されるセルに値があり、ボタンの代わりにメニューのコマンドで操作できるため、特に構造解析などの必要はありません。「どのシステムのどこを見て、その値をExcelのココに転記する」といった作業を覚え込ませることにより、人手を介した作業を削減できるとともに転記ミスを防止できます。
(4)複数Webサイトからの情報収集
競争社会で勝つために、競合会社の動向をウォッチするのはビジネスの基本です。例えば、小売業でも他社の価格を調べ、それよりも少しだけ安く値段を設定するようなことはよくありますが、こうした作業もRPAにやらせることで効率化できます。
この場合のキーワードは「煩雑な作業」を「常時」行うというものです。例えば、ライバル企業のURLを10社分登録しておき、次のような手順でライバル店より安い価格を決めるのです。
①1社目のURLを見にゆく
・商品検索欄に商品型番を入れて「検索」を押す
・検索結果から商品価格を読み取り、Excelに記録する
②2社目のURLを見にゆく
・商品検索欄に商品型番を入れて「検索」を押す
・検索結果から商品価格を読み取り、Excelに記録する
(以下繰り返し)
:
:
価格comのような比較サイトで「他社より1円でも安く」としのぎを削っているケースでも、大量の商品の価格を時々刻々とチェックするのは大変なのでRPAが役立ちます。また、価格以外でも複数サイトの口コミ情報をRPAが巡回ウォッチし、自社ブランド・製品に関係するツイートを拾って記録するなどSNS情報収集にも利用できます。 このように、RPAはこれまで人間が何気なくやっていた煩雑な作業を肩代わりしてやってくれる可能性が大きいので、非常に注目されているのです。
RPAの3つのクラス
冒頭でRPAは”機械学習モノ”ではなく”ロジックモノ”だと書きましたが、RPAにAI要素を取り入れてより賢いRPAを目指す取り組みがなされています。そうした観点からRPAは3つのクラスに分けられています(図4)。
現在主流のRPAはルールベースで動作するクラス1です。画面操作手順を記憶して、ワークフローで設定した通りを忠実に実行します。クラス2とクラス3は機械学習による自立型AIの要素が入ります。この2つの差は明確に定義されていないのですが、クラス3が人間のようなAI(一般に強いAIと呼ばれているもの)で、クラス2は先ほど紹介した構造認識AIのような特定の処理においてAIを取り入れるレベルと捉えておけば良いでしょう。

図4:RPAの3つのクラス
RPAの弱点
RPAの弱点は「ロバスト性」です。ロバスト性とは、外乱の影響があったときでも持続できる対応力のことで、車に例えればサーキットに最適化したF1カーより、悪路でも走れるSUVの方がロバスト性は強いと言えます。
RPAは決められたことを忠実に再現しますが、画面に通知メッセージが表示されたり、処理するデータに想定外のものが入っていたりすると、すぐにエラーで止まってしまいます。そして、セットした夜間処理が全く行われなかったのを知らずに出社して、ガーンとショックを受けるわけです。
どのようなエラーでストップするのか、あらゆる想定を立ててエラーを検知する仕組みを設定するのはかなり大変です。例えば、ウィルスソフトの通知ポップアップでエラーになった場合は、一定時間後に通知が消えるのを待ってもう一度処理するか、消えないポップアップなら閉じる操作を行わせなければなりません。
データに不備があって入力が完了せず、画面上にエラーメッセージが出ている場合はどうでしょうか。こんな簡単なケースでも、実はRPAに「エラーが出ていますよ」と教えるのは意外と難しいです。エラーメッセージ表示エリアにエラーメッセージ(ラベルコントロール)が表示されていたら、エラーと判定してそのデータはスキップするなどのエラー処理を記述することになります。
また、画面上の1項目ずつを入力するとき、人間は無意識に相手(コントロール)が反応したかを目視しながら次の項目の入力に移るのですが、RPAは(今のところ)このような認識ができません。そこで1項目ずつタイマーで遅延させて、(たぶん)反応しただろうというタイミングで次の入力に移るよう対処するケースもあります。
最初にすべての想定を設定できれば一番良いのですが、通常は何度も痛い想いをしながら少しずつ例外処理対応を付け加えてロバスト性が高めていきます。過去のエラーを学習してロバスト性を高める、そんなAIも欲しいところです。
RPA製品の違い
もともとRPAという言葉を使い始めたのはイギリスのBlue Prism社ですが、今では海外および国内から非常に多くのRPA製品が出ています。急速に市場が広まっているため、まだ発展途上な面もありますが、製品をチェックする上のポイントをいくつか説明します。
(1)RPAの基本機能
一般にRPAに必要とされる基本的な機能は次の通りです。RPAを選定する際は、これらの機能がどのように実装されているかを確認する必要があります。
・キーボードやマウスの操作を記憶する
・画面上の表示文字や画像情報を取り込める
・ワークフロー(処理手順)を作成・カスタマイズできる
・ワークフローに従ってキーボードやマウスを自動化できる
・エラー処理やログ記録機能を持つ
・データをもとに分析できる
(2)サーバー型とクライアント型
RPAには、ソフトをクライアント端末にインストールする「スタンドアローン」または「クライアント/サーバー型」とサーバーにインストールする「サーバー型」、そしてクラウドでサービスを提供する「クラウド型」があります。
(3)WebとWindows
製品の生い立ちにより、Webに強いタイプとWindowsに強いタイプがあります。最終的には、両方とも「どんとこい」になるでしょうが、現状はまだ得意不得意が見られる製品があります。
(4)記録機能
人間の操作を自動記録して処理フローの初期設定を行えるタイプと、記録機能がないタイプがあります。もちろん、記録機能のある方がずっと初期設定をしやすいのですが、実際には記録した通りになぞるだけではやりたい処理は行えません。繰り返しや分岐、例外処理などのフローをどこまで実務を想定してわかりやすく設定できるかが重要なポイントとなります。
(5)フロー設定
処理フローをScript(リスト形式)で記述するタイプ、マウス操作でフローチャートを作成するタイプ、プログラミング言語で記述してゆくタイプがあります。新しい作業や作業の変更などに柔軟に対応するためには、できるだけ現場で簡単にフローを作成・変更できる必要があります。その際に重要なのが、実際の作業に即したライブラリの充実度です。ライブラリをユーザーが作成・追加できる仕組みも備えているタイプであれば、利用しながら自社に合った処理を追加できます。
RPAの今後
RPAは急速に世の中に広まりつつあり、さまざまな製品がわっと現れ、またそれぞれの製品が進化しはじめており発展途上です。利用料金もまだ割高で、ユーザーの導入事例がニュースになったりしているわけですが、こうしたことは黎明期にありがちな現象です。いずれは、各製品ともコモディティ化して似たような機能に収束してゆき、価格も大幅に下がってゆくものと思われます。
みなさんはExcelの価値をどう思いますか。企業の業務に欠かせない便利なツールの価値を先入観なしで考えてみると、数百万円と言われても導入するだけの価値はあります。
そしてRPAはExcelのようなものとも考えられます。特定の目的のために導入するものではなく、どの企業にも装備され、利用できそうな作業があったときにパッと設定して使うというツールになるかも知れません。そういう意味からも、ERPやSFAのようなソフトではなく、Office365のようなユーティリティ的なソフトの1つとして提供されることになると一人で予想しています。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
