はじめに
前回はAzure Data Explorer(以下、ADX)の機能や位置づけ、ユースケースについて解説した。今回は、実際の使い方を解説することで、Azure Data Explorerに対する理解を深めることを目標にする。
なお、今回の手順を実行するにはAzureのアカウントが必要だが、実際に操作をしなくても理解できるように努めた。
Azure Data Explorerクイックスタート
Azure Data Explorerはフルマネージドサービスだが、サーバーレスではない。そのため最初にクラスターを作成する。データを検索できるようになるまでの手順は以下のとおりだ。なお、「Azure Data Explorer公式ドキュメントのクイックスタートの手順をベースにしている。詳細はドキュメントを参照してほしい。
- クラスターの作成
- データベースの作成
- データの取り込み
- クエリの実行
この一連の流れを説明しよう。
クラスターを作成する
はじめに、Azure Data Explorerクラスターを作成する。クラスターとは、Azure Data Explorerを構成する仮想サーバー群だ。
- Azure portalにサインインする。
- リソースの一覧から「Azure Data Explorer Clusters」を選択し、「追加」をクリックする。
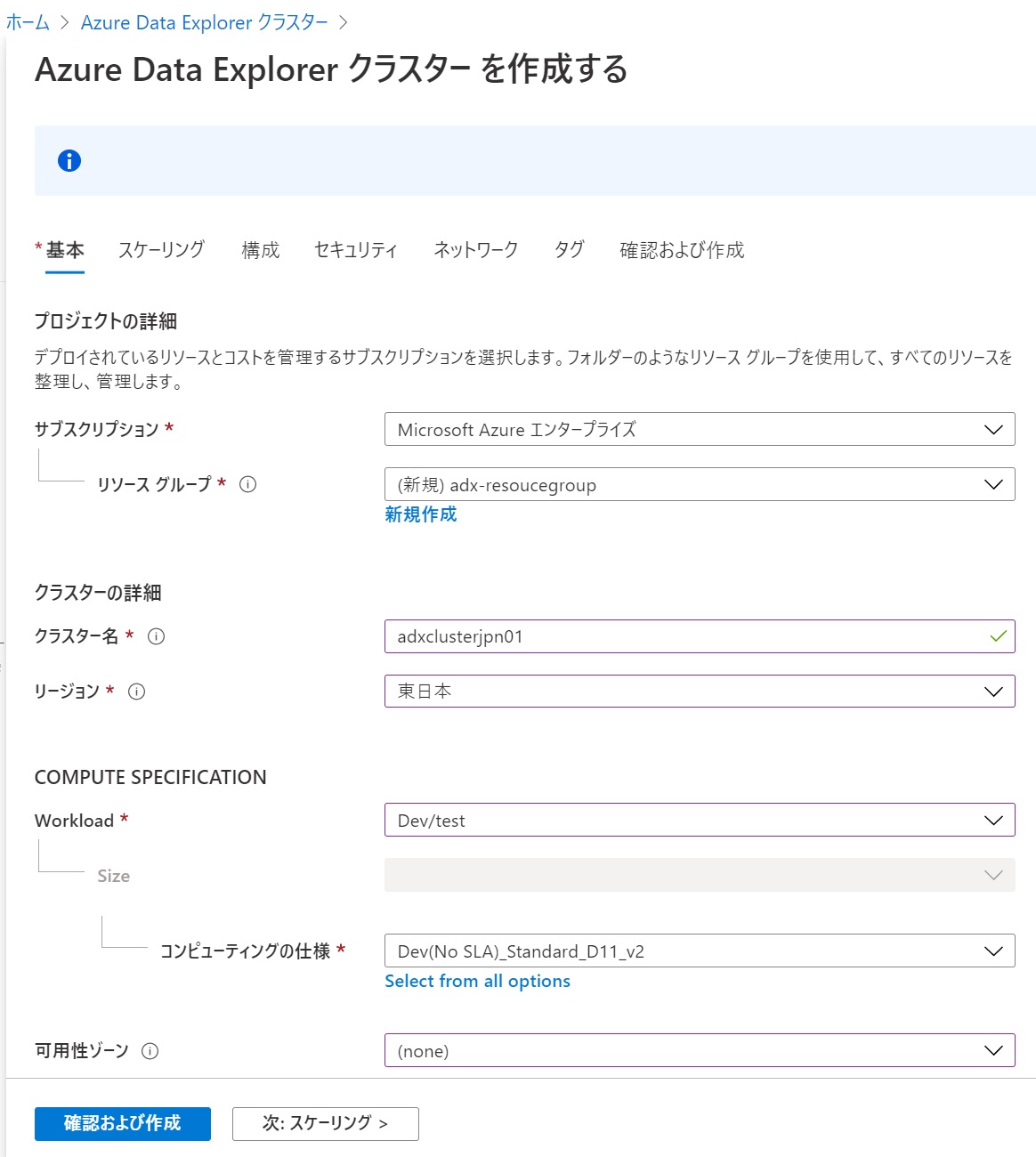
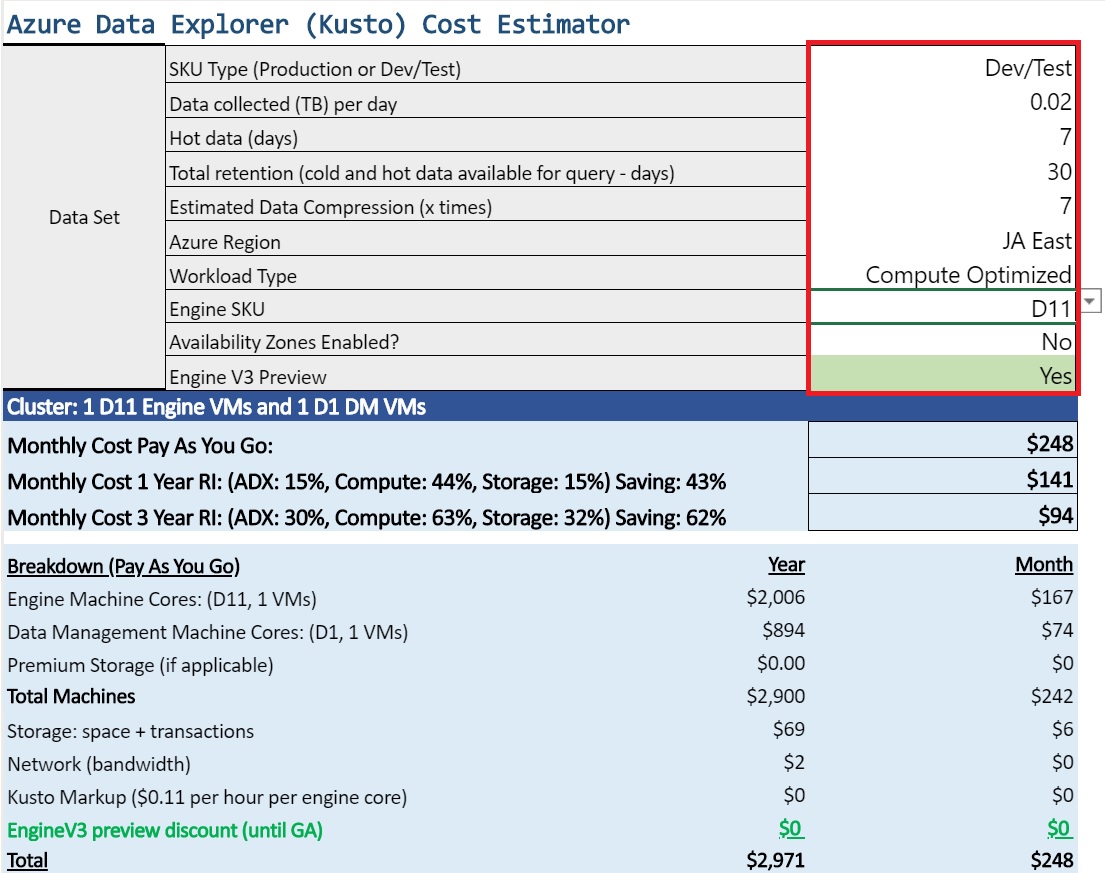
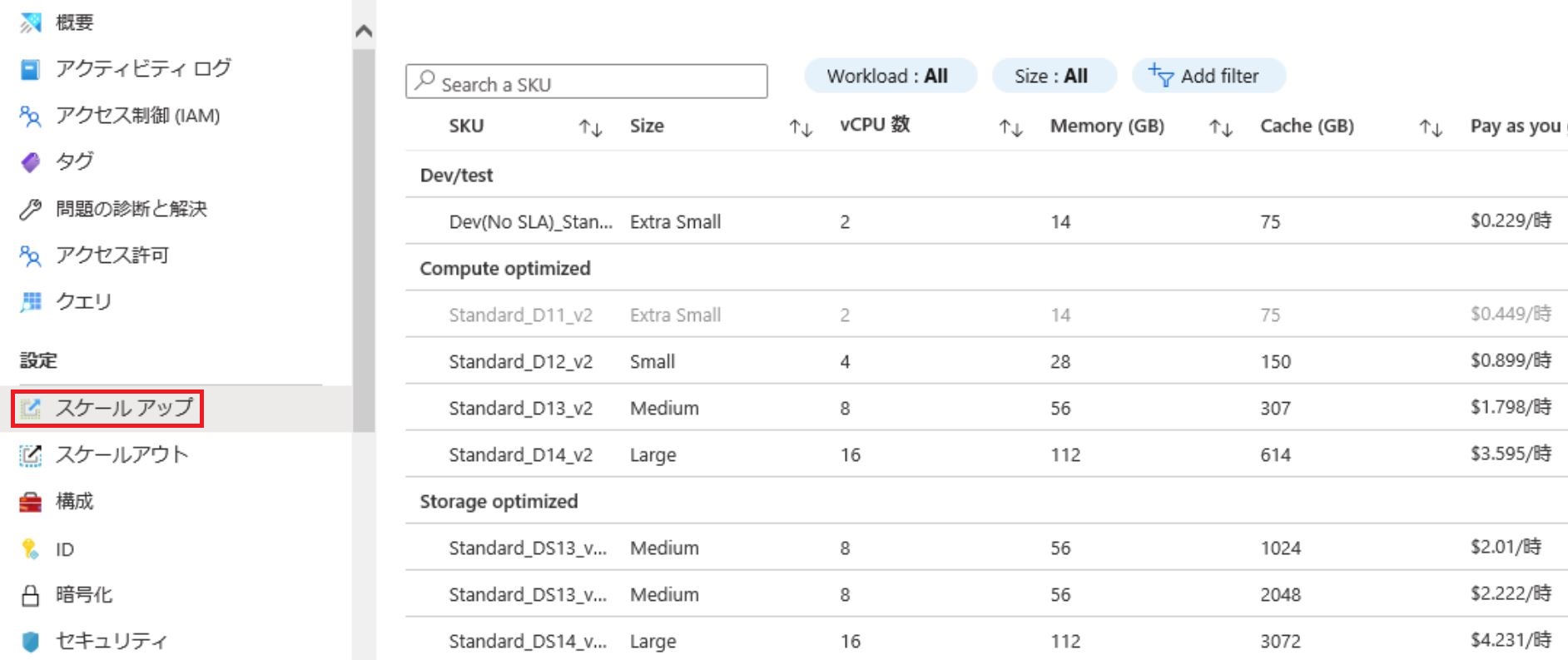
- クラスター作成に必要な項目を入力する。ここで重要なのは「コンピューティングの仕様(COMPUTE SPECIFICATION)」だ。これがクラスターを構成する仮想マシンのCPU/メモリタイプで、サイズによって価格が異なる。開発・テスト用の「E2a v4」「D11」ならば1時間20~40円で利用できる(2020年11月現在)。
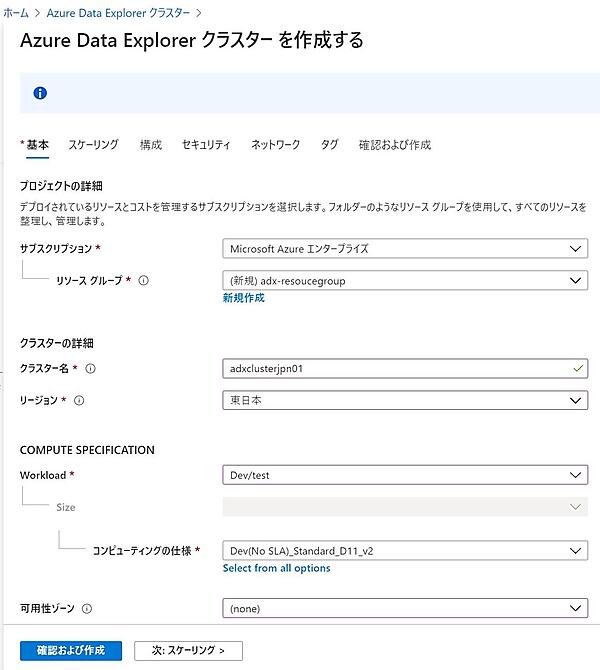
Azureのコスト見積もりツール項目 説明 データソース 英数字4文字以上の22文字以内の名前。https://<クラスター名>.<リージョン>.kusto.windows.netでアクセスするため、世界で一意の名前にする必要がある Workload Dev/Test, Compute optimized, Storage optimizedから選択する。それによって選択できるコンピューティングが異なる コンピューティングの仕様(SKU) インスタンスタイプを選択する。このインスタンスタイプによって価格が変わる
価格は「Azure Data Explorerの価格」や「コスト見積もりツール」で確認できる。下図の赤枠のセルに入力すると自動的に計算される。コスト見積もりツールはExcelライクで使いやすいのだが、セキュリティの厳しい企業のネットワークでは使えないこともあるようだ。
そしてAzureで覚えておきたい用語にSKU(Stock Keeping Unit)がある。SKUは、もともと物流用語で、アイテムの最小識別単位を指す。AzureではCPU/メモリのタイプを表し、AWSのインスタンスタイプに相当する。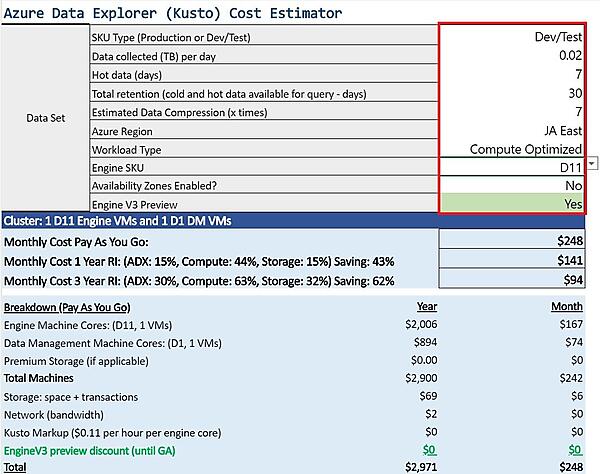
- 「確認と作成」をクリックしてクラスターの詳細を確認し、次に「作成」をクリックして作成を開始する。クラスター作成には十数分かかる。
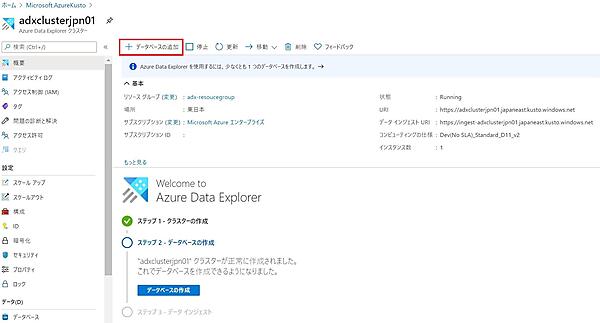
- 作成が終わると次の画面が表示されるので「リソースに移動」をクリックする。


データベースを作成する
クラスターの作成が終わるとデータベースを作成できるようになる。1つのクラスターには複数のデータベースを作成でき、データベースの作成が終わるとテーブルを作成できる。
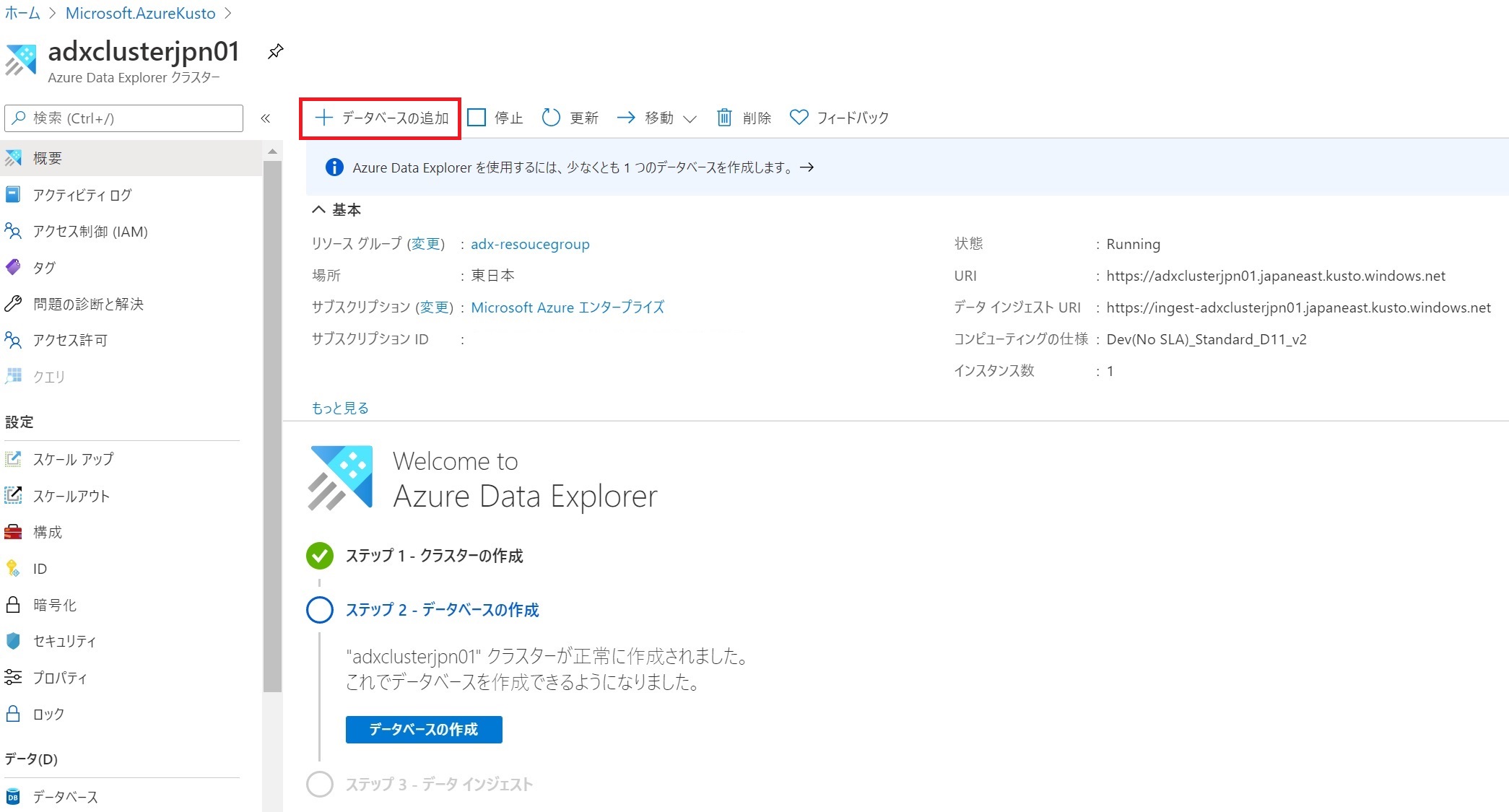
- 「データベースの作成」をクリックする。
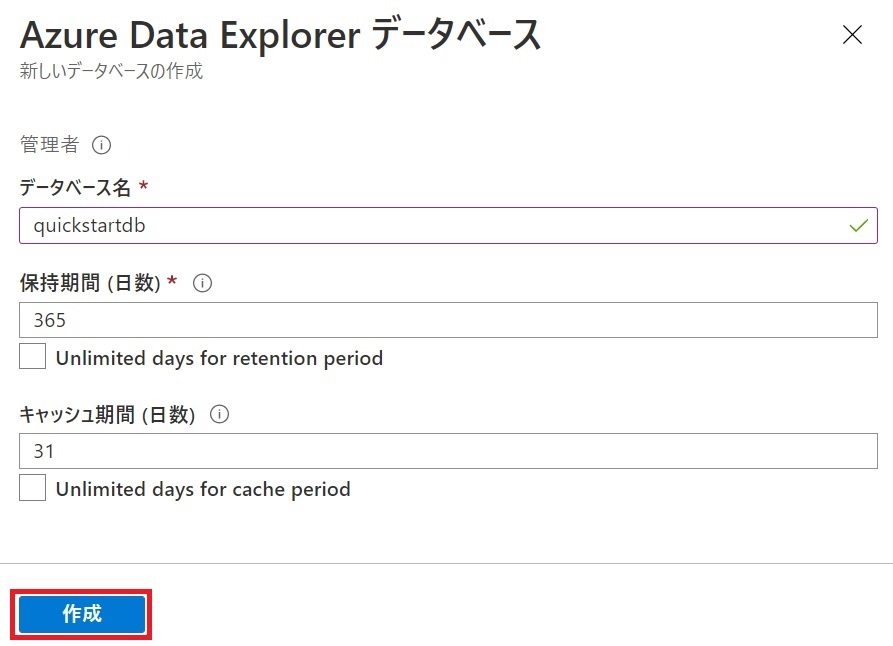
- データベース作成に必要な項目を入力する。入力が終わったら「作成」をクリックしてデータベースを作成する。保持期間とキャッシュ期間は課金額に影響する。テストで使うときには、それぞれ31日と7日のように小さくすると良いだろう。
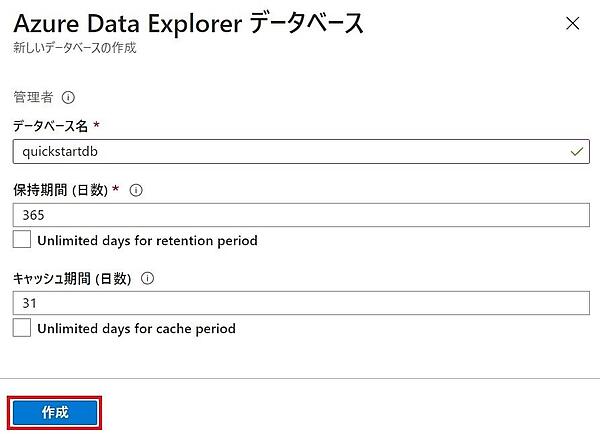
項目 説明 データベース名 クラスター内で一意の名前 保持期間 データを取り込んでから、検索対象とするデータの範囲。この期間を過ぎると検索できなくなる。データはBlob Storageに格納され、コールドキャッシュともいう キャッシュ期間 取り込んだデータをSSDもしくはメインメモリに保持する期間。よく検索するデータの範囲を指定する。ホットキャッシュともいう。この期間を超えるとコールドキャッシュに移動される - 作成が終わると、次の画面が表示される。「Ingest new data」ではワンクリック・インジェストと呼ばれる対話形式でデータ収集方法を設定できる。「データ接続を作成する」では、データソースとなるBlob StorageやEvent Hubsとのコネクションを定義できる。今回は何もしないで次に進む。


Azure Portalの管理機能を理解する
Azure Data Explorerには、以下の2種類のWeb UIがある。
- 管理者権限を持つユーザーが使用する「Azure Portal(portal.azure.com)」
- 一般ユーザーがクエリを実行する「Azure Data Explorer Web UI(dataexplorer.azure.com)」
これまで使用してきたのがAzure Portalで、クラスターやデータベースの作成、スケールアップなどの管理作業に加え、クエリも実行できる。いくつかの機能を紹介しよう。
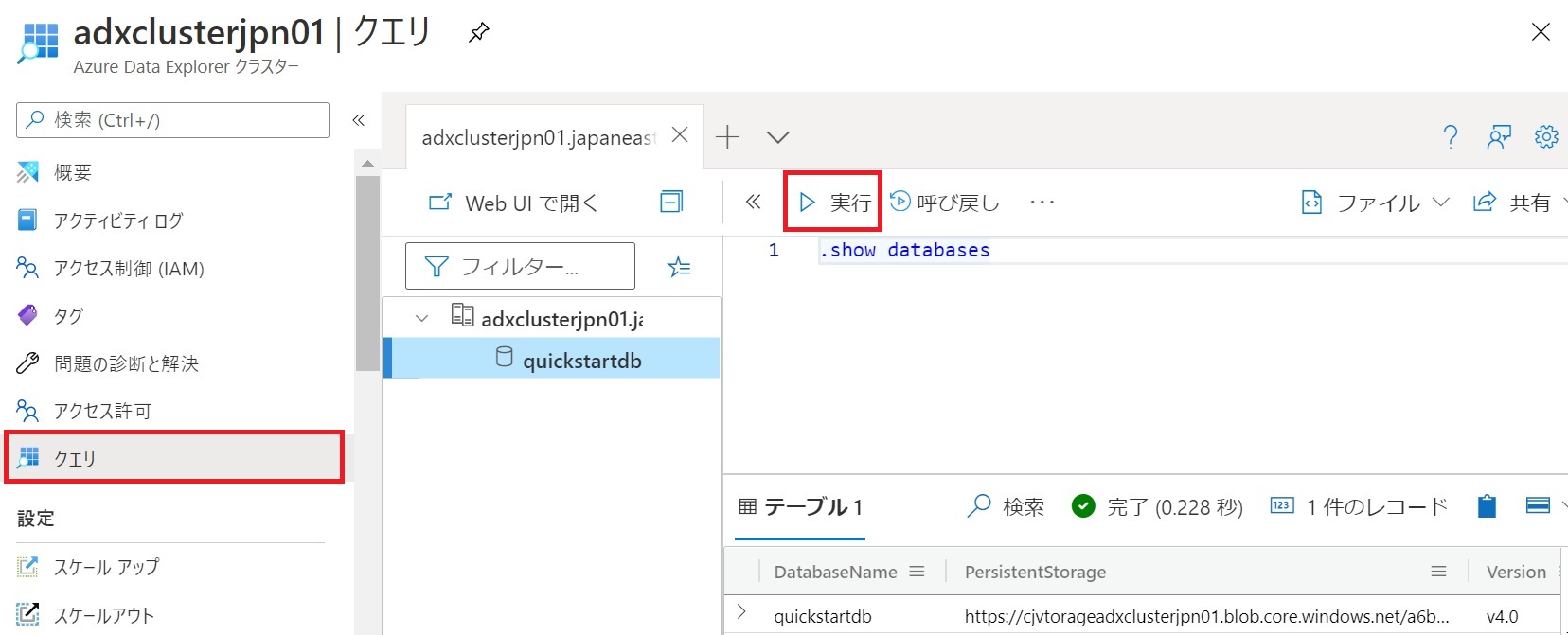
- ページ左の「クエリ」タブをクリックする。
.show databasesコマンドを入力して「実行」をクリックすると、先ほど作成したデータベースが表示される。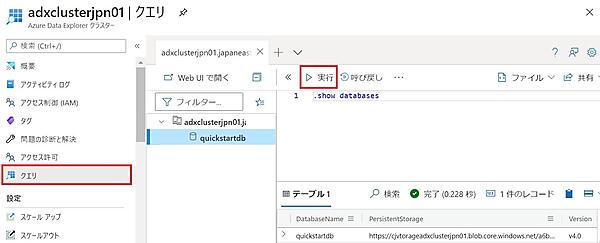
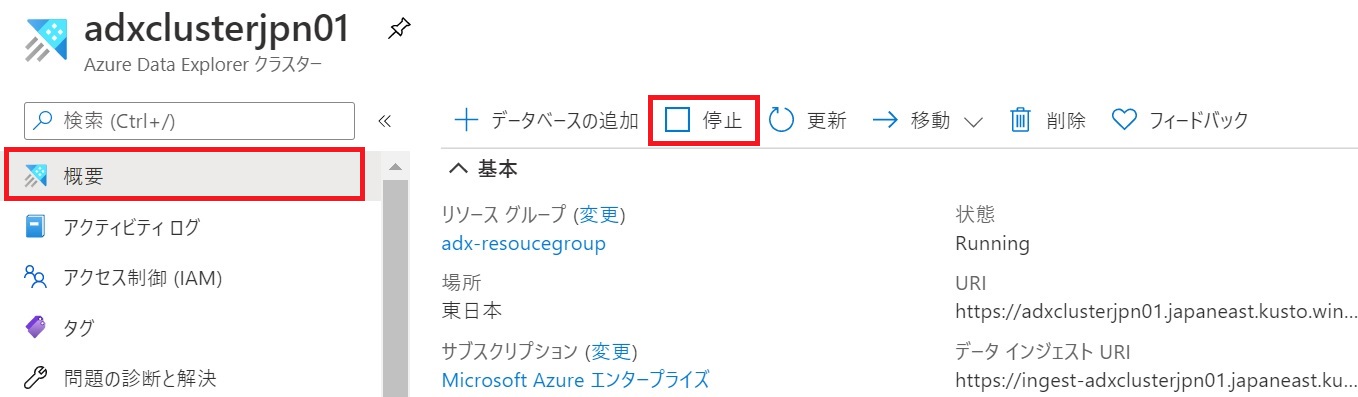
- 「概要」タブで「停止」をクリックするとクラスターを停止できると共に課金も停止できる。ただし、メリット・デメリットがあるので注意すること。メリット:
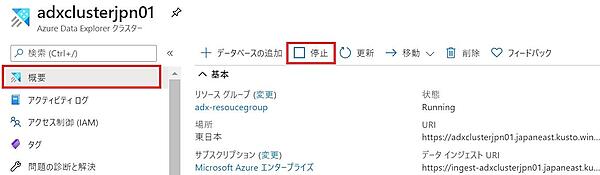
- コンピュートに対する課金を停止できる。ストレージに対する課金は停止しない。
- 再起動後、利用できるようなるまで十数分かかる。データがホットキャッシュに移動し、高速に検索できるには、さらに時間がかかる。
- 取り込み機能を利用しているときには、新しいデータを取り込めない。
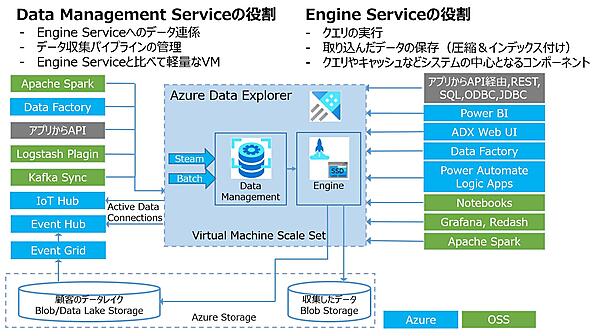
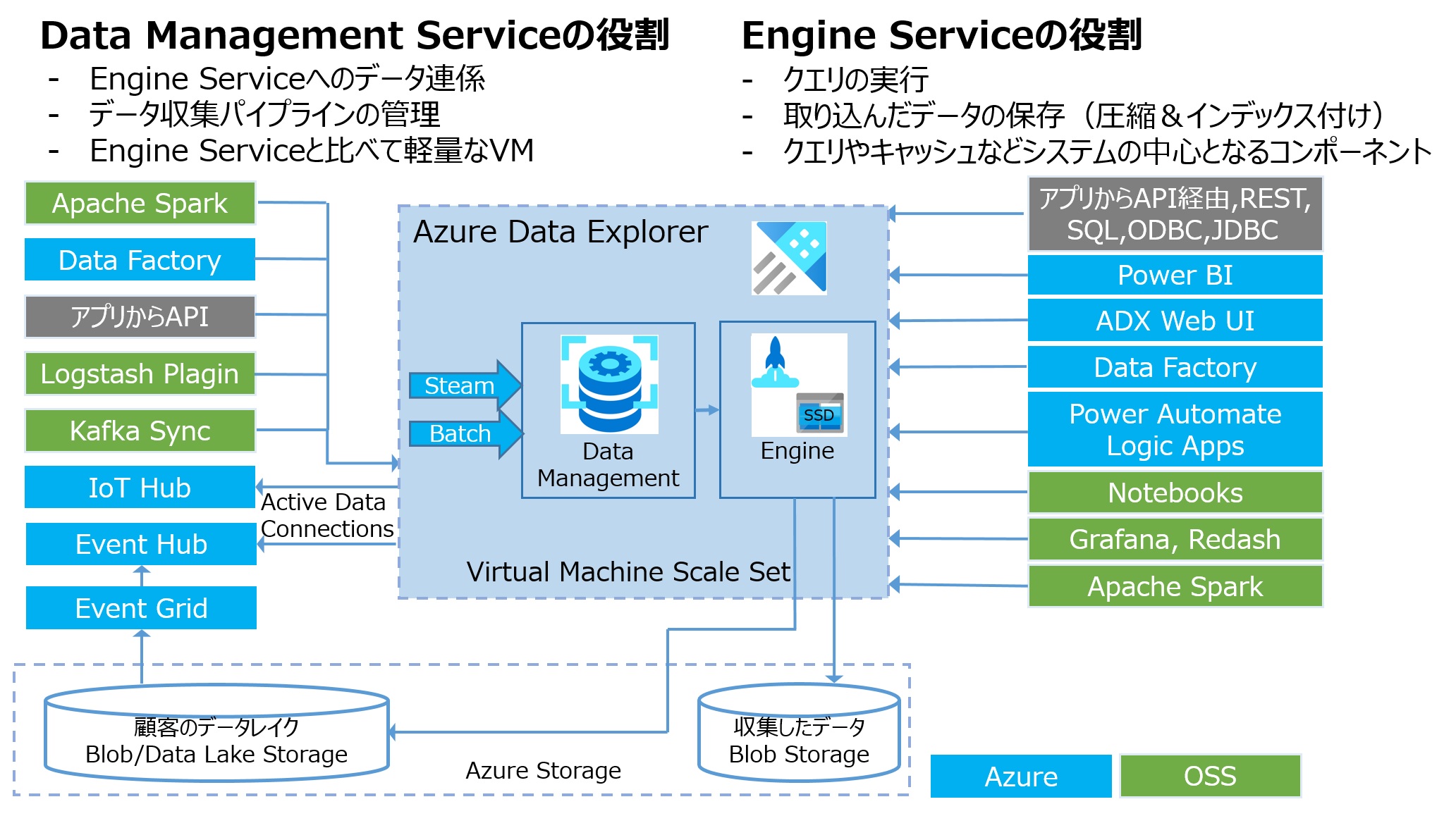
- スケールアップやスケールアウトも簡単に設定できる。下図はAzure Data Explorerのアーキテクチャ図だ。クラスターはEngine用とData Management用の2種類のノードから構成される。本番(Production)用のSKUはそれぞれ2ノード以上で構成されるため、単一障害点(SPOF:Single Point Of Failure)がない構成になっている。
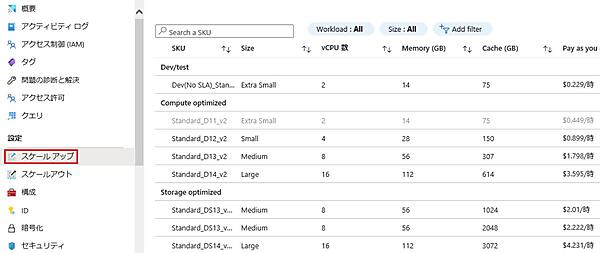
- 「スケールアップ」タブをクリックするとSKUの一覧が表示される。変更にはシステム停止が発生するが、任意のSKUにスケールアップ/ダウンできる。
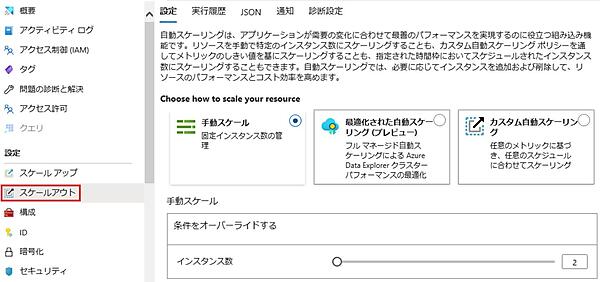
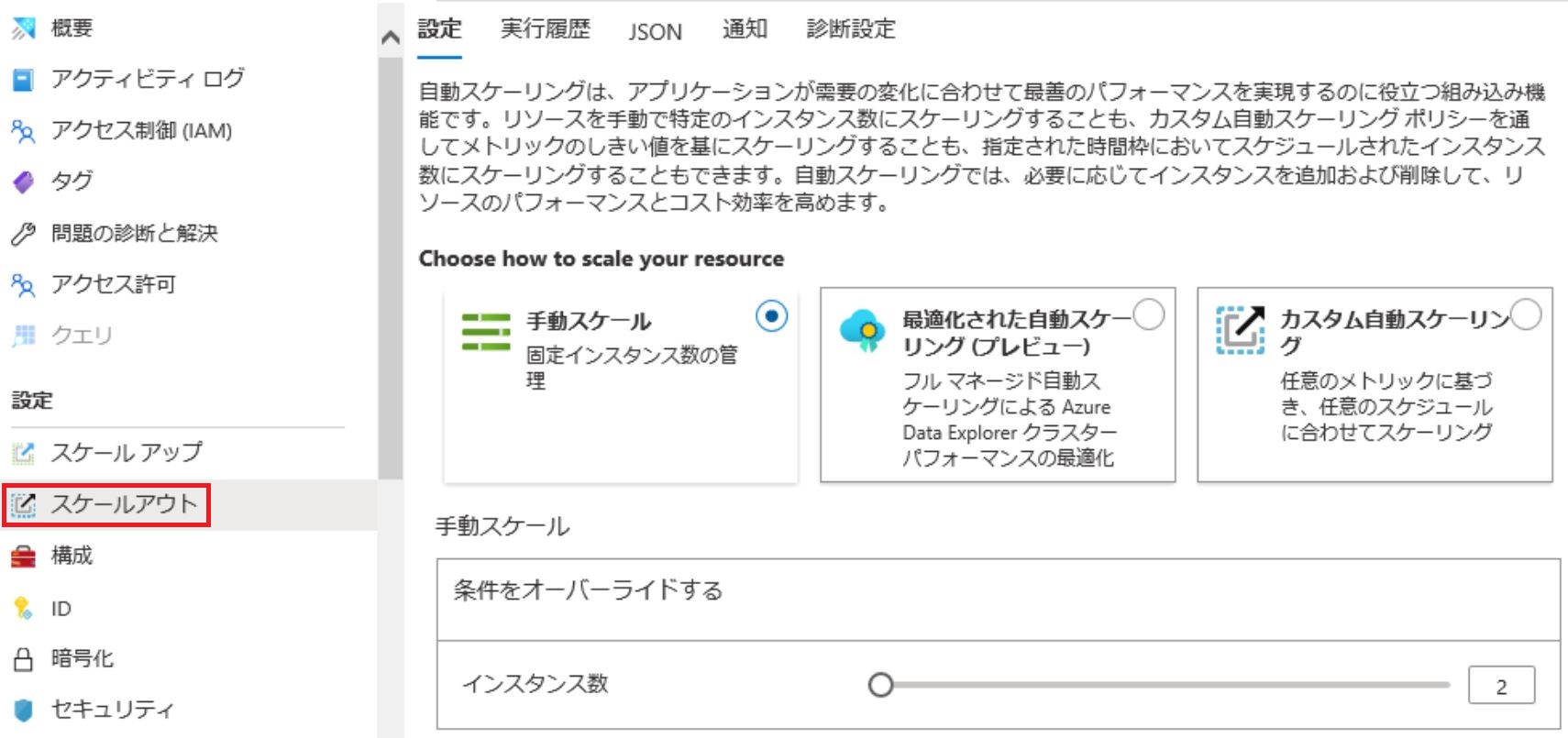
- 「スケールアウト」タブをクリックすると、スケールアウト方法の選択肢が表示される(Dev/TestのSKUでは表示されない)。ここでは手動もしくは自動で水平方向のスケーリングを設定できる。
- Azure Data Explorer管理者の作業は、データ収集や保存期間の設定など、データにかかわる部分が中心であり、システム管理的な作業としては性能管理やエラー監視などがある。
サンプルデータを取り込む
サンプルデータの取り込みは「Azure Data Explorer Web UI」を使用する。これはクエリやデータの取り込みなどができる。なお、サンプルデータには米国のNOAA(National Centers for Environmental Information)が公開している気象データのサブセットを利用する(Microsoft社のサイトにある)。
- Azure Data Explorer Web UIを開くには、Azure Portalの「クエリ」で「対象のデータベース」を選択した状態で「Web UIで開く」をクリックする。
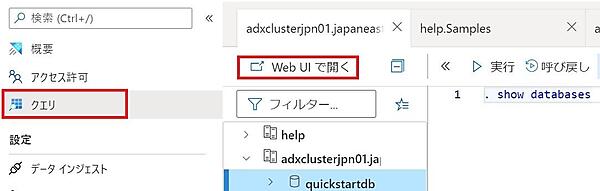
- ブラウザに別タブとして「Azure Data Explorer Web UI」が表示される。
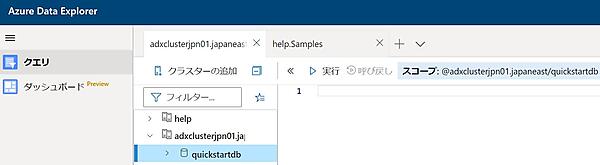
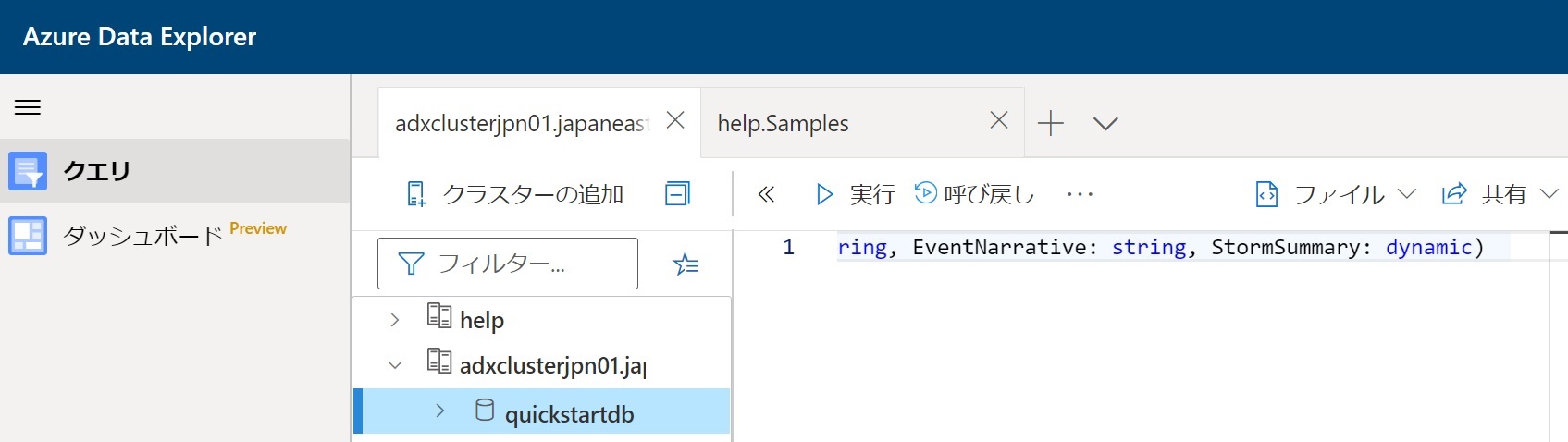
- 次のコマンドを貼り付け、「実行」をクリックしてStormEventsテーブルを作成する。
.create table StormEvents (StartTime: datetime, EndTime: datetime, EpisodeId: int, EventId: int, State: string, EventType: string, InjuriesDirect: int, InjuriesIndirect: int, DeathsDirect: int, DeathsIndirect: int, DamageProperty: int, DamageCrops: int, Source: string, BeginLocation: string, EndLocation: string, BeginLat: real, BeginLon: real, EndLat: real, EndLon: real, EpisodeNarrative: string, EventNarrative: string, StormSummary: dynamic)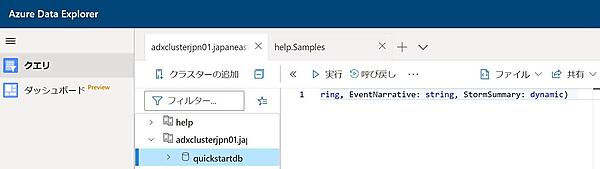
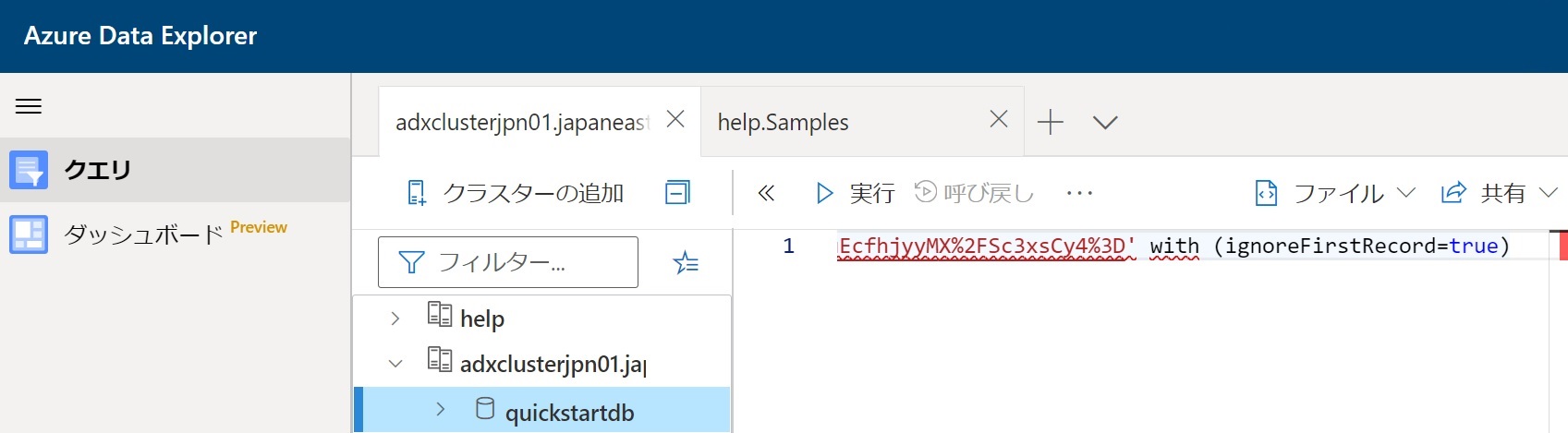
- 次のコマンドを貼り付け、「実行」をクリックしてデータを取り込む。
.ingest into table StormEvents h'https://kustosamplefiles.blob.core.windows.net/samplefiles/StormEvents.csv?sv=2019-12-12&ss=b&srt=o&sp=r&se=2022-09-05T02:23:52Z&st=2020-09-04T18:23:52Z&spr=https&sig=VrOfQMT1gUrHltJ8uhjYcCequEcfhjyyMX%2FSc3xsCy4%3D' with (ignoreFirstRecord=true)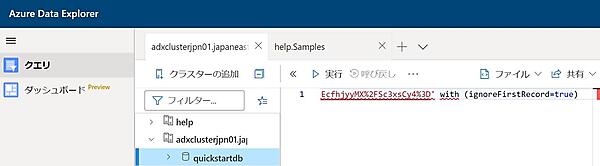

クエリを実行する
サンプルデータを取り込んだのでクエリを実行しよう。ここで使用しているのが「Kustoクエリ言語(KQL:Kusto Query Language)」だ。SQLに似た文法を持ち、パイプ記号でつなげていくだけなので、SQLよりも簡潔に記述できる。また、一部制限はあるが、SQLからKQLに変換する機能もある。なおKustoは、Azure Data Explorerの開発コード名だ。
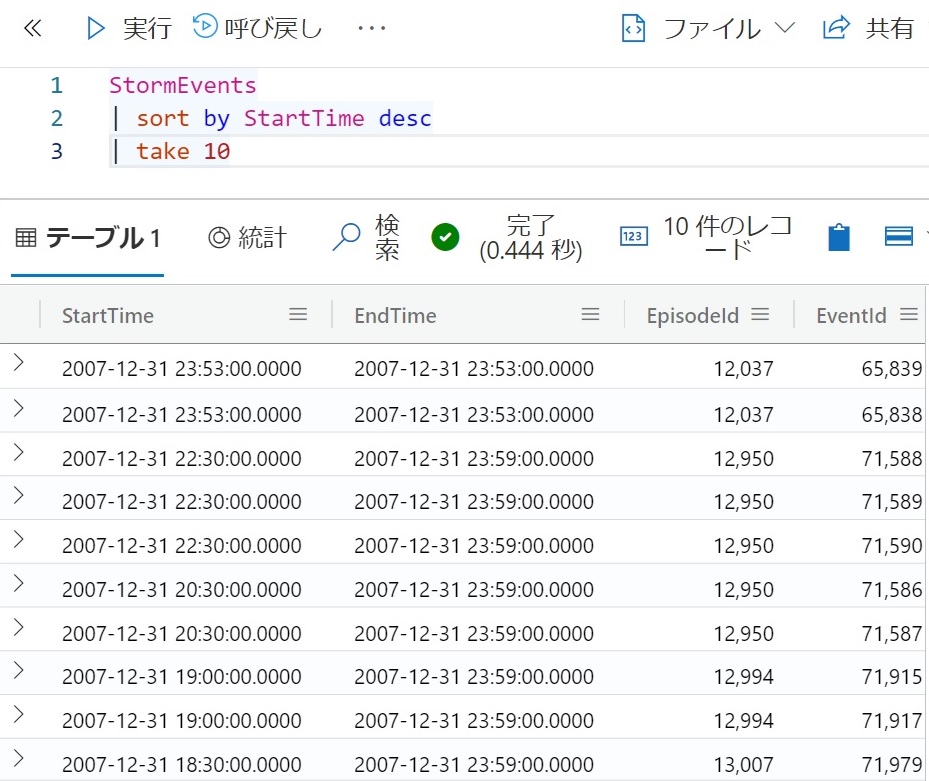
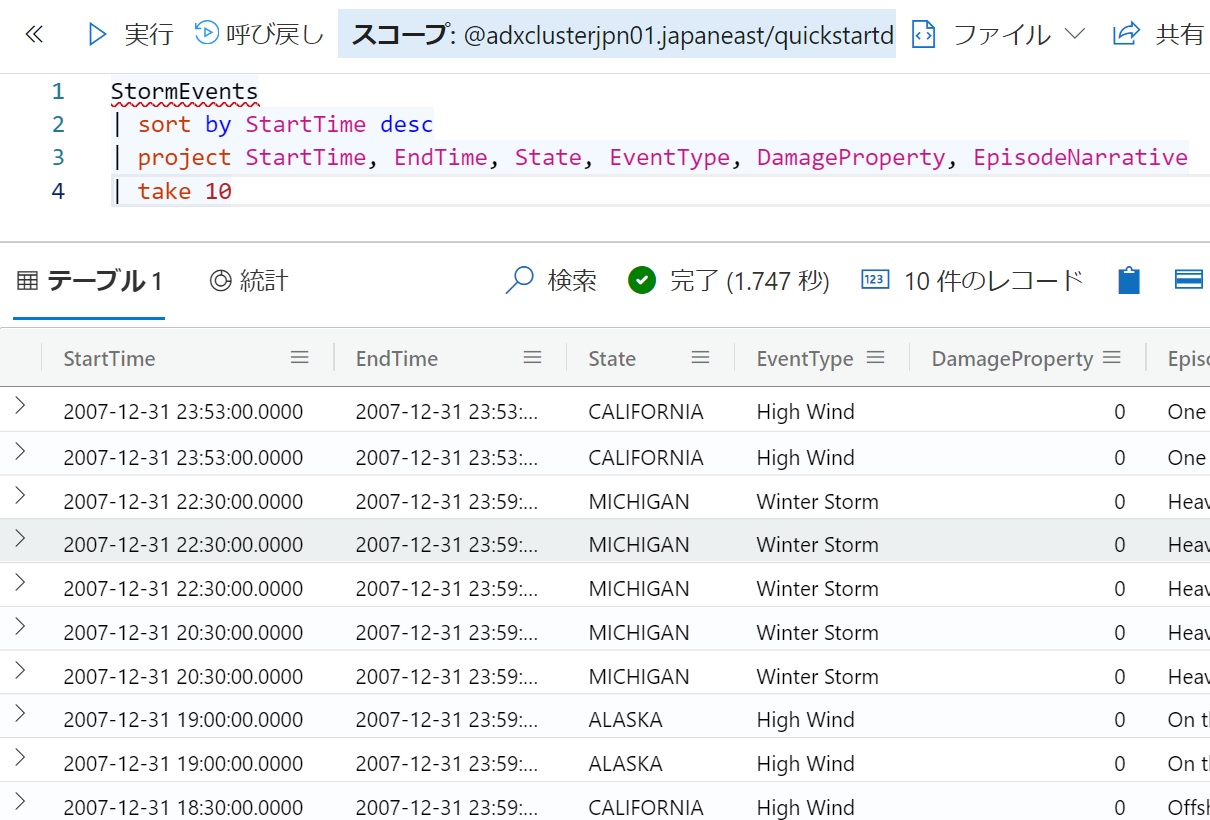
- 取り込みが完了したら、次のクエリを貼り付けて「実行」をクリックする。この例ではStartTime列を降順に10件のデータを取り出している。
StormEvents | sort by StartTime desc | take 10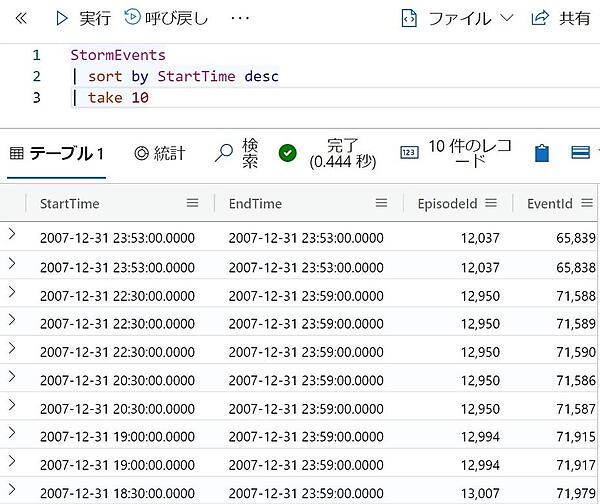
- 次の例ではprojectステートメントで取り出す列を指定している。
StormEvents | sort by StartTime desc | project StartTime, EndTime, State, EventType, DamageProperty, EpisodeNarrative | take 10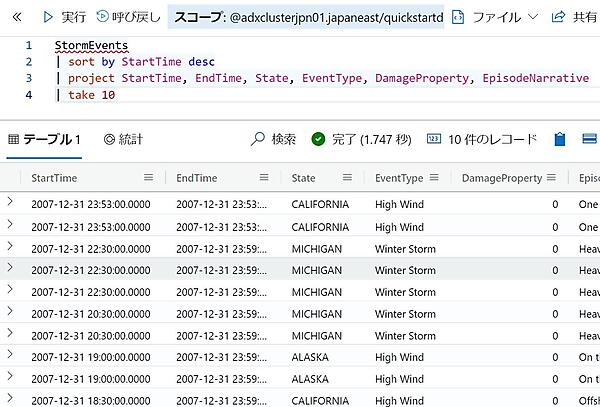
- テーブルのグリッドを利用するとExcelライクなソートやグループ化なども可能だ。

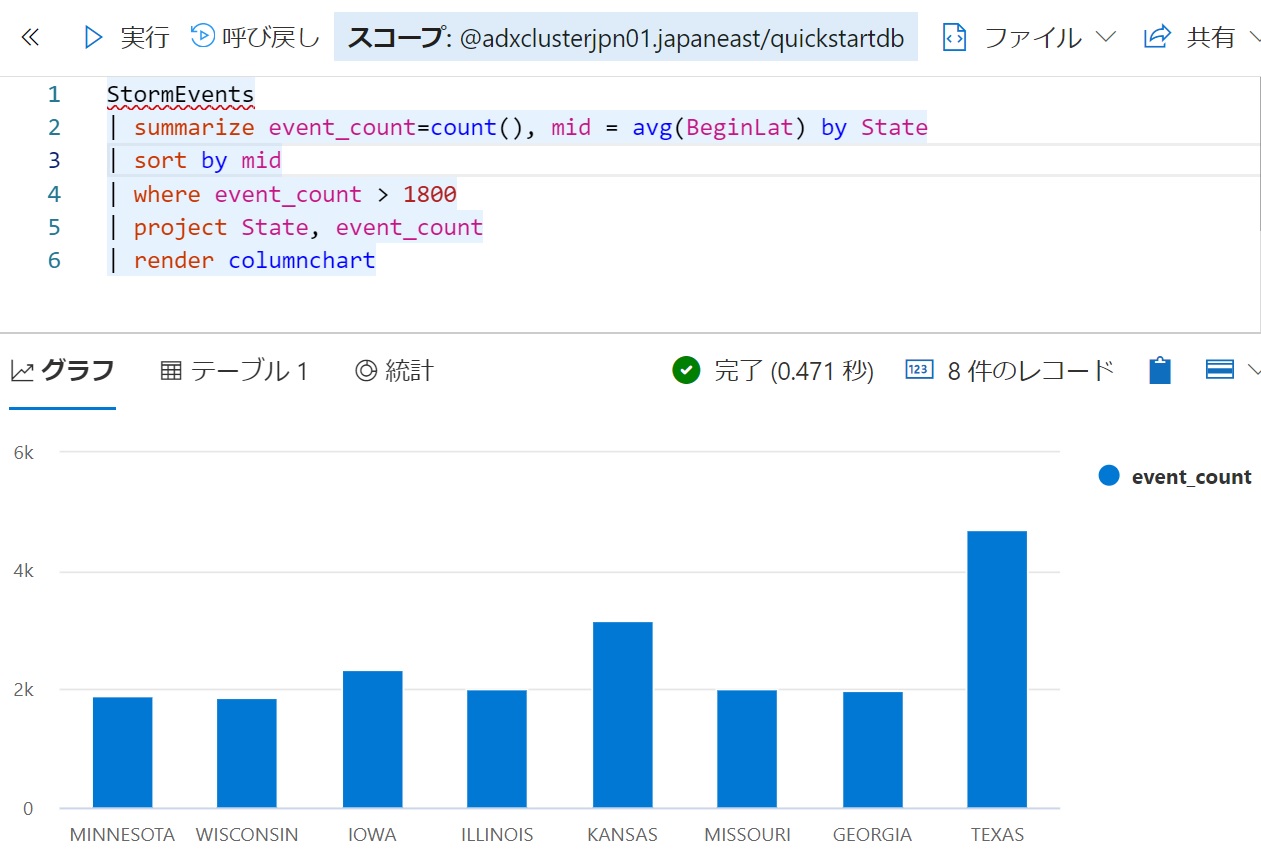
- 次の例では最終行のrenderで結果をグラフ化している。今回は棒グラフを使用しているが、十種類以上のグラフをサポートしている。
StormEvents | summarize event_count=count(), mid = avg(BeginLat) by State | sort by mid | where event_count > 1800 | project State, event_count | render columnchart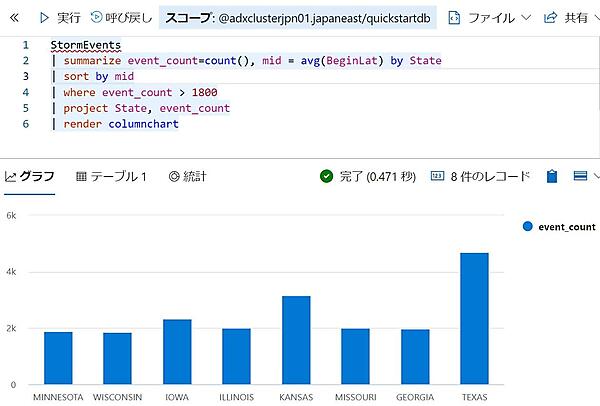
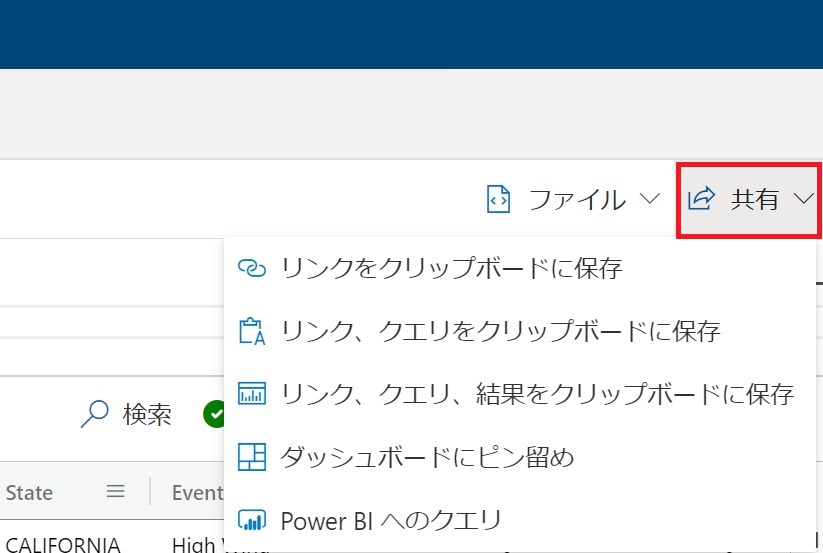
- 右上の「共有」を使うと、クエリやクエリ結果をURLリンクとしてほかのユーザーに渡したり、 Power BIのクエリとして出力したりできる。
これでAzure Data Explorerの基本機能をひと通り使ったことになる。データ取り込みから検索まで、とても簡単にできることがわかっただろうか。次に「集める」「検索する」「ビジュアル化する」のそれぞれについて、もう少し詳しく解説する。
Azure Data Explorerでデータを集める
「データ収集」もしくは「データ取り込み」とは、1つ以上のデータソースからデータを読み取り、Azure Data Explorerのテーブルにロードするまでの手順全体のことを指す。データをAzure Data Explorerにロードすることで、初めて検索できるようになる。下図は、データ収集の全体像を表したものだ。
ここでは、Azure Data Explorerで可能なデータ収集方法を紹介する。

データ収集とは
データ収集では、内部的に以下のことが実行され、Data Managementサービスが主体となって機能している。
- データソースへの読み取り要求
外部のデータソースに対して読み取り要求を出す。 - データのインポート
バッチもしくはストリーミングのいずれかの方法でデータを受け取り、データの初期検証や型変換などを実施する。 - ストレージへの保存
ロード先テーブル列へのマッピングやインデックス付け、圧縮などが行われストレージに格納される。
ログデータなどを収集することを「インジェスト(ingest[動詞])」もしくは「インジェスチョン(ingestion[名詞])」と言うことがある。本来の意味は「(食べ物などを)摂取する、飲み込む」だが、従来のキャプチャーやインポートと似た意味で使われている。
上記のように手順を分解すると、インジェストのほうが全体像を的確に表しているように感じるのではないだろうか。Azure Data Explorerのドキュメントでは「ingest(日本語訳:取り込む)」と書かれている。
サポートするデータフォーマット
サポートする主なデータフォーマットは以下とおり。GZipもしくはzipで圧縮されていても構わない。AvroはKafkaやHadoopなどで使用する行指向フォーマットで、OLTPやストリームデータを扱うのに適している。ParquetやORCは列指向フォーマットで、Hadoopエコシステムのバッチ処理で使用することが多い。
- CSVなどのテキストファイル
- JSON
- 行指向フォーマット(Avro)
- 行指向フォーマット(Parquet、ORC)
データの収集方法
データ収集方法は「バッチ収集」と「ストリーム収集」を選択できる。どちらを使用するかはシステムの目的次第だ。また、収集ポリシーを設定すると自動でデータを収集できる。
| バッチ収集 | ストリーム収集 | |
|---|---|---|
| 特徴 | スループット重視で、大量データを高速に収集 | レイテンシ重視で、より早くメッセージ受信 |
| レイテンシ | 収集間隔(5分以上)に依存 | 10秒以内 |
| 1回のデータ量 | 多い(1回あたり1GB以下が推奨) | 少ない |
| データソース | Azure Data Explorerが対応している必要がある | 左記に加え、データソースがストリーム収集に対応している必要がある |
Azure Data Explorerは、さまざまな収集方法をサポートしており、収集元となるターゲットの種類や、データ収集の目的に応じて最適なものを選択できる。代表的な方法を紹介しよう。
マネージドパイプラインを利用
外部ソースとのコネクタ機能を持つ以下のようなサービスを利用する方法だ。それぞれが監視やリトライ、流量調整などの機能を持っているので、容易にパイプラインを構築できる。
- Event Hubs
さまざまなデータソースからリアルタイムにデータを収集。 - IoT Hub
対応しているIoTデバイスから流れてくるストリームデータを収集。 - Event Grid
オブジェクトストレージにファイルが配置されたら起動するような、イベントを契機としたデータ収集。 - Data Factory
Data FactoryはAzureのETLサービスだ。90以上のデータソースをサポートしているので、Amazon S3やAmazon Redshift、Google BigQueryなどにアクセスできる。変換機能もあるので高度な前処理も可能だ。またAzure Data ExplorerとData Factoryは密接な関係があり、一緒に利用することが多い。
コネクタやプラグインを利用
Azure Data Explorerが用意する以下のコネクタやプラグインを利用する方法だ。既存のデータ収集基盤やHadoop基盤を活用できる。
- Logstash
- Kafka
- Power Automate(Microsoft社のRPAサービス)
- Synapse Analytics
- Apache Spark(Databricks含む)
SDK
以下のSDKやAPIをサポートしている。定型処理などはプログラムにすることで処理の効率化が図れる。
- Python
- .NET
- Java
- Node.js
- Go API
- REST API
ツールやコマンド
Azure Data Explorerが提供するツール類だ。ワンクリック・インジェストでデータ収集を対話形式により簡単に設定できる。LightIngestはBlob Storageからデータを取り込むコマンドラインツールだ。Kustoクエリ言語の制御コマンドは、今回はデータをロードするときに使用したが、プロトタイプやテストに適した方法だ。
- ワンクリック・インジェスト
- LightIngest
- Kustoクエリ言語の制御コマンド
外部テーブルとは
外部テーブルは、Blob StorageやData Lake Storageなどに格納しているデータに直接アクセスする方法だ。データ収集方法とは少し異なるが、重要な機能なので紹介する。
Azure Data Explorerの高速性を発揮するには、テーブルにデータを取り込む必要がある。これが原則だ。しかし、外部テーブルを使うと、データを取り込まずに外部データを直接クエリできる。それほど性能が求められないときや、データを取り込む前に参照したいときなどに便利だ。
外部テーブルは、データのエクスポート先としても使用できる。ほかのシステムとデータ連係したいときに便利だ。また、大規模バッチなどAzure Data Explorerが苦手な処理を、Apache Sparkやデータウェアハウスなどの他システムにオフロードするときにも利用できる。
外部テーブルがサポートしているデータソースは以下のとおり。
- Azure Blob Storage
- Azure Data Lake Storage
- Azure SQL Database(SQL Server)
Azure Data Explorerでデータを検索する
Azure Data Explorerの強みの1つは、Kustoクエリ言語があることだ。SQLライクな言語で、SQLと同じようなことができる。SQLよりも優れた点は、読み書きしやすく、グラフ化などの便利機能があることだ。ここではKustoクエリ言語で、どのようなことができるのかを解説する。
クエリツール
Kustoクエリ言語を実行するには、以下のツールがある。Azure Data Explorer Web UIは先ほど紹介したWebアプリケーションだ。Kusto.ExplorerはWindowsのデスクトップアプリケーションで、よりリッチなインターフェースを利用できる。Kusto.cliはコマンドラインツールで、対話的に実行できるだけでなく、C#やPowerShellなどのスクリプトと連携できる。
- Azure Data Explorer Web UI
- Kusto.Explorer
- Kusto.cli
Kusto.Explorerのスクリーンショット
Kustoクエリ言語とは
Kustoクエリ言語(KQL:Kusto Query Language)は検索専用の言語だ。SQLと似た部分もありながら「可読性が高い」「変更しやすい」「簡単にグラフ化できる」「ログ探索でよく使用する関数群が充実している」という特徴を持っている。
SQLを書いたことがある人ならわかると思うが、複雑なSQLは何をやっているかわかりづらいし、ちょっとしたwhere条件の追加も難しい。ところが、Kustoクエリ言語はやりたいことをパイプで接続するのが基本だ。そのため読みやすいだけでなく変更もしやすい。
ほかにもデータ探索やログ探索で使用する集計関数やウインドウ関数、時系列分析、機械学習、地理空間などの関数が充実している。そしてrenderを使えば、結果を簡単にグラフ化できる。renderは十種類以上のグラフをサポートしている。制限はあるが、SQLからKustoクエリ言語の変換機能もある。
それでも「なぜSQLではなくKustoクエリ言語なのか」と思う人もいるだろう。Kustoクエリ言語は、Azure MonitorのLog AnalyticsやApplication Insightsなどでも利用できる。Azureを使用するならば、覚えて損はないはずだ。公式ドキュメントにはSQLとの対比表が載っている。
Kustoクエリ言語のサンプル
いくつかサンプルを紹介しよう。次の例では、最初に対象となるテーブルStormEventsがあり、whereやsortをパイプ記号でつなげている。takeは取得数する行数だ。最後のprojectは取得する列名である。SQLを知っている人ならすぐにわかるだろう。
StormEvents
| where EventType == 'Flood' and State == 'WASHINGTON'
| sort by DamageProperty desc
| take 5
| project StartTime, EndTime, State, EventType, DamageProperty, EpisodeNarrative
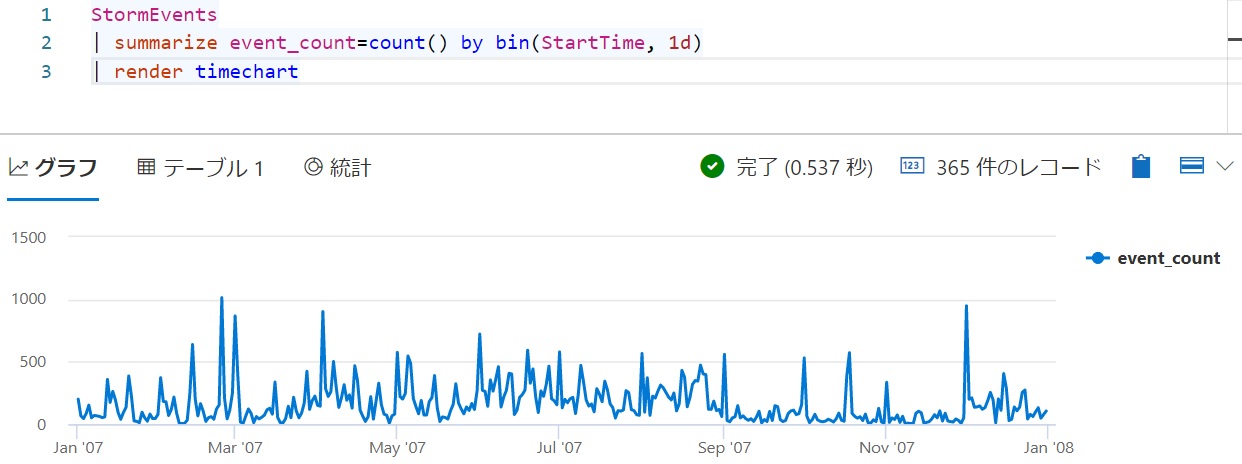
次の例は、嵐が発生した回数を1日ごとに集計している。
StormEvents
| summarize event_count=count() by bin(StartTime, 1d)
グラフ化するときはrenderでグラフの種類を指定する。
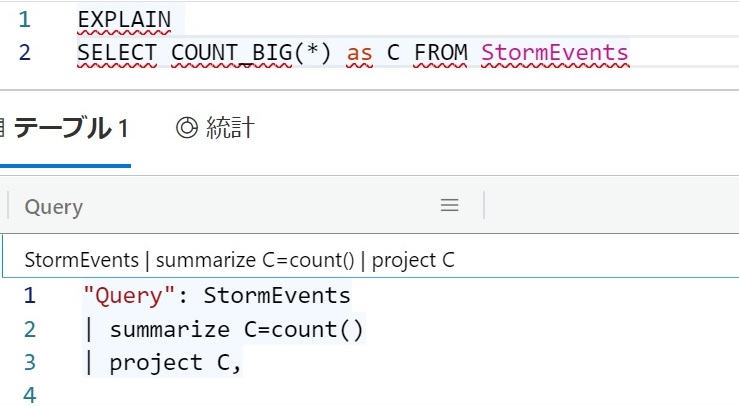
SQLからの変換機能もある。次のようにEXPLAINをつけると変換できる。
SQLにはない記述として、次のように列名を指定しない方法がある。この例では、すべての列に対して"Snow"という文字を検索している。
StormEvents
| search "Snow"
Kustoクエリ言語が作られた理由
データ分析におけるデータ探索では、インサイトを得るために条件や視点を変更してクエリを繰り返し実行する必要がある。トラブルシュートやユーザーサポートなどのログ探索では、時間帯や検索対象文字、エラーの発生回数など、条件を変更しながら障害原因を突き止める。
これらの作業では、対象となるテーブルやwhere、group byなどの条件を少しずつ変更しながら、繰り返しクエリを実行する。そして結果を直感的に理解するにはグラフ化も欠かせない。Kustoクエリ言語は、これらの要求を満たすために作られた言語と言える。
Kustoクエリ言語ができないこと
Kustoクエリ言語は検索専用の言語だ。そのためSQLのINSERTやUPDATE、DELETEに相当する操作はできない。次の表はSQLとの比較だ。きわめて割り切った設計であることがわかる。
| 命令 | 内容 |
|---|---|
| SELECT(検索) | Kustoクエリ言語 |
| INSERT(挿入) | パイプラインやプラグインによるインジェストや、Azure Data Explorer制御コマンド |
| UPDATE(更新) | 不可 |
| DELETE(削除) | 保存期間を超えたデータの削除もしくはテーブルごと削除。GDPR対応のデータ削除(再編成) |
Azure Data Explorerでは検索と追記だけができる。一般的なデータベースに存在するトランザクション機構を大幅に省略することで高速化を実現しているのだ。
下記に挙げる、検索以外の操作はAzure Data Explorer制御コマンドで実施する。興味深いのはインデックスに関するコマンドがないことだろう。自動作成するので不要なのだ。
- データベースの管理
- テーブルの管理
- データのエクスポート
- データのインジェスト
- アクセス制御
Azure Data Explorerでデータをビジュアル化する
データのビジュアル化は、データ分析やレポート作成では欠かせない。Azure Data Explorerでビジュアル化するには以下の方法がある。これまで説明していなかったダッシュボードと、対応するBIサービスを紹介する。
- Kustoクエリ言語のrender
- Azure Data Explorerのダッシュボード
- 対応するBIサービスやツール
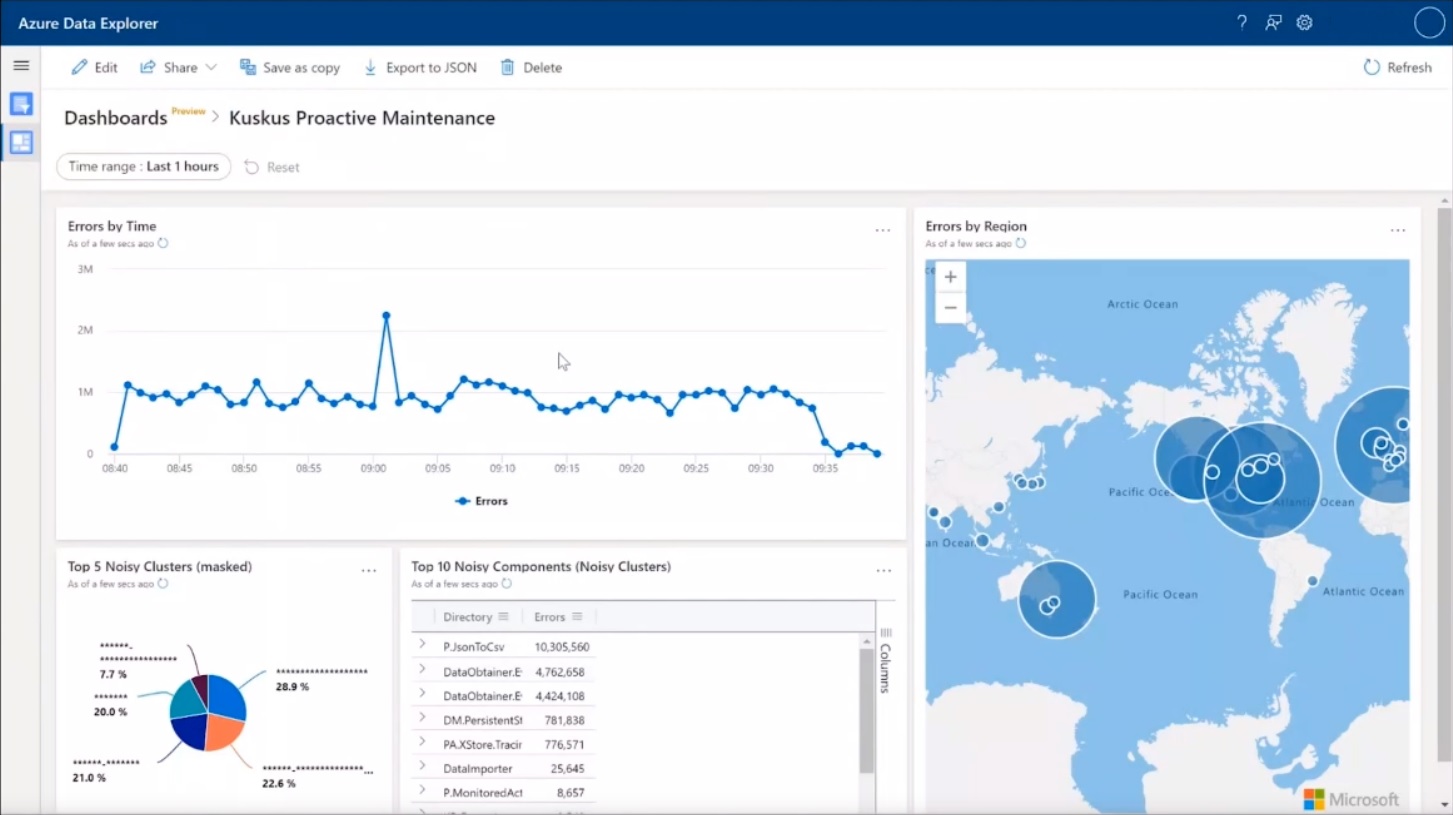
Azure Data Explorerのダッシュボード
ダッシュボードは、Azure Data Explorer Web UIが提供する機能だ。定義したクエリを埋め込み、複数のグラフを表示できる。
対応するBIサービスやツール
使い慣れたツールでAzure Data Explorerに格納したデータを検索/表示できる。特にBIツールは表現力に優れており、使いやすいものが多い。
アクセスするには、Azure Data Explorer用のコネクタやプラグインを使う方法と、ODBCやJDBCなどの汎用コネクタを使う方法がある。前者のAzure Data Explorerに対応したツールには、Kustoクエリ言語を埋め込み、シームレスに利用できるものもある。以下に紹介するツールは一例だ。
- Excel
- Power BI
- Kibana
- Grafana
- Tableau
- Qlik
- Sisense
- Redash
- Jupyter Notebook
Azure Data Explorerを管理する
Azure Data Explorerの管理について少し解説する。フルマネージドサービスなので、一般的なデータベースと比べると管理作業は少ない。管理者が実施する作業として以下のものがある。いずれもAzure Portalで容易に管理できる。
- 性能管理(スケールアップ/スケールアウトなど)
- 正常性の管理(各種エラーの有無など)
- アクセス制御などセキュリティ管理
- データの保存期間
- トラブルシュート
- 可用性の設計
1つ注意すべきは可用性の設計だ。本番用のSKUならば単一障害点がないように設計されている。しかし、可用性ゾーン(AWSのAZ相当)やリージョン障害に対応するには、別途設計が必要になる。詳しくは公式ドキュメントの「事業継続とディザスター リカバリーの概要」を参照してほしい。
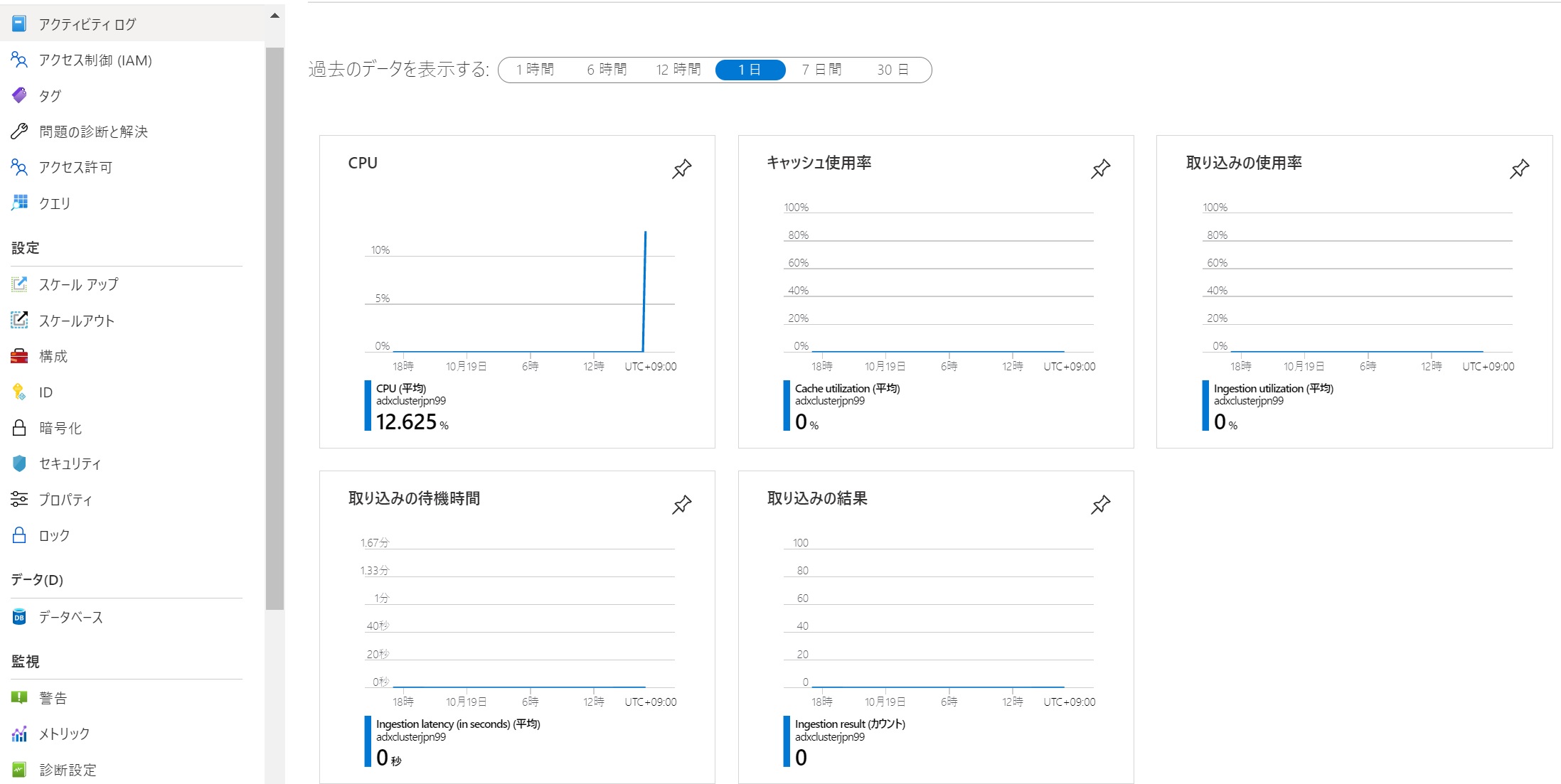
Azure Portalの管理画面では使用状況などを表示できる
おわりに
Azure Data Explorerは完全に類似するサービスがないため、その良さを理解するのに時間がかかるかもしれない。強いて挙げれば、Splunkが似ているだろうか。正直なところ、筆者もAzure Data Explorerの良さを理解するには時間がかかった。
そして調査を進めるたびに、Microsoft社の本気を感じるサービスだ。Azureの各種サービスでの利用が広がっているし、機能やドキュメントの進化も早い。また、さらに高速化した次世代クエリエンジンEngineV3のプレビュー提供が開始され、より安価なAMD EPYCのSKU提供も始まっている。
以下のような、大量のIoTテレメトリデータやログデータ、時系列データが発生するシステムならば、利用を検討しても良いだろう。
- ミッションクリティカルなシステムの監視
- 大量のIoTデータの分析
- データ分析時のデータ探索における傾向や異常値の発見
- アプリケーションのログ分析によるカスタマーエクスペリエンス向上
また、以下のサイトが参考になる。英語だがPluralsightの動画コンテンツはオススメだ。
次回はまとめとして、Azure Data ExplorerのFAQやGoogle BigQueryやAmazon Athenaなどとの比較を解説する。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者


筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
