Azure Data Explorerと各社のビックデータ分析サービスを比較する
2020年12月4日 6:46
はじめに
前回まで、ビッグデータ分析の基礎知識とAzure Data Explorerについて解説した。今回は最終回として、これまでをふりかえると共に、Google BigQueryやAmazon Athenaと比較し、それぞれの違いを明らかにする。
これまでのふりかえり
これまでの連載を簡単にふりかえる。
イントロダクション
- データ活用分野は、基幹系システムと比べてクラウドを導入しやすいため、クラウドベンダーはサービス開発に力を入れている。
- 同一分野のサービスでも、それぞれアピールポイントが異なるため、以前の競合比較のような同一軸での比較は困難になっている。さらに、同一ベンダーのサービスでも機能がオーバーラップし、複雑な状況になっている。
データウェアハウスとデータレイク
- データウェアハウスは、主に基幹系システムのデータを分析目的に応じて加工・格納し、意思決定支援に用いる検索中心のシステムを指す。検索に特化した専用データベースを使用することが多い。
- データレイクは、構造化データだけでなく、半構造化データや非構造化データも対象にし、より生データに近い形で保存することで、さまざまな用途に役立てることを目的としている。「非構造化データにも対応」「サイズ制限なし」「高信頼性」「低価格」という特性から、データ格納先にはオブジェクトストレージを使用することが多い。
- データレイクのデータは生データなので、そのままでは扱いづらいことが多い。そのため、データレイクのデータを加工・整形して、データウェアハウスやデータマート、Apache Sparkなどにロードして利用することも多い。データウェアハウスとデータレイクは背反する概念ではなく、使い分けるものだ。
バッチ処理とストリームデータ処理
- ストリームデータ処理は、IoTのテレメトリデータやWebアプリケーションログなど、絶えず発生するデータをリアルタイムに近い時間で処理する技術である。
- 工場や農業のIoTセンサーを使ったモニタリングや不正アクセス検知など、リアルタイムに近い対応が求められる分野で利用されている。
- バッチ処理では、数時間から数日、数カ月に発生した大量データを処理する。それに対して、ストリームデータ処理では、数ミリ秒から数分程度に発生した小さなデータを素早く取り込むのと同時に、即座に検索できることが重要になる。
データ分析の基礎
- データ分析で最も大切なのは、分析の目的や目標を決める「企画」フェーズである。
- 次に実施する「データ探索」フェーズでは、対象となるデータを調査し、データ分布やパターンの有無などを調べ、データ分析に利用できるか確認するとともに、データの加工方法(集計軸など)を決定する。データ分析全体では、前処理に相当するフェーズだ。ここで方向性を間違うと、後続のフェーズに影響を与え、正しい分析が困難になる。
Azure Data Explorerとは
- Azure Data Explorerは、ログデータやIoTテレメトリデータなど、大量に発生するストリームデータをリアルタイムに収集・分析するサービスである。
- フルマネージドサービスなので簡単に使い始められ、インメモリ技術とクラスターアーキテクチャによって高速なクエリを実現できる。
- Kustoクエリ言語はSQLよりもわかりやすく、ビジュアル化も容易にできる。
- 強力なデータ取り込み機能と外部連携機能を利用して、データ活用基盤を構築できる。
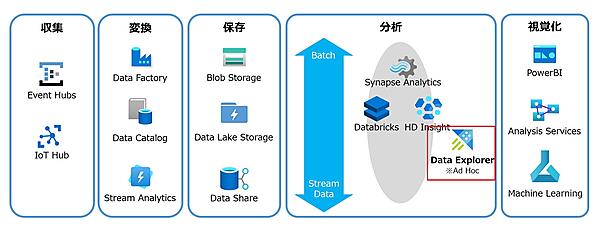
各社のサービスを比較する
Azure Data Explorerと、他社サービスであるGoogle BigQueryとAmazon Athenaを比較する。これまで連載を読んできたかたや他社サービスに詳しいかたは「アップルトゥアップル(Apple to Apple)」の比較でないことがわかるだろう。
第1回「各クラウドベンダーのDXへの取り組み」でも述べたとおり、各クラウドベンダーの取り組みは激しい競争となっている。そのため同じジャンルの製品・サービスでも、それぞれに味付けがなされ、同一軸の比較が難しい。何を主体にするかで、比較対象が変わってしまうからだ。
そこで今回は、ログ分析/探索に代表される業務で、大量のログデータに対してアドホックなクエリを実行するという視点でサービスを選択した。
比較ポイント
ログ分析/探索をするうえで、サービスを選択するポイントはいくつかある。以下に代表的なものを挙げた。どれを重視するかは分析の対象や目的次第だ。これらの中から、いくつかポイントを解説する。
- フルマネージドサービスかどうか
- サーバーレスアーキテクチャかどうか
- ストリームデータに対応しているか
- データ収集機能
- 性能
- 費用
- 使用言語
- ビジュアル化機能
- 対応するエコシステム
フルマネージドサービス
データ分析者がやりたいのは分析であってインフラ管理ではない。そのため、できるだけ導入や運用が簡単なものが望ましい。フルマネージドサービスであれば、最小限の手間で導入・運用できる。ビッグデータブームの当初に盛り上がったのはHadoopだ。しかし、運用管理の難しさからオンプレミスの構築は廃れ、現在はクラウドでの利用が主流になっている。
サーバーレスアーキテクチャ
性能や可用性などの非機能要件は、クラウドでも通常は利用者が設計・管理する必要がある。サーバーレスアーキテクチャでは、性能や可用性などはクラウドに任せ、真に使っただけサービスを実現できる。データ分析ではメリットも多いが、利用頻度の高い業務では高価格になりがちだ。サーバーレスサービスは、スキャンしたデータ量に応じた課金のため、よりよりデータモデル構築のためにデータ探索しすぎたら、とんでもない課金になってしまったということは避けたい。
性能
性能は、使用するデータやクエリ内容によって異なるため一概には比較できない。しかし、ログ分析/探索では、問題解決やインサイト獲得のため大量のデータに対して何度もクエリを実行する必要がある。毎回何分もかかっていては分析作業が進まない。できるだけ速いことが望ましい。
Google BigQuery
Google BigQueryは、Google Cloud Platformのサービス群の1つであり、大規模で強固なGoogleインフラストラクチャを利用できるデータウェアハウスサービスだ。
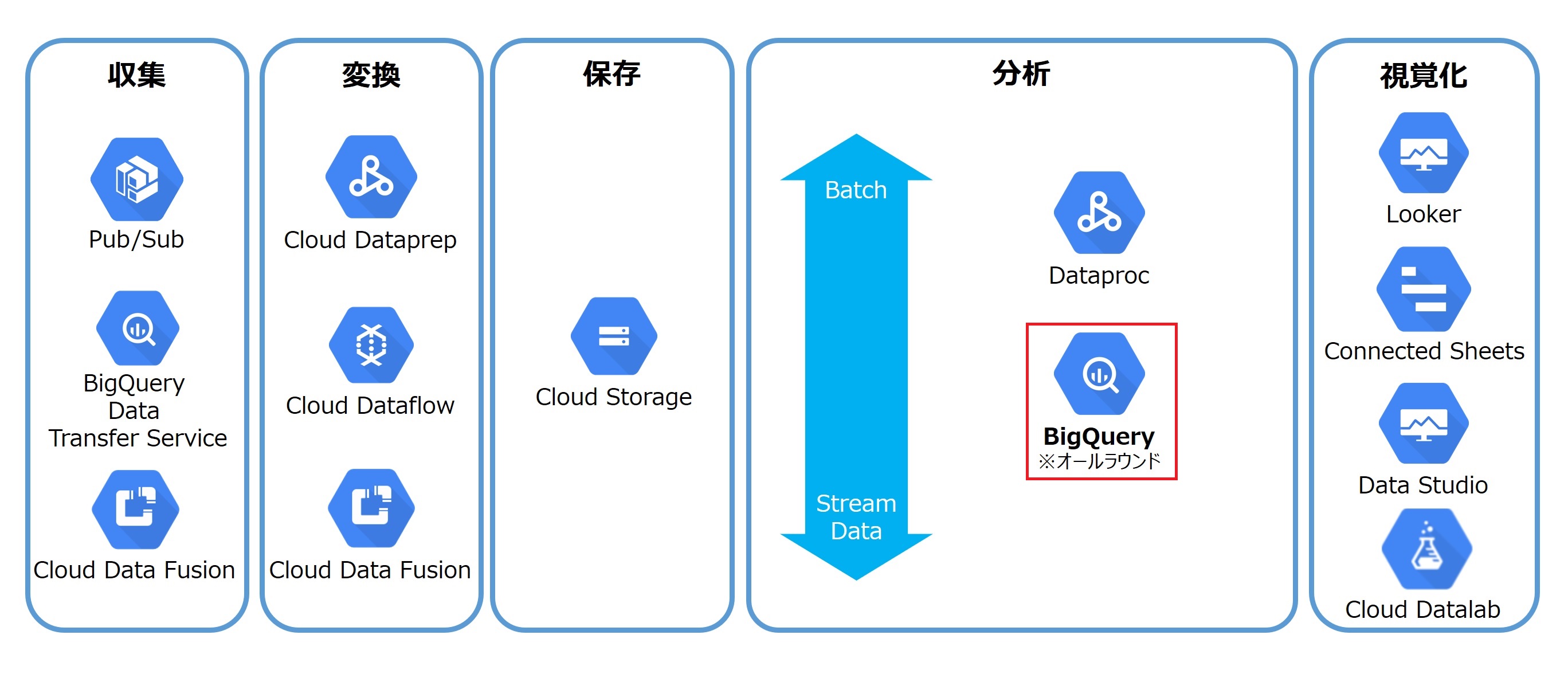
もともとは、Google社が自社で保有している膨大なデータを効率的かつ高速に分析するために構築した社内データ分析基盤であり、それを一般提供したのがGoogle BigQueryだ。2011年に企業向けビックデータ分析サービスとしてプレビュー版が公開され、数億件のデータに対するフルスキャンを数秒~数十秒で返せる処理能力が話題になった。
現在は、処理の裏側で数千台のサーバーを同時処理させていると言われ、PB(ペタバイト)級のデータに対するクエリも数十秒で返す圧倒的なパワーがある。また、Web分析の標準といってもよいGoogle Analyticsのデータを簡単にロードできるのも魅力だ。
実際に使ってみても、使い勝手のよさや、複雑なクエリでも高速で動作することから、データ分析担当者にとって魅力的なサービスであることは間違いない。
実行時の注意点は、クエリ問い合わせの量に対して課金されることだ。不用意に巨大なデータにクエリ実行をすると、その分請求されるため、分析担当者はクエリを実行する前に、金額見積もりや利用者に対しての金額利用制限(クォータ)を設定しておいたほうがよいだろう。
ストリーミングインサート機能を利用すると、ストリームデータをほぼリアルタイムに収集できる。ただし、データの取りこぼしや別料金が必要などの制約もある。大量のデータをリアルタイムではなく、日次や月次バッチ処理のようなデータ鮮度での運用が許されるのであれば、きわめて有力な選択肢だろう。
特徴
- 高度な並行処理のため、大量のデータに対する処理速度が高速
- 標準SQL言語が利用可能
- サーバーレスアーキテクチャ
コスト
月額のストレージ利用料金と、実際にクエリを実行した分の料金で計算される。詳細はBigQueryの料金表を見てほしい。スロット単位課金もある。
- ストレージコスト:月額 1TB / $20
- クエリ実行時にスキャンされたデータ量:1TB / $5
- ストリーミングインサート:$0.010 / 200MB ※ストリーミングデータでなければ無料
Amazon Athena
Amazon Athenaは、Amazon S3に保存しているCSVデータなどを、標準SQLを使って簡単に直接分析できるクエリサービスである。サーバーレスアーキテクチャであるため、事前にインフラストラクチャを準備する必要はない。
使い方は簡単で、Amazon S3にあるデータを指定し、スキーマを定義して標準的SQLを使ってクエリを実行するだけだ。メリットはAmazon S3に保存済みの既存データを読み込んで、素早く分析できることである。
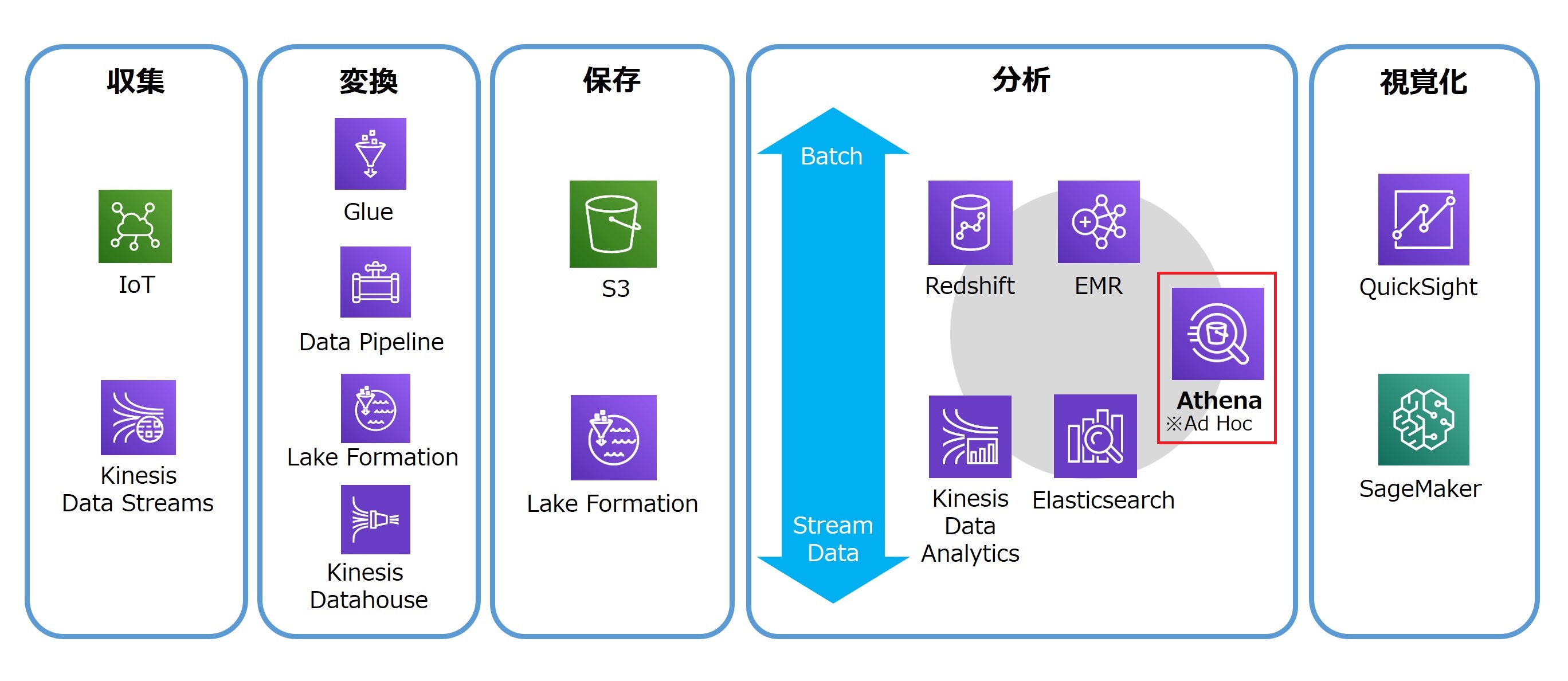
すでにAmazon S3上にデータを保存しており、アドホックに分析をしたいのであれば、強くオススメしたい。また、より早く処理時間を短くしたいニーズがあれば「Amazon Redshift」などのサービスを利用するのもよいだろう。
特徴
- 標準SQL言語が利用可能
- データをストレージに取り込む必要はなく、Amazon S3に直接クエリ実行ができる
- サーバーレスアーキテクチャ
コスト
実際にクエリを実行した分だけの料金で計算される。詳細はAmazon Athenaの料金を見てほしい。
- クエリ実行時にスキャンされたデータ量:1TB / $5
各サービスの機能比較表
各サービスの違いを横並びで比較したのが次の表だ。機能的に競合する部分はあるが、比較対象と言うよりはポジショニングが違うことがわかっていただけるだろうか。
| Azure Data Explorer | Google BigQuery | Amazon Athena | |
|---|---|---|---|
| ポジショニング |
| TB or PB(テラ/ペタバイト)級のデータを高速に分析したい | Amazon S3にデータ保存がされている |
| 機械学習サポート | 単独で時系列や異常検知系のライブラリを利用できる | 別サービスと組み合わせが必要 | 別サービスと組み合わせが必要 |
| 前提知識 | 学習難易度が低い Kustoクエリ言語で操作可能 ※標準SQLも利用可 | 標準SQL知識必須 | 標準SQL知識必須 |
| データ収集機能 | ストリーム/バッチ | ストリーム/バッチ | 他ツールを利用 |
| データビジュアル化 |
| 別サービスと組み合わせが必要 | 別サービスと組み合わせが必要 |
| コスト | サーバー利用時間課金 | データ処理量による課金 | データ処理量による課金 |
Azure Data Explorerは、Microsoft社が自社の課題解決のために開発したサービスだ。そのため、開発のきっかけとなった大量のログ分析/探索に便利な機能を持っている。
特に、データの可視化機能や、Kustoクエリ言語の異常検知や時系列分析機能は、便利さをすぐに実感できるだろう。また豊富な連携機能を生かして、他サービスを組み合わせて機能拡張も可能だ。
ポジショニングとしては、次のように言えるだろう。
- 汎用的に大量データを高速処理したいならGoogle BigQuery
- データが既にAmazon S3にあるならAmazon Athena
- リアルタイムにログやIoTデータの分析を行いたいならAzure Data Explorer
今回はAzure Data Explorerを中心に比較したが、Google BigQueryを中心に比較するならば、Azure Synapse AnalyticsやAmazon Redshiftが比較対象になるだろう。ビックデータ分析やDX導入の参考情報となれば幸いである。
Azure Data Explorer FAQ
Azure Data Explorerの理解を深めるために、FAQをいくつか紹介する。
Azure Data Explorerとは何か?
Azure Data Explorerは、Webサイトやアプリケーションのログデータ、IoTデバイスのテレメトリデータなど、大量に発生するストリームデータを、リアルタイムに収集・分析するサービスだ。フルマネージドサービスなので簡単に使い始められ、高度な圧縮技術やインメモリ処理によって、遅延が少なく、きわめて高速なクエリを実現できる。
- テラバイト、ペタバイトのデータを高速に検索
- フルマネージドサービスで簡単に利用可能
- 使いやすくビジュアル化も簡単なKustoクエリ言語
- 多彩なデータ取り込み機能
- Microsoft以外の外部ツールとの連携
IoT HubやEvent Hubs、Kafka、Logstashなどのデータソースから、大容量で高速なストリーム収集もしくはバッチ収集が可能だ。
データ探索向けに開発されたKustoクエリ言語は、SQLよりもわかりやすく、ビジュアル化も簡単で、Microsoft IntelliSenseによる強力な支援機能を持っている。格納したデータは、Power BIやApache Spark、Grafanaを初めとする多くの外部ツールからのアクセスできる。
サーバーレスではないが、ストレージには信頼性が高いBlob Storage、コンピュートには大量のメモリとSSDを搭載したクラスターアーキテクチャを採用し、スケーラブルなフルマネージドサービスを実現している。
Azure Data Explorerはどのような使い方が適しているか?
下記のような、大量のログデータやテレメトリデータ、時系列データが発生するシステムに適している。
- ミッションクリティカルなシステムの監視
- 大量のIoTデータの分析
- データ分析時のデータ探索における傾向や異常値の発見
- アプリケーションのログ分析によるカスタマーエクスペリエンス向上
Azure Data Explorerは、Microsoft社が自社の課題を解決するために開発したサービスだ。開発目標として挙げたのが次の項目である。ここまでデータ量が多くなくても、近い課題があれば、適用を検討する価値はあるだろう。
- 数千億レコードのログが毎日発生する
- このデータを数週間から数か月は確実に保存する
- このデータに対して複雑な分析クエリを実行できる
- データを取り込んでから、そのデータをクエリできるまでのタイムラグは最小にする
- データが構造化データ、半構造化データ、テキスト文章であっても、数秒でクエリが完了する
Azureアーキテクチャガイドには、他サービスと組み合わせた利用例が掲載されている。左上のテキストボックスに「azure data explorer」と入力すると表示できる。
Azure Data Explorerはデータレイクか?
Azure Data Explorerはデータレイクではない。取り込むにはスキーマ定義が必要なので、事前準備なしにデータは格納できない。また、長期間のデータ保管も想定していない。
ただし、強力なデータ取り込み機能を生かして、ストリームもしくはバッチでデータを収集できる。そして取り込んだデータをBlob StorageやData Lake Storageなどのデータレイクにエクスポートするような連携は可能だ。
Azure Data Explorerはデータウェアハウスか?
Azure Data Explorerは、データウェアハウスではない。トランザクションやログジャーナルは無く、データの更新や削除はできない。長期間のデータは保持できるが、Azure Data Explorerの高速性を生かすには、検索対象のデータがSSDとメモリに乗る程度の範囲の検索が適している。
バッチ処理や複雑なクエリ、長期間のデータに対するクエリなど、時間のかかる処理はAzure Synapse Analyticsが適している。
Azure Data Explorerが適していないことはあるか?
次のような処理はAzure Data Explorerには適していない。ほかのサービスを検討してほしい。
- オンライントランザクション
- データの頻繁な更新を伴う処理
- 複雑なクエリ、多くのジョインが必要なクエリ
Azure Data Explorerは1カ月にどのくらい費用がかかるか?
価格は使用するインスタンスタイプ(SKU)に依存する。1カ月およそ3万円から10万円くらい。詳しくはコスト見積もりツールを参照のこと。最近は日本リージョンでも、安価なAMD EPYCのSKUが利用できるようになった。
もともとDXという概念は「もっとICTを活用しよう、もっとデータを活用しようというモチベーション」だとされている。
「紙を使わずに、ペーパーレスでやりましょう」から始まり、かなり昔からある言葉である。
なぜ再びDXなのか。
AIについても同様だが、日米の情報化投資の特性差は大きい。日本では不景気になると情報系の投資を絞り、目先のコスト削減を目指す。それに対してアメリカでは不景気になると積極投資を行い、ICTおよびデータを活用して労働者1名あたりの利益を1円でも多く稼ぎだそうとする。
また、今までのオンプレミス中心のデータ分析では、成功するかわからないことに対する投資判断の渋さ、初期導入コストの高さ、サイズが有限なディスク、シームレスにアクセスできないテープ装置など、多くのハードルが存在していた。
しかし今日のクラウドサービスは、きわめて低コスト・短期間に導入できる。またデータを単に可視化するだけではなく、リアルタイムな予測モデルや推論モデルを適用できる環境が整備されつつある。
過去は「絵に描いた餅」だったDXと同類のバズワードたちだが、以下に挙げるようなクラウドサービスの発展で、きわめてバズワードとなりえない前提条件が整っている。
- 最低限の管理作業で使えるデータ分析のフルマネージドサービス
- 信頼性が高く低価格で容量無制限のオブジェクトストレージ
- AIや機械学習のライブラリや学習済みモデル
- データ分析に関するエコシステムの充実
- 万が一失敗したときでも、使っただけ課金でダメージを最小限に抑える料金体系
Data Is the New Oil
この言葉は、データはマネタイズにつながる新しい資源であることを表している。データを活用することで、それぞれの企業が抱えている課題を解決できないか棚卸しをしてほしいと思う。
データは貯めるだけでは「ただのゴミ」でしかない。どのデータを、どのように、どの程度の期間保持し、どのように分析することが、ビジネス課題を解決する「オイル」になるのか。データ分析業界の知見を活用することが求められるだろう。
おわりに
本記事を執筆するきっかけは、Azure Data Explorerはうまく使えば優れたサービスなのに、そのよさが知られていないと感じたことだった。また、リレーショナルデータベースやデータウェアハウスに慣れ親しんでいても、Azure Data Explorerがデータ分析初心者にとって理解しづらいサービスだということもある。
ひと口にDXやデータ活用と言っても幅が広い。何をやりたいのかによって使用するサービスは異なる。Azureでサービスを固めたとしても、データ活用で必ずしもAzure Data Explorerが必要になるわけではない。適材適所だ。
クラウド時代のデータ分析者は、数多くのサービスの中から、目的に応じてサービス組み合わせる技量が求められる。
今回はAzure Data Explorerを主題としながらも、データ分析初心者に向けて、特に第1回と第2回には力を入れて書いたつもりだ。データ活用の基礎知識として、みなさまのお役に立てば幸いである。
この記事をシェアしてください
バックナンバー
この記事の筆者


筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
