はじめに
今回で本連載も最終回となる。今回は、前回から引き続き、ゼットラボ株式会社の坂下幸徳氏のインタビュー後編をお届けする。前半より話がさらに白熱していく中、ヤフー株式会社内で実際に起きていること、これからやらなくてはいけないことがさらに明確になっていく。
恐らく、今後コンテナ、Kubernetesが一般的に普及する中で、皆さんも同じ経験をしていくことになると思われるため、自社のシステムと照らし合わせながら読み進めてほしい。
※以降では、ヤフー株式会社をヤフー、ゼットラボ株式会社をZ Labと略す。
コンテナ環境の拡大と、ステートフルへの挑戦
― コンテナの導入は、どのくらいの数から始めて、どのくらいのタームで膨れ上がっていったものなのでしょうか?
- 坂下:Z Labが開発したKubernetes as a Serviceのヤフーでのトライアルが始まったのが2017年8月、この時はベータで、あるサービスに協力してもらい、パイロットプロジェクトで試していました。その後、約1年かけて検証しました。そして、2018年8月にGA(ヤフーの中でサービス開発者が広く利用できる状況)になりました。
そこから、2019年7月時点で、Kubernetesのクラスタ数は400以上になっており、前年比で8倍にまで増え、50以上のサービスで利用されています。これは、まだまだシステムの一部です。現在はステートレスのアプリケーションが中心です。
「運用を含めて楽にできるか」という視点で考えたときに、ステートレスはコンテナ上に乗せやすいし効果も出やすいかと思います。一方、ステートフルなアプリケーションは少し特殊です。データを持っていることで、SLA/SLOが異なってくるのです。

CaaSの利用実績
― もう少し、ステートレスとステートフルの違いを教えてください。
- 坂下:例えば、ステートレスのWebサーバに関しては、10台のうち1台が壊れても大きな問題にはなりません。実際にはリトライ処理が走るので、新しいサーバが1台立ち上がるまで一瞬だけ影響はあると思いますが、数分以内には元通りの性能になります。
一方、ステートフルですが、ヤフーはカスタマーの個人情報が入ったデータから、ログや画像など様々なデータを大量に持っています。そのデータがなくなるとビジネス上大きな問題となってしまいます。サーバは復旧できますが、データはいくらストレージを新しくしても戻ってきません。
- 幕田:ステートフルな状態にしたときのキーはストレージのような気がするのですが、Z Labとしてはそのストレージ部分に関しては自分たちでOSSを持ってきてSDS環境を構築しますか。あるいは、そこはストレージベンダーの製品を購入して対応しますか。
- 坂下:そこは使い分けの見極めが重要になります。データは重要なものとそうでないものがあります。例えば、カスタマーの個人情報のような重要なデータから、ビジネスへの影響度の低いログデータのようなものまで様々です。それらのデータはしっかりと分別して、適切なストレージに入れなくてはいけません。
個人情報のような重要なデータはやはり、ストレージが故障した際にしっかりと復旧できるかがポイントです。障害時にストレージベンダーの専門家がインフラ管理者の横にいてしっかりサポートしてくれるという、安心、保険としてストレージを見ている面もあります。
一方で、重要でないログデータなど、企業としてビジネスに影響がでないデータ、壊れても大きな問題はないデータは安価に構築できるSDSで対応することも可能です。保険料を支払うべきデータか、その価値を見極めて判断していかなくてはいけないと思います。
これは、ストレージだけではなく、全てにおいて同じことが言えます。全てをコンテナにする必要はないですし、全てVMである必要もありません。いい塩梅を探りながら、それぞれ判断していけば良いのです。
ただ、ここで忘れてはいけないのはインフラ管理者が楽になることが重要であるということです。これが1つのゴールなので忘れてはいけません。

ゼットラボ株式会社/ヤフー株式会社/SNIA日本支部 技術委員会副委員長/SNIA Technical Council Advisor 坂下幸徳氏
― ストレージベンダーの製品を利用する場合、何が選択基準になりますか?
- 坂下:データの価値に応じて、使用するストレージベンダーや製品が異なってきます。現状、ストレージの操作方法は各社ごとに異なっており、バラバラな状態です。これが、Kubernetesのコマンドで異なるベンダーのストレージでも同じように管理できるとしたらどうでしょうか。
Kubernetesではストレージプールを示すリソース(StorageClass)を切り替えるだけで、データの価値に応じてストレージを選択できる環境を容易に構築できます。開発環境→テスト環境→本番環境でストレージを切り替えても良いかと思います。つまりKubernetesなどでストレージが抽象化されてきている世界では、単にストレージの機能面だけでなく、新しい運用方法に合うか、データの価値にあったコストかなどが選択の基準になってくると思います。
また、コンテナ対応に絞ってみてみると、ストレージベンダーのコンテナオーケストレーション向けストレージの標準化であるCSI(Container Storage Interface)への対応は徐々に進んできています。
ストレージベンダーの中には「コンテナ対応しました」というときに、CSIへ対応したらコンテナにも対応したと思っている人も多いかと思います。ただし、これは単なるコンテナオーケストレーションの管理インターフェースに対応したにすぎません。単にKubernetesに組み込みやすいかだけです。選ぶ側は「コンテナ対応」といった際は、コンテナを生かした使い方、運用方法にマッチするかを含んで期待しています。
- 幕田:コンテナになっても、バックアップの形態やスナップショット、レプリケーションなど、今あるストレージの技術は使いますか? そこは変わらないのでしょうか?
- 坂下:変わらないと思います。ただし、今のストレージベンダーのバックアップ/スナップショットの操作やレプリケーションの設定などは、ベンダーの独自色が強すぎるのが問題だと思っています。やりたいのは、データの価値に応じて容易にストレージを切り替えられるようなシステムを容易に組むことができるようなシステムです。例えば、開発環境と本番環境でストレージを切り替えたいと思った場合に、バックアップ/スナップショットのやり方が複数のベンダー間で全く違っていたら、どうでしょうか。嫌ですよね。
CSIでは、バックアップ/スナップショットやレプリケーション(コピー)などの仕様が徐々に登場してきているので、それに期待したいところもありますが、ベンダーの対応は間違って欲しくないとも思います。例えば、各ベンダーのレプリケーションの特徴機能を使うがために、予めベンダー固有のレプリケーションのおまじないのような設定をインフラ管理者が行い、CSIからリクエストがきたら動きます、というような製品が出てきたら選びたくはないですね。インフラ管理者の負荷はほとんど減りませんから。理想は、CSIからリクエストがきたら、各ベンダー固有の設定は、これらのインターフェースの裏でよしなに動いて欲しいです。
過去、ストレージベンダーは、ストレージ側からではワークロード(アプリケーション)がわからないから適切なレプリケーションの設定ができないなど様々な問題があり、今のようなベンダー固有の値を細かくせざるを得ない事情があったのではないでしょうか。しかし、今は違います。Kubernetesでストレージのリソースをデプロイするほとんどの場合はアプリケーションのコンテナと一緒に行われます。つまり、レプリケーションを適切に設定するための情報はあるのです。これらをうまく使いインフラ管理者の負荷をなくすことができるようなバックアップ/スナップショットやレプリケーションを期待します。
Kubernetesをソフトウェアではなく、フレームワークに
― カンファレンスなどでZ Labのシステム構成を見るとKubernetesでOpenStackやKubernetesを管理するなど、すごく複雑に見えますが、そこまでしないといけないのですか?
- 坂下:まず、私たちはKubernetesを単なるインフラ基盤のソフトウェアではなく、フレームワークとして捉えています。Kubernetesには、セルフヒーリングなどを実現するための非常に優れたフレームワークを持っています。また、独自のリソース(CRD:Custom Resource Definition)やカスタムコントローラを組み込むことも可能です。
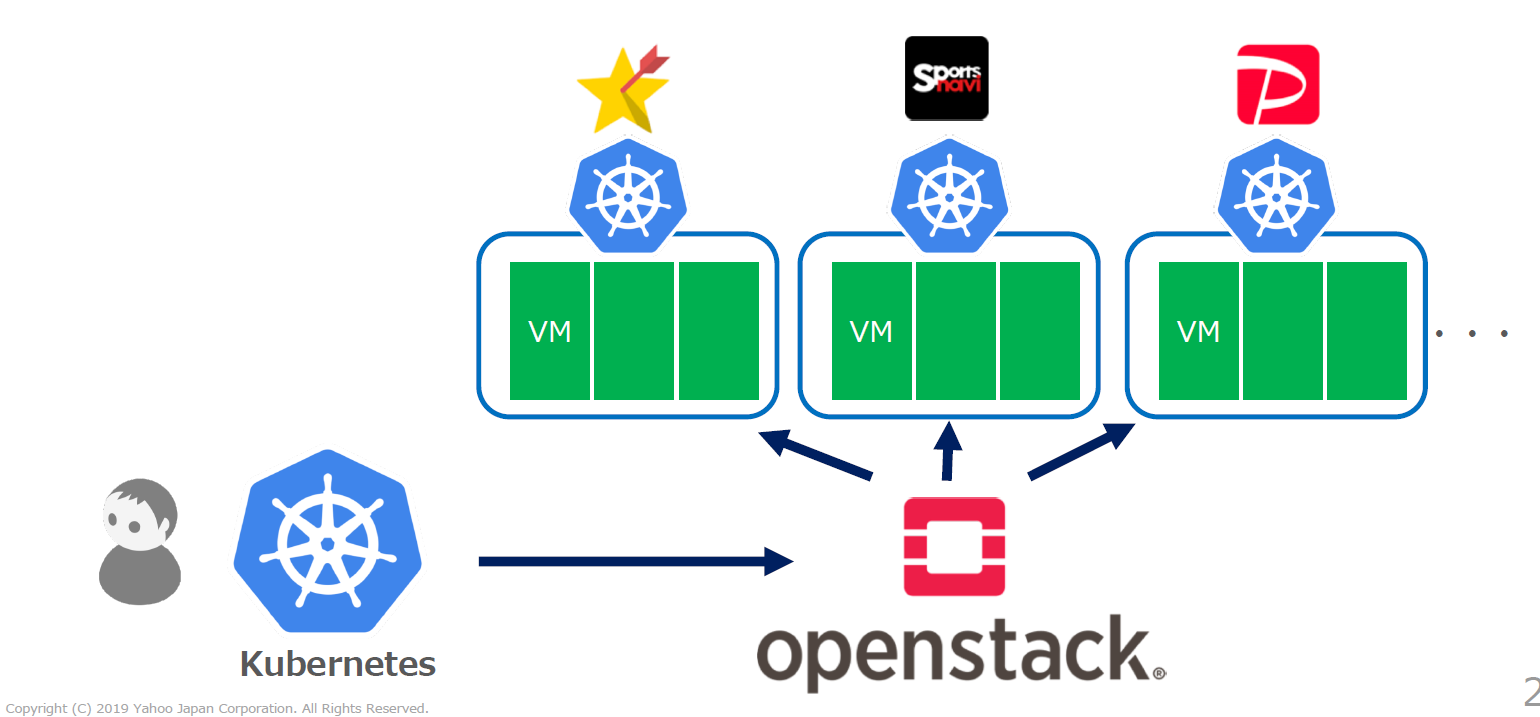
Z Labでは、そのフレームワークを利用してKubernetes as a Serviceを実現しています。
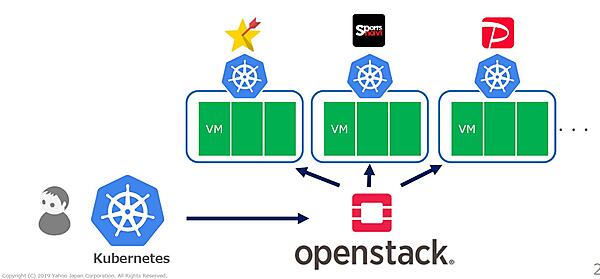
Kubernetes as a Service
例えば、VM10台と設定しておくと、VMに障害が起こってもVM10台の環境を維持するため、自動的にOpenStack上へ新しいVMを作成するといったことをKubernetesのセルフヒーリングのフレームワークを使い実現しています。このような形にしておくと、運用管理の省力化が実現できます。
― そのようなやり方は、米国では当たり前なのしょうか?
- 坂下:いくつかのKubernetesのサービスや製品で似たようなものをカンファレンスなどで目にします。先進的な方法だとは思いますが、発明的というレベルではありません。
多くの運用の現場では、その一部を改善するだけで、やり方を抜本から変えようとしないから、その発想が生まれにくいのではないでしょうか。あとは、フレームワークを知らず気づけない場合もあります。視点を変えれば、色々な、もっと良い方法があるかもしれません。
- 幕田:既存の仮想化のようなインフラ環境から、コンテナ環境への載せ替えは大変なことでしょうか。何をすれば簡単に移行できるのでしょうか。
- 坂下:容易にいくものと、いかないものがあります。ステートレスは移行しやすいですし、ステートフルは難しい。でも、その議論の前に忘れてはいけないのが、移行すべきかどうかをジャッジすることです。
そもそも、VMとコンテナは別の技術ですが、VMの代替えするものがコンテナだと考えてしまっている方が多いかもしれません。VMはCPU、メモリ、ネットワーク、ストレージ仮想化する技術ですが、コンテナは、プロセスが利用するライブラリなどを他プロセスに影響しないように独立させたものです。つまり、コンテナは、ライブラリ/アプリケーションのイメージ付きのプロセスと捉えた方が良いかもしれません。
コンテナを使い易くするためにオーバーレイネットワークを組むことはありますが、コンテナの本質ではないと思います。コンテナは仮想化しているわけではないのです。
例えば、Webサービスでも、本当にVMのような仮想CPUが必要なのかを見定めるのが一番難しいです。本当に仮想CPUが欲しいのか、複数のWebサービスを立ち上げたいだけかの見定めが重要だと思います。VMで出来ることの多くは、技術的にはコンテナでも出来るようになってきました。仮想化でしか実現できないことは、かなり少なくなっています。
そのような中で、見定めの重要なポイントの1つは、「VMをコンテナに載せ替えると運用管理が楽になるか」という点があります。アップデートもせずに同じバージョンのまま使い続けるようなサービスの場合、VMから無理にコンテナに移行する必要はないでしょう。
一方で、サービスを落とさずにバージョンアップしたい場合やカナリアリリースを行いたい場合などは、VMよりコンテナに載せ替えた方が運用管理は楽になる場合もあります。つまり、どういう仕事に変えたかったのかを考えVMかコンテナかを選択していくという点が重要なのです。何も考えず「慣れているからVMだ」「流行っているからコンテナだ」というのは避けたいですね。
※オーバーレイネットワーク:ネットワーク上に構築され、仮想的なコンピュータネットワーク
※カナリアリリース:プロダクトやサービスの新機能を一部ユーザーのみが利用できるようにリリースし、新機能に問題がないことを確認しながら、全体に向けて段階的に展開していくデプロイ手法

インタビューを担当した筆者。今回のインタビューでは坂下氏から貴重な知見を得ることができた
ワクワクするようなテクノロジーに触れる
― ヤフーのコンテナ数は50,000以上という話を聞きました。このような数に成長した次の課題は何ですか?
- 坂下:Kubernetes as a Serviceをヤフーに展開し、インフラを刷新するとともに運用管理方法もアップデートしてきました。デプロイされているコンテナ数も爆増していますが、少数のインフラ管理者でも数に負けずに運用管理できる体質になってきたと感じています。次の展望としては、適応するサービスの拡大です。これまではステートレス中心で展開してきましたが、データベースなどのステートフルなアプリケーションにも適用し、さらに多くの現場でワクワクするようなインフラ・運用管理に仕上げていきたいと思います。
また、エンジニアや管理者には元気よくなってもらいたいです。新しい技術に触れることはワクワクしますよね。その経験をコミュニティに発信・共有していくことで土壌を育てていく。そうすれば、自然とその技術・企業には良いエンジニアが集まってきます。
日本はエンジニアの育て方を失敗していると思います。北米ではエンジニアは新しいテクノロジーを求めて転職していきます。2019年時点の北米では、Kubernetesは転職に有利なテクノロジーのトップクラスになり、多くのエンジニアが積極的に勉強しコミュニティに参加しています。一方、日本は一部のクラウド/Webサービス企業を中心にコミュニティが活性しつつありますが、多くの企業は人の流動性が低いため、どうしても目の前の効率化に走ってしまい、ITインフラ・運用のやり方を刷新するようなポテンシャルを持つ技術のコミュニティへ積極的に参加しようというマインドが少々低いように感じます。他社の事例が出てくるのをじっと待ち、出てきたら石橋を3回叩いて壊す、そういう文化の企業も多いのではないでしょうか。新しい技術の採用にはリスクはありますが、既存のものの効率化のみでは未来はないと思います。そこを飛び出ないといけません。
エンジニアが積極的に新しい技術に挑戦し、新しいやり方を理解・取り込める組織・環境とモチベーションを作っていくのが、組織のトップさらには日本全体のチャレンジです。『ワクワクするようなテクノロジー』。これがエンジニアのモチベーションになり、エンジニアを育ていくことでもあり、優秀なエンジニアが集まってくる鍵だと思います。
* * *
これまで、4回に渡って市場の拡大、ベンダーの動き、実際に利用しているユーザーの声という形をお届けした。今後さらにコンテナが普及するのは間違いない。今までもクラウドや仮想化が登場したとき、誰がDBをそこに置こうとしただろうか。最初はWebアプリや開発環境だけという形で使われていたが、今では基幹システムでさえもその環境で動くようになった。
コンテナの動きはクラウドや仮想化よりも圧倒的に速く、実際Kubernetesがデファクトスタンダードになるまでに何年もかかっていない。さらに、そこから世界中のサービス事業者がKubernetesに準じたサービスやソフトウェア製品を次々と生み出し、常にアップデートが行われている。
「日本は欧米に比べて2~3年遅い」と言われるのは間違いないが、それでも欧米での普及が尋常ではない速度で進んでいることを考えると、日本も追随していく形になるだろう。『エンジニアがワクワクするテクノロジー』。コンテナ・Kubernetesは難しいが実に面白いテクノロジーだ。ゼットラボ株式会社/ヤフー株式会社/SNIA日本支部 技術委員会副委員長/SNIA Technical Council Advisor
[経歴]
2003年に株式会社日立製作所 システム開発研究所に入社。主任研究員として運用管理・クラウド技術の研究開発に従事。2014年に米国シリコンバレーのHitachi America Ltd, R&D/IT Platform Systems Labのラボ長に就任、同国で2017年まで活動。
2018年よりゼットラボ株式会社に移り、Kubernetesを中心とした運用管理・クラウド技術の研究開発に従事。また、2012年よりストレージの業界団体SNIA(Storage Networking Industry Association)でも活動。2013年にSNIA@米国のTechnical Working Groupを取りまとめるTechnical Councilに日本人初で就任し、ISO/ANSIの標準化にも貢献。
2019年現在はSNIA日本支部技術委員会副委員長、SNIA Technical Council Advisor (米国)としても活動中。お酒を嗜みつつKubernetesでのストレージ活用、Statefulアプリケーションの普及を狙い奮戦中。
博士(情報科学)、情報処理学会会員、「Kubernetes実践入門」共著者(技術評論社)
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
