データ分析
データ分析
次にTFXコンポーネントを使ってデータ分析を行う方法について解説します。このステップではStatisticGenを使ってデータセットの統計量の計算や可視化する方法、SchemaGenを使ってスキーマを生成する方法について解説します。
- StatisticsGenとは
StatisticsGenは、データセットの統計量を生成するTFXコンポーネントです。ExampleGenで取り込んだデータセットを入力とし、計算済みの統計量を出力します。統計量の計算はApache Beam ※ を使用して処理されるため、大規模なデータセットに対してもスケールして対応できます。
※ Apache Beamとは:ETL、バッチおよびストリーミング処理を含むデータ処理パイプラインを定義・実行するためのフレームワークです。処理のバックエンドとしてApache SparkやApache Flink、Google CloudのDataflowなどに対応しています。デフォルトでは組み込みのダイレクトランナーモードで実行されます。
- StatisticsGenを使ったデータの可視化
先ほど実行したExampleGenの出力結果を使ってStatisticsGenを実行します。
statistics_gen = tfx.components.StatisticsGen(examples=example_gen.outputs['examples'])
context.run(statistics_gen)
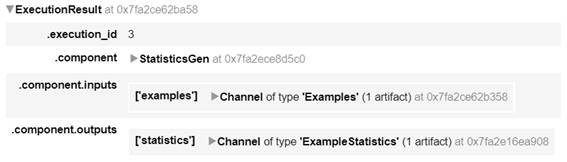
図2-3:StatisticsGenの実行結果
StatisticsGenの実行結果を表示します。
context.show(statistics_gen.outputs['statistics'])
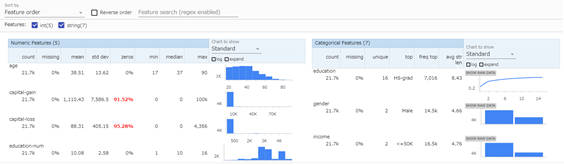
図2-4:TFDVによるデータの可視化(デフォルト表示)
実行結果を表示すると、StatisticsGenが計算した統計量をもとにデータが可視化されます。この機能は、TensorFlow Data Validation(TFDV)というTensorFlowエコシステムのデータ分析支援ツールにより実現しています。
TFDVで可視化する内容は数値変数とカテゴリー変数に分けられており、それぞれ次の統計値やチャートが表示されます。
- 数値変数
数値変数では、平均や標準偏差、中央値といった情報が表示されます。また、ヒストグラムチャートによるデータ分布の可視化もします。
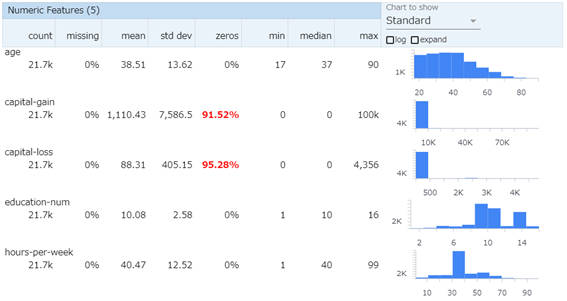
図2-5:数値変数の可視化(デフォルト)
数値変数の一覧
| 項目名 | 説明 |
|---|---|
| count | 有効データ数 |
| missing | 欠損値の割合 |
| mean | 平均 |
| std dev | 標準偏差 |
| zeros | ゼロの割合 |
| min | 最小値 |
| median | 中央値 |
| max | 最大値 |
表示設定(Chart to show)をデフォルトから「Quantiles」(クォンタイル)に切り替えることで分布のばらつきを可視化できます。
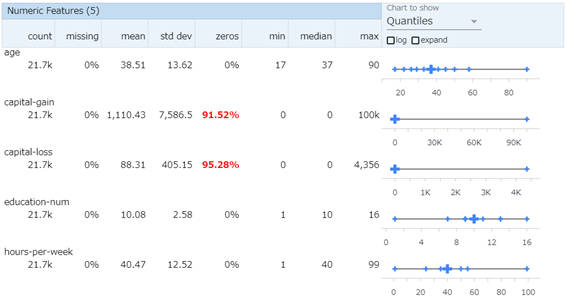
図2-6:クォンタイルチャート
また、「Quantiles」の下にある「log」にチェックを入れると対数によるクォンタイルチャートを表示できます。
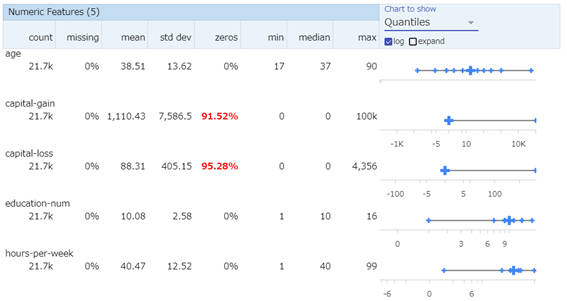
図2-7:クォンタイルチャート(対数)
- カテゴリー変数
カテゴリー変数では、値の種類数や最頻値といった情報を表示できます。
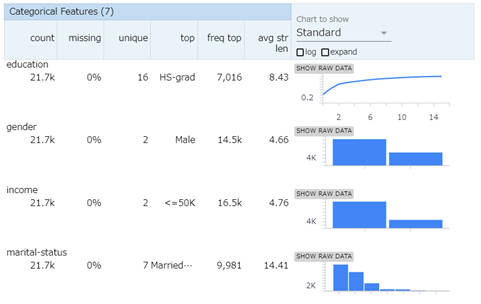
図2-8:カテゴリー変数の可視化
カテゴリー変数の一覧
| 項目名 | 説明 |
|---|---|
| count | 有効データ数 |
| missing | 欠損値の割合 |
| unique | カテゴリー数 |
| top | 最頻値 |
| freq top | 最頻値の出現割合 |
| avg str len | 文字列の長さの平均 |
このようにTFDVで可視化された結果を確認してみると、前回記事で解説した探索的データ分析(EDA)で行うことを、TFXでは一つのコンポーネントとして実現できることがわかります。なお、次に解説するSchemaGenというスキーマ生成を行うコンポーネントと組み合わせることで、データセットの構造を形式化して把握することができます。
- SchemaGenとは
SchemaGenは、データセットの統計量をもとにスキーマを自動的に生成するTFXコンポーネントです。スキーマはデータセットの構造を表現するための記述形式となっていて、データセットに含まれるべき項目や各項目の型(int、float、string、byteなど)、許容されるデータの範囲(カテゴリー値であればその種類、連続値であれば許容される値の範囲など)を定義します。ここで生成されたスキーマは「データ検証」で実施するデータセットのエラー検出などで利用します。
- SchemaGenの実行
先ほど実行したStatisticsGenの出力結果を使って、SchemaGenを実行します。
schema_gen = tfx.components.SchemaGen(statistics=statistics_gen.outputs['statistics'])
context.run(schema_gen)
図2-9:SchemaGenの実行結果
SchemaGenの実行結果を表示します。
context.show(schema_gen.outputs['schema'])
実行結果を表示すると、次のように項目の一覧や項目の型、カテゴリー値の項目であればその種類などの情報が表示されます。
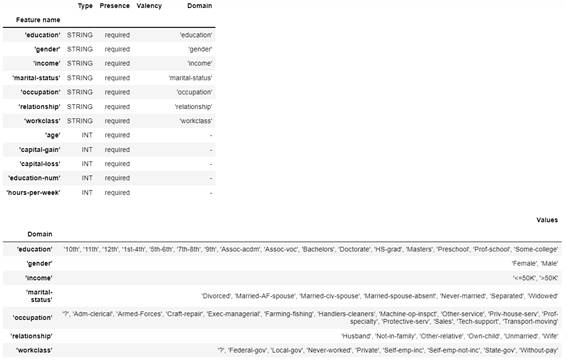
図2-10:SchemaGenにより生成されたスキーマの可視化
スキーマの項目名の説明
| 項目名 | 説明 |
|---|---|
| Feature name | 項目の名前 |
| Type | データ型(INT、FLOAT、STRING、BYTEなど) |
| Valency | 学習データごとに必要な値の数 |
| Domain | カテゴリー値の場合に付与されるValuesに紐づくキー |
| Values | 出現するカテゴリー値の種類 |
このスキーマで問題ないこと(期待するスキーマになっていること)を確認できたら、以降は変更がない限りこのスキーマを利用します。これは、「正しいスキーマ」と新しく取り込んだデータセットの統計量を比較し、期待する構造になっているか検証するためです。生成されたスキーマが期待どおりになっていない場合は、後述の「スキーマの更新」を実施し、手作業でスキーマを編集します。今回は、生成されたスキーマで問題ないことが確認できたと仮定して、パイプラインで利用する手順を次に解説します。
- スキーマをMinIOにアップロード
生成されたスキーマをパイプラインで利用するために、MinIOにアップロードします。
bucket.upload_file(os.path.join(schema_gen.outputs['schema'].get()[0].uri, 'schema.pbtxt'), 'schema/schema.pbtxt')
- スキーマを読み込むためのコンポーネントの実行
スキーマを読み込むためのコンポーネントImporterを作成します。
※TFX v1.3.0以上ではImportSchemaGenというスキーマを読み込むためのTFXコンポーネントが追加されています。
import_schema = tfx.dsl.Importer(
source_uri = '%s/schema/' % bucket_name_s3_prefix,
artifact_type = tfx.types.standard_artifacts.Schema).with_id('schema_importer')
context.run(import_schema)
図2-11:Importerの実行結果
- スキーマの更新
SchemaGenが生成するスキーマは統計量をもとに自動生成されたものとなっているため、期待しているものとは異なる場合があります。例えば、ある項目のカテゴリー値が実際の業務では定義されているものの、「現在のデータセット」には含まれていない場合などです。これは、「現在のデータセット」をもとにスキーマを推定するため、本来取り得るすべての値を考慮できないからです。
例として以下のような場合を仮定して、既存のスキーマを更新します。
- 「age」の値の有効範囲が実際は最小30、最大60しか存在しない
- 「workclass」の値の種類として実際は「?」は存在せず「unknown_workclass」が存在する
※ここでは、後述する「データ検証」のステップで異常検出することを例示するために、意図的に実際のデータセットの構造ではないスキーマに更新しています。
# スキーマファイルの読み込み
from tensorflow_metadata.proto.v0 import schema_pb2
# スキーマファイルの読み込み
schema_output_file = os.path.join(schema_gen.outputs['schema'].get()[0].uri, 'schema.pbtxt')
schema = tfdv.load_schema_text(schema_output_file)
# スキーマの更新(有効範囲の設定)
tfdv.set_domain(schema, 'age', schema_pb2.IntDomain(name='age', min=30, max=60))
# スキーマの更新(ドメインの削除・追加)
workclass_domain = tfdv.get_domain(schema, 'workclass')
workclass_domain.value.remove('?')
workclass_domain.value.append('unknown_workclass')
# 更新したスキーマの確認
tfdv.display_schema(schema)
実行すると次のようにスキーマが更新されたことを確認できます。
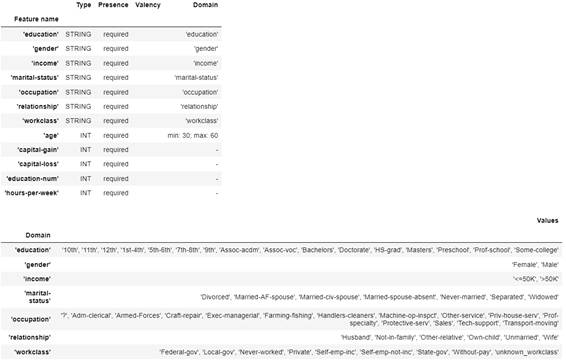
図2-12:手動で更新したスキーマの可視化
更新したスキーマを書き出します。
update_schema_output_dir = os.path.join(os.getcwd(), 'update_schema')
os.makedirs(update_schema_output_dir, exist_ok=True)
tfdv.write_schema_text(schema, os.path.join(update_schema_output_dir, 'schema.pbtxt'))
このようにしてスキーマを手作業で更新することができます。後述する「データ検証」ではこのスキーマを使って異常検出する例を紹介します。
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
