データ変換
データ変換
次にTFXコンポーネントを使ったデータ変換について解説します。このステップでは、TensorFlow Transform(TFT)を使ってデータセットを学習に利用できるデータに変換する方法について解説します。
- TFTとは
TFTは、取り込んだデータセットを機械学習モデルの学習で利用できるデータに変換するためのコンポーネントです。TFTはTFXコンポーネントのなかで、最も習得が難しいコンポーネントといえます。なぜならTensorFlowのオペレーションでデータ変換処理を実装するのは、pandasやnumpyを使って実装するのとは異なる複雑さがあるからです。したがって前回解説したような「初期の機械学習モデル」を開発する段階では、TFTの利用は適さないと考えられます。一方で機械学習モデルを本番運用する際には、機械学習パイプラインとしてTFTを組み込んでおくべき主な理由として次の2つがあります。
- Apache Beamを使って処理されるため、大規模なデータセットに対してもスケールして対応できる
- 学習・推論間でのスキューを回避できる
前者は、StatisticsGenをはじめTFXのコンポーネントはApache Beamをバックエンドとして利用しており、TFTも同様に大規模なデータセットに対するスケーラビリティといったメリットを享受できます。後者の学習・推論間のスキューに関しては次に詳しく解説します。
- 学習・推論間でのスキュー
学習・推論間でのスキューとは、モデルの学習時と推論時でデータ変換処理に不整合が生じることを指しています。多くの場合、モデルの学習に用いるデータはpandasなどを利用してデータ変換処理を実施します。このモデルをREST APIとして本番環境にデプロイする場合、モデル学習時のデータ変換処理と推論時のデータ変換処理が常に一致していることが前提となり、その確認と調整が必要になります。
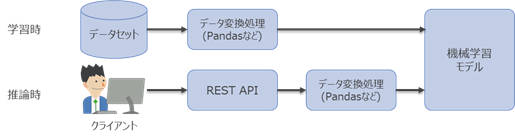
図2-13:一般的な機械学習モデルの学習と推論の例
TFTを利用すると、学習済みモデルと一緒にデータ変換処理もエクスポートできるため、不整合(スキュー)を回避できます。
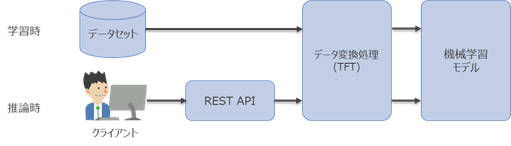
図2-14:TFTを使った機械学習モデルの学習と推論の例
また、TFTは複雑な実装を軽減できるような便利な関数を備えています。TFTを使いこなすにはある程度の慣れが必要ですが、組み込みの関数を活用しながら実装を進めていくことができます。
TFTの組み込み関数の例
| データ型 | 関数 | 概要 |
|---|---|---|
| 数値 | scale_to_z_score | 平均が0で標準偏差が1に正規化します |
| 数値 | scale_by_min_max | 指定した最小値、最大値の範囲にスケーリングします |
| 数値 | pca | バイアスされた共分散を使用してデータセットのPCA(Principal Component Analysis)を計算します |
| 数値 | compute_and_apply_vocabulary | カテゴリー変数を出現頻度の高い順にラベルエンコーディングします |
| テキスト | ngrams | n-gramのSparseTensorを作成します |
| テキスト | vocabulary | データセット全体での一意の値を検索します |
| テキスト | word_count | 各行のトークン数を検索します |
- TFTの実装
TFTを使ってデータ変換処理を実装していきます。TFTではpreprocessing_fnという名前の関数にてすべての変換処理を定義していきます。preprocessing_fn関数は、入力データとして、キーに項目名、値に変換前の生データを含むPythonの辞書型の値を受け取ります。そして、変換後の項目名と値を辞書型で返す関数です。なお、TFTで実装した処理をTFXのパイプラインとして組み込む際は、モジュールファイル化(.pyファイル化)する必要があるため、ノートブック上で実行するとともにモジュールファイルにも書き出しを行います。
まず、モジュールファイル名と出力ファイル名を定義します。
transform_module_file_name = 'adult_income_transorm_module.py'
transform_module_file_path = os.path.join(os.getcwd(), transform_module_file_name)
次に、preprocessing_fn関数にて使用する定数や関数を定義していきます。
%%writefile {transform_module_file_path}
import os
import sys
import tensorflow as tf
import tensorflow_transform as tft
# 数値変数の項目名リスト
NUMERIC_FEATURE_KEYS = [
'age',
'education-num',
'capital-gain',
'capital-loss',
'hours-per-week',
]
# カテゴリー変数の項目名とその次元数の辞書
ONE_HOT_FEATURES = {'workclass': 8,
'education': 16,
'marital-status': 7,
'occupation': 14,
'relationship': 6,
'gender': 2
}
# 予測対象の項目名
LABEL_KEY = 'income'
# 変換後の項目名の変換用関数
def transformed_name(key):
return key + '_xf'
変換後のデータであることを明示するため項目名に「_xf」というサフィックスを追加する関数を用意します。これにより、エラーが発生したときに入力と出力のどちらに起因する問題なのかを区別することができます。また、変換されていない項目値を誤ってモデルに適用することを防ぎます。
次にpreprocessing_fn関数を定義して、変換処理を記述していきます。
%%writefile -a {transform_module_file_path}
def preprocessing_fn(inputs):
#文字列型の値を数値型に変換する関数
def __convert_string2int_value(key, original_values, converted_values):
initializer = tf.lookup.KeyValueTensorInitializer(
keys=original_values,
values=tf.cast(converted_values, tf.int64),
key_dtype=tf.string,
value_dtype=tf.int64)
table = tf.lookup.StaticHashTable(initializer, default_value=-1)
return table.lookup(inputs[key])
outputs = {}
#欠損値を最頻値に変換
inputs['workclass'] = tf.where(tf.equal(inputs['workclass'], '?'),
'Private', inputs['workclass'])
inputs['occupation'] = tf.where(tf.equal(inputs['occupation'], '?'),
'Prof-specialty', inputs['occupation'])
# TFTの関数を使って数値型の項目を正規化 (平均値0標準偏差1に変換)
for key in NUMERIC_FEATURE_KEYS:
outputs[transformed_name(key)] = tft.scale_to_z_score(inputs[key])
# TFT の関数を使ってダミー変数化(One-Hot エンコーディング)
for key in ONE_HOT_FEATURES.keys():
dim = ONE_HOT_FEATURES[key]
index = tft.compute_and_apply_vocabulary(
tf.strings.strip(inputs[key]),
num_oov_buckets=0,
vocab_filename=key)
one_hot_tensor = tf.one_hot(index, dim)
one_hot_tensor = tf.reshape(one_hot_tensor, [-1, dim])
for i in range(0, dim):
one_hot_name = transformed_name(key + '_' + str(i))
outputs[one_hot_name] = one_hot_tensor[:,i]
# Labelを0と1に変換
table_keys = ['<=50K', '>50K']
outputs[transformed_name(LABEL_KEY)] = __convert_string2int_value(
LABEL_KEY, table_keys, [0, 1])
return outputs
データ変換処理の内容自体は前回記事と同様です。pandasのDataFrameやscikit-learnで実装したものと比較してみると記述方法等の違いがわかります。TensorFlowのオペレーションにより複雑な実装に見えますが、TFTの関数によりコードの記述量は削減されています。今回利用したTFTの関数は次のとおりです。
- scale_to_z_score: 平均が0で標準偏差が1に正規化する
- compute_and_apply_vocabulary: カテゴリー変数の値を数値に変換する
次に、パイプラインの実行時に利用するために、モジュールファイルをMinIOにアップロードします。
bucket.upload_file(transform_module_file_path, 'module/%s' % transform_module_file_name)
データ変換処理を実行します。
param_transform_module_file = '%s/module/%s' % (bucket_name_s3_prefix, transform_module_file_name)
transform = tfx.components.Transform(
examples = example_gen.outputs['examples'],
schema = import_schema.outputs['result'],
module_file = param_transform_module_file)
context.run(transform)
実行結果は次のとおりです。
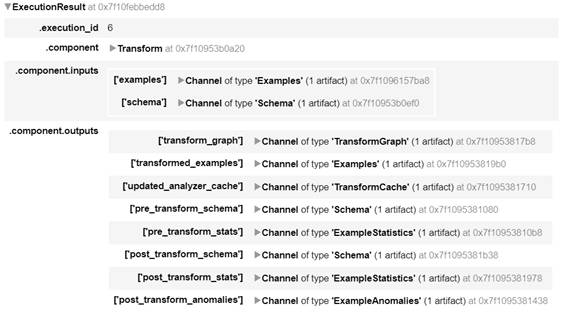
図2-15:Transformの実行結果
データ検証
次にTFXコンポーネントを使ったデータ検証を行う方法について解説します。このステップではExampleValidatorを使ってデータセットの検証を行う方法について解説します。
- ExampleValidatorとは
ExampleValidatorは、データセットのエラーを検出するコンポーネントです。事前定義済みのスキーマとデータセットから算出された統計量を比較し、期待するデータセットの構造になっているか検証します。ExampleValidatorはTFDVを内包しているコンポーネントのため、TFDV単体でも同様のことはできますが、パイプラインに組み込む際は、ExampleValidatorを利用します。
- データ検証が必要な理由
機械学習モデルはデータからそのパターンを学習します。つまり、機械学習のワークフローはデータが中心であり、データの品質が最も重要な要素となります。データ検証は、入力データや変換済みのデータが期待されているものになっているかをチェックします。これにより、モデルの学習に利用するデータを一定の品質に保つことができます。さらに、データが時間の経過とともに変化する場合、その変化を捉えることにも役に立ちます。
- ExampleValidatorの実行
本稿では、入力データと変換済みのデータに対してデータ検証を実施する方法について解説します。
- 入力データに対するデータ検証
まずExampleValidatorでエラー検出する例として、前述した「データ分析」の「スキーマの更新」で作成したスキーマを利用して、データの異常を検出させてみます。
import_anomalies_schema = tfx.dsl.Importer(
source_uri = update_schema_output_dir,
artifact_type = tfx.types.standard_artifacts.Schema).with_id('schema_importer')
context.run(import_anomalies_schema)
ExampleValidatorを定義し実行します。
anomalies_example_validator = tfx.components.ExampleValidator(
statistics = statistics_gen.outputs['statistics'],
schema = import_anomalies_schema.outputs['result'])
context.run(anomalies_example_validator)
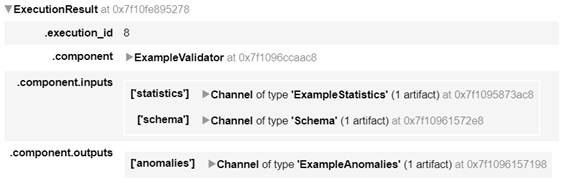
図2-16:ExampleValidatorの実行結果
データの検証結果を表示します。
context.show(anomalies_example_validator.outputs['anomalies'])
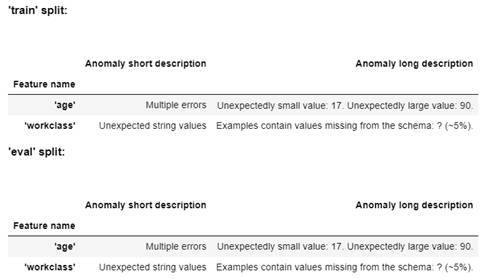
図2-17:ExampleValidatorで異常値検出した実行結果
ageに有効範囲外の数値が含まれているのと、workclassに取り得る値ではない「?」という値が含まれているため、異常として検出されました。この例は意図的に実際のデータセットの構造ではないスキーマを定義し、異常を検出させましたが、新しく取り込むデータセットの項目数や取り得る値の種類、値の範囲が変わった場合などに、この例と同様に異常検出することができます。
今回、パイプラインで利用する「正しいスキーマ」は、前述した「データ分析」の「スキーマ生成」でアップロードしたスキーマとなるため、それを読み込むExampleValidatorを定義して再度データ検証を実施します。
example_validator = tfx.components.ExampleValidator(
statistics = statistics_gen.outputs['statistics'],
schema = import_schema.outputs['result'])
context.run(example_validator)
図2-18:ExampleValidatorの実行結果
データセットの検証結果を表示します。
context.show(example_validator.outputs['anomalies'])

図2-19:ExampleValidatorで異常値が存在しなかった場合の実行結果
異常は検出されませんでした。
- データ変換済みのデータに対するデータ検証
Transformコンポーネントには標準でデータ検証のコンポーネントが組み込まれているため、それを利用する方法について解説します。先ほど実行したTransformの結果からデータ変換後のスキーマを参照します。
context.show(transform.outputs['post_transform_schema'])
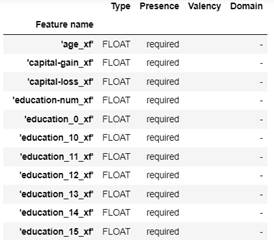
図2-20:Transform実行後のスキーマ表示の一部
このスキーマで問題ないと仮定して、そのスキーマをパイプラインで利用するために、MinIOにアップロードします。
bucket.upload_file(os.path.join(transform.outputs['post_transform_schema'].get()[0].uri, 'schema.pbtxt'), 'post_schema/schema.pbtxt')
次にTransformコンポーネントで利用するスキーマを設定します。stats_options_updater_fn関数を追加することで、既存のスキーマをTransformコンポーネントに読み込ませることができます。
%%writefile -a {transform_module_file_path}
def stats_options_updater_fn(stats_type, stats_options):
import tensorflow_data_validation as tfdv
from tfx.components.transform import stats_options_util
if stats_type == stats_options_util.StatsType.POST_TRANSFORM:
load_post_schema = tfdv.load_schema_text('s3://census-income/post_schema/schema.pbtxt')
stats_options.schema = load_post_schema
return stats_options
モジュールファイルを更新したため、MinIOにアップロードします。
bucket.upload_file(transform_module_file_path, 'module/%s' % transform_module_file_name)
これで、入力データセットに対するデータ検証と変換済みデータセットに対するデータ検証をパイプラインに組み込むことができました。
データ分割(分割済みデータの取り出し)
ここまで入力データの取り込みからデータを変換し検証するところまでパイプラインの実装を進めてきました。本稿の最後に機械学習モデルの学習時に利用する「学習用データ」と「評価用データ」を取り出し、その内容をノートブック上で確認する手順を解説します。※TFXパイプラインでは、データセットの分割をExampleGenで行います。分割に関する設定は前述した「入力データの取り込み」の「データセットの分割設定」を参照してください。
- 学習用データと評価用データの内容を確認
学習用データは「Split-train」を、評価用は「Split-eval」をそれぞれキーとして指定することで、Transformコンポーネントの出力結果から変換済みのデータファイルのパスを取得できます。次の例は学習用のデータを読み込み、表示する手順です。
transformed_train_uri = os.path.join(transform.outputs['transformed_examples'].get()[0].uri, 'Split-train')
tfrecord_filenames = [os.path.join(transformed_train_uri, name)
for name in os.listdir(transformed_train_uri)]
dataset = tf.data.TFRecordDataset(tfrecord_filenames, compression_type="GZIP")
#上から3行を表示
for tfrecord in dataset.take(3):
serialized_example = tfrecord.numpy()
example = tf.train.Example()
example.ParseFromString(serialized_example)
print(example)
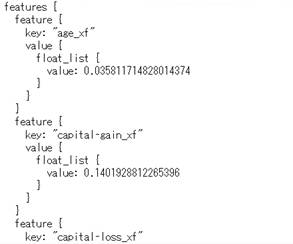
図2-21:Transform実行後の「Split-train」のデータ表示の一部
また、Transformコンポーネントの出力結果には、統計情報も含まれています。これを取得してTFDVで可視化することも可能です。
post_transform_path = os.path.join(transform.outputs['post_transform_stats'].get()[0].uri, 'FeatureStats.pb')
post_stats = tfdv.load_stats_binary(post_transform_path)
tfdv.visualize_statistics(post_stats)
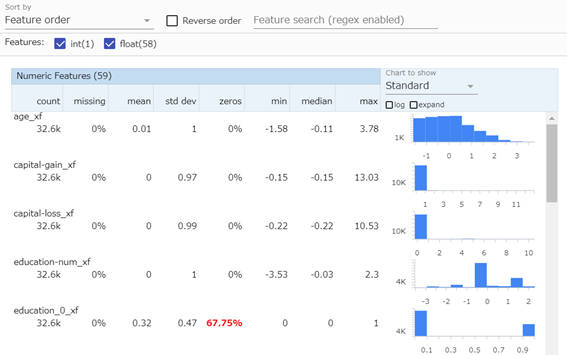
図2-22:TFDVによる学習用データの可視化
ここまで、機械学習パイプラインのうち「データ準備」を構成する各ステップについて、TFXコンポーネントを使って実装しました。
おわりに
今回はTFXの概要と機械学習パイプラインのうち「データ準備」のステップについて、TFXコンポーネントの解説と実装を行いました。次回は、後半部分となる「モデル作成」について、引き続き解説と実装を行います。
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
