CloudNative Days Fukuoka 2023、九州でスーパーを展開するトライアルのグループ会社、Retail AI Xによる生成型AIを解説するセッションを紹介
CloudNative Days Fukuoka 2023より、九州でスーパーを展開するトライアルのグループ会社、Retail AI Xによる生成型AIを解説するセッションを紹介する。
2023年11月27日 6:00
2023年8月3日開催のCloudNative Days Fukuoka 2023キーノートから、九州でディスカウントストアやスーパーマーケット、流通業などを展開する株式会社トライアルホールディングスのグループ会社、株式会社Retail AI XのHead of Techである辻隆太郎氏によるセッションを紹介する。タイトルは「Enterprise generative AI on Cloud Native」、生成型AIのエンタープライズ企業における応用を解説するという意味合いのタイトルとなっている。
●動画:Enterprise Generative AI on cloud Native
オンラインでセッションを行う辻隆太郎氏
前半のパートでは生成型AIの基本的な部分について解説し、生成型AIの使われ方、トライアルグループにおける失敗を含む経験談を紹介、そして後半のパートではFuture-Proofというキーワードを使い、生成型AIに対する将来的な取り組みを説明している。
最初のポイントは生成型AIを作成する側に立つのか、消費する側に立つのかという問いかけだ。
消費する側か、作成する側になるのかは結果を求める側のニーズ次第
これについては、短期的な結果を求めるならOpenAIなどの先行するベンダーが提供するサービスを使うべきではないだろうかと説明。では作成側に立つというのはどういうことかを説明したのが次のスライドだ。
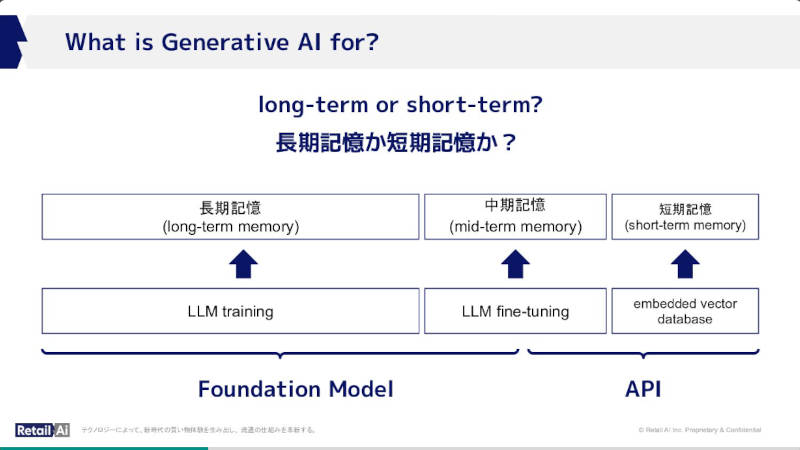
短期記憶、中期記憶、長期記憶などの違いとLLMでの技術にマッピング
ここでは大規模言語モデルを「データによって永続的に残る長期記憶」と位置付け、中期記憶はファインチューニングされたモデル、そして短期記憶をEmbedded Vector Databaseに対応付けて説明を行っている。さらに長期記憶をFoundation Model、短期記憶をAPIにタグ付けしているが、この部分の詳細な解説は省かれている。
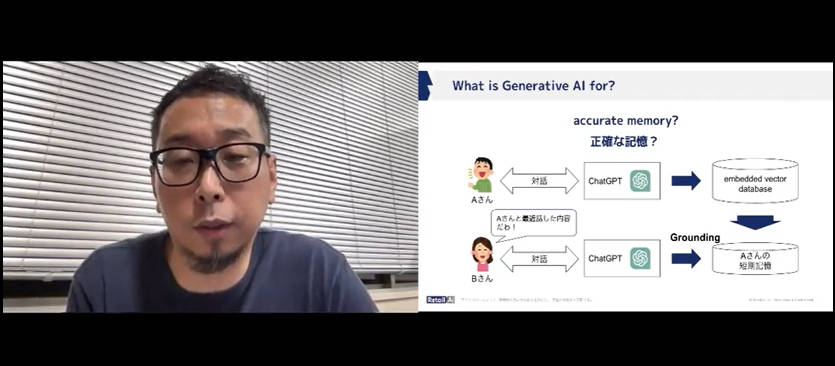
例を使って短期記憶がユーザーに与える回答の違いを解説
このスライドでは短期記憶がプロンプトに対してある領域では正確な回答を生成することを説明。次に示す例では正確ではないものの全体として「らしい」回答を返すモデルについて解説。
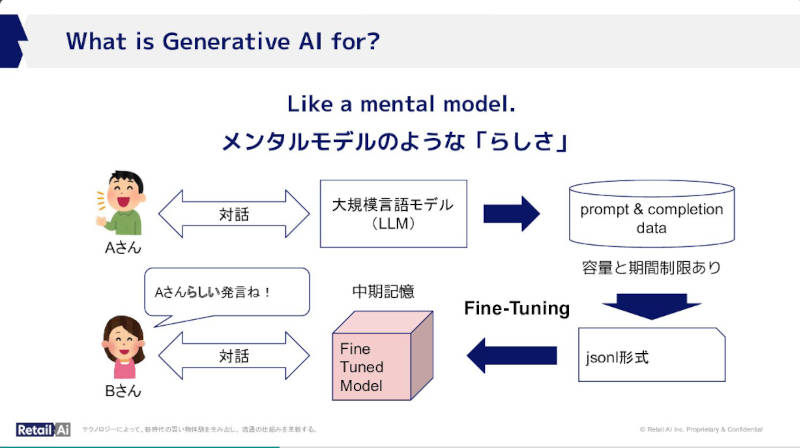
「らしさ」を生成する中期記憶のモデル
ただこの2つの例は対比しているように見えながら、それぞれGrounding、Fine-Tuningというテクニカルタームで語られているのは残念だが、20分という短い時間でそこまで説明するのは無理という判断なのであろう。
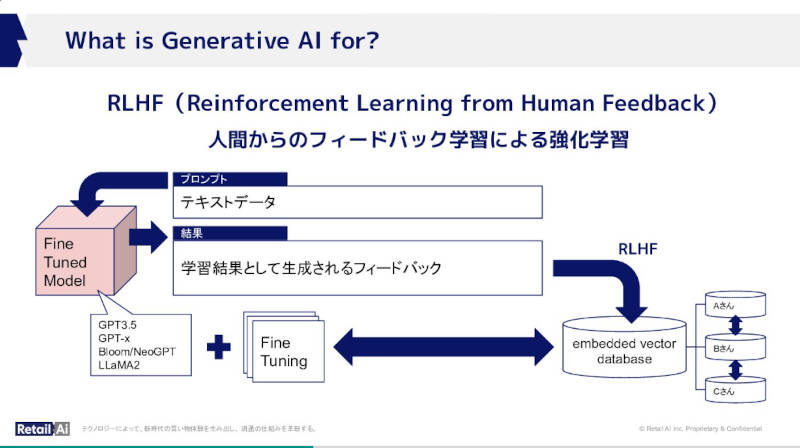
少し前にバズワードになったRLHF(人間のフィードバックによる強化学習)を説明
RLHF(Reinforcement Learning from Human Feedback)についてもその仕組みを解説するのみで、その価値やコストなどの説明は省かれた。
またデータが増えればLLMが生成する回答も変化するとして、スタンフォード大の論文やOpenAIの論文を引用して説明。ここでも専門用語が出てくるが特に解説を行うことはなかった。

P.W. Anderson氏の論文から「More is Different」を引用
またマイルス・デイビスのコメント「I'll Play it, and tell you what it is later」を引用して言語モデルについても紹介しているが、生成型AIの概略を解説するには抽象的だったのではないだろうか。

さまざまなデータから言語モデルが生成可能という説明にマイルス・デイビスの言葉を引用
ここからはトライアル社内の経験談として、トランザクション処理がビジネスの成長に追いつかないという理由で独自のトランザクションデータベースe3SMARTを開発したことを説明。

独自開発のe3SMARTによってビジネスが満足する結果に
この独自データベースによってトランザクションシステム自体は満足する結果を出すようになったが、独自仕様だったことにより「SQLもJDBCも使えない」「クラウド化困難」「ハードウェアコストの増大」などのマイナス面が現れてしまったと説明した。
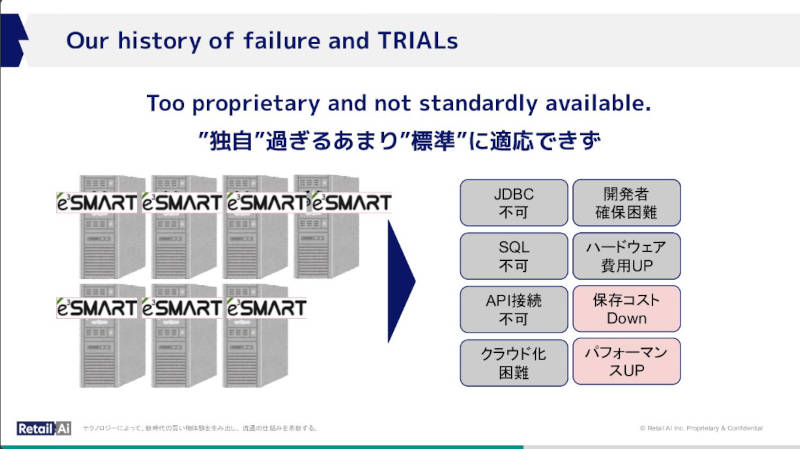
e3SMARTが独自過ぎて標準に適応できなかったと説明
試しにネットで「トライアル e3SMART」などのキーワードで検索すると、元Panasonic出身でトライアルのCIOというタイトルの西川晋二氏によるe3SMARTによる実績が検索結果として表示される。自社で独自に開発したデータベースによる成功例として以下のように紹介されているが、見直しが始まっているのかもしれない。
●参考:Amazon大競争時代の流通業成長戦略ビジョン AI×IoT×クラウドの進化で加速するデジタルトランスフォーメーション
またディスカウントストア内部に設置されたカメラの画像処理のためのサーバーも計160コア、4 GPUというハイスペックなものを用意したが、大量の画像データが使われずに放置されている状況を解説した。上述の2018年に行われたダイヤモンド社のイベントレポートでは、40台のカメラからのデータを用いて性別や年齢の判定、導線分析などに使われていると西川氏が講演しているが、それも見直しの段階ということだろう。
そして最後のパートFuture-Proofでは、今必要なものはサービスを利用する、いずれ必要になることがわかっているものは自社で基盤開発を行うことでバランスをとるべきだと説明。ここでは西川氏の先端的な取り組みに対するバックラッシュが起こっているように思える。
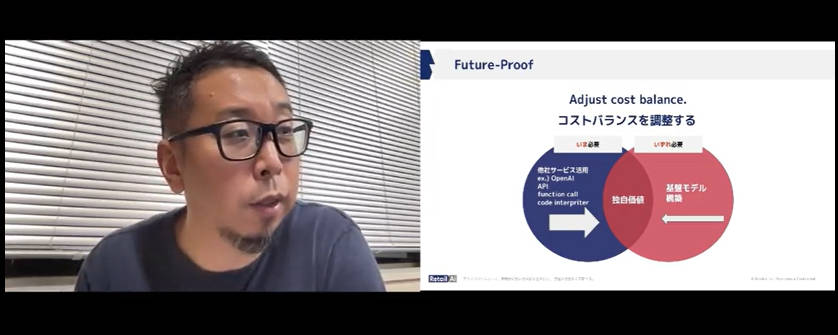
いま必要なものは外部サービス、将来的に必要になるものは自社開発のバランスが大事
また生成型AIの精度についてもCatastrophic Forgetting、Contamination Detect、RLHFなどのキーワードを使い、参加者にとって理解を求めるよりも「こういうキーワードがあることを覚えておいて欲しい」という意味合いで生成型AIの精度について日々進歩していることを示したと言える。
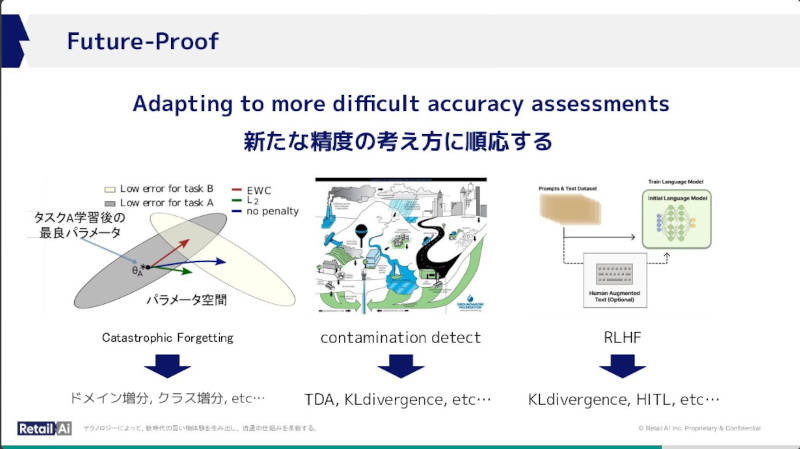
生成型AIの精度についてさまざまなテクノロジーが出現していることを紹介
そしてエンゲージメントを求めるゴールとして挙げた時にデータから生成型AI、機械学習などを経てどのように繋がっていくのかというスライドでは、トライアルが考える価値創生の発想方法が垣間見える。ここでは生成型AIや機械学習は資産の一歩手前というのが興味深い。
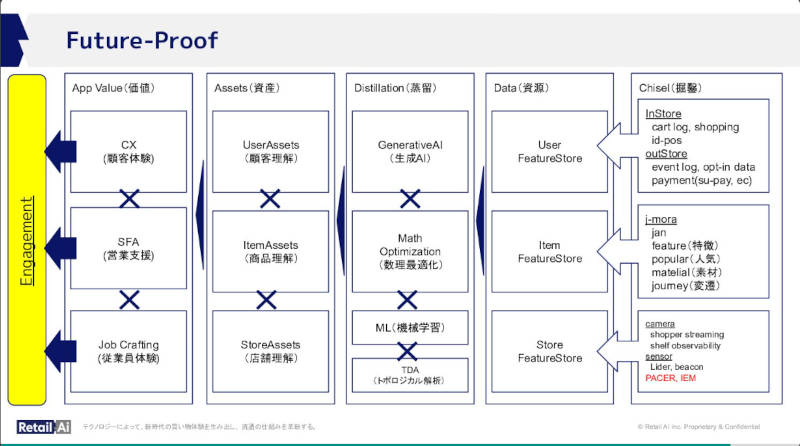
エンゲージメントに繋がるデータからの概念的な流れを解説
最後にシステム全体を通してデータがどのように資産、価値に変わっていくのか? を説明。ここではe3SMARTをデータ処理のための高速エンジンとして位置付けている。
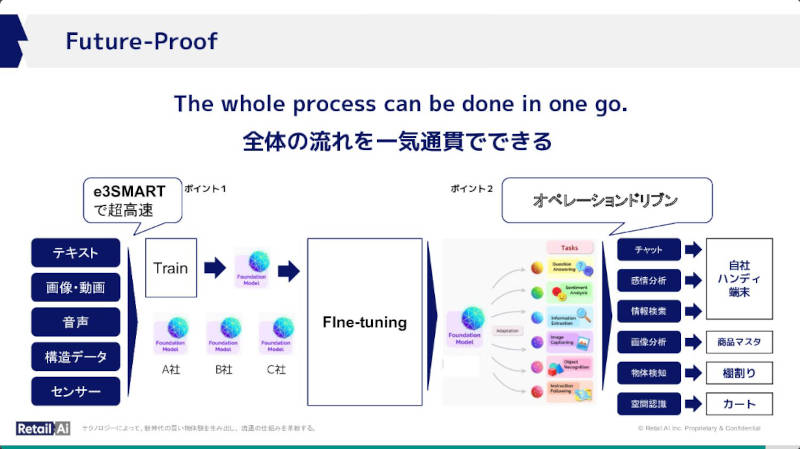
全体が淀みなく繋がり、データからオペレーションに昇華するのが目的?
辻氏が先端の人工知能について知識が深いのは、さまざまな論文の引用やテクニカルタームが頻出していることからも理解できた。一方、参加者にとってみればもう少し泥臭い「ディスカウントストアでの生成型AIの応用はこうすべき」や「独自開発データベースのその後」という話が聞きたかったようにも感じた。高価な画像サーバーが店頭で邪魔モノ扱いされている経緯などは、エッジにおける画像処理に大きな期待を抱いているエンジニアにとっては興味のあるところだろう。次回以降、そういったピックも聞けることを期待したい。
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
