はじめに
AIは既に顔認証や音声認識、翻訳などさまざまな分野で実用化されていますが、ChatGPTの出現により自然言語処理能力についても十分実用レベルに到達していることが広く認識されました。それどころか、あまりにも急速に賢くなっていて、いったいどこまで行くのだろうと不安視する声も聞こえてきます。
何ごとも相手をよく知らないと不安になるものです。そこで、本連載ではGPTシリーズを中心に大規模言語モデル(LLM)がどのような技術や原理で人間の期待した回答を生み出しているのかをやさしく解説します。仕組みを知ると客観的に判断でき、ビジネスへの活用イメージが湧きやすくなります。
ChatGPTとは
「ChatGPTとは、OpenAIが開発した大規模な言語モデルで、テキスト生成や言語翻訳などの自然言語処理タスクに利用することができます。 現在利用可能な最大かつ最先端の言語モデルの一つであるGPT-3(Generative Pretrained Transformer 3)モデルをベースにしています。 ChatGPTは、人工知能チャットボットです。2022年11月に公開されました。」
はい、まずは“お約束”で、これはGPT-4を搭載しているBingに「ChatGPTとは」と質問した際の回答です。
Bingの回答をまとめると、次の3点になります。
- OpenAIが開発した大規模言語モデルで、2022年11月に公開された
- テキスト生成や言語翻訳などの自然言語処理タスクに利用できるAIチャットボットである
- GPT-3(Generative Pretrained Transformer)モデルをベースにしている
もう少し補足しましょう。
- GPTは、Generative Pretrained Transformerの略。Generative(生成できる)、Pre-trained(事前学習する)、 Transformerという技術を使った言語モデルで、生成AIと呼ばれている
- ポリグロッド(多言語対応している)言語モデルである
- Attentionという技術で学習し、RLHFという強化学習でお作法を学んでいる
- 正確にはGPT-3.5をベースとしており、その進化版GPT-4もリリースされている
- ChatGPTやGPT-4は2021年9月までのデータで学習しているため、それ以降の情報に弱い
- Microsoftの新BingやCopilotでGPT-4が使われている
大まかな特徴はこんなところでしょうか。本連載は「エンジニアなら」という冠がついていますので、GPTとのやり取りの紹介は少なめにして、仕組みや技術について解説していきます。
GPT誕生まで
実は、私は2017年のThink ITの連載「ビジネスに活用するためのAIを学ぶ」で「自然言語処理は、音声認識や画像認識に比べると“人間レベル”に到達するまでまだ時間がかかりそうですが…」と書きました。実際、そのときのレベルはそんなものだったのですが、直後にTransformerという新技術が現れて急に進化が加速しました。
4年後の続編「エンジニアなら知っておきたいAIのキホン2021年版」の第6回(2021年10月26日掲載)では、GPT-3を紹介しています。そこでは「これがもっと進化して完成度が高くなれば、骨子やあらすじを示すだけでブログや記事、小説などをAIが書いてくれる時代が来る、そんなふうに期待されているのです」と書いています。そして、そのわずか1年後の2022年11月30日にChatGPTが公開され、これが現実的なものとして認識されたのです。
実際、ChatGPTのような大規模言語モデルは短い期間で急成長しており、その進化の速さが「このままだととんでもないことが起こるのでは」という不安を掻き立てている面もあります。そこでエンジニアらしく技術を理解して冷静に判断するために、まずはChatGPTがどのように作られてきたのか、その誕生までの流れを図1を使って説明しましょう。
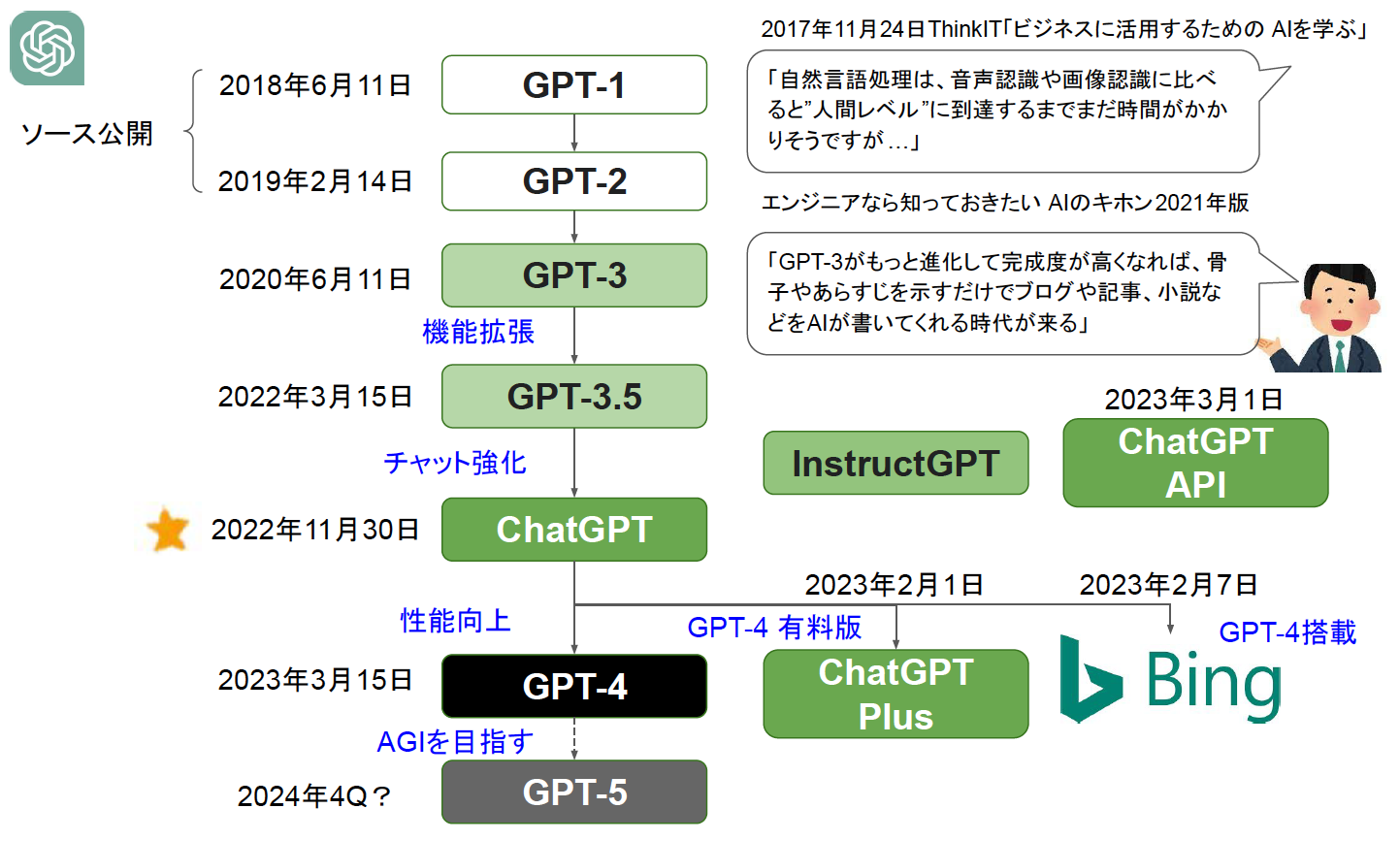
図1:GPTシリーズ
GPT-3
アメリカのAI関連企業OpenAI社は、2020年6月にGPT-3というAIを公開しました。これは、従来の自然言語処理AIに比べて格段にレベルが高く、AIが人間のように書けることを最初に示したと言われています。GPT-3はその前身のGPT-2と同じ言語モデル構造ですが、学習データ量が40GBから570GB、パラメータ数が15億個から1750億個と大幅に増えています。このGPR-3の登場により学習データとパラメータ数を大きくしてゆく大規模言語モデル競争が始まったのです。
GPT-3.5
OpenAIは2022年5月にGPT-3の機能を拡張し、2021年6月までのデータを用いて訓練したGPT-3.5というモデルをリリースしています。パラメータ数は未公開ですが推定3550億個くらいとも言われており、これがChatGPTのベースとなっています。
ChatGPT
GPT-3.5のチャット機能を強化したものが、話題沸騰のChatGPTです。チャット強化とは「人間の好む回答をする(話術の向上)」と「不適切な発言をしない(マナー向上)」という2点です。これをRLHFという強化学習により学び、一般公開しても大丈夫なレベルにしたのです。
この戦略は非常にうまくハマりました。GPT-3やGPT-3.5は多くの専門家に注目される技術でしたが、あくまでも“通を唸らせる”存在でした。しかし、これをチャットで公開して誰でも利用できるようにサービス提供したことで一気にバズりました。世界中でこれをどのように活用するかという試みが爆発的に広がり、学習データも世界中の人々から集まっています。これまでの研究室レベルから世界に広がったことにより、進化が加速しているのです。
なお、現状、1つだけ注意が必要なのがChatGPTは2021年9月までの学習データで学んでいることです。そのため、それ以降の出来事に関係する質問をした場合に、回答のネタが古いというケースが発生します。例えば、ChatGPTに「日本の総理大臣は誰ですか」と聞いてみると「2023年5月現在、私が取得している情報によれば、日本の総理大臣は菅 義偉(すが・よしひで)氏です。」と回答します。わざわざ“2023年5月現在”という言葉を付けて平気で嘘をつくのがChatGPTらしいですね。
ChatGPTシリーズの成長
GPT-4
2023年3月にGPT-4がリリースされました。これはChatGPTを進化させたもので、次のように性能が大幅に向上しています。
a.言語能力が上がり(言い回しがうまい)や信頼性も向上(嘘が減る)している
b.文字だけでなく画像も取り扱える(マルチモーダルである)
c.ChatGPTに比べて、長い文章が取り扱える(8倍の長さ)
d.脚本や音楽などの創造性が向上している
e.ポリグロット(多言語を操れる人)の能力がアップ
f.差別や暴力など不適切な発言を回避する能力が向上(プロンプト・インジェクションに強い)
OpenAIのテクニカルレポートによると、アメリカの司法試験(模擬試験)を受験したところ、ChatGPTが受験者の下位10%程度のスコアだったのに対し上位10%程度に入って合格したそうです。こうした専門的な分野(さらに英語圏)によっては人間レベルの性能を発揮できそうですね。
ChatGPT Plus
2023年2月1日に、GPT-4を搭載したChatGPT Plusがリリースされました。月20ドルという価格ですが、GPT-4を使えるほかに、有料な分、優先的なアクセスやサポートが提供されます。また、マイクロソフトのBingのチャットはGPT-4を搭載しているので無料で利用できます。
なお、GPT-4の学習済みデータはいまのところChatGPTと同じく2021年9月までのデータです。Bingの場合は、プロメテウスという仕組みでネット上の新しい情報を使って回答してくれるので、日本の総理大臣を尋ねると図2のようにきちんと岸田文雄と回答してくれます。

図2:ChatGPTとBingチャットに総理大臣が誰かを質問
GPT-5
GPTモデルの性能向上はこうしている間も絶え間なく続いており、2023年第4クォーターもしくは2024年には次のモデルとなるGPT-5がリリースされると噂されています。また、GPT-5のリリース前に中間バージョンとなるGPT-4.5があり、これがリリースされるかどうかは分かりませんが、長文入力に対する正確な対応、より正確な回答などの性能向上が実現しているそうです。
AGI
ChatGPTやBingで公開した結果、これまでの研究室での開発に比べて、いっきに実用的な対話データを取得できるようになりました。これらを学習データとして利用することで著しい進化を果たすのではと期待しています。
OpenAIの目標は、第3次AIブーム(2018年頃)に話題となったAGI(Artificial General Intelligence)、すなわち人間と同じレベルの汎用人工知能です。そして、GPT-5はその可能性を示す最初のモデルになると期待されているのです。
OpenAIとマイクロソフト
OpenAI Inc.は、2015年12月にサム・アルトマン氏やイーロン・マスク氏らが10億ドル出資して作った非営利法人です。マスク氏は、テスラで研究しているAIとの利益相反を理由に2018年2月に役員を辞任して離れました。その1年後の2019年3月にいくつかのファンドから出資を受けて営利部門のOpenAI LPが設立され、7月にマイクロソフト社から10億円の出資を受けて関係性を深めています。

図3:OpenAIとマイクロソフト
マイクロソフトはさらに追加で出資を行い、2023年1月には総額100億ドルとなりOpenAIの株式の49%を取得しています。創業者でありCEOのサム・アルトマン氏は、2023年4月に来日して岸田総理と対談したことで、お茶の間でも有名になりましたね。
GPTシリーズはOpenAIの設立ポリシーのもとで2018年のGPT-1、2019年2月のGPT-2まではオープンソースとして公開されてきました。しかし、2019年3月に営利組織のOpenAI LPが設立されてマイクロソフトなどからの出資を受けたことでスタンスが変わり、2020年9月22日にマイクロソフトはGPT-3の「独占的な利用」を発表しました。
そして、2020年6月発表のGPT-3からはソース非公開になっており、ChatGPTではパラメータ数なども秘密になりました。AIという新たな武器で王座Googleに挑む立場としては当然のことだと思いますが、生い立ちがオープンだっただけに批判もあります。
大規模言語モデル
エピソード1と2
上記ではGPT-3から説明しましたが、スターウォーズと同じくエピソード1と2、すなわちGPT-1とGPT-2についても紹介しましょう。GPT-1のパラメータ数は1.17億個、GPT-2のパラメータ数は15億個でした。ただし、OpenAIは「悪意のある応用に対する懸念」を理由にGPT-2フルモデル版のリリースを見送り、1.24億パラメータの縮小版を2019年2月14日にリリースしています。
悪意ある応用とは、オンラインでのなりすましや不適切なコンテンツ、誤解を与える記事、ヘイト宣伝などです。これ以降も継続的に対策を続けていますが、いまだに問題視されることが多い宿命のような課題とも言えます。
スケーリングの法則(Scalling Low)
Open AIは2020年に「スケーリングの法則(Scalling Low)」という論文で、ニューラルネットワークの言語モデルの性能が計算能力やモデルサイズ(パラメータ数)、データセットの量と関係が深いことを発表しました。つまり計算能力はもちろん、パラメータ数や学習データの量は非常に重要で、これが大きければ大きいほど精度が上がるということです(図3)。

図4:スケーリングの法則
シンプルで当たり前に見えますが、まさにコロンブスの卵のような法則です。通常は性能がサチる(飽和する)と思われそうですが、サチらず強い相関関係が続くのです。この法則のモデルはGPT-3でした。モデルサイズ(パラメータ数)はGPT-2が15億個だったのに対し、GPT-3は1750億個と大幅に増えています。また、学習データ量もGPT-2が40GBだったのに対しGPT-3は570GBに拡大しています。このように言語モデルを大規模化したことにより、初めて「AIが人間に近い対話をできそうだ」と思わせる実力が示されたのです。
大規模言語モデル競争
論文とGPT-3の出現により、一気に大規模言語モデル(LLM:Large Language Model)競争が始まりました。現在、世界中で表のような言語モデルの大規模化が著しく進んでいるのです。
表:大規模言語モデル(GPT-3.5/4のパラメータ数は推定)
| 言語モデル | リリース日 | 開発元 | 最大パラメータ数 |
|---|---|---|---|
| GPT-3 | 2020年6月 | OpenAI | 1750億 |
| GShard | 2020年6月 | 6000億 | |
| Swich Transformer | 2021年1月 | Google Brain | 1.57兆 |
| 悟道(WuDao)2.0 | 2021年6月 | 北京智源人工知能研究院 | 1.75兆 |
| HyperCLOVA | 2021年11月 | LINEとNAVER | 390億 |
| Gopher | 2022年1月 | DeepMind | 2800億 |
| 日本語GPT | 2022年1月 | rinna | 13億 |
| GPT-3.5 | 2022年3月 | OpenAI | (推定)3550億 |
| PaLM | 2022年4月 | Google Reserch | 5400億 |
| GPT-4 | 2023年3月 | OpenAI | (推定)5000億~1兆 |
Google社は、GPT-3と同時期の2020年6月に6000億のパラメータからなる「GShard」を発表しました。その翌年の2021年1月にはGoogle Brain社が1.6兆ものパラメータを持つ「Swich Transformer」をオープンソース化し、半年後の2021年6月には北京智源人工知能研究院が悟道(WuDao)2.0を発表しています。また、2022年1月にはAlphaGoを開発したGoogleの子会社であるDeepMindが2800億のパラメータを持つGopherを発表しています。
GPT-4のパラメータ数は非公開ですが、5000億〜1兆個くらいではと言われています。人間の脳の容量は150TB、記憶容量は17.5TB、シナプス数は100兆個と言われています。1T(テラ)は1兆ですから、だんだん人間の領域になっているような感じですね。
日本語に特化した言語モデルも登場して来ました。2021年11月にLINE社と親会社の韓国NAVER社が共同開発したHyperCLOVAのパラメータ数は390億個ですが、820億個のモデルを開発中とのことです。また、チャットボットりんなを開発していたチームがスピンアウトして2020年6月に設立したrinna社は、オープンソースのGPT-2をベースにした13億パラメータからなる日本語GPTをオープンソース化し、研究や開発に役立つように提供しています。
まとめ
今回は、以下の内容について学習しました。
- ChatGPTはGPT-3.5をベースとし、チャットを強化した大規模言語モデルである
- ChatGPTはAttentionという技術で学習し、RLHFという強化学習でお作法を学んでいる
- GPT-4は言語処理能力や信頼性、ポリグロットなどが大幅に向上し画像も扱える
- ChatGPTやGPT-4の学習データは2021年9月までのものである
- マイクロソフトはOpenAIに出資し、新BingやCopilotにGPT-4を搭載している
- スケーリングの法則により、大規模言語モデル競争が始まっている
今回は第1回ということで概要を中心に紹介しましたが、次回からはAttentionやRLHFなどの言語モデルの技術を解説していきます。難しい式を使わず、図や例でわかりやすく説明しますので、新しい技術に対する好奇心を一緒に楽しんでいきましょう!
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
