KubeCon China 2024から、ローカルでLLMを実行するSecond Stateのセッションを紹介
KubeCon China 2024から、ローカルでLLMを実行するSecond Stateのセッションを紹介する。
2024年11月8日 9:01
KubeCon China 2024から、大規模言語モデルをローカルのPCやエッジデバイスで実行する方法を解説するSecond Stateのセッションを紹介する。プレゼンターはSecond StateのCEO、Michael Yuan氏だ。

プレゼテーションとデモを行ったMichael Yuan氏
ローカルでのLLM実行をデモで見せるセッション
セッションのタイトルが「Run LLM agents on self-hosted devices」と題されているように、大規模言語モデルの実行をクラウド側ではなくローカルのノートPCやエッジで行うことを実演する内容だ。スライドは少なく実際にチャットを行うデモを見せることで、確かにローカルのデバイスで実行できることを示している。
デモは3つ用意されており、タイトルにあるようにローカルでLLMを実行し、チャットを行うものが最初のデモとして紹介された。
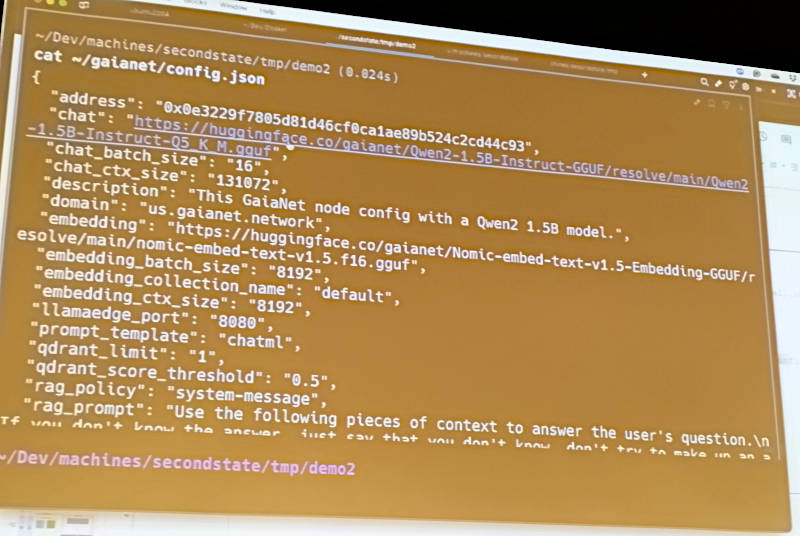
チャットボットの構成ファイルをエディターで見せながら解説
デモで利用したモデルは、HuggingFaceで公開されているQwen2 1.5Bを利用していることがわかる。
実際に起動してチャットを行うYuan氏
チャットの内容は香港で2日間の観光を行う際の提案を質問するというもので、香港に馴染みのある参加者なら納得できる回答となっていたようだ。

チャットで2日間の香港観光のプランを質問
またその内容をチャットから中国語に翻訳する質問にも的確に答えており、文脈を維持したまま翻訳のタスクを実行できることを示した。

チャットの内容を中国語に翻訳
このデモでは軽量な実行モデル、どのCPU、GPUでも実行できること、さまざまなモデルとの入れ換えが可能なこと、そしてアプリケーション内への組み込みが容易であることなどを特徴として挙げた。

ローカルでLLMを実行できることの利点を解説
その上でAppleのエコシステム、Googleが提供するAndroidのエコシステムともにローカルデバイスでの生成型AIの実行を目指しており、このモデルはどちらのエコシステムにおいても有効であることを説明した。メーカーが提供するスマートフォンにロックインされることなく、しかもネットワークの常時接続がなくてもLLMを実行できるアーキテクチャーがすでに存在していることを示した形になった。
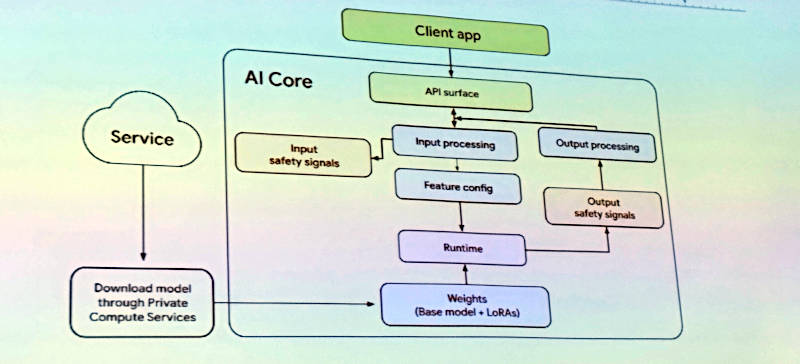
ローカルでLLMを実行するためのアーキテクチャーを解説
このアーキテクチャー図では、ランタイムを通じてダウンロードされたモデルを利用する仕組みが解説されており、そのランタイムとしてはSecond Stateが開発しオープンソースとしてCNCFのサンドボックスプロジェクトとして公開されているWasmEdgeを利用していることが解説された。
ローカル実行のランタイムはWasmEdgeを利用
新たなフレームワークGaiaNet
このデモの実装にはGaiaNetという新しいフレームワークが使われており、以下のGitHubページに解説が公開されている。

ローカルでLLMを実行するためのフレームワーク、GaiaNetの紹介
●GaiaNet AI:https://github.com/GaiaNet-AI
このページには日本語のreadmeファイルも用意されているので、ぜひ参考にして欲しい。冒頭のチャットボットの構成ファイルはconfig.jsonの内容を確認したものである。
●日本語のreadme:https://github.com/GaiaNet-AI/gaianet-node/blob/main/README-ja.md
公式ドキュメントも公開されている。
●公式ドキュメントサイト:https://docs.gaianet.ai/intro/
GaiaNetはローカルでLLMを実行するだけではなく2つ目のデモの解説の中で紹介された「大規模言語モデルに自身の知識を追加することで特定の領域の正確性を増す」ことと同時に「その追加された知識に対する報酬を提供する」モデルも仕組みとして実装されていることが紹介された。この部分は時間が短かった関係でセッションの中では省略されてしまったが、大規模言語モデルのハルシネーションを抑制しながら、データを提供した専門家に対する報酬を与えるという現在の生成型AIの欠点の補完を狙っているようだ。
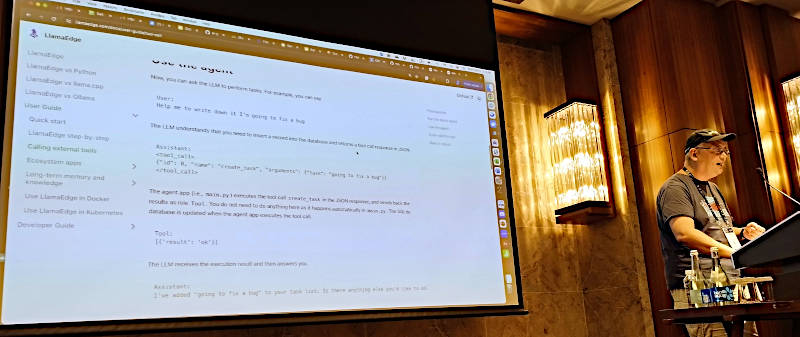
知識を追加することで正確性を増すデモを見せるYuan氏
ここで2番目のデモとして、モデルに知識を追加することでチャットボットの回答の質が向上する部分を見せた。デモで利用したのはLlamaEdgeだ。LlamaEdgeはWasmEdgeの上にLLMを実装したランタイムとAPI Serverのセットと言えるソフトウェアだ。
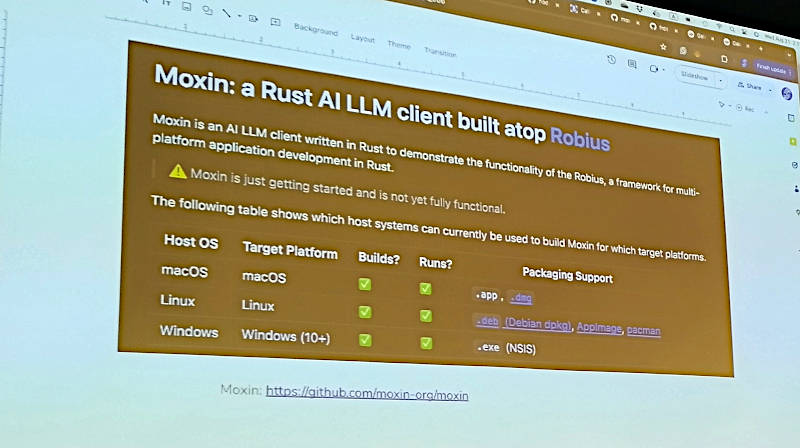
LLMのユーザーインターフェースをRustで実装したMoxinの解説
Yuan氏はチャットボット以外のアプリケーションのためにはユーザーインターフェースが必要となる場合もあるだろうと説明し、マルチプラットフォームでユーザーインターフェースを開発するためのMoxinというツールを紹介した。MoxinはRustで開発されたマルチプラットフォームのユーザーインターフェースのためのツールRobiusをベースにしている。それぞれのツールについては下記の公式ページを参照して欲しい。
●Moxin公式ページ:https://www.moxin.app/
●Robius公式ページ:https://robius.rs/
短い時間の中で3つ目のデモまで紹介したかったYuan氏であったが、2つ目のデモ、知識ベースを追加して回答の質を向上させるところまでが時間の限界であった。会場はトレンドなトピックであると同時に中国出身のMichael Yuan氏が登壇するとあって、満員の盛況となった。

満員となったMichael Yuan氏のセッションのようす
WasmEdgeのコントリビュータによるLlamaEdgeに関するセッション
またLLMの実行についてはLlamaEdgeに関する別のセッションが行われたので、そちらも簡単に紹介しよう。

「Wasm for Portable AI Inference Across GPUs, CPUs, OS and Cloud-Native Environments」というタイトル
セッションを担当したのはWasmEdgeのコントリビュータで北京からやってきたMiley Fu氏とHung-Ying Tai氏だ。
Fu氏はAIの実行にWebAssembly(WASM)が必要な理由を紹介。ここではMichael Yuan氏と同様に、クラウドに依存しないローカルでの実行と高速かつ小さな実行モジュール、そしてセキュアであることなどを挙げて、それらがWASMの特徴とマッチしていることを訴求した。

WASMの特徴がそのまま活かされる生成型AIのアプリケーション
その上でWasmEdgeの上に実装されたLlamaEdgeを紹介。ここではさまざまなOSやCPU/GPUの上で実行できる高い互換性を訴求している。

LlamaEdgeの紹介
さらにLlamaEdgeの特徴を紹介するスライドを使って説明した。ここではランタイムとAPI Serverを合計しても30MB以下という軽量さを強調した。

LlamaEdgeの詳細な特徴
そしてクラウドネイティブという文脈ではKubernetesのさまざまなバリエーションでも実行できること、コンテナランタイムとも連係できることなどを説明した。
そのセッションではLlamaEdgeを使ったデモなども行われ、ローカルでマルチプラットフォームな生成型AIの実行形として強くその存在をアピールした形になった。

クラウドネイティブなシステムにおいてもエコシステムの一員であることを訴求
セッション後に今回登壇した3名をブースで撮影。ちなみに北京から参加したSecond Stateのエンジニアは中国語でのプレゼンテーションが許されているカンファンレンスであるにも関わらず、流暢な英語で解説を行っており、中国本土の若いエンジニアの英語力が日本のエンジニアのそれを遥かに凌駕していることを感じたセッションでもあった。

Second Stateブースの前で撮影
前半のMichael Yuan氏のスライドは以下からアクセスできる。
●スライド(PDF):Run LLM agents on self-hosted devices
- この記事のキーワード
この記事をシェアしてください
関連記事
Cloud Native Wasm Dayから大規模言語モデルをWasmで実行するデモを解説するセッションを紹介
2024年2月8日 6:00
KubeCon Europe 2025、エッジでAIを実行するKubeEdge Sednaのセッションを紹介
2025年5月29日 6:00
WasmCon 2023からLLMをWASMで実装するセッションを紹介
2023年12月1日 6:00
KubeCon China 2025開催、中国ベンダーによるキーノートを紹介
2025年9月8日 6:01
Civo Navigate North America 2024、元Dockerで現DaggerのCEO、Solomon Hykesのインタビューを紹介
2024年5月10日 6:00
KubeCon Europe 2026:Anthropicのエンジニアが解説するMCPの未来とは?
6月22日 6:01
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
