ファインチューニングを行う手順とポイント
第12回は、OpenAIが公開しているガイドをベースに、ファインチューニングを行う手順とポイントについて解説します。
2024年3月1日 9:00
目次
- はじめに
- 実施前にプロンプトを工夫する
- ファインチューニングのやり方
- 3つのハイパーパラメータ
- ファインチューニングのコスト
ファインチューニングは別料金なので、実際にどれくらいコストがかかるか気になりますね。図3の想定をもとにトレーニングにかかる費用を試算してみましょう。価格
GPT-3.5 Turboを利用したファインチューニングの価格は以下のとおりです。
- トレーニング時:$0.008/1,000トークン
- 利用時(入力):$0.012/1,000トークン
- 利用時(出力):$0.016/1,000トークン
バッチサイズ バッチサイズはコストに影響しませんが、ここでは50としておきます。5,000メッセージのうち、評価用とテスト用にそれぞれ10%(500メッセージ)ずつ分割することにします。バッチサイズが50だと、1つのバッチで50メッセージずつ処理されることになります。全部で4,500メッセージ分処理するので、1つのジョブは90バッチで処理が終わります(モデルの重みは90回更新されることになります)。 エポック数 エポック数を3とし、上記のジョブを3回繰り返すことにします。 トレーニングにかかる費用 トレーニング時の費用は、次の式で計算されます。トークナイザー第9回で、トークン数はOpenAIが提供するトークナイザーで調べられると紹介しました。実際に試してみましょう。 図4はトークナイザーに“トークン数とエポック数”という文字列を入れてみたものです。GPT-3.5やGPTー4はGPT-3より効率的なトークナイザーに改良されており、12文字で11トークンとカウントされていることがわかります。前回は日本語1文字2トークンくらいで試算しましたが、1文字1トークンくらいで見積もっても良さそうですね。図4:トークナイザー(https://platform.openai.com/tokenizer)トークン数(データ処理量) × エポック数(学習の回数) × トークン単価($0.008/1000)通貨レートを1ドル150円とすると、次のような計算で合計で約2,700円の見積りとなります。トレーニング:4,500メッセージ × 160トークン × 3回 × (0.008/1000)ドル × 150円=2,592円1回だけなら大した額ではなさそうに思えますね、しかし、機械学習は何度もトライ&エラーを繰り返してゴールに近づくものなので、下手するとけっこう高く付きそうです。とにもかくにも慎重に計画を立てて行いましょう。 おわりに 今回は、以下のような内容について学習しました。
テスト:500メッセージ × 160トークン × 1回 × (0.008/1000)ドル × 150円=96円- OpenAIはGpt-3.5 turboのファインチューニングを行うためのSDKやAPI、UIツール、実施ガイドなどを提供している
- プロンプトチェーンはタスクごとに小さなプロンプトに分割して連鎖するテクニック
- トレーニングに使う学習データは実稼働環境に似た会話セットを準備する必要がある
- 「こう質問したら(Prompt)、こう解答する(Completion)」という会話セットはメッセージという形式で記述される
- 最適なプロンプトを見つけ出し、トレーニングサンプル(メッセージ)1つずつに含める
- 学習データセットはトレーニング用と評価用、最終テスト用に分割する
- ミニバッチ学習法で過学習を防ぐためにバッチサイズを指定する
- トレーニングのジョブを1回流すだけでなくエポック数だけジョブを繰り返し実行する
- 学習率は学習度合いを指示する係数であるが、大きくすると過学習を引き起こす
- 日本語の場合は1文字1トークン程度で計算できそう。トークナイザーで確認できる
- ファインチューニングは子育てと一緒。モデルを生成して終わりではなく、そこをスタートとして育ててゆく覚悟が必要
- おわりに
はじめに
前回は企業データを追加学習する3つの方法のうち、コンテキスト学習とファインチューニングについて解説しました。今回は、ファインチューニングのやり方について解説します。
ファインチューニングを行う手順を学ぶことで、ファインチューニングと言えども機械学習の基本に沿って学習すること、そのため学習データ(トレーニングサンプル)の準備が大変なこと、でもうまく学習すれば良い結果が得られそうなことなども理解していただければと思います。
実施前にプロンプトを工夫する
OpenAIは、ファインチューニング可能なモデル(Gpt-3.5 turbo)だけでなく、ファインチューニングを行うためのSDKやAPI、UIツール、実施ガイドなどを提供してくれています(至れり尽くせりですね)。しかし、これらをの道具が揃ったとしても、やっぱり機械学習なので学習データの準備やトレーニングで学習効果を高める作業はかなり大変です。また、モデルを生成して終わりではなく、運用しながら改善・改良を続ける覚悟も必要なのがファインチューニングです。
そのため、OpenAIもファインチューニングに踏み切る前にプロンプトエンジニアリング、プロンプトチェーン、関数呼び出しなどで目的が果たせないか試してみることを推奨しています。
関数呼び出し(function calling)については第9回で紹介したので、今回はプロンプトチェーン(Prompt Chaining)について解説しましょう。
プロンプトチェーンとは、複雑で長いプロンプトを生成AIに投げるのではなく、タスクごとに小さなプロンプトに分割するテクニックです(図1)。1つのプロンプトの出力を次のプロンプトの入力として渡すのでチェーンと言うのですね。
人間だっていっぺんに言われるとわけが分からなくなりますが、順を追って質問してくれると話しやすいです。生成AIも同じだと考えて質問の仕方を工夫しましょう。これが上達すれば、人に対する質問力もアップするかもしれません。
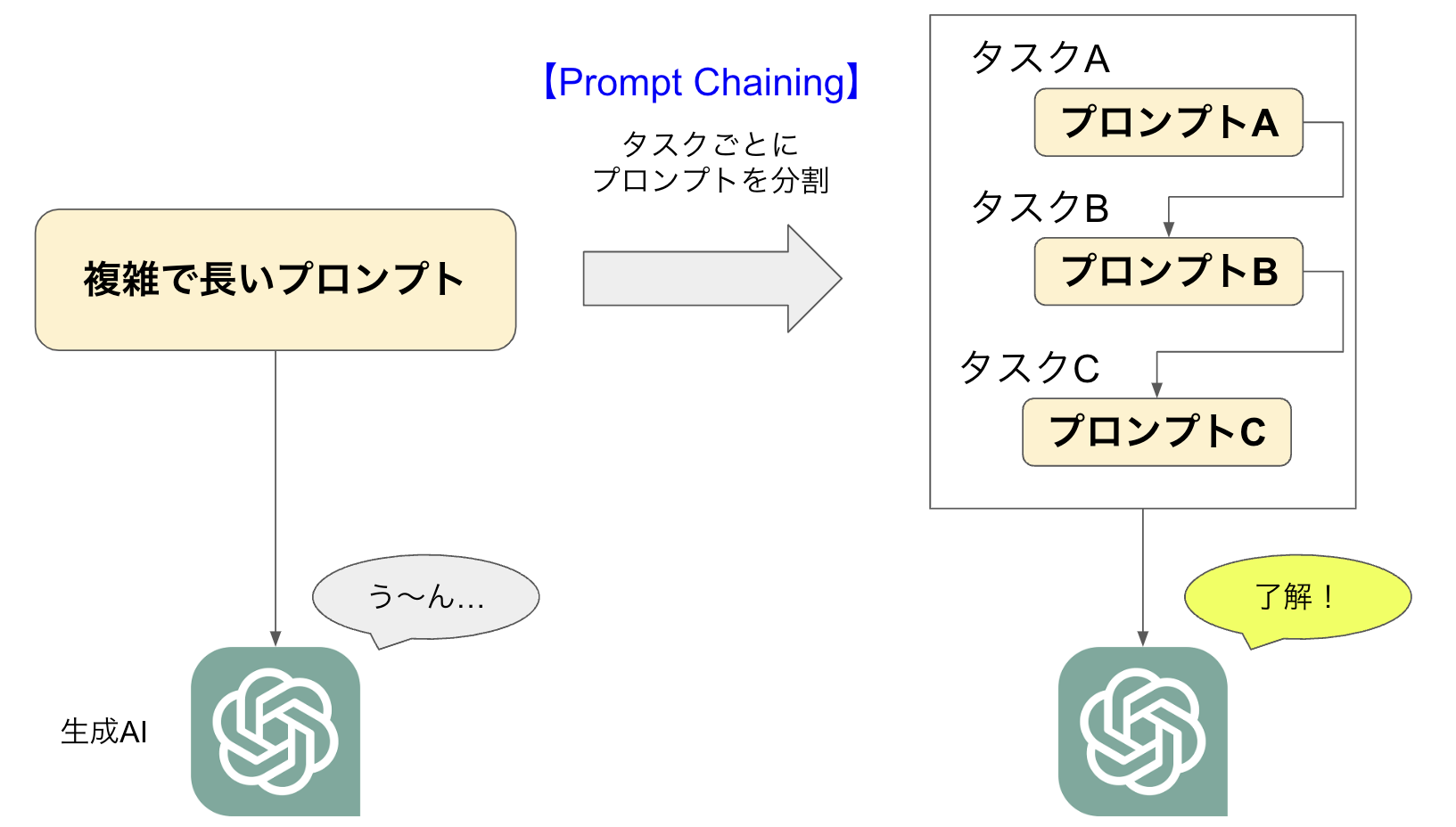
図1:プロンプトチェーン
ファインチューニングのやり方
OpenAIのガイドをベースに、ファインチューニングを行う手順とポイントを図2にまとめました。この図を使ってファインチューニングのやり方を説明しましょう。
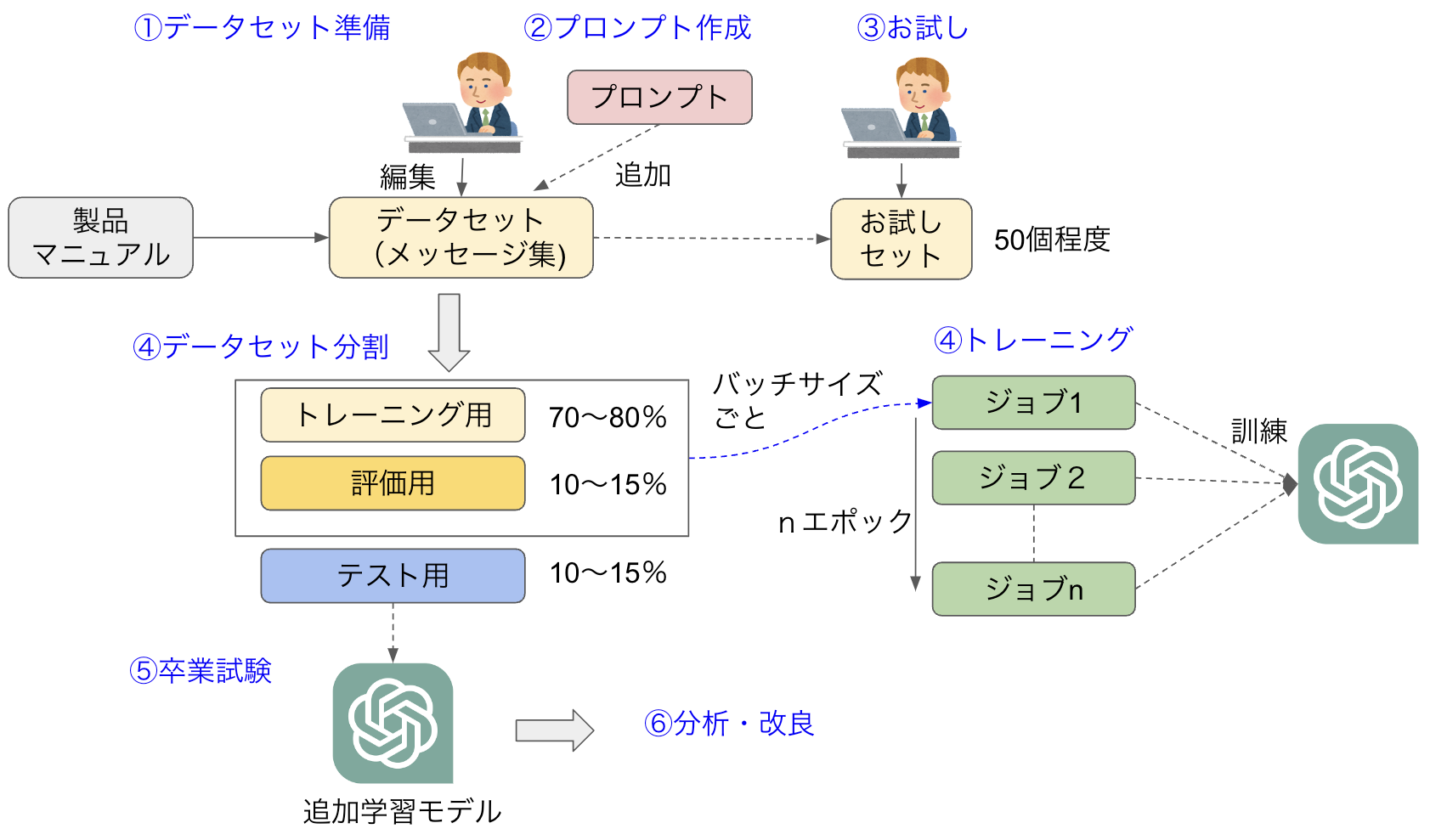
図2:ファインチューニングの手順
(1)本番をイメージしたデータセットを準備
例えば、製品マニュアルの内容をもとに顧客サポートbotを作成するとしましょう。生成AIの実力を知るとなんか簡単にできそうに思いますが、単にマニュアル1冊を数回読ませて期待に応えてくれるほど甘くありません。トレーニングに使う学習データは、実稼働環境に似た会話セットを準備する必要があります。具体的には製品マニュアルの内容から「こう質問したら(Prompt)、こう解答する(Completion)」というトレーニングサンプルを準備して学習に使うことになります。
ChatGPT APIでは、role(役割)とcontent(内容)を格納したリストをリクエストパラメーターとして送信するので、トレーニングサンプルもこの形式に則ったものになります。
roleは次の3つから選択できます。
- −system:ChatGPTに対して条件を伝えたり、状況を伝えたりする
- −user:ユーザーからのPrompt(質問や指示)を送信する
- −assistant:ユーザーからのPromptに対して、適切なCompletion(回答や情報)を提供する
学習に使うトレーニングサンプルは、次のように"messages"という文にrole(役割)とcontent(内容)を記述する形式で記述します。
{"messages": [ {"role": "user", "content": "在庫引当とは?"}, {"role": "assistant", "content": "在庫引当は、ある商品を受注した際に在庫から確保する処理です"}]}
ERP製品の学習データを作る想定で、3つほどトレーニングサンプルを作ってみました(表)。
表:在庫引当に関するトレーニングサンプル(メッセージ)
| Prompt | Completion |
|---|---|
| 在庫引当とは? | 在庫引当は、ある商品を受注した際に在庫から確保する処理です |
| 在庫引当が行われないのは どのようなケースか? | 在庫引当可能な在庫数は有効在庫数以下に限られます。例えば、ある商品の注文が5個入り有効在庫数が3だった場合、在庫引当可能な在庫数は2個となります |
| 有効在庫数より受注数が多い場合は 在庫引当が全数できません | 受注数が全数在庫引当できない場合は部分在庫引当となります。引当されなかった分の受注数は、次回在庫が補充された時点で受注日の早い優先順で自動的に在庫引当されます |
Promptを質問形式にするのは特定のQ&Aモデルを作るときに有効ですが、Promptが必ず質問というわけではありません。目的によっては指示形式(◯◯してください)や状況説明形式(◯◯という状況になっていますので…)など、いろいろな形式が考えられます。あえてPromptの形式に多様性を持たせてモデルの柔軟性と適応性を高める場合もあります。例えば表の3つ目のメッセージはPromptを説明形式とし、Completionを詳細説明としています。
こんなふうに在庫引当に関する適切なメッセージを数多く準備すればするほど、在庫引当に関するプロンプトに対して良い感じで回答してくれるようになります。しかし、メッセージを用意するには一筋縄では行きません。ここはシンプルに3つの質問で3つのメッセージとしていますが、実際は「在庫引当とは?」「在庫引当が行われないのは?」などの各Promptに対して10種類くらいずつCompletionを用意します。とんでもなく多くの、かつ良質なメッセージを考えて作る必要があるのです。
ファインチューニングの学習データを揃える大変さにげんなりしたでしょうか。しかし、例えばマニュアルからトレーニングセットのネタを作成する作業をAIに手伝ってもらうなど工夫の余地はありそうなので、いろいろと試してみましょう。
(2)最適なプロンプトを作成
ファインチューニングにおいてもプロンプトは重要なので、トレーニングを行う前にどのようなプロンプトで学習させるのが良いか試行錯誤しましょう。単に「読んで覚えよ」ではなく、役割や目的、期待される結果なども伝えた上で学習させた方が効果があります。そして、最適なプロンプトが見つかったら、それをすべてのトレーニングサンプルに含めます。
(3)お試し
最初からすべてのサンプルをジョブに流すのではなく、まずは50個程度のトレーニングサンプルでお試しファインチューニングを行います。機械学習は最初からそんなにうまく行きませんので、コストや労力を無駄にしないように気をつけましょう。お試しで効果の兆しが見られるようならそのまま続けますが、改善が見られない場合は学習データの見直しやプロンプトの改良などの対策を行う必要があります。
(4)評価データとテストデータの分離
機械学習では、ホールド・アウト法という過学習(over fitting)を防ぐためにトレーニングデータとは別に評価データ(validation data)を用意します。トレーニング中に両方の統計値が提供されるので、評価データで上達ぶりをチェックしながらトレーニングするのです。
一見するとこれで十分なのですが、実はもうひと工夫が必要です。トレーニングを繰り返す際に評価データが良くなるようにチューニングしながら学習するので、どうしてもvariance(学習データに依存したモデルになって汎化誤差が大きくなること)が生じます。そのため、評価データとは別にテストデータを取り分けておき、トレーニング終了後にモデルが期待する水準を満たしたかを最終確認します。
一般的にトレーニングデータが70〜80%、評価データが10〜15%、テストデータが10〜15%くらいの割合で分割します。トレーニングデータと評価データは、ファインチューニングジョブに含めますが、テストデータはトレーニングには使わず卒業試験用として使うのです。
(5)トレーニング
トレーニングサンプルが準備できたら、いよいよトレーニングです。用意したトレーニングサンプルのファイルを「Files API」でアップロードし、OpenAIの提供する「fine-tuning UI」などを使ってファインチューニングジョブを作成します。そしてOpenAI SDKでファインチューニングを開始してください。モデルのトレーニングが完了するとメールで通知されます。
(6)卒業試験
エポックで指定した回数のジョブが成功すると、モデルは推論ができるようになっています。最終エポックの評価データを確認して、これでOKと判断できたらいよいよ卒業試験です。取り分けておいたテストデータで最終テストを行い、期待通りの性能を発揮しているか、過学習が起きていないかを確認します。
(7)分析・改良・反復する
ジョブが完了すると、トレーニングの過程で取得したメトリクスが提供されます。メトリクスとは「指標」や「測定基準」という意味で、ここではトレーニング損失、トレーニングトークンの精度、テスト損失、テストトークンの精度などが提供されます。これらのメトリクスを確認することで、トレーニングが健全に行われたかを判断できます。しかし、役に立つものかどうかは、実際にプロンプトを投げて試してみることになります。
推論モデルは、たとえ期待する効果が得られたとしても、最初に作っただけで放置できるほど楽ではありません。本番運用して直面する課題を解決したり、より精度を高めるために改良し続ける必要があります。そのためにファインチューニング後のモデルに対して、データを追加学習させてさらにファインチューニングすることもできます。
ファインチューニング後にも手間暇がかかることはとかく見落としがちです。企業でファインチューニングをやろうと言うのは簡単ですが、リリースしたあとの運用・メンテナンス負荷や継続的な改良作業も計画に入れておきましょう。
3つのハイパーパラメータ
pGPT-3.5 turboのファインチューニングでトレーニングの際に指定できるハイパーパラメータは次の3つです。ハイパーパラメータとは、モデルに直接指示する内部パラメータと違い、モデルの学習プロセスをコントロールするための外部パラメータです。
- エポック数:ジョブを実行する回数
- バッチサイズ:1回に処理するトレーニングサンプル量
- 学習率:モデルに対する学習の深さ
最初はいずれも指定せずにおまかせでトレーニングすることが推奨されていますが、簡単に説明しておきましょう。
エポック数
エポック数は、何回学習するかというジョブ数です。例えば、エポック数が3の場合、一連のデータセットを学習するジョブを3回実行します。
人間はドキュメントを1回読んだだけでは頭に入りきらず、何回か繰り返し学習してようやく覚えることができます(英単語の勉強を思い出してください)。AIも同じです。ドキュメント(トークン)を繰り返して学習することで「あ、さっきまではわからなかったけど、今ならわかるぞ」というようにパラメータが最適化されてゆくのです。
バッチサイズ
機械学習ではミニバッチ学習法と言い、学習データを細かな単位(バッチサイズ)に小分けしてそれらをランダムな順で学習する方法がよく使われています。これはGPUメモリ容量の制限を避けるという意味もありますが、確率的勾配降下法(Stochastic Gradient Descent:SGD)により学習効果が高まるからです。
確率的勾配降下法とは、誤差を小さくするために自律調整する仕組みです。バッチサイズが大きいとトレーニング速度は向上しますが、トレーニングデータに対する過学習のリスクが高まります。一方、バッチサイズを小さくすると、ミニバッチごとにモデルのパラメータ(重み)を更新することになります。ミニバッチごとに自律調整されるため、モデルの汎化能力が向上するのです。
ハイパラメータで指定するバッチサイズは、ミニバッチごとに処理するトレーニングサンプル数です。例えば、トレーニングサンプルを5,000メッセージ分用意できたとしましょう。バッチサイズを50に指定すると、モデルは50ずつ学習してその都度パラメータ(重み)を更新します。このミニバッチを100回行った時点で1ジョブが終了し、エポックが3の場合はこの一連の作業を3回繰り返すことになります。
学習率
学習率(learning rate multiplier)は、モデルに対する学習度合いです。モデルの追加学習が収束していないように見える場合に「もっと学習しよう」と調整する係数ですが、変に高くすると追加した(少量の)データで過学習してしまい、せっかくすごい性能を発揮していたオリジナルの重みバランスが崩れてしまいます。多くの場合、これらの値を変更するよりも学習データを改善する方が効果があります。
OpenAI DevDayで発表されたGPT-4 Turboは、入力可能な文字数がGPT-4 API比べて4倍の16,385トークンに増えました。このタイミングでGPT-3.5モデルも「GPT-3.5 Turbo-1106」がリリースされ、コンテキストの最大長が同じく16,385トークンまで増えています。
つまり「GPT-3.5 Turbo-1106」を用いてファインチューニングを行う場合、トレーニングサンプルの大きさはMax16,385トークンにということになります(超過した分はカットされます)。
ファインチューニングのコスト
ファインチューニングは別料金なので、実際にどれくらいコストがかかるか気になりますね。図3の想定をもとにトレーニングにかかる費用を試算してみましょう。
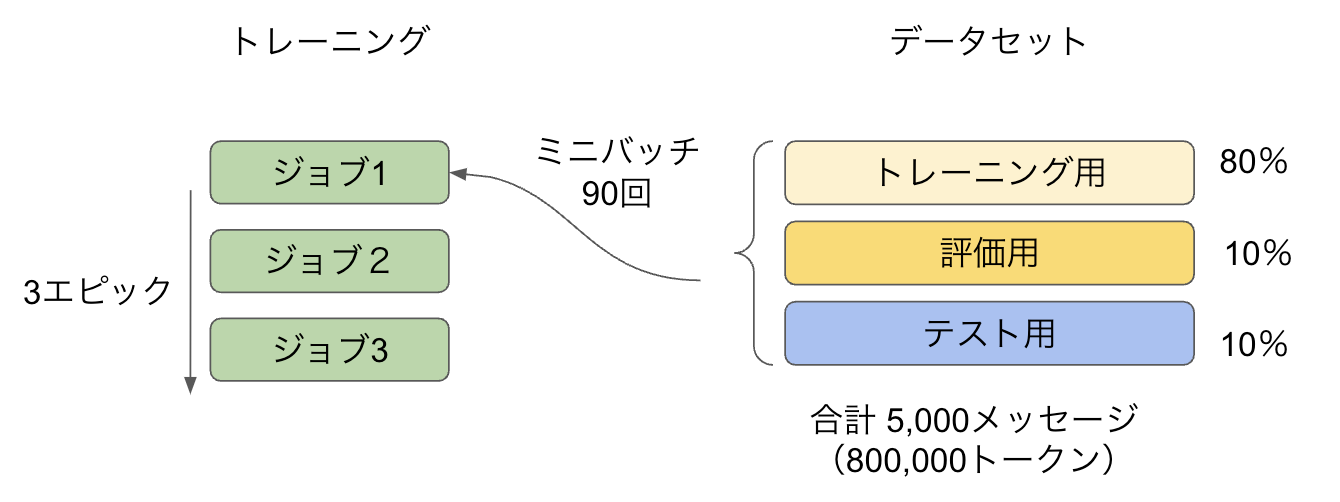
図3:ファインチューニングのコスト見積り
価格
GPT-3.5 Turboを利用したファインチューニングの価格は以下のとおりです。
- トレーニング時:$0.008/1,000トークン
- 利用時(入力):$0.012/1,000トークン
- 利用時(出力):$0.016/1,000トークン
学習データの量
学習に使うトレーニングサンプルを評価用を含んで5,000メッセージ分用意するとしましょう。1つのトレーニングサンプル(メッセージ)が160トークンだとすると、全部で約800,000トークンということになります。
第9回で、トークン数はOpenAIが提供するトークナイザーで調べられると紹介しました。実際に試してみましょう。
図4はトークナイザーに“トークン数とエポック数”という文字列を入れてみたものです。GPT-3.5やGPTー4はGPT-3より効率的なトークナイザーに改良されており、12文字で11トークンとカウントされていることがわかります。前回は日本語1文字2トークンくらいで試算しましたが、1文字1トークンくらいで見積もっても良さそうですね。
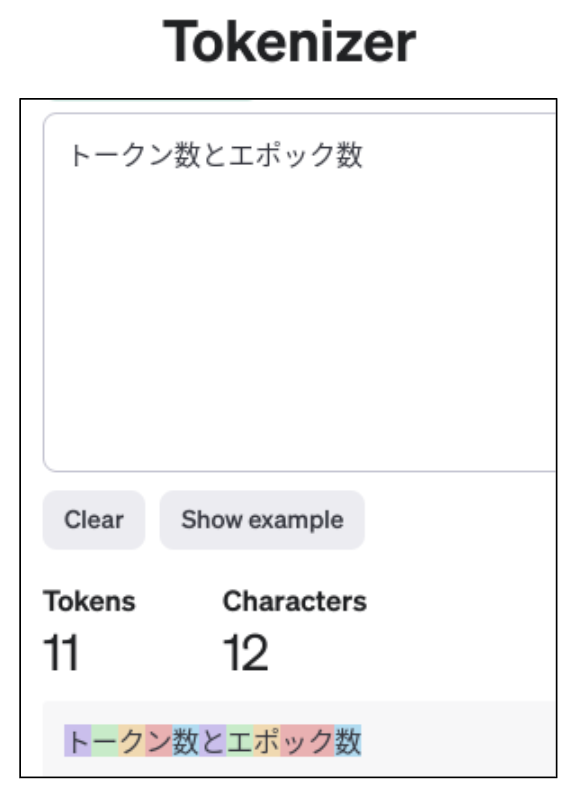
図4:トークナイザー(https://platform.openai.com/tokenizer)
バッチサイズ
バッチサイズはコストに影響しませんが、ここでは50としておきます。5,000メッセージのうち、評価用とテスト用にそれぞれ10%(500メッセージ)ずつ分割することにします。バッチサイズが50だと、1つのバッチで50メッセージずつ処理されることになります。全部で4,500メッセージ分処理するので、1つのジョブは90バッチで処理が終わります(モデルの重みは90回更新されることになります)。
エポック数
エポック数を3とし、上記のジョブを3回繰り返すことにします。
トレーニングにかかる費用
トレーニング時の費用は、次の式で計算されます。
トークン数(データ処理量) × エポック数(学習の回数) × トークン単価($0.008/1000)
通貨レートを1ドル150円とすると、次のような計算で合計で約2,700円の見積りとなります。
トレーニング:4,500メッセージ × 160トークン × 3回 × (0.008/1000)ドル × 150円=2,592円
テスト:500メッセージ × 160トークン × 1回 × (0.008/1000)ドル × 150円=96円
1回だけなら大した額ではなさそうに思えますね、しかし、機械学習は何度もトライ&エラーを繰り返してゴールに近づくものなので、下手するとけっこう高く付きそうです。とにもかくにも慎重に計画を立てて行いましょう。
おわりに
今回は、以下のような内容について学習しました。
- OpenAIはGpt-3.5 turboのファインチューニングを行うためのSDKやAPI、UIツール、実施ガイドなどを提供している
- プロンプトチェーンはタスクごとに小さなプロンプトに分割して連鎖するテクニック
- トレーニングに使う学習データは実稼働環境に似た会話セットを準備する必要がある
- 「こう質問したら(Prompt)、こう解答する(Completion)」という会話セットはメッセージという形式で記述される
- 最適なプロンプトを見つけ出し、トレーニングサンプル(メッセージ)1つずつに含める
- 学習データセットはトレーニング用と評価用、最終テスト用に分割する
- ミニバッチ学習法で過学習を防ぐためにバッチサイズを指定する
- トレーニングのジョブを1回流すだけでなくエポック数だけジョブを繰り返し実行する
- 学習率は学習度合いを指示する係数であるが、大きくすると過学習を引き起こす
- 日本語の場合は1文字1トークン程度で計算できそう。トークナイザーで確認できる
- ファインチューニングは子育てと一緒。モデルを生成して終わりではなく、そこをスタートとして育ててゆく覚悟が必要
次回は、ファインチューニングとRAG、ベクトルデータベースを組み合わせた独自データの追加学習方法について解説します。
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
