独自データを追加学習する「コンテキスト学習」と「ファインチューニング」
第11回は、生成AIに独自データを追加学習させて特定の目的を実現する方法の中から、「コンテキスト学習」と「ファインチューニング」について解説します。
2024年2月8日 6:30
はじめに
2023年は、汎用データを学習してすごく賢くなった生成AIの出現に世界中が沸き立った年でした。そして2024年は次のステップとして、生成AIに独自データを追加学習させて特定の目的を実現するサービスが次々と現れそうです。今回はいくつかある「独自データを追加学習する方法」の中から「コンテキスト学習」と「ファインチューニング」について解説します。
生成AIに追加学習する構想
GPTなどの生成AIは、インターネットなどに公開されている膨大な情報を学習して賢くなっています。しかし、外観検査ではねられた異常画像、店舗のPOSデータなど、ネット上で公開されていないデータは学習していないので、これらに関して質問しても「知りません」となってしまいます。
2018年前後のAIブームの際は、このような独自データを大量に用意して機械学習させ、異常検知や需要予測などに活用しようという試みが世界中で行われました。それから5年、こうした取り組みは今もって熱く継続していますが、そこに彗星のごとく登場したのが生成AIです(図1)。
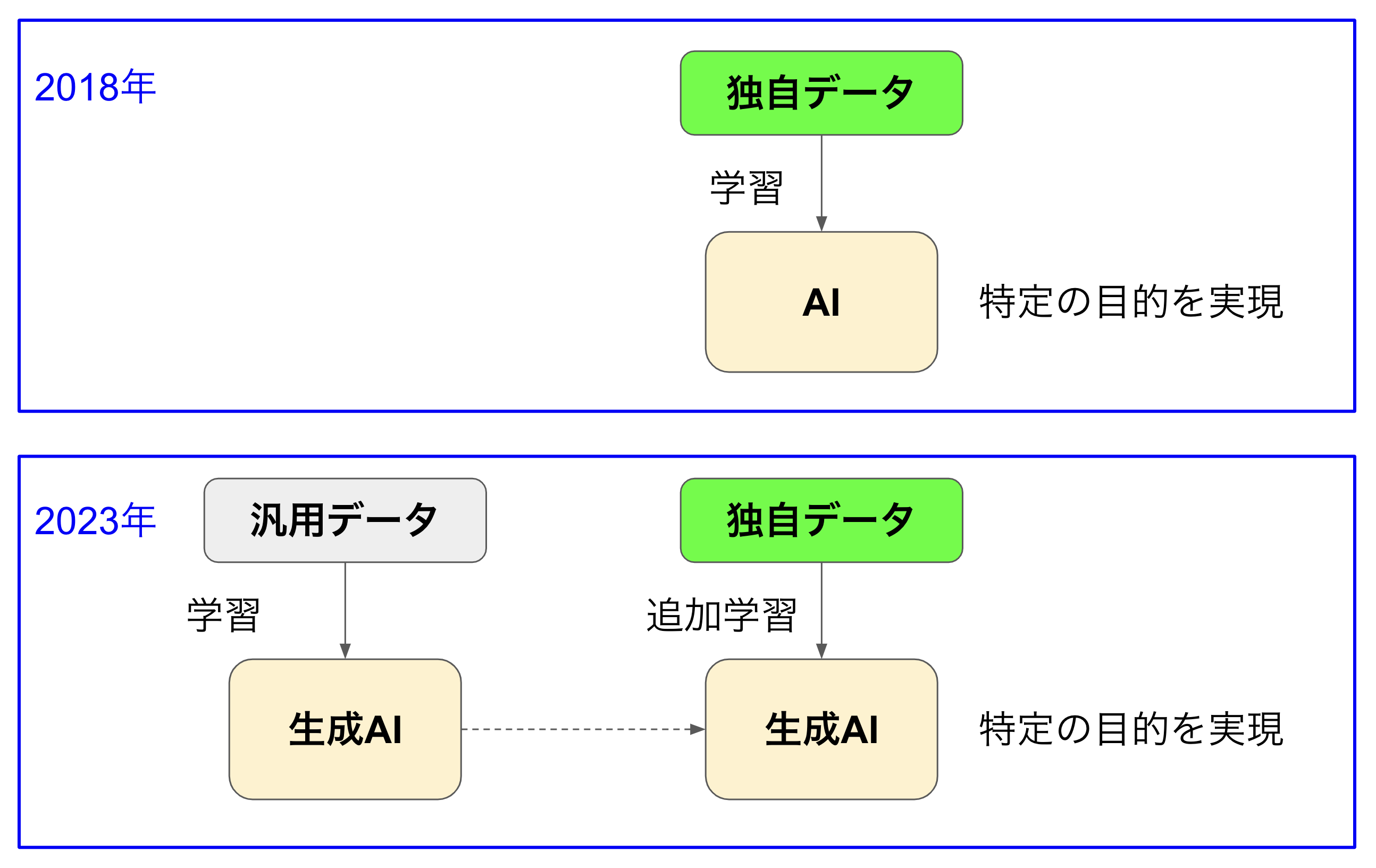
図1:生成AIを利用した独自データの学習
何もないところから独自データを学習させるのではなく、膨大なデータで学習した生成AIに追加学習させた方が良いかも知れない。生成AIの凄さを目の当たりにして、このように考えるのも当然なことです。
人間に置き換えて、中華料理店のご主人が我が子に「秘伝の八宝菜のレシピと作るコツ」を伝授するとしましょう。おそらく幼児の頃に料理のイロハから教えるよりも、知識が豊富な大人になってからレクチャーした方が飲み込みが早いはずです。基礎的な知識を豊富に持っている方が、追加の情報を理解しやすいというケースはありそうです。
独自データを学習したAIに期待される応用例
独自データを学習したAIの適用分野は多岐にわたります。図2に6つほど応用例を挙げました。
- 自社ECサイトの購買履歴を学習してOne on Oneマーケティングを行うレコメンデーション
- 特定の病気や症状の医療画像を学習して医療診断を支援するAI
- 特定業界・市場データで訓練した予測モデル
- 特定の製品の正常/異常データを学習した異常検知
- 過去の故障やインフラの劣化画像で訓練したリスク検知AI
- 自校の学習履歴や成績データで訓練してパーソナルな学習支援AI
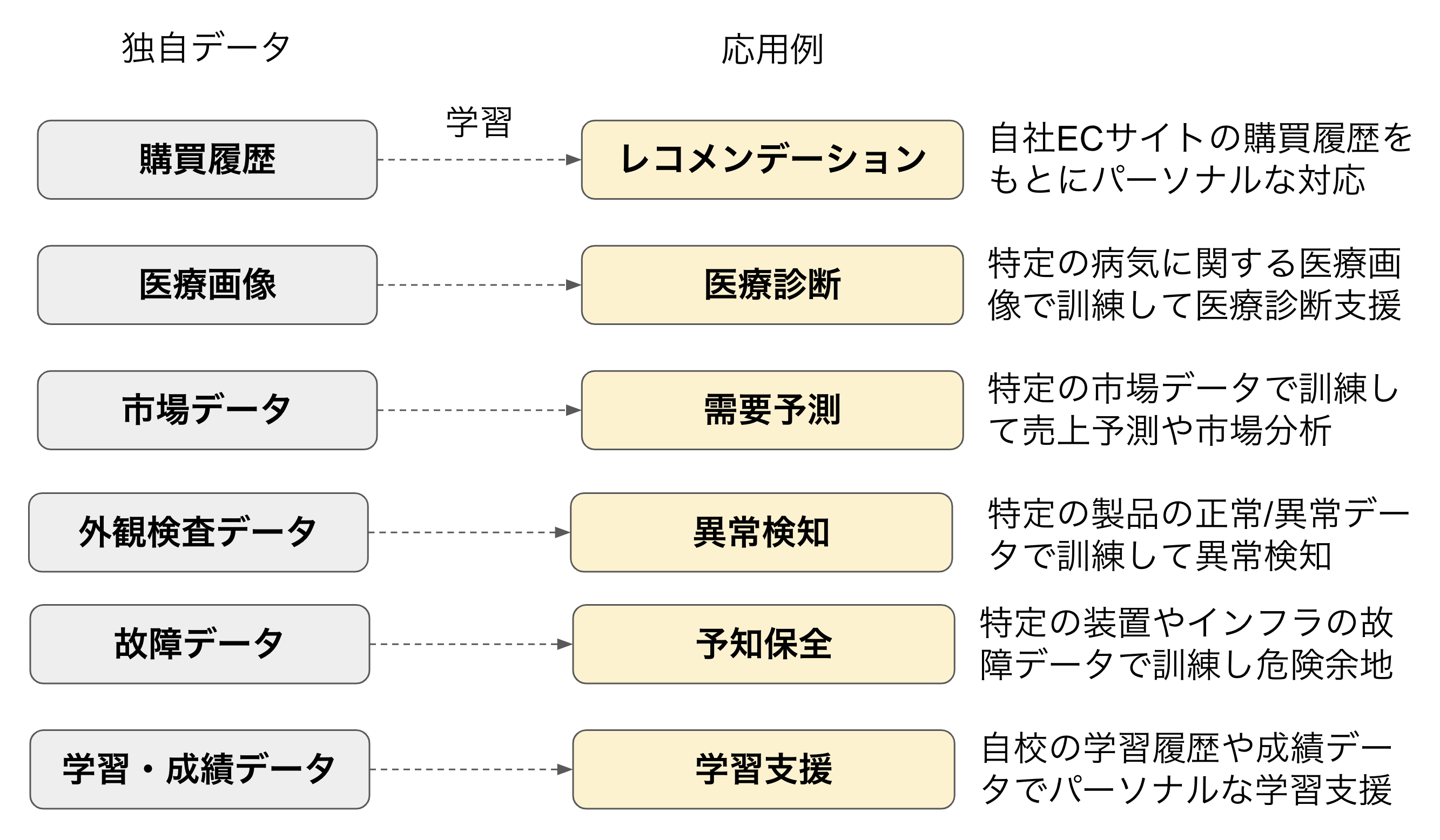
図2:独自データ学習AIに期待される応用例
どの例も2018年頃から見慣れたものですね。実際、こうした取り組みの事例は枚挙にいとまがなく、分野によっては一定の成果を果たしています。ただ、予測や診断、分析といったジャンルはなかなか難しい課題が多く、まだ十分な成果を出せているとは言えない状況でもあります。まあ、人間にしても予測や診断、分析は難易度が高いスキルなので、そう簡単ではないってことなのでしょう。
自社データを学習したAIに期待される応用例
追加学習するデータにも生成AIとの相性があり、相性が悪い場合は逆にモデルの性能が低下します。生成AIは膨大なデータを使って“次の単語予測クイズ”を徹底的に訓練した「言語の達人」です。クイズを極めるうちに文脈や文法を理解するようになり(理解しないと当たりません)、特にドキュメントやプログラミングコード(これも言語)に強いという特徴があります。この「言語に強い」という特性を活かすことができる独自データは得意ですが、そうでないものはうまく行きません。
得意分野の代表は自社ドキュメントの活用です。設計書や社内規程、契約書、製造指示書、テスト仕様書などの社内ドキュメントは言語で記述されたテキストデータなので、これを追加学習して顧客サービスや生産性向上に利用するのはお手のものです。利用方法はたくさん考えられますが、図3にいくつか例を挙げました。
- 製品マニュアルを学習して、顧客の質問に回答してくれるbotサービスを提供
- これまでの問合せ履歴データをもとに、FAQネタを指定数作成してもらう
- 社内文書や社内データをもとに、ナレッジデータベースを構築してもらう
- 設計書を読ませて、製造指示書やテスト仕様書、操作マニュアルなどを自動作成してもらう
どれも成功すればホワイトカラーの生産性が向上しますね。すでに多くの会社でこのような試みを行っており、それをビジネスとしてサービス化する企業も増えています。
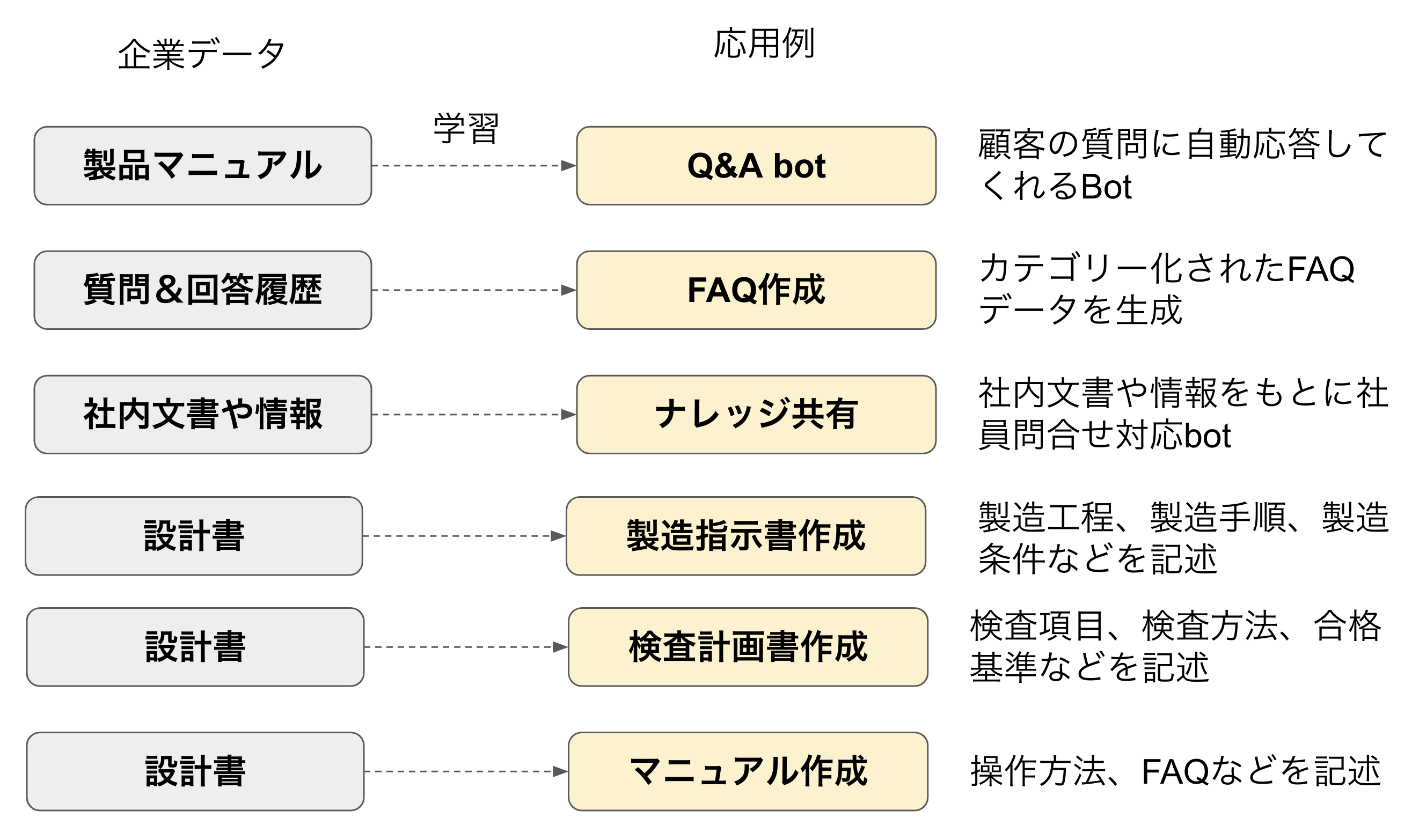
図3:企業データを追加学習して期待される応用例
自社データを追加学習させる3つの方法
実際、どのようにしたら追加学習できるのでしょうか。現時点で大規模言語モデル(LLM)に独自データを追加学習して、特定の目的を実現させる方法は主に3つあります(表)。今回は、この中からコンテキスト学習(In-Context Larning:ICL)とファインチューニングについて解説しましょう。
表:企業データを追加学習する主な方法
| 追加学習法 | 処理内容 |
|---|---|
| コンテキスト学習 (In-Context Learning) | ニューラルネットワークのすべての層のパラメータは凍結したまま。その状態で文章をプロンプトとして読ませ、そこで得た知識を用いてプロンプトに沿った回答をしてもらう方式 |
| ファインチューニング (Fine Tuning) | ニューラルネットワーク(NN)の一部の層だけパラメータを更新できるように解凍する。その状態で独自データを追加学習し、解凍した層のパラメータをいい塩梅に調整(ファイン・チューニング)する方法 |
| RAGとエンべディング (RAG&Enbedding) | 企業データをテキストからベクトルに変換したベクトルデータベースを作成しておく。プロンプトもベクトル変換し、ベクトルデータベースとプロンプトをベクトルデータ同士で突き合わせて回答を得る方法。回答はテキスト化してユーザーに返される |
コンテキスト学習
図4はGPT-4 Turboをモデルにしたコンテキスト学習(In-Context Learning)の概念図です。ネット上の膨大なデータを学習した生成AI(GPT-4)は、その学習範囲において最適なニューラルネットワークのパラメータとなっています。コンテキスト学習は、このパラメータを変更することなく、独自データを追加学習させ、新しく得た知識を使って回答させる方法です。
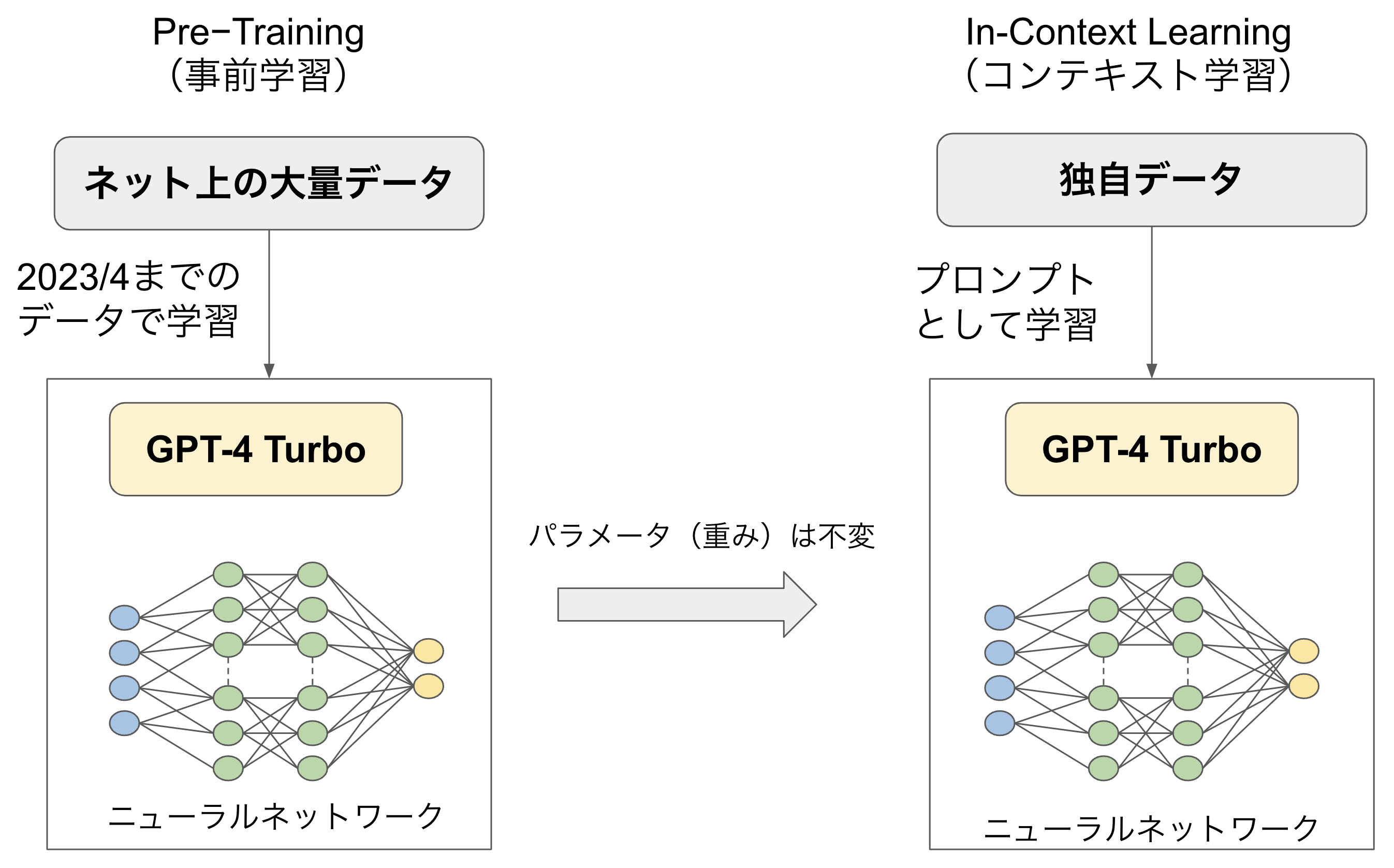
図4:インコンテキストラーニング
Contextという言葉は、ちょっと日本人には難しい単語ですが「文脈」や「状況」という意味で使われます。In-Context Learningは一般用語ですが、生成AIにおいてはユーザーからのプロンプトがContext(文脈)です。つまり、ユーザーとの対話や文章をそのまま追加学習する手法を指します。素の生成AIをそのまま利用するプロンプトエンジニアリング手法なので、プログラミング技術などがなくても試してみることができます。
前回で紹介したMy GPT(GPT Bulder)も、プロンプトの指示方法をわかりやすくサポートしたものなので、ベースはコンテキスト学習と言えます。
コンテキスト学習を試してみる
ChatGPT Plusを使ってインコンテキスト的な学習を試してみましょう。図5はChatGPT Plusを使った簡単な実験です。最初の質問で「大谷翔平は現在どこの球団に所属していますか?」と聞いたときは「エンゼルスに所属しています」ときっぱり回答してくれました。2023年4月までのデータでしか学んでいないので、年末に移籍したことを知らないのは当然と言えます。
そこで「12月10日のBBS NEWS JAPAN」で書かれている「大谷翔平、ドジャース移籍へ」という記事を読んでもらってからもう一度同じ質問をすると、今度は12月9日にドジャースに移籍したと正解を答えてくれます。
生成AIは、ユーザーからの直近の入力を考慮して一貫性のある対話を行います。その特性を利用して、こんなふうにテキストを追加で読ませるだけでその情報を使った応答をしてくれるのです。なお、ここではBBSのURLを読み取ってもらうのに、第5回で紹介した「WebPilot」というプラグインを使っています。
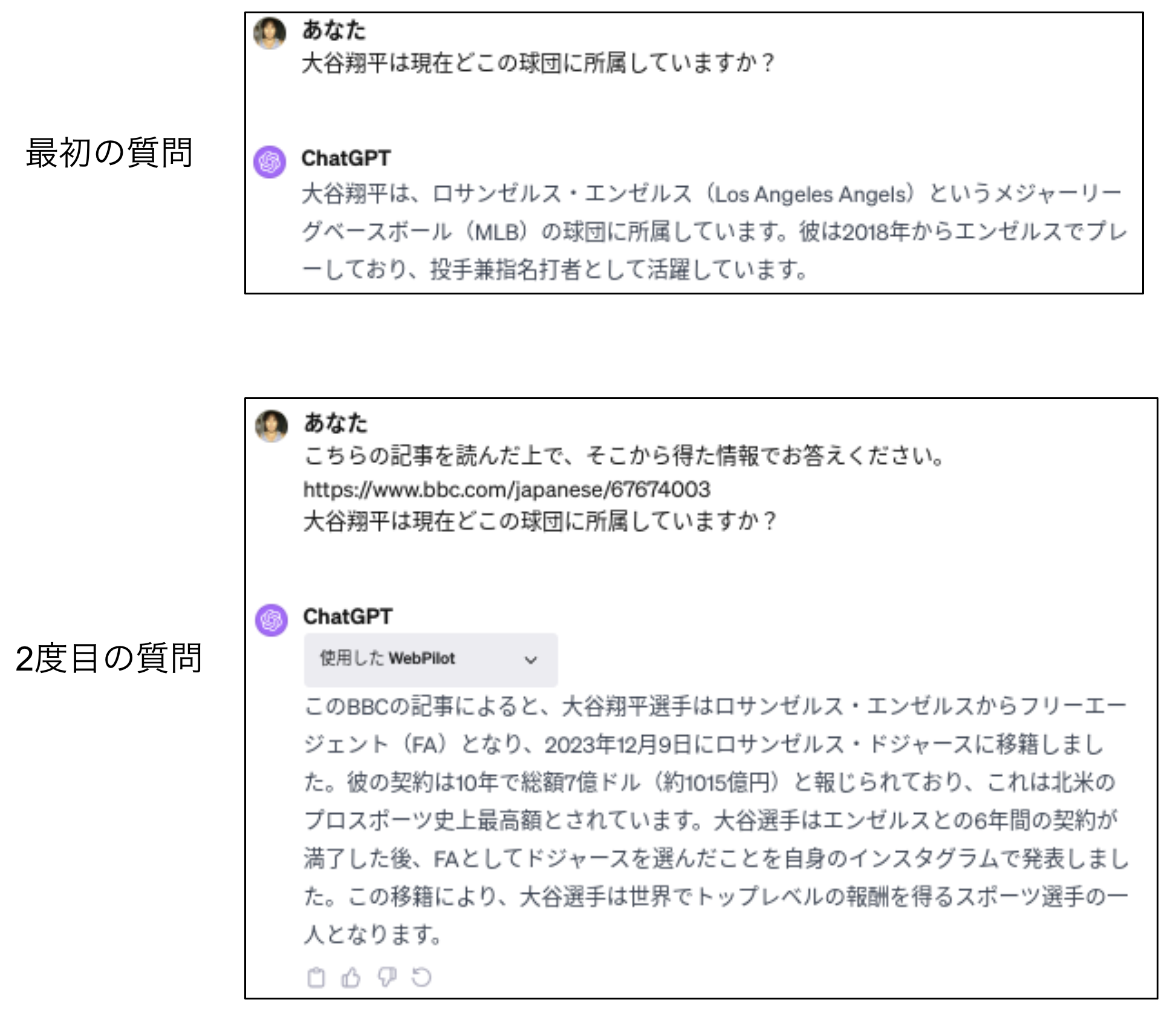
図5:ChatGPT Plusを使ったIn-Context Larning
コンテキスト学習の限界
この結果を見ると、コンテキスト学習で何でもできそうに思いますね。しかし、実際にプラグインを使って製品マニュアルのPDFをGPT-4に読ませて、Q&Aシステムを作ってみても期待したほどの結果を得られません。
学習データ(プロンプト)の量が多いと「覚えきれないぞ」って感じでイマイチですし、テキストが短くてもすぐに忘れてしまいます。パッと読んだだけでモデルのパラメータを更新していないので、新しく取得したスキルはLLMが応答した後ですぐに消えてしまうのです。
人間にも「脳に刻む」という言葉があります。脳に刻んだことはなかなか忘れないのですが、その場限りで流したようなことは後日「え、そうだっけ?」と覚えていないことが多いです。
ニューラルネットワークのパラメータ調整
知識を脳に刻む(パラメータを更新する)とはどういうことなのか復習しましょう。図6は第3回で説明したニューラルネットワークの構造を再掲したものです。今回は動物を当てる学習に変えています。入力層から画像がinputされ、「猫」「犬」「猿」「羊」「馬」など様々な予想を指示する信号が左のノードから右のノードに順番に伝播され、最後に多数決で「犬」や「猫」などが選ばれ仕組みです。
「犬」のラベルが付いた画像をinputしたのに「猫」と解答したとしましょう。間違いだったので「猫」という誤りにつながる信号を伝搬してきた各層の線の太さ(重み)を小さくします。「お前らがガセ情報を伝えたから間違ったじゃないか。お前らの信用を少し下げるぞ」という感じです。この重みがパラメータで、信号の伝わりやすさです。このように間違っては重みを調節する(誤差逆伝播と言います)というフィードバックを延々と繰り返すことで、ニューラルネットワークは頭が良くなるのです。
私の世代は英単語を覚えるために単語カードをよく使いました。表(おもて)に書かれている日本語にな対応する英単語を考えてから、ひっくり返して裏に書かれている英単語を見て答え合わせをします。そこで「あっ、間違った」と思ったときに脳に刻まれる学習が誤差逆伝播なのです。
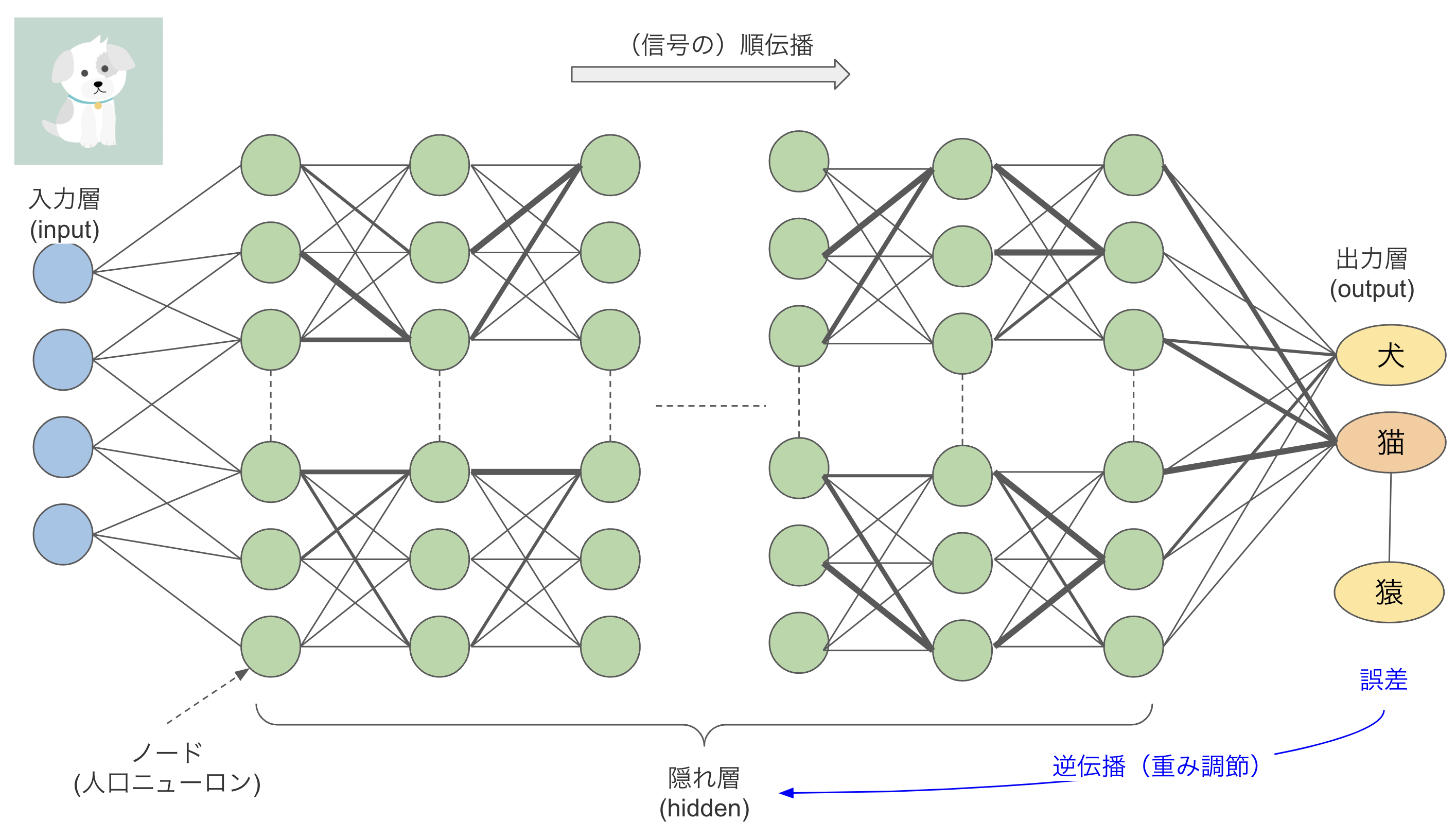
図6:ニューラルネットワークのパラメータ(重み)調整
転移学習
転移学習(Transfer Learning)は、AIを勉強したことがある人なら誰でも知っている学習方法です。ひと言で言えば「あっちで学んだ学習済みモデルを利用して、こっちの学習を少ないデータで済ます方法」です。ファインチューニングを理解する上で知っておきたい技術なので、ここで説明しておきましょう。
解答の選択肢を決めて学習
ラベルあり学習は、出力数を決めて学習します。例えば「犬」「猫」「羊」など20種類の動物を出力とした場合は、それ以外の動物は解答できません。「うさぎ」を学習していない場合は、「うさぎ」の画像をinputするとできるだけそれに近い動物(例えば「猫」)を出力します。このような場合は、当然、確信度は低くなります。
動物ではなく、30種類の鳥の名前を教えてくれるAIを作るとしましょう。普通にイチから作るのであれば、数千〜数万枚の鳥の画像の中から品質の良いものだけにラベル(鳥の名前)を付けて(この作業をアノテーションと言います)、AIに数十回読ませて訓練する必要があります。
必要となる学習データが多いので、それだけの枚数の鳥の画像を集めたり、良い画像だけを選んだり、画像1つ1つに名前を付けたりという作業がとても大変です。しかし、すでに「動物の名前を当てることができるAI」が完成していれば、これを利用して少ない画像で効率的に学習するウルトラ技が使えるのです。
転移学習の仕組み
この魔法の方法が転移学習(transfer learning)です。転移学習にはいろいろな方法がありますが、今回は最後の2〜3層を再学習する方式で説明します。図7は動物を見分けるモデルを利用(transfer)して、鳥の名前を教えてくれるAIを作成する転移学習です。まず、動物モデルの最後の2〜3層だけ残してフリーズ(パラメータ凍結)します。そして、鳥の画像を新たに訓練し、そこで学んだ内容がフリーズしなかった層の新たな重みとなるのです。
転移学習の優れた点は、学習データが少なくても済むところです。すでに動物の名前を見分けるようにパラメータが最適に調節できているので、対象を鳥に変えてもパラメータは有効です。そのため、新しい知識をちょこっとフリーズ解除した層だけに刻むことで、すぐに鳥を見分けられるようになるのです。
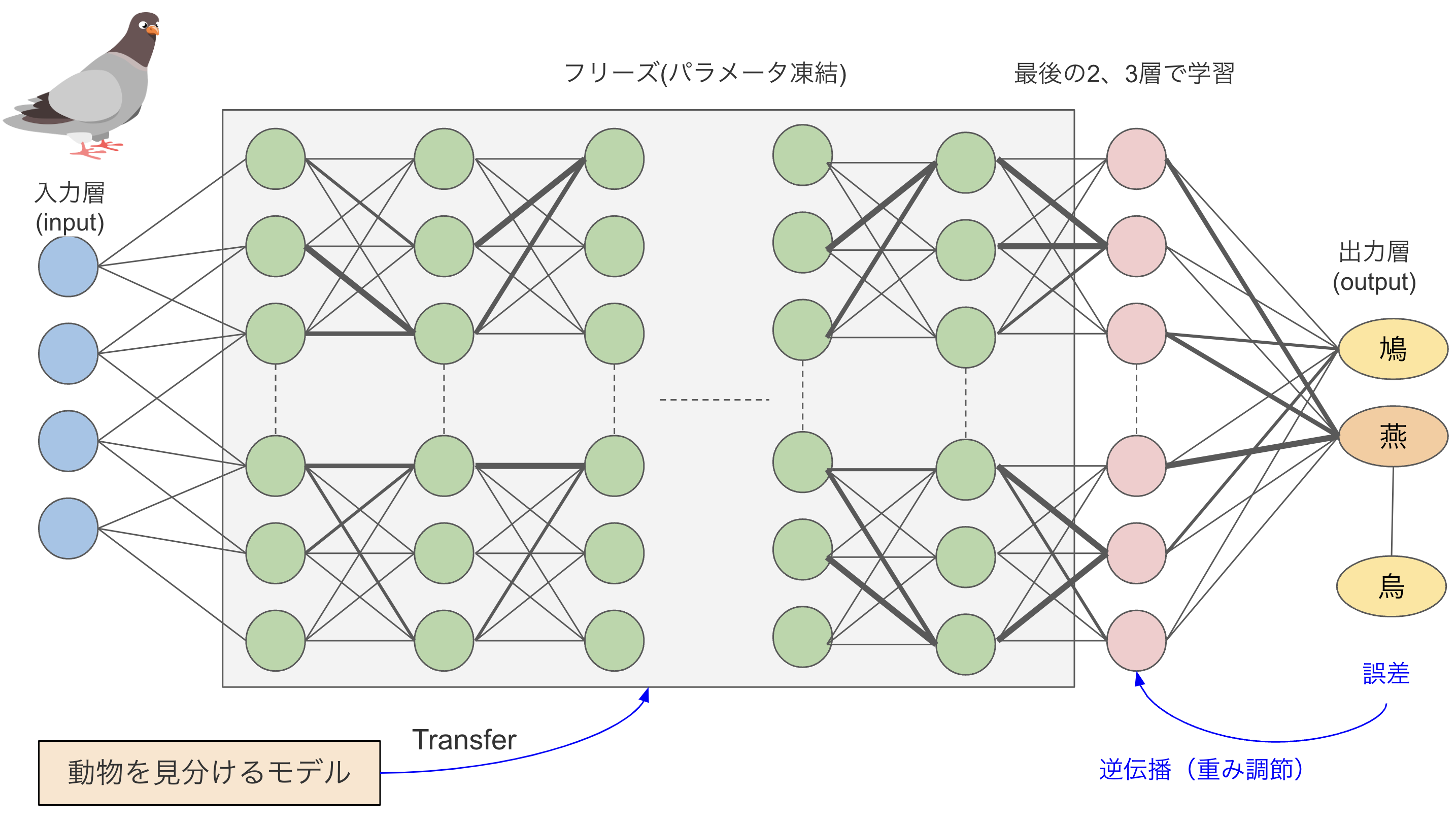
図7:転移学習
少数ショット学習(Few-Shot Learning)は、少数のトレーニングサンプル(学習データ)を用いてモデルを学習させるアプローチの総称です。手法としては、メタラーニング(複数のタスクから学習したモデルを新しいタスクに適応する方法)、データ拡張(既存のトレーニングサンプルを変形・拡張して多くのデータを生成する方法)などがあります。そして、転移学習もその1つの有力な手段とされています。
また、モデルが新しいトレーニングサンプルを全く学習することなく、見たことのないものを認識するゼロショット学習という言葉もあります。
ファインチューニング
ここまでの説明でピンと来るように、ファインチューニング(Fine Tuning)は転移学習の一種です。汎用データで学んだ生成AIの一部の層を凍結解除し、そこのパラメータを新しいデータに適応させることにより独自データが脳に刻まれます。
ファインチューニングの仕組み
GPT-3.5 turboをモデルにしたファインチューニングの概念を図8に示します。転移学習は図7のように最後の層(もしくは最後の2〜3層)のみフリーズ解除して再学習するケースが多いです。一方、ファインチューニングは、もっと広い層を再学習対象とします。ただし、せっかく最適に調整されているオリジナルモデルを大きく変えてしまうと性能を落としてしまうことになりかねません。そのため層ごとに調整係数をかけてパラメータ更新に制限をかけます。
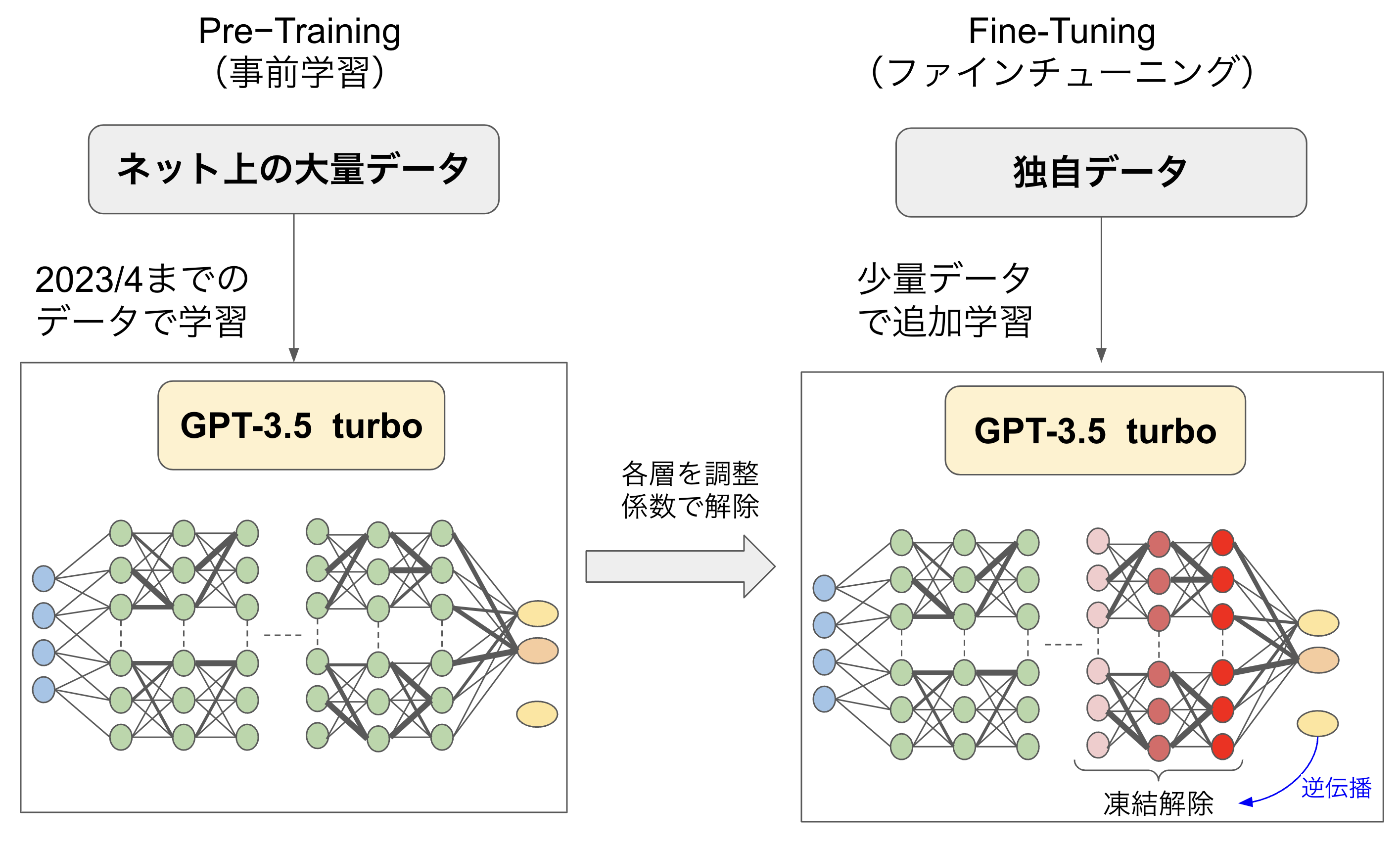
図8:ファインチューニングの概念
例えば、最終層は出力の変更(20種類の動物から30種類の鳥)に対応させるために調整係数を1.0とします。一方、だいぶ手前の層は調整係数を0.05として5%しか変更されないように制限するような感じです。
GPT-3.5 turboのファインチューニングでは、モデル全体の学習率をハイパーパラメータとして指定できます。しかし、その結果で各層の学習率がどのように設定されるかまではわかりません(普通に使う分には知る必要もないですが)。とにかく新しく追加で学習された内容が、凍結解除された層のパラメータに刻み込まれるので、独自データの内容を忘れにくくなるわけです。
ファインチューニングのメリット
コンテキスト学習と比較して、ファインチューニングには次のようなメリットが挙げられます。なんと言っても最大のメリットは(1)で、これが企業データの利用に必要となるため、追加学習の手間をかけてでもファインチューニングを行うわけです。
(1)長い学習データを覚えられる
コンテキスト学習は覚えてもらうデータをプロンプトとして与えますが、入力できるトークン数には制限があります。制限を回避するために少しずつ文章を読ませたり、PDF化してプラグイン経由で読ませたりしても、脳に刻んでいないため長い文章だと覚えきれません。一方、ファインチューニングは、膨大な文章をトレーニングサンプル(1つのメッセージ)の集合として制限なく用意できるので、学習データセットの大きさを気にする必要がありません。
(2)システムの応答速度が速い
コンテキスト学習では、学習データを都度プロンプトとして入力するので、長いプロンプトを解釈して回答するのに時間がかかります。ファインチューニングは、データセットの学習は済んでいて役割や出力フォーマットなど短いプロンプトを付与するだけなので、応答速度が速いです。
(3)プロンプトの作成が効率化
コンテキスト学習とファインチューニングは、どちらもプロンプトエンジニアリングがベースなので、期待通りの回答を得るためにはプロンプトがとても重要です。コンテキスト学習ではプロンプトを都度入力しますが、ファインチューニングは最初に最適なプロンプトを見つけて設定しておけば、あとは自動的にそのプロンプトが使われるようになります。なお、コンテキスト学習も前回解説したCustom InstructionsやMy GPTsにより定型的なプロンプトを入力に付加できるようになっています。
ファインチューニングにより改善できる使用例
OpenAIのホームページでは、上記のメリットの他に次のような利用ケースを挙げています。
- スタイル、トーン、形式などを指示する
- 目的の出力を生成する際の信頼性や精度の向上
- 複雑なプロンプトに対応する
- 例外的なケースにも対応する
- オリジナルモデルでは難しいタスクを実行する
ファインチューニング提供モデル
第7回でも追加学習の方法としてコンテキスト学習とファインチューニングを紹介しました。このときOpenAIはChatGPT(GPT-3.5)のファインチューニングを提供していませんでしたが、2023年8月22日の発表でGPT-3.5 turboのファインチューニングが利用可能になりました。
企業の利用を想定しているので、トレーニングに使ったデータをユーザー以外が学習に利用することはありません。また、ユーザーの学習データが安全かどうかをチェックしているため、OpenAIの安全基準に違反するような良からぬ学習データがあれば排除されます。
このとき、GPT-4のファインチューニングも秋に提供される予定と発表されましたが、残念ながら現時点でまだリリースされていません。すでに特定ユーザーにはgpt-4-0613のファインチューニングが提供されているようなので、遠からずGPT-4 turboのファインチューニングも一般公開されると思われます。
ただし、ファインチューニングはパラメータを更新するのでモデルサイズが大きいほど計算コストがかかります。GPT-4 turboはGPT-3.5 turboに比べて大幅にパラメータ数が増えていますので、料金も高く設定される可能性があります。
おわりに
今回は、以下のような内容について学習しました。
- 独自データを学習する方法として、生成AIに追加学習させる方法が脚光を浴びている
- 企業ドキュメントデータは、生成AIと相性が良いのでホワイトカラーの生産性向上が期待できる
- 企業データを追加学習させる方法には、コンテキスト学習とファインチューニングとRAG&エンべディングがある
- コンテキスト学習は、テキスト文章を読ませてから回答させるプロンプトエンジニアリング手法
- コンテキスト学習は脳に刻んでいないので、すぐ忘れてしまうのが弱点
- ファインチューニングは転移学習の一種で少数ショットの追加学習で目的を達成するモデルが作れる
- 転移学習は最終層を再学習するが、ファインチューニングはより広い層を学習率で制限かけながら追加学習する
- 現在OpenAIが提供しているファインチューニングはGPT-3.5 turboモデル。GPT-4 turboモデルも近日公開される予定
次回は、ファインチューニングのやり方について解説します。GPT-4 turboのファインチューニングがリリースされると、かなり便利なものが作れそうなので、自社データの活用を考えている方は今のうちからトレーニングサンプルの準備しておきましょう。
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
