Oracle Cloud Hangout Cafe Season 4 #5「Kubernetesのオートスケーリング」(2021年8月4日開催)

PodやContainerのCPUやメモリ利用率以外でのスケール
ここまでの例では、PodのCPUやメモリの利用状況でのスケールでしたが、他にも4つのメトリクスを利用できます*2。
| 種別 | メトリクス | 収集元 | スケールロジック |
|---|---|---|---|
| Resource | CPU利用率 メモリ利用率 |
metrics-serverがkubeletから取得した値 | PodのCPU/メモリ利用率で評価 |
| ContainerResource | CPU利用率 メモリ利用率 |
metrics-serverがkubeletから取得した値 | ContainerのCPU/メモリ利用率で評価 |
| Pods | Podの任意のメトリクス | API Aggregation Layerから取得した任意のエンドポイント | 値での評価(≠率) |
| Object | 任意のメトリクス(Pod/Container以外のKubernetesオブジェクト) | API Aggregation Layerから取得した任意のエンドポイント | 単一の値と目標値の比較 |
| External | 任意のメトリクス(Kubernetesオブジェクト以外) | API Aggregation Layerから取得した任意のエンドポイント | 単一の値と目標値の比較 |
ここで登場したAPI Aggregation Layerについて補足します。API Aggregation Layerとは、広く利用されているOperatorを利用したCRD(カスタムリソース)での拡張とは異なる手法でkube-apiserverに新しい種類のオブジェクトを認識させる仕組みです。kube-apiserverのフラグでAggregation Layerを有効に設定する必要があり、拡張APIサーバとなるPodを実行し、APIServiceオブジェクトを登録することで利用できます。
CRD(カスタムリソース)よりも詳細なAPIを定義でき、apiserver-builder(OperatorでのKubebuilder相当)を利用して実装できます。
PodもしくはContainerのCPU/メモリ利用率以外をスケール時のメトリクスとして利用する場合はmetrics serverを利用しないため、下図のような処理フローになります。
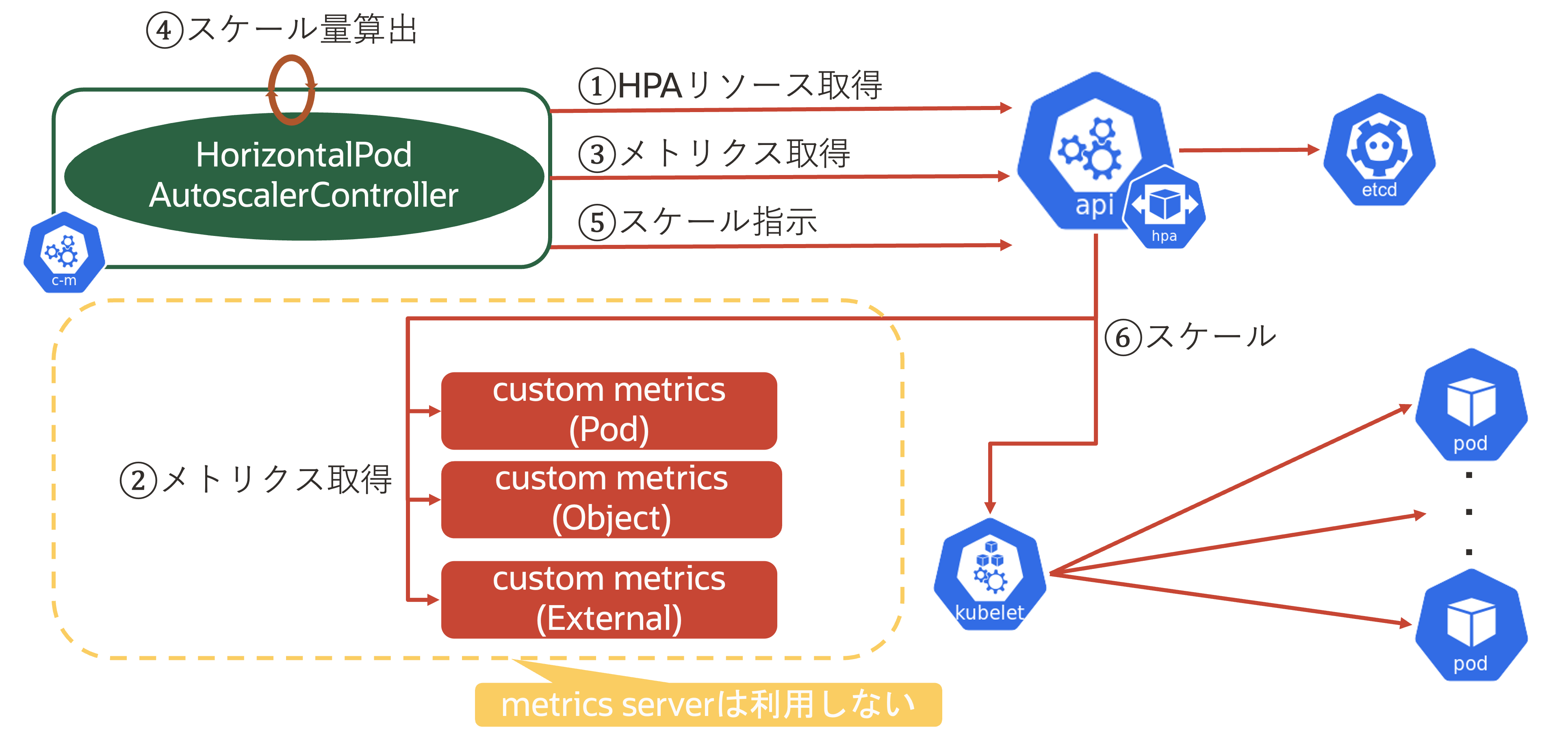
PodのCPUやメモリ利用率以外でのスケール
PodやContainerのCPUやメモリ利用率以外でのスケールでのHPAリソース定義例を示します。
*2: セッション当時はHPAリソースをapiVersion: autoscaling/v2beta2として解説しましたが、この記事では最新のapiVersion: autoscaling/v2を用います。そのため、セッション資料とは異なるフィールドや値が存在します・type:Podsの場合
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Pods
pods:
metric:
name: packets-per-second
target:
type: AverageValue
averageValue: 1k
.spec.metrics.metrics[].typeにPodsを指定すると、任意のPodメトリクスをスケール条件に利用できます。例えば、上記のケースではpackets-per-secondというメトリクスの平均値が1000になるようにレプリカ数が調整されます。任意のPodのメトリクスを利用する場合は平均値(≠率)での判定になります。
・type:Objectの場合
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1
kind: Ingress
name: main-route
target:
type: Value
value: 2k
.spec.metrics.metrics[].typeにObjectを指定すると、同一Namespace内のPod以外の任意のメトリクスをスケール条件に利用できます。例えば、上記のケースではmain-routeという名前のIngressリソースにおけるrequests-per-secondというメトリクスの値が2000になるようにレプリカ数が調整されます。Pod以外の任意のメトリクスを利用する場合は値か平均値(≠率)での判定になります。
・type:Externalの場合
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: External
external:
metric:
name: kafka_consumergroup_sum
target:
type: AverageValue
averageValue: 30
.spec.metrics.metrics[].typeにExternalを指定すると、Kubernetesクラスタ外の任意のメトリクスをスケール条件に利用できます。例えば、上記のケースではkafka_consumergroup_sumというメトリクスの平均値が30になるようにレプリカ数を調整します。Kubernetesクラスタ外の任意のメトリクスを利用する場合は実値か平均値(≠率)での判定になります。
・複数のスケール条件
ここまでは、単一のスケール条件で説明をしてきましたが、HPAでは複数のスケール条件を定義できます。
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
- type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1
kind: Ingress
name: main-route
target:
type: Value
value: 2k
- type: Pods
pods:
metric:
name: packets-per-second
target:
type: AverageValue
averageValue: 1k
例えば、上記のケースでは、以下すべての条件下でのレプリカ数を算出し、最もレプリカ数が大きい結果が適用されます。
各PodのCPU使用率50%になるレプリカ数main-routeという名前のIngressリソースにおけるrequests-per-secondというメトリクスの値が2000になるレプリカ数packets-per-secondというPodメトリクスの平均値が1000になるレプリカ数
HPAのデモ
当日のセッションでは、HPAのデモを実施しています。詳細はセッション動画をご確認ください。


連載バックナンバー



Think ITメルマガ会員登録受付中
他にもこの記事が読まれています






全文検索エンジンによるおすすめ記事
- Kubernetesにおけるオートスケーリングの概要
- Podのリソース割り当ての推奨値を提案するKRR(Kubernetes Resource Recommender)
- ドメインを考慮した柔軟なPodの配置を実現する「Balancer」
- Kubernetesアプリケーションのモニタリングことはじめ
- OpenShift:アプリケーションの構成と運用
- kustomizeで復数環境のマニフェストファイルを簡単整理
- Kubernetesの基礎
- 「K8sGPT」の未来と生成AIを用いたKubernetes運用の最前線
- 「kwok」でKubernetesクラスターをシュミレーションする
- kustomizeやSecretを利用してJavaアプリケーションをデプロイする