DATADOG
DATADOG

DATADOG社は、2010年に設立されたアメリカ ニューヨークに本拠を置く企業である。前述のNew Relic社と同様にソースコードレベルの診断・解析や、システムの死活、性能監視やアクセス解析などをSaaS型で提供を行っている。実際に使用してみると、まずグラフ表示がきれいで見やすいと感じられた。公式サイトで公開されているダッシュボードの画面を以下に紹介する。
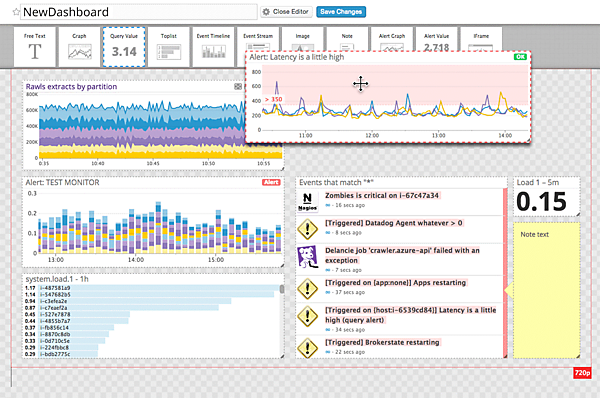
DATADOG社が公開する監視画面
DATADOG社が提供する機能として公式サイト上で紹介されているものを、以下の表にまとめた。
DATADOG社が提供するサービス
| No | サービス名 | 概要 |
|---|---|---|
| 1 | ホスト管理 | 監視対象ホストのリソース割り当てや稼働状況の一覧と詳細表示に加えて、稼働しているホストグループごとの稼働状況をグラフィカルに表示するHost Mapなどの機能が存在する |
| 2 | リソース監視 | 監視対象ホスト、プロダクトのリソース使用量やアクセス件数などを集計し、グラフ表示を行う機能。基本的にはGUIでの操作だが、JSON editorを使用し、画面上で集計方法や表示をカスタマイズすることも可能 |
| 3 | イベント監視 | 監視対象のプロダクト、リソース、ログなどから取得したイベントのログと発生件数をグラフィカルに表示する機能。さらに発生したインシデントに対するコメントの追記や、イベントを通知する機能も提供されている |
| 4 | 監視アラート | 前述のリソース監視結果やイベント監視結果に対応し、発生状況に応じアラートを送信する機能 |
日本語化された詳細なドキュメントが、DATADOG DOCSで公開されている。初期導入から各プロダクトの監視設定の方法や、監視設定のカスタマイズの手順まで詳細に記載されており、製品の理解を助け、導入へのハードルを大きく下げている。
各プロダクトや基盤の監視を行うIntegrationはPythonで記述されており、ソースも公開されている。基本的には設定ファイルの一部を実行環境に合わせて変更するだけで使用できるが、取得するデータのカスタマイズも可能である。
監視結果を表示するダッシュボードは、GUIによって取得するデータと表示するグラフをカスタマイズできる。
他の製品同様、DATADOGも通常のLinuxなどのOSを監視する際にエージェントをインストールするが、Docker環境では以下の特徴がある。
- Docker環境へのDATADOGエージェントのインストールは、DATADOGコンテナを起動する形で行う
- コンテナのリソース監視のみであれば、DATADOGエージェントのインストールは不要
- コンテナの生成を自動的に検出し、リソース監視を開始できる
コンテナのデータ取得には、cgroupsを使用しており、エージェントレスでかつコンテナごとの正確なデータ取得を実現している。公式サイトで公開されているDockerの監視状況の画面を以下に示す。
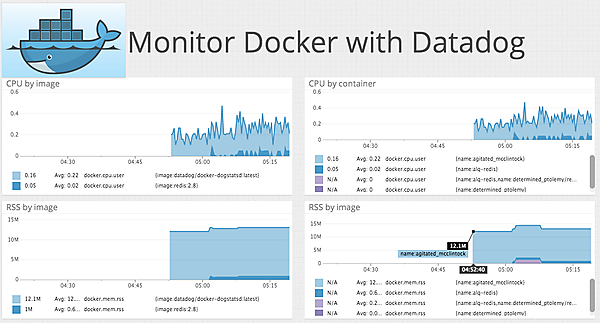
DATADOG社が公開するDockerの監視画面
価格構成は、以下の表のようにシンプルである。Freeプランが存在するのは、大変ありがたい。
DATADOG社が提供するサービスの料金体系
| プラン | Free | Pro | Enterprise |
|---|---|---|---|
| 料金 | 無料 | $15/ホスト、月 | Volume discounts |
| 制約事項 | 5ホストまで | 500ホスト以下 | 500ホスト超 |
signal fx

SignalFx社は、2008年に設立されたアメリカ カリフォルニア州サン・マテオに本拠を置く企業である。リソース使用状況やアプリケーションの処理件数や処理時間を集計し、分析を行うSaaSサービスを提供している。サーバOSやアプリケーションから取得されたデータをメトリック化し、signal fxに送信すると為替や株価のように統計情報として集計、分析を行う機能を提供している。さらに集計、分析を行ったメトリックが指定した条件にマッチした場合、アラートを送信する機能も提供している。
メトリックをsignal fxに送信する方法だが、Linuxのcollectdを使用している。通常はcollectd単体でもグラフ作成は可能だが、内部でグラフ化するのではなく、メトリックをSignalFx社のサービスに送信する設定を行い、集計と分析・グラフ化をSaaSサービスにて実施する形となる。
集計されたデータの分析・グラフ化は、SignalFx社サイト上のダッシュボードのGUIで行う。ダッシュボードには、グラフ以外にもマークダウン記法が使用できるドキュメント表示の機能も存在する。
公式サイト上で公開されているダッシュボードの画面イメージを以下に示す。
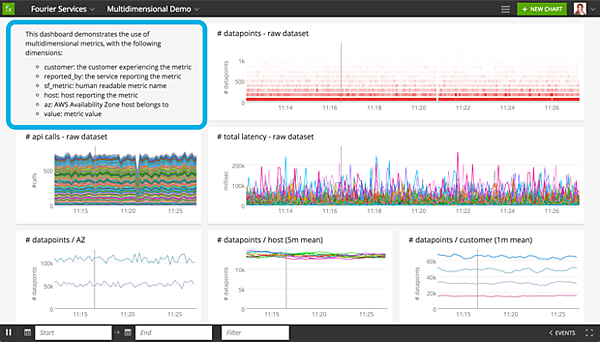
SignalFx社が公開するダッシュボード画面
Dockerの監視方法については、SignalFx社の公式ブログに記載されていた。やはりcgroupsからDockerコンテナのCPU、メモリ、ディスクI/Oの使用量などの数値を取得し、送信を行う方法が解説されている。他の監視も同様だが、signal fxではシステム利用者側で集計したいメトリックをシステムより抽出し、送信する作業を行う必要がある。
コンテナの自動検出とメトリック抽出に対応したサンプルが、やはり公式ブログで公開されている。取得結果を元に監視を行ったサンプル画面は、以下の通りだ。
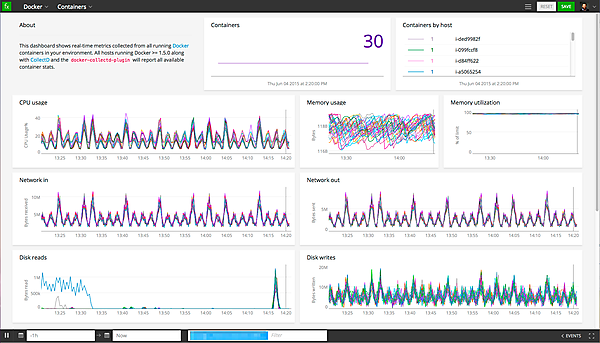
SignalFx社が公開するコンテナ監視のサンプル画面
価格は、測定するデータの送信量によって変動する。
SignalFx社が提供するサービスの料金体系
| プラン名 | 1分あたりの上限送信件数 | 月額料金 |
|---|---|---|
| Bootstrap | 5,000 | $75 |
| Startup | 10,000 | $150 |
| Business | 25,000 | $375 |
| Growth | 50,000 | $750 |
| Enterprise | 100,000 | $1,400 |
| CustomMore | 100,000超 | 問い合わせ |
料金は1分あたりの送信メトリック数により変化するが、誤ってsnmpなどの情報を全て送ってしまうと、1回で1万件くらいメトリックが送信されてしまう。利用に際しては、課金額を抑えるために、利用者側で必要最低限のメトリックを送信するように十分な検討と設計が必要である。
Librato

Libratoを提供するSolarWinds Worldwide, LLC社は、1998年に設立され、インフラ基盤やサーバ、アプリケーションなどに様々な運用・監視製品を提供する老舗ベンダーである。Libratoを2015/02/02に買収し、SaaS型運用サービスも提供を開始した。
前述のsignal fxと同様に、サーバ側で収集したリソース使用量やアクセス件数などのデータをメトリック化し、Libratoのサービスに送信することで集計とグラフ化や、閾値に対応したアラート発行を行う機能を提供している。公式サイトにて公開されている画面イメージは以下のようなものだ。
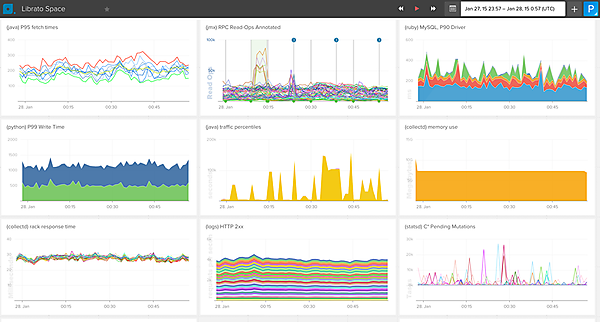
Libratoの監視画面イメージ
メトリックの送信方法として、以下の3種類のインターフェースが提供されており、そのインターフェースごとに課金が異なる。
Libratoの料金体系
| No | 送信方法 | 特徴 | 料金 |
|---|---|---|---|
| 1 | collectdを使用 | Linuxのcollectdのメトリック送信先をLibratoのサービスに変更し、集計を行う | 20メトリクス/60秒以下なら$2/サーバ、月 29メトリクス/10秒以下なら$7.25/サーバ、月 |
| 2 | AWS CloudWatch連携 | AWS CloudWatchのAPIと連携し、CloudWatchで取得されたメトリックを送信して集計を行う | EBS:$0.50/月 EC2:$1.00/月 ELB:$1.30/月 RDS:$1.40/月 |
| 3 | StatsDを使用 | 指定されたパラメータの回数や平均値を保持して、結果を送信するアプリケーション。GitHubからダウンロードし、ビルドして使用する。UDPでの送信が可能で、短時間で多くのメトリックが送信できる | 50ケージ/カウンタメトリックスなら$5.00/月 10タイマー・メトリックなら$2.00 |
Dockerの監視方法については、公式ブログにトレジャーデータ社の田村清人氏が寄稿された記事が掲載されている。コンテナのCPU、メモリなどの利用状況は、やはりcgroupsから取得しているが、Libratoへの送信にはcollectdではなくFluentdを利用している。公式ブログ上で公開されている監視画面イメージは、以下の通りだ。
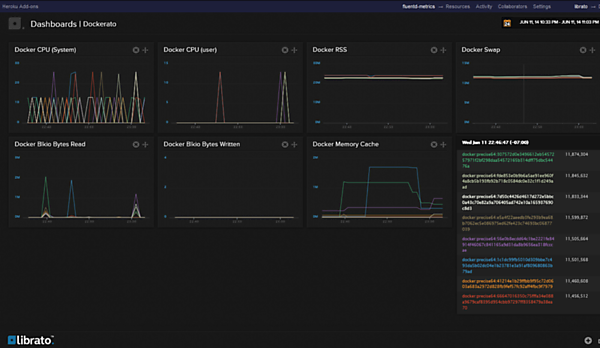
Libratoのコンテナ監視画面イメージ
Libratoのサービスを効率よく利用するためには、signal fxと同様にメトリックの集計に利用者側での十分な設計と開発が必要となる。SignalFx、Libratoは、共にエージェントに対してcollectdやFluentdなどから取得したメトリックをSaaS側に転送するインターフェースを持っている。一部カスタマイズは必要だが、他のサービスに提供されているサンプルを流用することも有効な手段だと考えられる。
Scout

Scoutは2007年に内部ツールとして開発され、2008年にOSSとして公開されている。前述のsignal fxやLibratoと同様に、サーバ側で収集したリソース使用量やアクセス件数などのデータをメトリック化し、Scoutのサービスに送信することで集計とグラフ化や、閾値に対応したアラート発行を行う機能を提供している。
リソース監視とグラフ化、アラートに機能を集約しており、インストールと設定の容易さを最大のメリットとして挙げている。またインストールのための、ChefやPuppetのレシピも公開されている。各種プロダクトを監視するプラグインも提供されており、そのプラグインの導入もGUI上の操作で行える。プラグインは全てRubyで作成されており、カスタマイズも行いやすくなっている。公式サイトで公開されている監視画面イメージを、以下に示した。
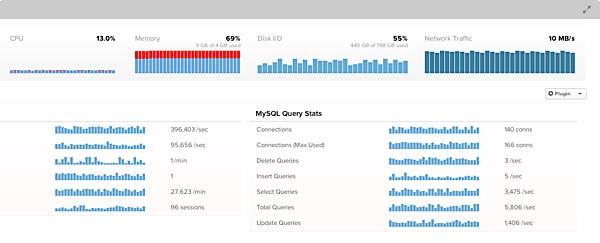
Scoutの監視画面
Docker環境の監視は、DATADOGと同様にエージェント実行用のコンテナをインストールする形となり、ベースOSへのエージェントのインストールは不要である。標準の機能でコンテナのリソース使用量およびDocker環境へのコンテナの作成、削除などのイベントの監視も行える。コンテナのリソース使用状況およびDocker上でのイベントの監視画面は、以下のようなものだ。
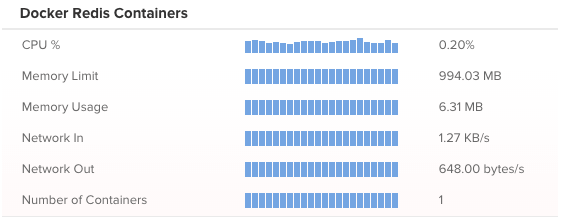
Scoutの監視画面(リソースの使用状況)
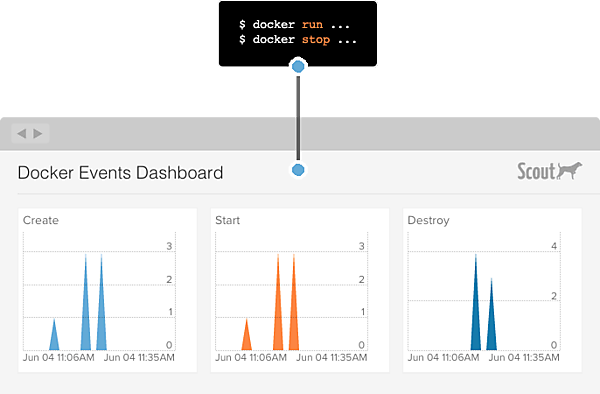
Scoutの監視画面(イベント監視)
課金は、シンプルな2つのプランが提供されている。14日間の無料評価期間も提供されている。
Scoutの料金体系
| プラン | SERVER MORITORING | STATSD |
|---|---|---|
| 料金 | $15/ホスト、月 | 1$/10メトリックス、月 |
| 制限 | 監視データ粒度1秒、データ保持1年間 | StatsDで取得したメトリックの集計と監視 |
導入も設定も比較的容易で、課金プランもわかりやすい。手間をかけずに、シンプルな監視基盤を構築したい場合に良い選択肢になると考えられる。1点問題があるとすれば、製品名の「scout」で技術情報を検索しても、情報がなかなか見つけられない点である。
Mackerel

最後に国産製品からMackerelをご紹介したい。Mackerelは、株式会社はてなが提供しているSaaS型サーバ監視サービスだ。前述のsignal fx、Librato、Scoutと同様に、サーバ側で収集したリソース使用量やアクセス件数などのデータをメトリック化し、Mackerelのサービスに送信することで集計とグラフ化や、閾値に対応したアラートを発行する機能を提供している。
Mackerelは2007年ごろから、はてな社内部の監視ツールとして開発されており、それをベースに2014年9月にSaaS型で提供が開始された。日本国内での導入事例も多く、特にコマースサイトやゲームなどの大規模なコンシューマ向けサービスを展開している企業に採用されている。
国産製品ということもあり、日本語のドキュメントやユーザ事例などが充実している。公式で公開されているプラグインは20点程度だが、利用者が開発して公開しているものも含めると、かなりのプロダクトをカバーできている。Docker向けのプラグインは、公式のGitHub(mackerelio/mkr)で公開されている。ただ、Docker専用OSへの対応に関する情報は、執筆時点では発見できなかった。
監視データを参照するダッシュボードのサンプル画面が公式サイトで公開されている。2015年7月には、ダッシュボードのカスタマイズも実装されている。
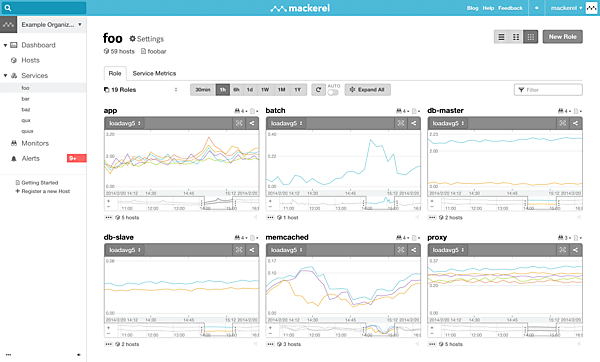
Mackerelのダッシュボードサンプル
リソース使用状況等の通常監視データ以外のメトリクスを、サービスメトリックと呼んでおり、そのサービスメトリックもhttp+json apiで独自に登録し、fluentdで取得したメトリックをMackerelエージェントのAPIで送信できる。サービスメトリックのグラフは、Mackerel以外のサイトに埋め込んで表示させることも可能である。さらに外部からのURLアクセスの正常反応を確認する、外形監視機能が提供されていることも特徴と言える。
課金は有料プランと無料プランが存在するが、現在は期間2週間のTrialプランも提供されている。詳細は、以下の表にまとめた。
Mackerelの料金体系
| プラン | Trial | Free | Standard |
|---|---|---|---|
| 料金 | 無料 | 無料 | \2,000/ホスト、月 |
| 制限 | ホスト255台以下 200メトリック/ホスト以下 サービスメトリック100件/契約以下 監視ルール数100件/契約以下 外形監視20件/契約以下 データ保持1年 ※Trial期間は2週間 |
ホスト5台以下 200メトリック/ホスト以下 サービスメトリック10件/契約以下 監視ルール数10件/契約以下 外形監視なし データ保持1日 |
ホスト1台以上 20台以上は問合せ 200メトリック/ホスト以下 サービスメトリック100件/契約以下 監視ルール数100件/契約以下 外形監視20件/契約以下 データ保持1年 |
国内ベンダー提供のSaaS型監視サービスで、Dockerに対応しているものは非常に少ない。前述の海外(ほとんどアメリカだが)のサービスと比較しても、機能面では遜色はないと考えられる。今後の機能強化や改善による、さらなる利便性の向上が楽しみなサービスである。
利用するサービスの選定にあたって考慮すべき点
以前より、監視サービスをアウトソーシングするためのSaaS化は行われていたが、技術の進歩は著しく、今や利用状況の可視化、問題分析までが実装されているほどだ。またSaaS型ということもあり、個人でクラウドサービスを利用するほどの容易さで使い始められるのは、便利な時代になったと感じる。今回紹介できなかったサービスも多々存在し、サービスの選定の際に、何らかの基準が必要になる。その基準となりそうな考え方をまとめてみた。
サービス面での必要性
最初に紹介したNew RelicやAppDynamicsは、監視機能に加えて、ユーザアクセス解析やエラー発生個所特定やパフォーマンス問題分析など、システムを運用するための課題・問題解決に直接役立つ運用状況の解析を行うサービスを提供している。
高機能であるため、利用料金は他の監視中心のサービスと比較すると高額になるだけではなく、監視運用負荷の上昇や取得した解析データをどう使うのかの判断も必要となる。それらのサービスが業務上必須であれば、迷うことなく選択すべきだが、運用や導入の負荷を少なく監視だけを始める場合、他の条件でサービスを選択すべきと考えられる。
実行時の環境で解析を行いたいのであれば、強力な解析ツールであるsysdigを利用できるSysdig cloudを選択すべきであるが、本番環境への負荷を考慮すると開発・テスト環境で行うべきかもしれない。
カスタマイズに使用する言語
各サービスを使いこなす上で、監視に使用するプラグインやテンプレートを運用者がカスタマイズする必要が発生する。カスタマイズの容易性をGUIで実現している製品も多数存在する。また、使用する言語の標準を統一している製品も存在する。たとえばDATADOGはPython、ScoutはRubyとなる。運用者のスキルに合わせて、使いやすい言語で開発が行える製品を選定するのも良い手だと考えられる。
監視間隔と通信の距離遅延
SaaS型監視サービスで注意すべきなのは、監視対象の拠点と監視ベンダーのSaaS拠点がネットワーク越しの遠隔地に存在する点だ。そのため、監視データの間隔を60秒としているサービスも存在するが、監視としてはやや長く感じられる。実際には、多くのサービスが1秒間隔を実現している。
監視間隔が短いということは、送信するメトリックの情報量が多くなるということで、通信負荷の増加が懸念される。さらに監視ベンダーのSaaS拠点が遠隔地に存在する場合、距離遅延による通信速度の低下も懸念される。
大規模監視を短い間隔で行う場合、監視対象の拠点と監視ベンダーのSaaS拠点が近い方が問題の発生を抑えることは明らかである。パブリッククラウドであれば、監視対象拠点を監視ベンダーのSaaS拠点に近づけることも一考の余地がある。また国内拠点で動かせないとなれば、国内でサービスを提供しているベンダーを選択することも一手だろう。
その他の手としてはメトリックをUDPで送信する機能を持つEtsy/StatsDのインターフェースを採用した製品を選択する手もある。TCPと異なり、送達確認がないため、大量のデータを高速に送信することが可能である。パフォーマンスデータのように、リアルタイム性が求められるメトリックに関しては有効な選択肢となるだろう。
Docker基盤の監視
これからのDocker基盤は、Red Hat Atomic HostやCoreOS、RancherOSなどのDocker専用OSで構築されることが多くなると考えられる。これまではLinux OSに対してインストーラを使用してパッケージインストールを行っていたが、Docker専用OSの場合、これはあまり好まれる方式ではない。やはり監視エージェントもコンテナとして提供される形が望ましいだろう。その点では現状、DATADOGとScoutが少し先行していると考えられるが、他ベンダーも追随することが予想される。
まとめ
ほぼ各社の製品に共通しているのは、監視対象システム側にインストールしたエージェントが収集したメトリックをSaaS側で受け取り、グラフ化、監視、アラート発行を行うことである。エージェントにメトリックを受け渡すインターフェースはcollectd、Fluentd、StatsDなど複数に対応している。必要な監視スクリプト(のサンプル)が、使用製品の公式サイトに存在しない場合も、他社サービス向けのリポジトリに流用可能なスクリプトが公開されている可能性が高い。実際に「collectd docker」でGitHub上を検索すると、かなりの数のリポジトリがヒットするので、これらを活用しない手はないだろう。
今回紹介した各社のサービスは、ほとんどが無償のTrial期間や小規模のFreeプランで実際に使用しての評価が行えるようになっている。サービス導入に際しては事前に評価を行い、使い勝手の良さを確認することが良いだろう。
SaaSであるので、使いたいサービスの一部分を一定期間だけ使うことも可能である。必要となるサービスを選択し、既存の監視機能なども含めて、より効率良く、業務負荷の低い運用監視を実現したい。
関連記事
Oracle Cloud Hangout Cafe Season4 #4「Observability 再入門」(2021年9月8日開催)
2024年4月23日 6:30
Infrastructure-as-Codeアプローチと「Pulumi」の概要
2023年2月14日 6:30
システム運用エンジニアを幸せにするソリューションPagerDutyとは
2018年2月16日 10:00
セキュリティ運用に必須のパッチ管理とログ監視(後編)
2018年6月5日 6:30
AWSの監視サービス「CloudWatch」でサーバー監視を試してみよう
2024年8月9日 6:30
パフォーマンス管理から「オブザーバビリティ」にブランディングを変えたNew Relicが新価格体系を発表
2020年9月15日 6:00
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
