Docker環境にマッチしたリソース監視機能
前回の連載終了(2015年6月)から1年も経っていないが、その間にもDockerは急速に利用が拡大しており、それに伴う関連製品の発表やサービスの提供、機能強化が日進月歩で行われている。そこで今回の連載では、進化を続けるDocker本体およびDockerを制御するための関連製品、Dockerをより便利に利用するためのクラウドサービス、SaaS(Software as a Service)などに注目し、その製品やサービスの紹介と合わせて、実際にシステムで利用する際のユースケースなども考えていきたい。
本稿では、Docker実行環境およびDockerコンテナの監視を行うサービスについて述べていきたい。ご存じの通り、Dockerはコンテナ型のサーバ仮想化製品であるため、コンテナごとに割り当てられるリソース(CPU、メモリ、ストレージ)は固定ではなく、ベースとなるOSと共用となる。そのため、既存のsnmpやZabbixなどの監視エージェントなどでリソース使用量を監視しようとしても、ベースOSのデータが取得されてしまい、コンテナごとのリソース使用状況の把握は行えない。
筆者が考えるDockerを監視するための必要な要件および機能は、以下の通りだ。可能な限り、現状のサーバ仮想化環境と同様の監視を実現しつつも、Docker環境の利便性を阻害しない対策の検討が必要となる。
Docker環境の監視に必要となる要件
| No | 要件 | 機能 | 注意点・考慮点 |
|---|---|---|---|
| 1 | リソース使用量の監視 | Dockerコンテナ全体のリソース使用量、使用率を集計する。対象はCPU、メモリ、ストレージ、NIC等、一般的なsnmpで監視が行えるパラメータ | コンテナ内で起動したプロセスも、ベースOSから見れば1つの独立したプロセスとして認識される。コンテナ本体およびコンテナ内で起動したプロセスの総和を、コンテナのリソース使用量とする必要がある |
| 2 | コンテナの自動検出 | Dockerコンテナが生成されたことを検知して監視を開始し、破棄されたことを検知し監視を終了する | Docker環境ではコンテナは必要に応じて作成され、不要になれば破棄されるため、作成・破棄が繰り返される環境での自動監視機能が必要となる。適切に破棄されたことと、障害で停止したことの見極めが重要となる |
| 3 | コンテナ内の設定に対する影響の最小化 | Dockerコンテナは、公式のDocker Hubなどからダウンロードされて、そのまま利用されることが想定されるが、その状態でも監視が行える | 監視用のエージェントや、スクリプト導入の有無が重要な観点となる。コンテナ導入時に、監視のために設定の追加が必要であれば、利用者がコンテナを生成するたびに作業が発生し、利便性の低下を招きかねない。ただ、ログなどのようにコンテナ内でしかアクセスできないものを監視する場合は、設定済みコンテナの利用など対策が必要 |
コンテナのリソース状況を測定する方法は、以下の2つが考えられる。
docker statsコマンドを使用する
Docker 1.5より実装されたdocker statsコマンドにより、CPU、メモリ、ネットワークI/Oについてはリソース使用状況が把握できるようになった。さらにDocker 1.9では、ディスクI/Oについての負荷も取得できるように機能強化されている。ところが、実際にスクリプトを利用し、一定間隔(10秒程度)でデータを取得してみると、コマンドの実行結果が取得できない事象が発生した。1台のサーバで同時に起動するコンテナ数を増やしていくと、結果が取得できない事象の頻度も増加する。このため、docker statsだけで本番環境と同様のリソース使用量監視を行うのは、若干不安がある。
cgroups(control groups)からプロセスごとのリソース使用量の値から集計する
上記の問題の発生により、対案としてcgroupsのリソース統計値から取得する方法を検証してみた。cgroupsでは各プロセスが使用しているCPU、メモリ、ディスクI/Oについての統計値の取得が可能である。Dockerのプロセスの起動を検知し、cgroupsから値を取得し、リソース使用量の情報を作成するスクリプトを作成したところ、何とか一定レベルの監視を行える状態を実現できた。
上記のcgroupsを用いる方法にて、Zabbix等の既存の監視ツールにてリソース監視を行うことは可能となったが、cgroupsから性能情報の取得を行うためのスクリプトの作り込みが必要である。またcgroups自体は、Linux OSのディストリビューションやカーネルのバージョンにより、出力が異なる可能性もある。そのため、それぞれの環境に対応するためのカスタマイズが必要なだけではなく、カーネル、Docker本体等のバージョンアップに対しても十分な配慮が必要となり、開発に対する相応のコストも必要となる。
Docker環境を利用する場合は、既存のサーバ仮想化環境とは異なり、Immutable(Disposable) Computingの考え方で運用される。Dockerコンテナは、作成・起動・停止のいずれも非常に短時間で行える。そのため、必要になった時点でコンテナを生成し、不要となったら削除する運用が標準となる。このような運用により、クラスタリングもオートスケールも自由度の高い運用が実現できる。
一方、既存の監視ツールはサーバが固定で存在することを前提としており、Immutable(Disposable) Computing環境のように生成と廃棄を繰り返す状態は想定していない。クラスタリングのために同一サーバを廃棄後に生成した場合は監視を継続する必要があるが、コンテナの場合はIPアドレスも変わるため、どのコンテナを継続監視すべきかの判定を行う必要がある。
これらの理由から、Docker環境のコンテナを監視するためには、既存の監視ツールに対して、かなりの規模の改修が必要となることが想定され、コスト負荷も運用負荷も非常に大きい。
これについては、July Tech Festa 2015でのDatadog社の堀田直孝氏による講演において、Docker環境の監視も行えるSaaSの利用が、非常に有効な解決策であるという説明があった。またその講演では、Docker環境の監視サービスを提供しているベンダーとして、以下の各社が紹介されていた。
Docker環境の監視機能を提供するSaaSの例
| No | サービス名 | 提供企業 | 公式サイト |
|---|---|---|---|
| 1 | New Relic | New Relic, Inc. | http://newrelic.com/ |
| 2 | AppDynamics | AppDynamics, Inc. | http://www.appdynamics.jp/ |
| 3 | sysdig cloud | Draios, Inc. | http://www.sysdig.org/ |
| 4 | DATADOG | Datadog, Inc. | https://www.datadoghq.com/ |
| 5 | SignalFx | SignalFx, Inc. | https://signalfx.com/ |
| 6 | Librato | SolarWinds Worldwide, LLC. | https://www.librato.com/ |
| 7 | Scout Monitoring | Zimuth, Inc. | https://www.scoutapp.com/ |
| 8 | Mackerel | 株式会社はてな | https://mackerel.io/ja/ |
そこで実際にサービスを利用し、顧客への提案を行う前に、各サービスの概要や特徴について、事前に調査を行った結果を、以下に紹介する。
New Relic

New Relic社は、2008年に設立されたアメリカ サンフランシスコに本拠を置く企業である。ソースコードレベルの診断・解析や、システムの死活、性能監視やアクセス解析などをSaaS型で提供している。New Relic社の公式サイト上で紹介されている提供サービスの概要は、以下となる。
New Relic社が提供するサービス
| No | サービス名 | 概要 |
|---|---|---|
| 1 | APM | アプリケーションの性能解析を行うサービス。処理のレスポンスを、トランザクション全体ではなくソースレベルで把握できるのが特徴。Java、Ruby、Python、PHPなどの言語や.NET、Node.jsなどのフレームワーク製品にも対応 |
| 2 | MOBILE | モバイルアプリケーションのレスポンスやアクセス解析を行うサービス。アプリケーションのパフォーマンスだけではなく、モバイル端末のデバイスやOS、アクセスしている地域やキャリアの情報の収取も行える。さらにアプリケーションのクラッシュが発生した場合、その発生状況の収集も行える |
| 3 | BROWSER | Webサイトのページごとのアクセス数や処理時間、アクセスしたユーザと各ユーザが画面上でどのようなオペレーションをしていたか、さらにはどのようなエラーが発生していたか、ブラウザ上で発生していた状況の情報をリアルタイムに収集する製品 |
| 4 | SYNTHETICS | 対象のWebサイトのユーザの行動を予測して、Webサイトのレスポンスのテストを行う製品。全世界9拠点からテストを実施し、各地域からのレスポンスの状況を調査できる |
| 5 | INSIGHTS | 上記の1~4の製品を組み合わせて解析を行う製品、解析のカスタマイズも行え、より高度な分析が可能となる |
| 6 | SERVERS | CPU、メモリ、ディスクI/Oの使用量と使用率を取得し、設定された閾値に対応した監視アラートを発行する。物理サーバ、クラウド基盤、仮想マシンに対応している |
| 7 | PLUGINS | 各種プロダクトや基盤に対応した監視プラグインを提供している。100種類以上のプラグインが提供されており、RDB(Oracle、MySQL、MS SQL Server)やWebサーバ(Apache、nginx)、ストレージ(ZFS、Google cloud storage)など多種多様なプロダクトや基盤に対する監視を、プラグイン導入のみで開始できる |
PLUGINSはRuby、Java、Shell、Python、Goなどの様々な言語で作成されており、Nagiosのpluginsと同様の使い方をされていると考えられる。
New Relic社のDockerの監視への取り組みは、こちらにまとめられている。Docker環境の監視は、前述のSERVERSとAPMを組み合わせることで実現している。実際には、Docker環境のベースとLinux環境にSERVERSのエージェントをインストールし、各コンテナにAPMのエージェントをインストールする実装となっている。
サイト上で公開されている監視画面でも、コンテナ内のアプリケーションの処理性能とコンテナごとのCPU、メモリなどのリソース使用量が取得できていることが見てとれる。
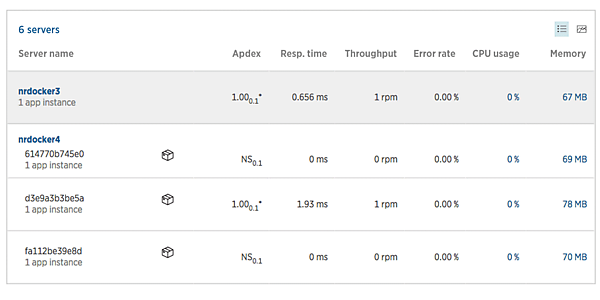
New Relic社が公開する監視画面
ただ、唯一欠点を上げるとすれば、SERVERSがLinuxにインストールするエージェントであるため、CoreOSやRancherOSなどのDocker専用OSでインストーラが動作しない場合は、利用が行えない可能性がある点だ。その点を除けば、システム監視、解析の非常に優秀なサービスをDocker環境でも利用できる。
サイト上で公開されている各サービスの利用料は、以下の通りだ。全ての機能に無償のトライアルライセンスが準備されており、利用前に試行・評価を行えるのは非常にうれしいところである。
New Relic社が提供するサービスの料金体系
| No | サービス名 | LITE | PRO | ENTERPRISE | 備考 |
|---|---|---|---|---|---|
| 1 | APM | 無料 | $149/ホスト、月 | 問い合わせ | 全プラン台数制限なしサポートレベルのみ異なる |
| 2 | MOBILE | 無料 | ? | $999/月 | データ保持期限は、LITEが1日、有償プランは3ヶ月 |
| 3 | BROWSER | 無料 | $149/月 | ? | データ保持期限は、LITEが1日(クラッシュレポートは最大1週間)、有償プランはいずれも3ヶ月 |
| 4 | SYNTHETICS | 無料 | $69/月 | ? | LITEはテスト実施可能機能に制限あり |
AppDynamics

AppDynamics社は、2008年に設立されたアメリカ サンフランシスコに本拠を置く企業である。前述のNow Relicと同様に、通常のシステム監視に加えて、システムの利用状況の解析やシミュレーションなども行う多機能なSaaSを提供している。提供機能のリストは以下の通りだ。
AppDynamics社が提供するサービス
| No | 提供機能 | 概要 |
|---|---|---|
| 1 | 監視機能 | ①エンドユーザー監視、②アプリケーションモニタリング・ダッシュボード、③自動ビジネストランザクション検出、④リアルタイムビジネストランザクション監視、⑤分散トランザクショントレーシング、⑥正常パフォーマンスの自動学習と異常の検出、⑦リアルタイムアプリケーション インフラストラクチャ監視、⑧プロアクティブ通知 |
| 2 | トラブルシューティング | ①トラブル表示専用ダッシュボード、②稼働アプリケーションへの影響は2%未満、③分散環境におけるトラブルシューティング、④データベース/SQL問題のトラブルシューティング、⑤エラー検出とトラブルシューティング、⑥ストールの検出とトラブルシューティング、⑦メモリーリークとスラッシュのトラブルシューティング、 |
| 3 | 分析 | ①カスタムダッシュボード、②トレンドとベースラインの分析、③アジャイルリリースの影響分析、④インテリジェントポリシーエンジン |
| 4 | 自動化 | ①クラウドにおける動的な規模の最適化、②自動化ワークフロー、③事前設定のAmazon EC2コネクタ、④クラウドバースティング |
非常に多機能であり、概要までは書ききれない。機能の詳細は、販売代理店である丸紅情報システムズの製品説明サイトに記載されているので、そちらを参照して欲しい。
公式サイト上で公開されている監視画面、ユーザ分析画面は以下となる。機能も充実しているが、GUIもかなりの高機能である。
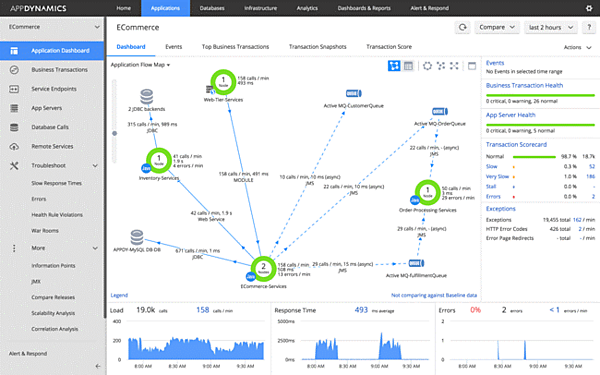
AppDynamics社が公開する監視画面
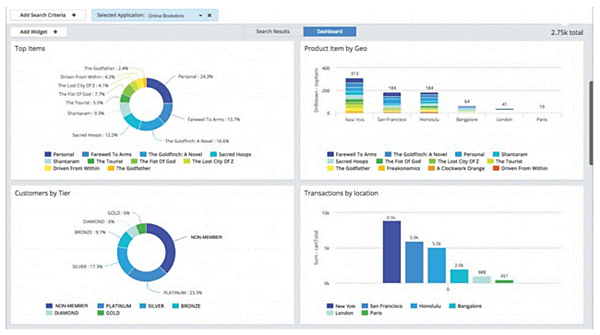
AppDynamics社が公開する監視画面
ライセンスは、機能制限付きだが無償で利用できるLite版と、有償のPro版が存在する。Pro版に関しては価格が公開されておらず、契約ごとの見積りとなるようだ。
Dockerの監視方法については、AppDynamics社の公式ブログで公開されている。Dockerに対応した拡張監視機能はすでに実装されており、コンテナごとにリソース情報の収集を行っている画面が公開されている。
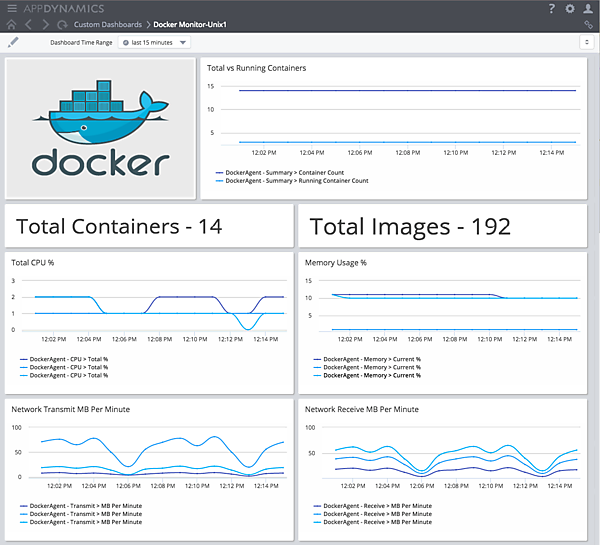
Dockerにも対応済み
監視、解析機能ともに、今回比較した中で最も多機能な製品だと考えられる。日本語でのサポートも行える販売代理店も存在し、導入支援を受けやすい環境が提供されている。パッケージ版での提供も行っているので、オンプレミス環境にも導入が可能である。大規模システムを総合的に管理する用途などに適していると考えらえる。
Sysdig cloud

Sysdig cloudを提供しているDraios社は、2013年に設立されたアメリカ カリフォルニア州デービスに本拠を置く企業である。前述のNew Relic社やDATADOG社と同様にシステムの死活、性能監視やアクセス解析などをSaaS型で提供している。
Draios社は元々、sysdig/csysdigというシステム稼働状態の監視と解析のためのツールを提供していた。このツールは、システム上のプロセスやファイル、CPU、ネットワークなどのデバイスへのI/Oの状態を監視し、デバッグが行える情報の取得と記録を行う製品である。
Sysdig cloudは、通常のシステム監視に加えて、システム稼働状態の記録とデバッグのサービスを提供している。前述のsysdig/csysdigの機能を活用しているものと考えられる。提供サービスの概要は、以下の通りだ。
Draios社が提供するサービス
| No | サービス名 | 概要 |
|---|---|---|
| 1 | システム監視 | サーバやプロダクトの死活、リソース使用状況などの監視を行い、取得した情報をグラフなどに表示する機能。各種基盤やプロダクトに対応した追加エージェントやプラグインを提供している |
| 2 | イベント監視 | 監視対象のプロダクト、リソース、ログなどから取得したイベントを、取得したログと発生件数をグラフィカルに表示する機能 |
| 3 | 履歴再生 | 記録された過去のシステム状態を録画した映像のように再生し、監視ログと合わせてシステムの問題を分析する機能 |
| 4 | 動的トポロジー解析 | システム内の状態をシステム全体からサーバ、プロセス単位まで詳細な解析を行う機能 |
| 5 | 監視アラート | 前述のリソース監視結果やイベント監視結果に対応し、発生状況に応じアラートを送信する機能 |
課金プランは以下のようになっており、オンプレミス環境での利用プランも存在する。14日間の無料評価期間も提供されている。
Draios社が提供するサービスの料金体系
| プラン | Standard | Enterprise |
|---|---|---|
| 料金 | $20/ホスト、月 | 問い合せ |
| 制限 | 監視データ粒度1秒 データ保持無制限 1ホスト20コンテナ以下 1ホスト100カスタムメトリック以下 SaaS利用のみ |
監視データ粒度1秒 データ保持無制限 コンテナ数 カスタムメトリック数無制限 SaaS利用およびオンプレミス環境での利用 |
以下に、公式サイト上で公開されている履歴再生の機能と動的トポロジー解析の画面を紹介する。
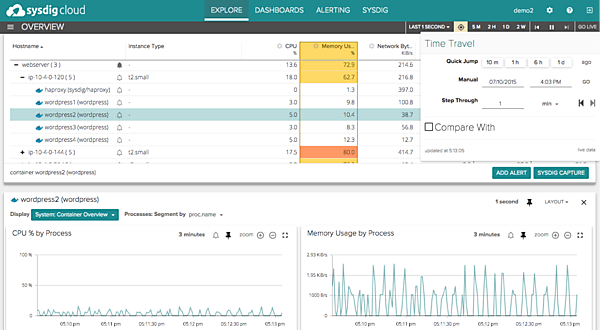
Draios社が公開する監視画面(履歴再生)
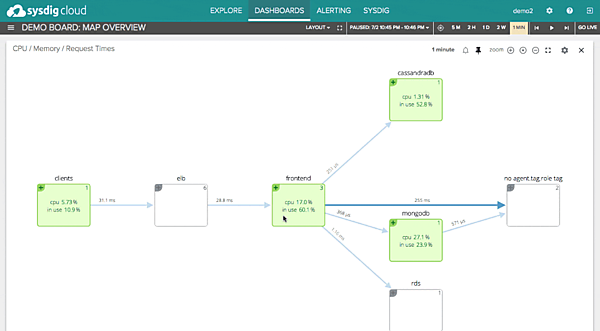
Draios社が公開する監視画面(動的トポロジー解析)
Sysdig cloudのエージェントをLinuxにインストールする場合、合わせてSysdigに対応した専用のカーネルヘッダーもインストールされる。専用のカーネルヘッダーが必要な理由は、前述のリソース状態の正確な把握や、sysdigのプロセスやファイル、デバイスに対するI/Oの完全な記録のためには、カーネル部分から情報を取得するのが確実であるからだと考えられる。
Docker専用OSのCoreOS上でも利用可能だが、他のLinuxと同様に専用のカーネルヘッダーのインストールが必要である。またSysdig Agentは、Dockerコンテナとしてのインストールも可能である。Docker専用OSベンダーであるRANCHER社の公式ブログで、Sysdig cloudの評価結果が掲載されている。Docker環境の監視がどのように行わるのか、大変わかりやすく解説されている。
さらに2015年7月14日に公式サイトのニュースとして、特許出願中のContainerVision™ technologyというコンテナネイティブの監視基盤の提供を発表している。これはベースOSのカーネルからではなく、コンテナ内部からリソースの使用状況の監視を行える機能で、コンテナへのエージェント等のインストールなしで監視が行える機能を実現しているとの発表があった。その発表に添付されていたサンプルの監視画面は、以下の通りだ。
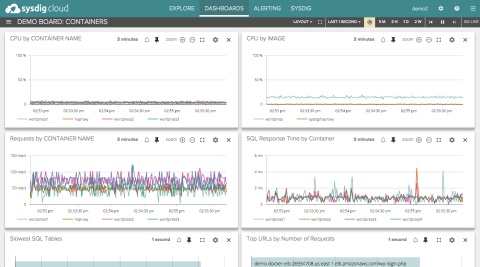
ContainerVision technology使用時の監視画面(サンプル)
カーネルに手を加える点に若干の懸念はあるが、監視ツールとしてもシステムのデバッグツールとしても非常に高機能であると考えられる。ContainerVision™のように、コンテナに対してエージェントのインストールや設定変更も不要で正確な監視が行えるのであれば、製品としての優位性も高いと考えられる。
関連記事
Oracle Cloud Hangout Cafe Season4 #4「Observability 再入門」(2021年9月8日開催)
2024年4月23日 6:30
Infrastructure-as-Codeアプローチと「Pulumi」の概要
2023年2月14日 6:30
システム運用エンジニアを幸せにするソリューションPagerDutyとは
2018年2月16日 10:00
セキュリティ運用に必須のパッチ管理とログ監視(後編)
2018年6月5日 6:30
AWSの監視サービス「CloudWatch」でサーバー監視を試してみよう
2024年8月9日 6:30
パフォーマンス管理から「オブザーバビリティ」にブランディングを変えたNew Relicが新価格体系を発表
2020年9月15日 6:00
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
